【强化学习-05】AlphaGo
Policy-based reinforcement learningPolicy NetworksBehavior CloningTrain policy network using Policy gradientTrain the value networkMente Carlo Tree Search本笔记整理自 (作者: Shusen Wang):https://www.bilibili.
·
Policy-based reinforcement learning
本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
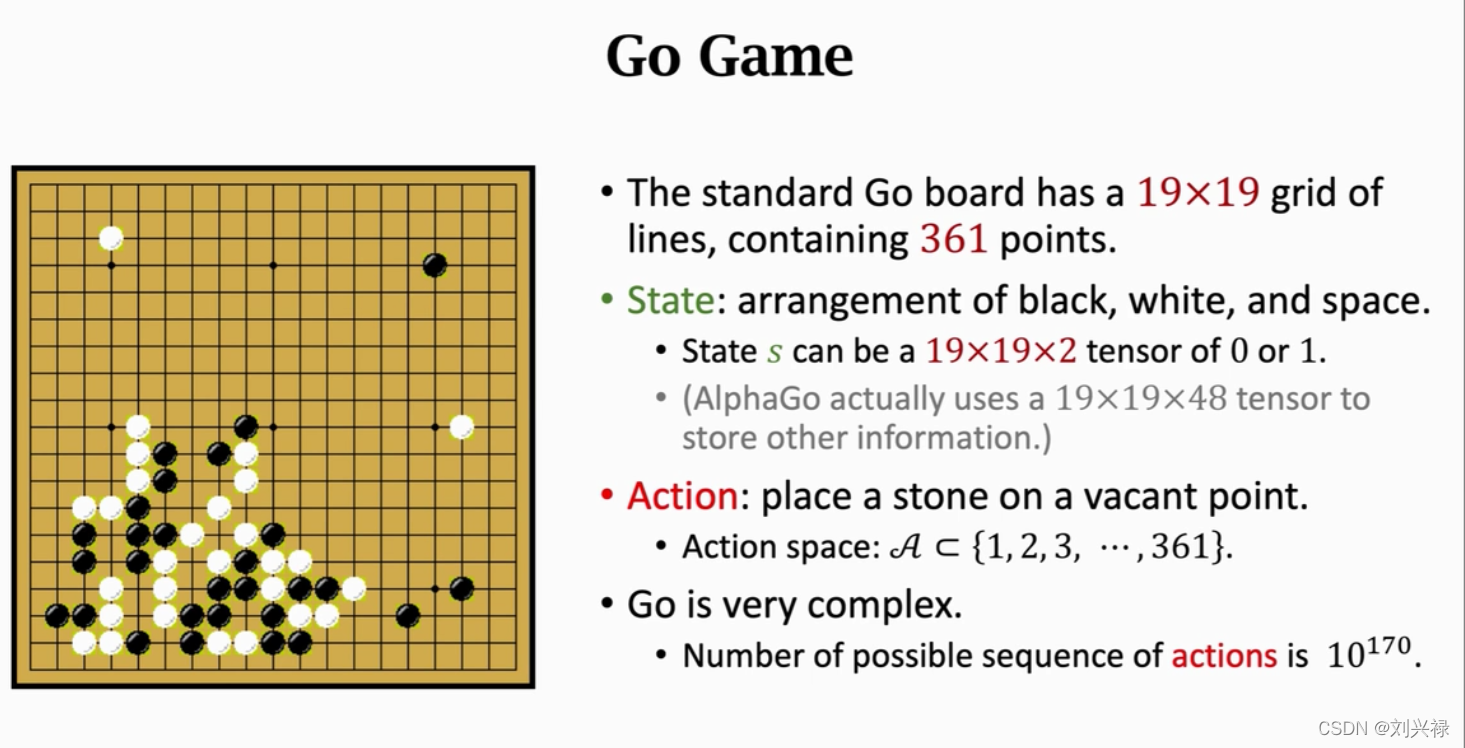


Policy Networks

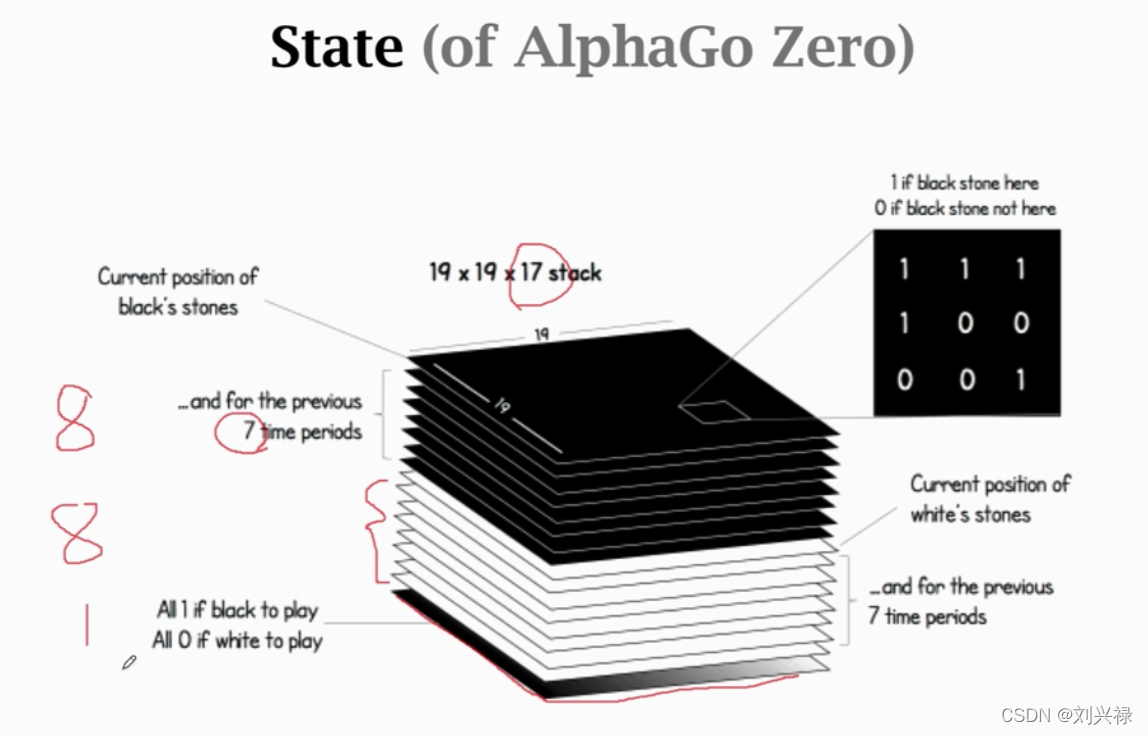
