python 0-1标准 最大值_数据预处理(去量钢化)的四大方法与python实现
如何学习数据分析?做数据分析,尤其是数据建模,一半的时间都会花费在数据预处理上。但不进行预处理又不可行,因为不处理就不能很好地进行数据压缩和可视化,也不能满足模型对数据的要求。数据预处理重要又费时,如何提高数据预处理的效率呢?数据去量钢化预处理四大方法来了, python帮你轻松实现。01.去量钢化四大方法1. 标准化(StandardScaler)StandardScaler使每个...
如何学习数据分析?做数据分析,尤其是数据建模,一半的时间都会花费在数据预处理上。但不进行预处理又不可行,因为不处理就不能很好地进行数据压缩和可视化,也不能满足模型对数据的要求。
数据预处理重要又费时,如何提高数据预处理的效率呢?数据去量钢化预处理四大方法来了, python帮你轻松实现。
01.
去量钢化四大方法
1. 标准化(StandardScaler)
StandardScaler使每个特征的平均值为0,方差为1。优点是确保每一个特征都在同一个数量级上,缺点是不能保证每个特征的最大值和最小值。
2. 鲁棒标量化(RobustScaler)
RobustScaler原理与StandardScaler类似,使每一个特征的统计属性都位于同一范围。
RobustScalar与StandardScaler不同的是,RobustScaler使用的是中位数和四分位数。
RobustScaler会忽略异常值(即与其他多数点有非常大差异的点)。
3. 最小最大值标量化(MinMaxScaler)
MinMaxScaler用数值本身减去最小值再除以数据范围(最大值-最小值),也使每一个特征的值都位于0和1之间。对二维数据集来说,就是使所有特征的值都位于以(0,0)和(1,1)互为对角线顶点的正方形内。
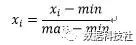
4. 正态标准化(Normalizer)
Normalizer对每一个数据点进行缩放,使特征向量的欧式长度等于1。对二维数据集来说,缩放后,所有数据点位于半径为1的圆上。
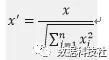
Normalizer对不同数据点特征的值进行的缩放不是同比例的(缩放比例为其特征向量长度的倒数),即不同数据点的特征值不同,会改变数据点特征的值的相对大小。因此,当只关心数据的变化方向,而不关心数值大小时,才进行Normalizer归一化。
02.
去量钢化的python实现(以MinMaxScaler为例)
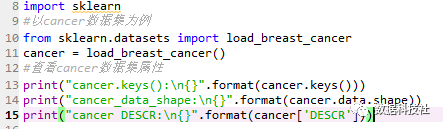
1.数据准备
(1)调用cancer数据集
输出结果:

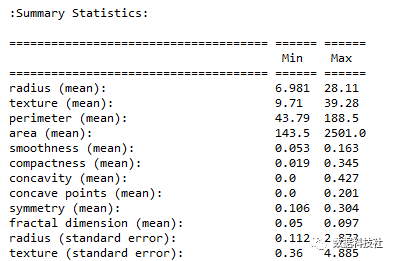
注:特征属性summary仅截取了部分
(2)将数据集分为测试集和训练集
分为训练集和测试集,以便后面对比相同伸缩、不同伸缩变换的影响,以及去量钢化对测试集预测精度的影响。
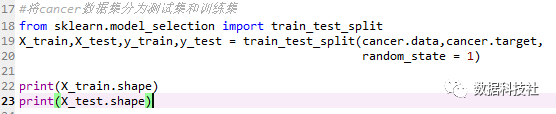
输出结果显示:测试集和训练集分别有426个数据点、143个数据点,都有30个特征。
2. 调用MinMaxScaler,用fit_transform方法进行数据变换
(1)用fit方法拟合缩放器Scaler
(2)用transform方法进行伸缩变换
注:四大去量钢化方法中都内建有fit和transfrom方法,fit和transform方法可以合并使用fit_transform。

对比训练集和测试集伸缩变换前后的最小值和最大值:

训练集最小值、最大值:

