Noisy Student Training:自训练(Self-training)、半监督学习、teacher和student迭代学习
1 简介本文根据2020年《Self-training with Noisy Student improves ImageNet classification》翻译总结。自训练(Self-training)使用标注数据训练一个好的teacher模型,然后使用该teacher模型对未标注的数据进行标注,最后使用标注数据和非标注数据联合训练一个student模型。如下图所示。本文提出的Noisy St
1 简介
本文根据2020年《Self-training with Noisy Student improves ImageNet classification》翻译总结。
自训练(Self-training)使用标注数据训练一个好的teacher模型,然后使用该teacher模型对未标注的数据进行标注,最后使用标注数据和非标注数据联合训练一个student模型。如下图所示。
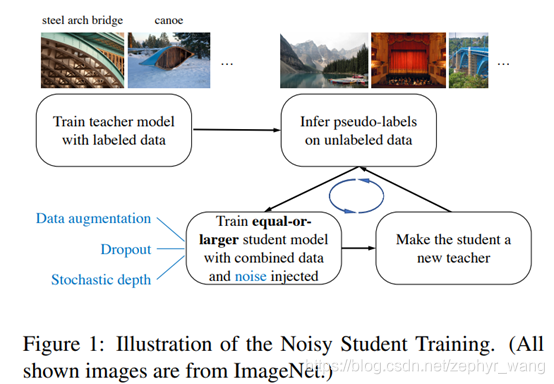
本文提出的Noisy Student Training扩展了自训练和蒸馏,即(1)使用一个相等或者更大的student 模型,(2)并添加噪声到student训练中。是一种半监督学习。(3)迭代学习,即student训练好后作为teacher继续生成伪标签,继续训练新的student。
我们的模型Noisy Student Training超过了以前的最优模型(弱监督模型),它们是采用了3.5B(billion)的弱标注(weakly labeled)数据(Instagram 应用的图片)。
2 Noisy Student Training算法
该算法的主要改善点是(1)添加噪声到student;(2)student模型不比teacher小。具体算法如下所示。

伪标签的生成可以是soft的(连续分布)或者hard的(one-hot 分布)。实际上,Soft 伪标签对于外域未标注数据表现的稍微好些。
Noising Student:我们采用两种类型的噪声:输入噪声和模型噪声。输入噪声采用数据增强方式,如RandAugment;模型噪声,我们使用dropout、随机深度(stochastic depth)。
其他技巧:当使用数据过滤和平衡时,模型表现的更好。我们过滤掉teacher 模型有较低可信度的图片,这些图片也往往是外域的。为了确保未标注数据的分布匹配训练数据,我们要平衡每个类别未标注数据的数量。
3 实验结果
我们最大的模型,EfficientNet-L2, 其需要在2048核上的TPU v3 pod训练6天,是EfficientNet-B7 训练实际的5倍。
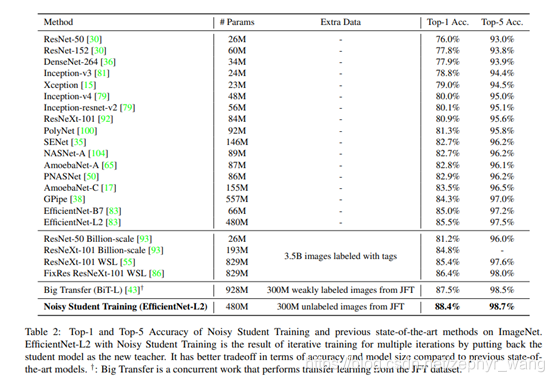
如下表,我们的模型Noisy Student Training (EfficientNet-L2)表现最好。
下图是没有采用迭代训练的Noisy Student Training,可以看到也表现很好。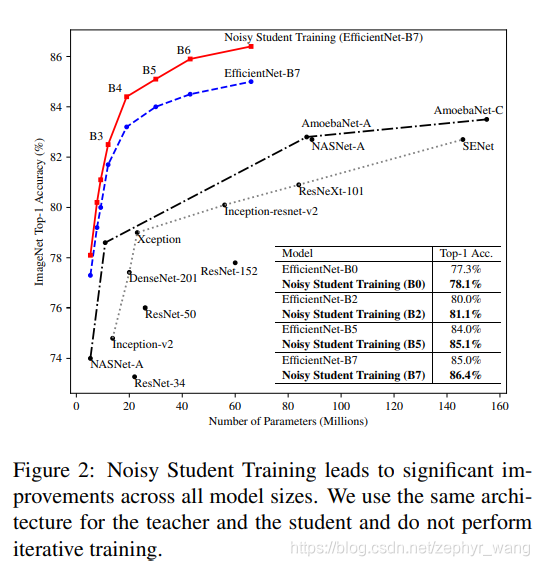
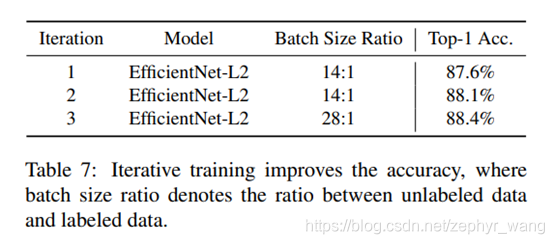
迭代的实验结果如下,如下表的第2行(2次迭代)比第1行(1次迭代)效果好。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)