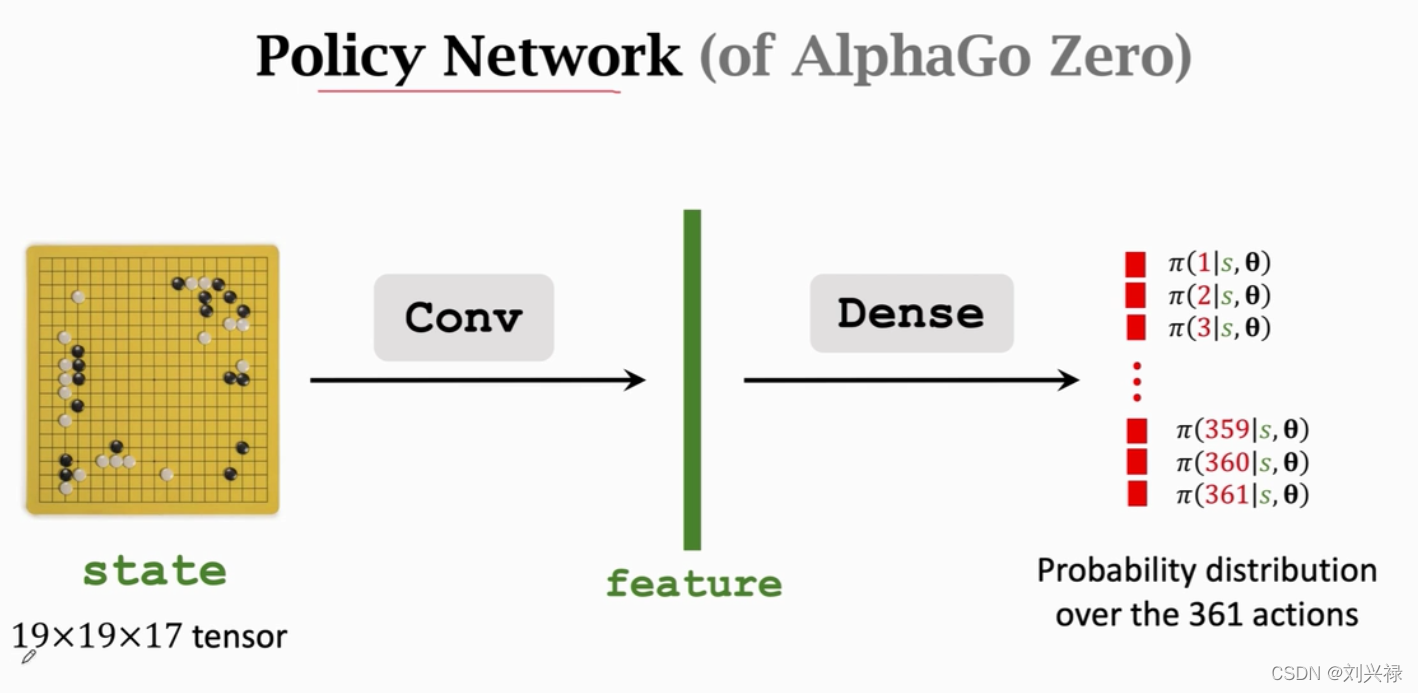
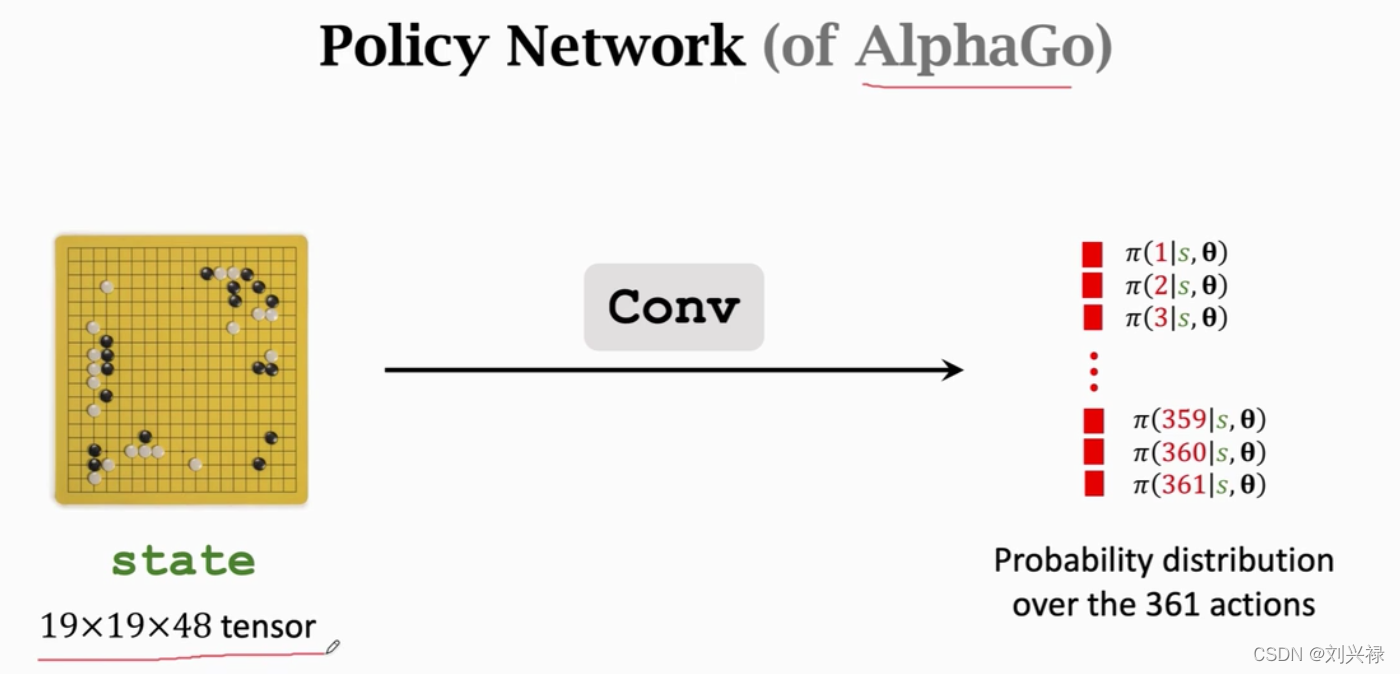
Behavior Cloning


Behavior cloning: 