测试集最小值、最大值:
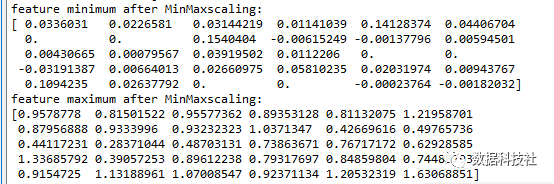
训练集最小值和最大值分别为0和1,但测试集不是(可能有小于0的数据,也可能有大于0的数据),因为transform方法对测试集进行MinMaxScaler伸缩变换时,最小值和最大值都用的是训练集中的最小值和最大值。
使用MinMaxScaler进行相同伸缩变换后,测试集最小值不为0,最大值不为1。是否有必要对测试集单独进行伸缩变换,使其最小值和最大值分别为0和1呢?不需要,因为我们关心的不是绝对数值,只要量级相同,我们就达到了去量钢化的目的。
3. 数据呈现与伸缩变换对比
对数据进行去量钢化预处理的主要目的之一是进行数据压缩和可视化,将数据呈现在容易观测的图形中。
可视化后,会发现:如果单独对测试集进行MinMaxScaler伸缩变换,反而会改变测试集相对训练集的数据分布,这也是不能单独对测试集进行伸缩变换的原因之一。
示例如下:
输出结果:我们发现右图中测试集(红色三角)与中间图中测试集的分布不同,并且相对训练集分布发生了变化。
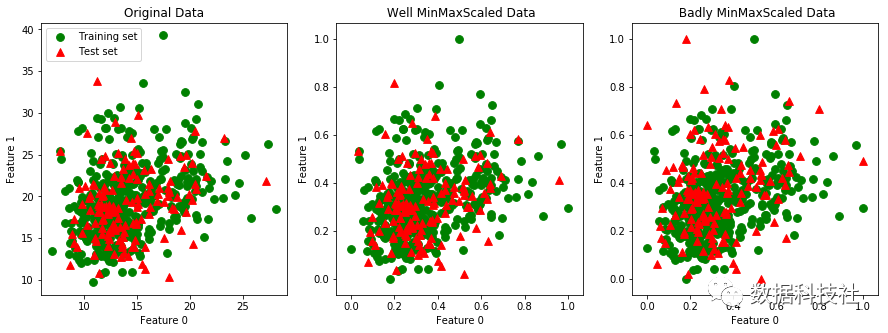
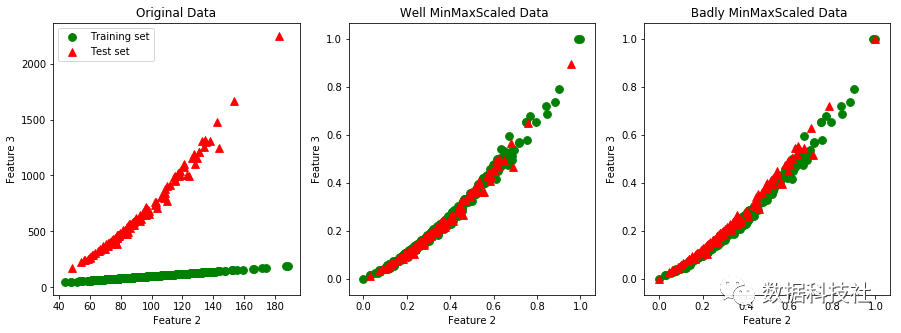
使用cancer测试集中Feature2和Feature3进行测试,得到了相同的结论:单独对测试集进行伸缩变换后,测试集数据分布相对训练集发生了变化。
4. 去量钢化有利于提升测试集预测精度
去量钢化的另一个主要目的是使数据符合模型,提升模型预测精度。

对比原始测试集和去量钢化后的测试集,发现:去量钢化后测试集的预测精度明显提高了。
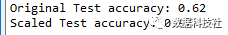
End
往期回顾
· 如何学习数据分析?
· 想做数据分析,如何找项目练习?
· 数据分析师的职业焦虑与未来发展——来自一个30岁数据分析师的感悟
· 数据分析师是做什么的?(滴滴数据科学负责人宋世君,深度长文)
· 价值百万的分析报告之数据呈现——阿里大牛谈五大原则和处理六大关系

长按关注公众号
长按加入微信交流群
有你认识的人吗?点“分享”,告诉TA


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)