是一种模仿学习,模仿学习和强化学习的主要区别在于:有没有奖励
没有奖励就是模仿学习,有奖励是强化学习


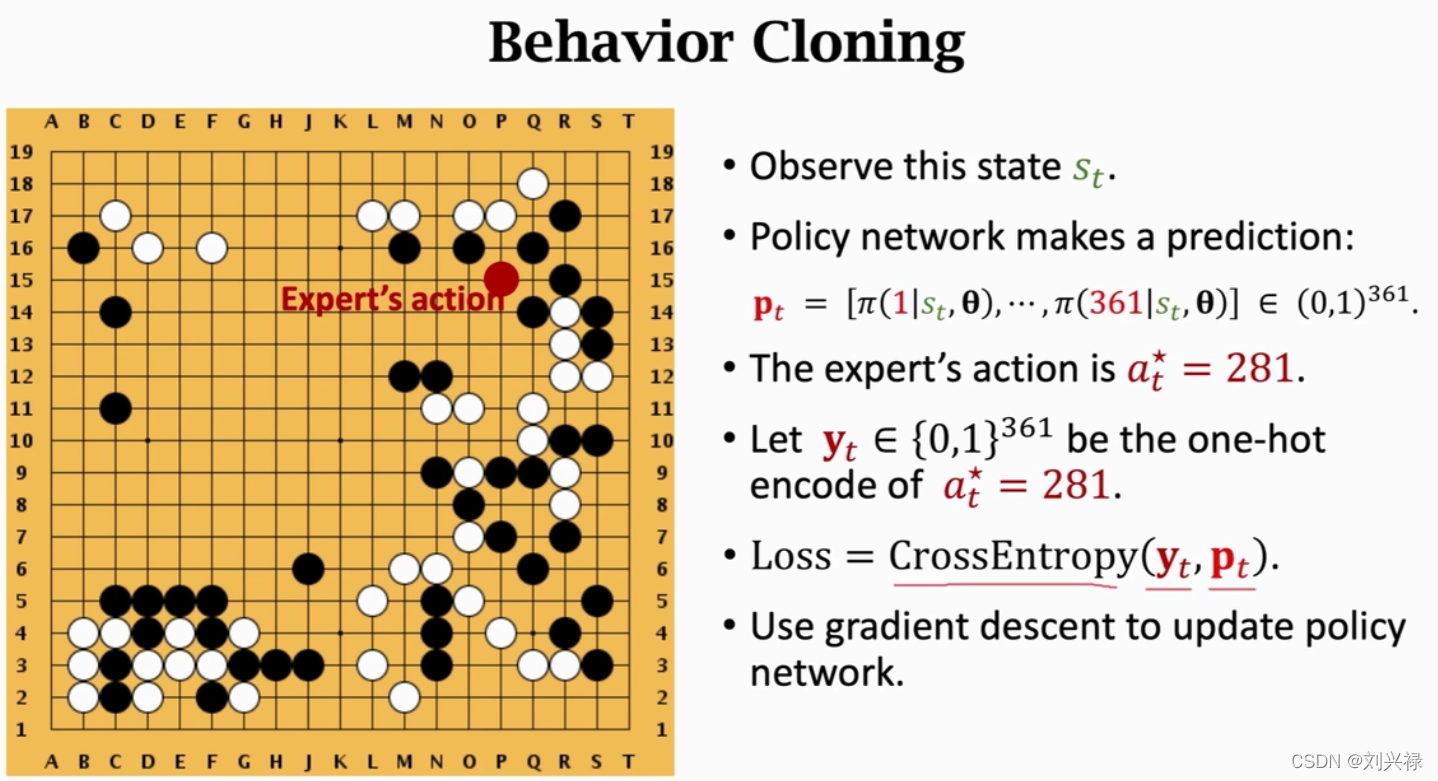
behavior cloning其实就是多分类,有361个类,其中label就是人类的下法。

如果策略网络没有见过 a t a_t at,策略网络就无法识别,就会失效。因此下一步 a t + 1 a_{t+1} at+1就会更奇怪。
Train policy network using Policy gradient

player: 根据reward来更新policy network
强化学习用奖励来更新网络
模仿学习没有奖励




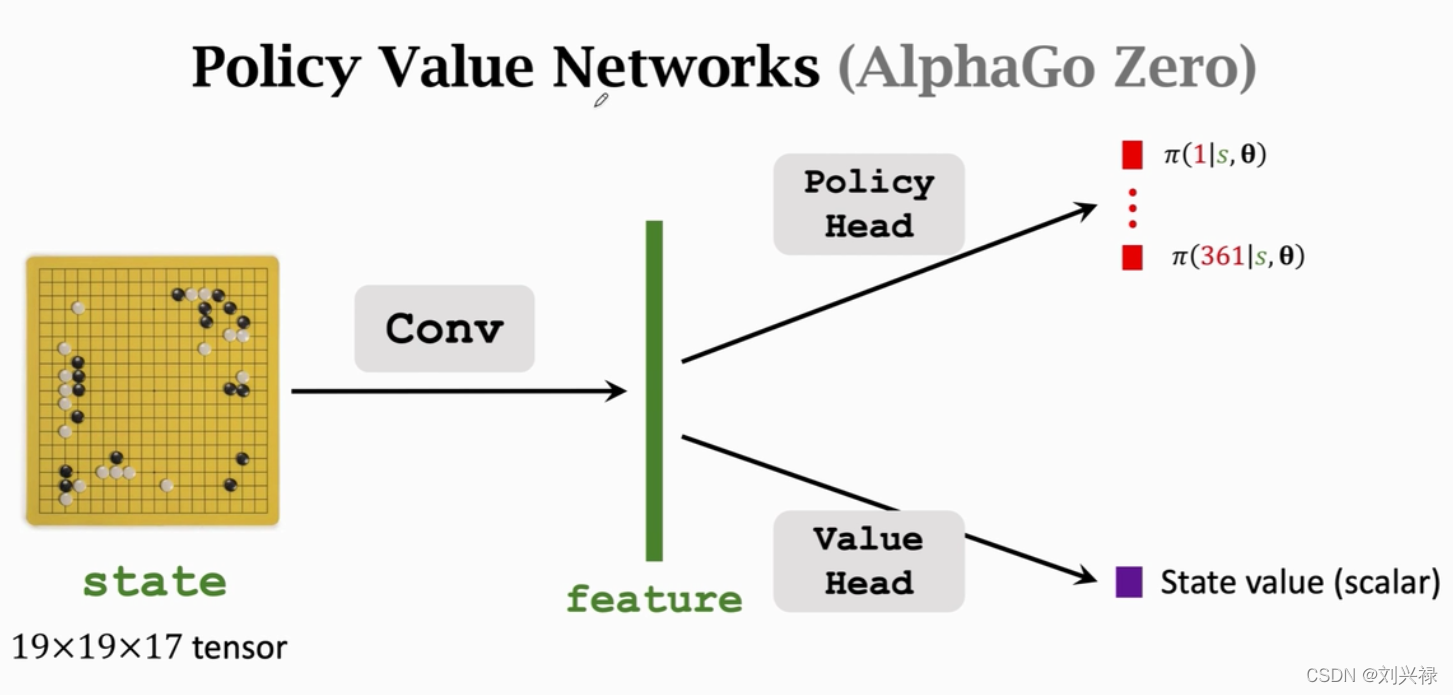
Train the value network


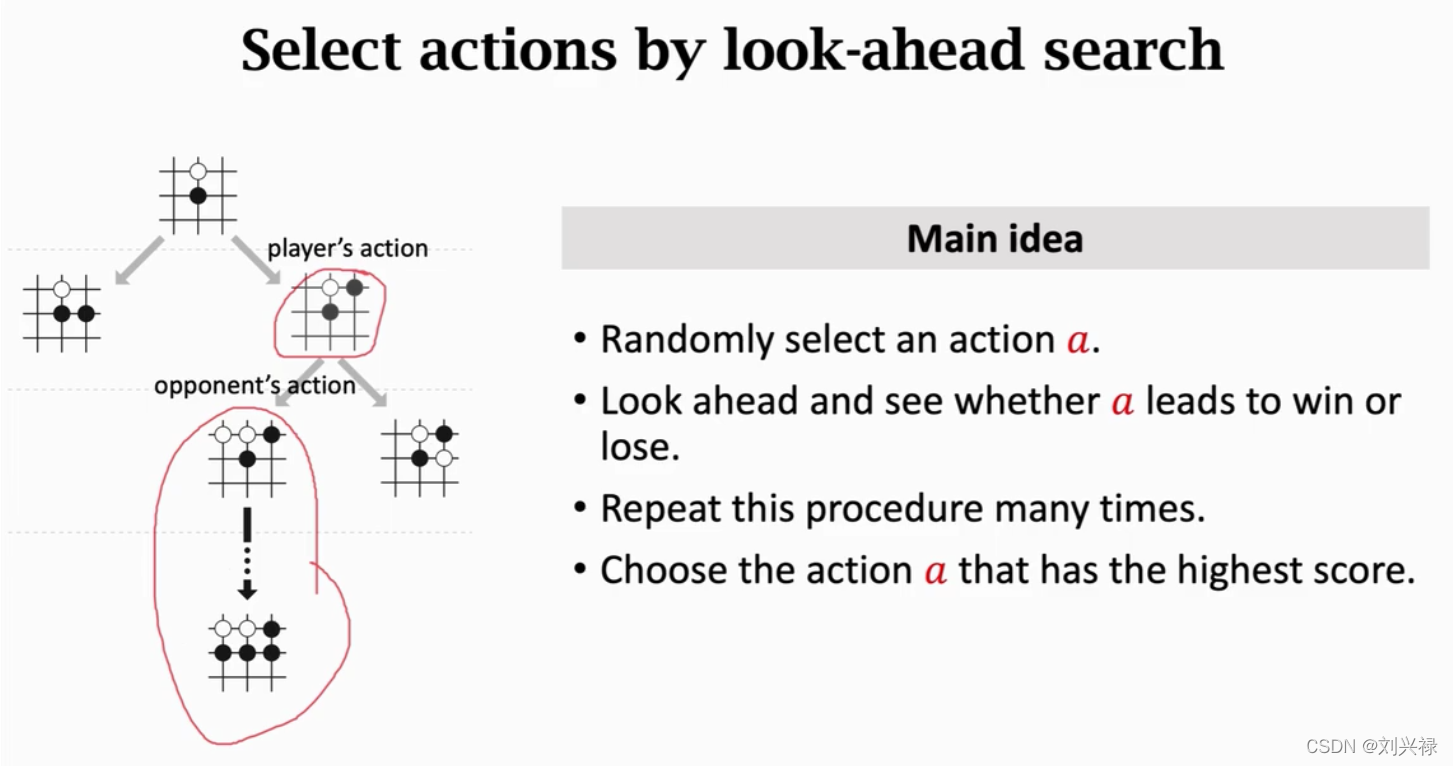
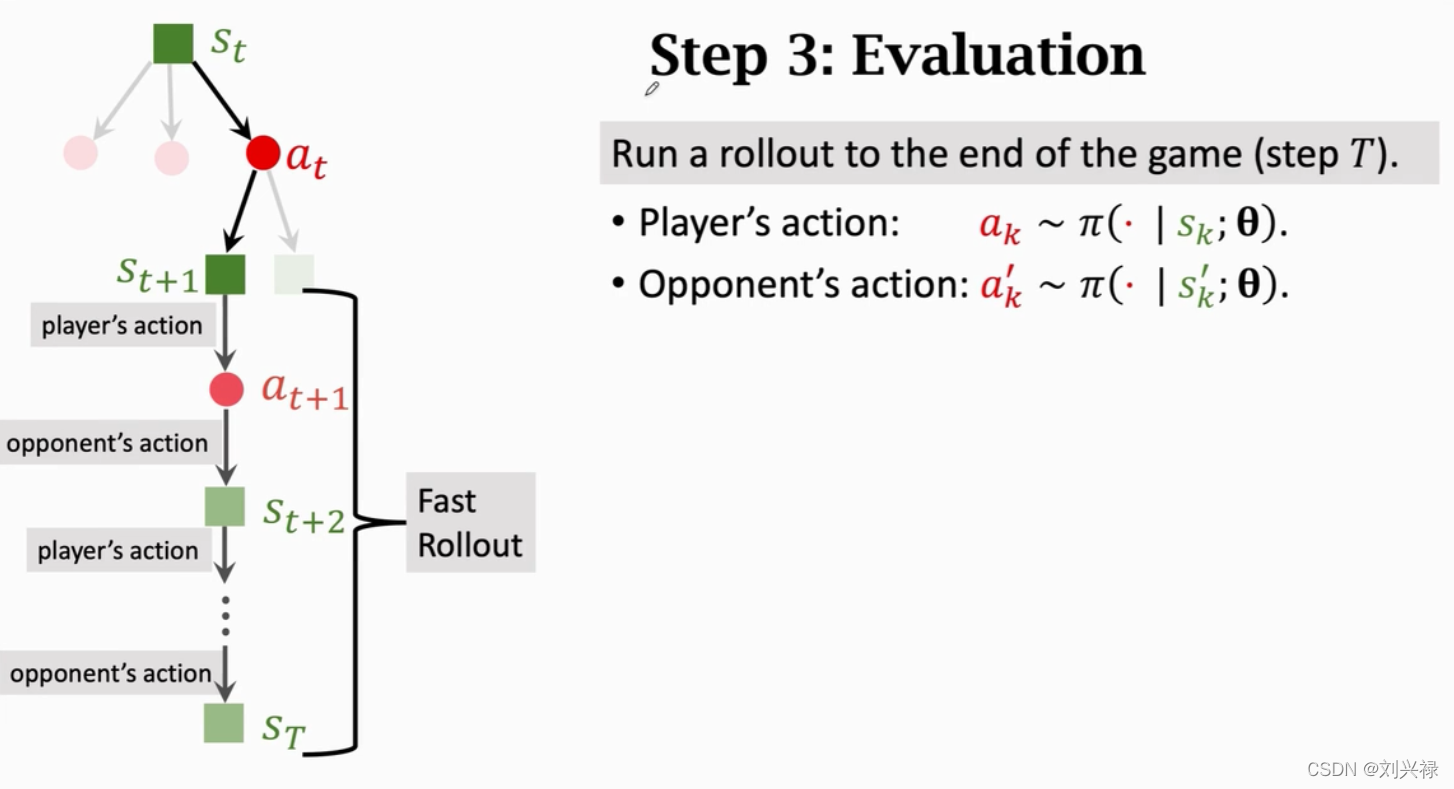
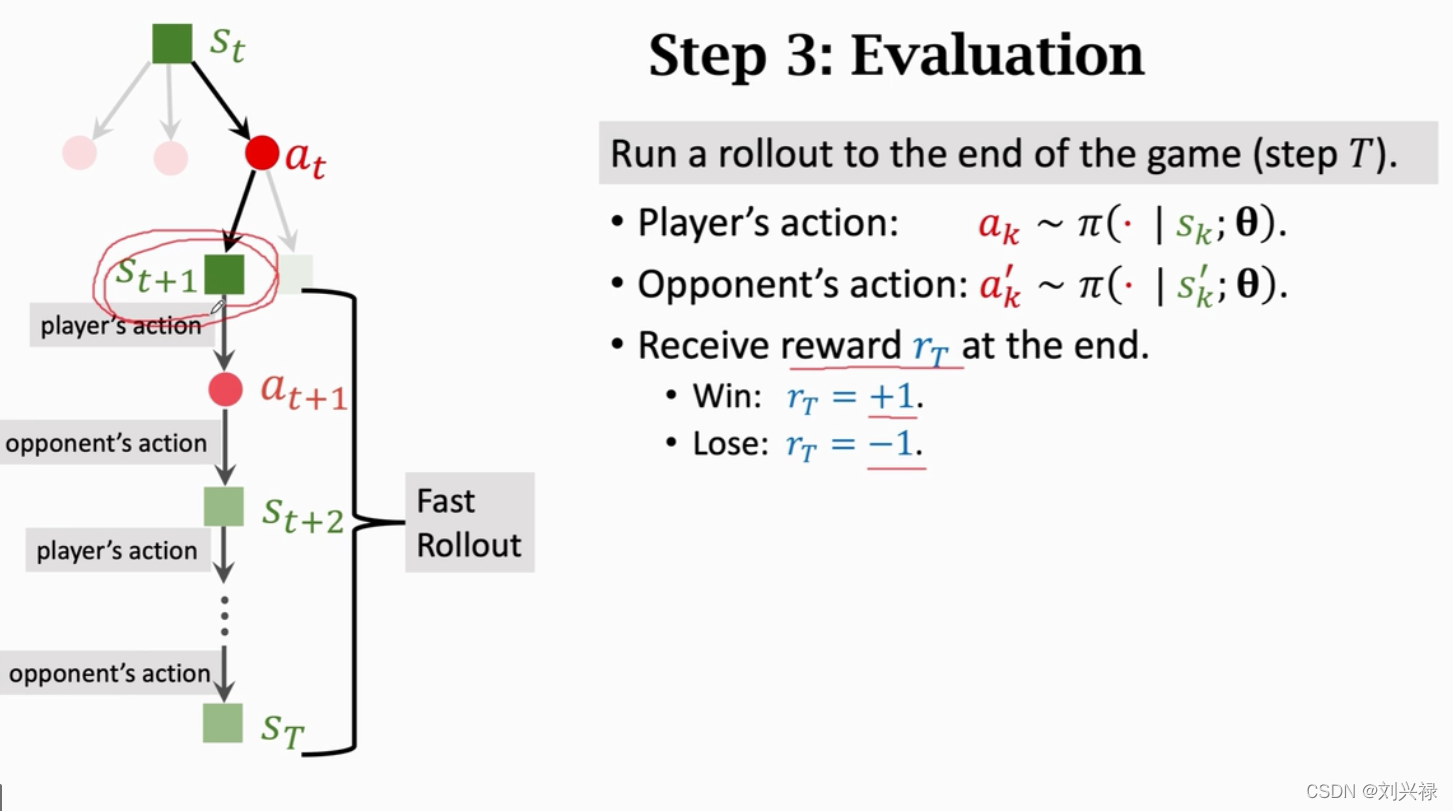
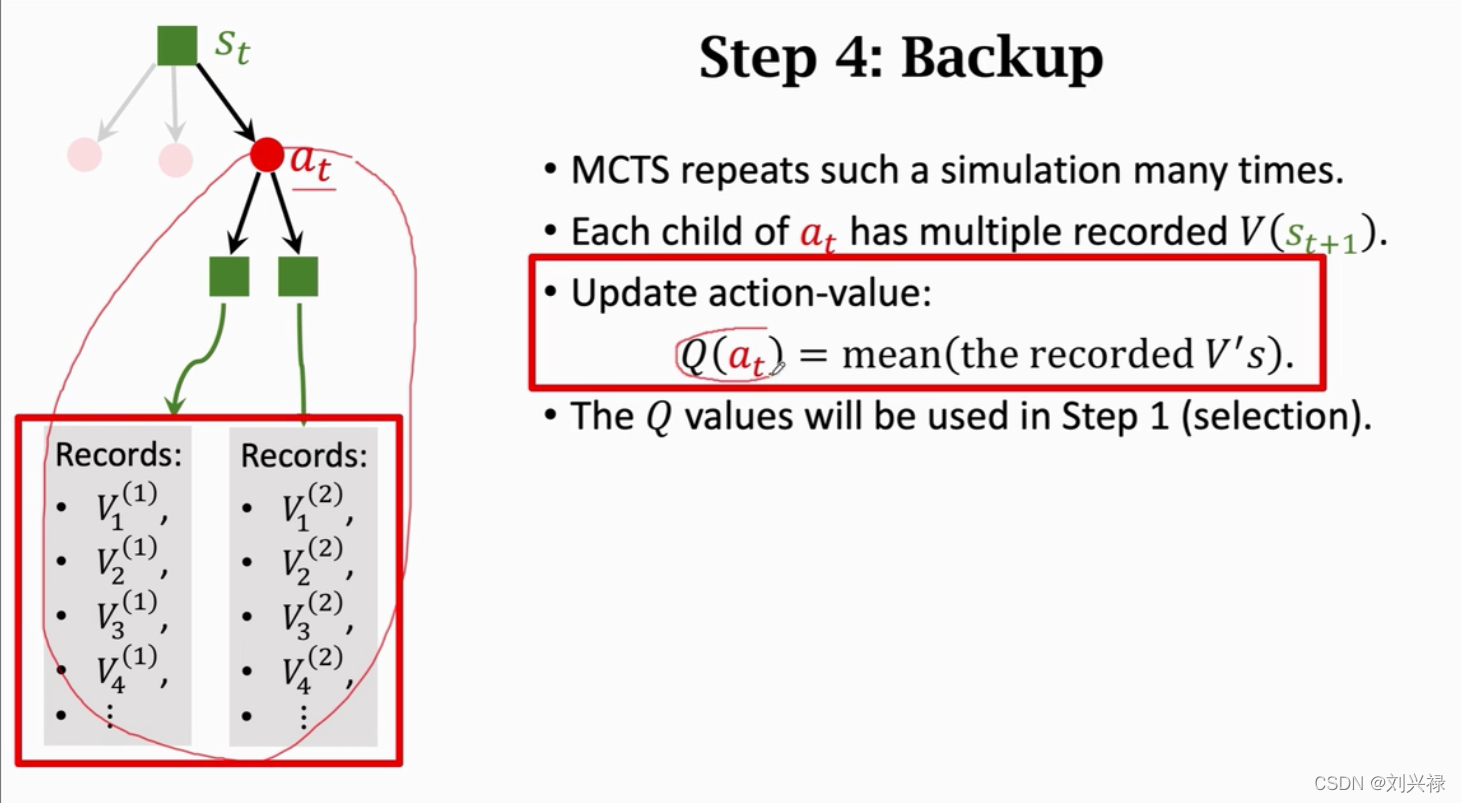
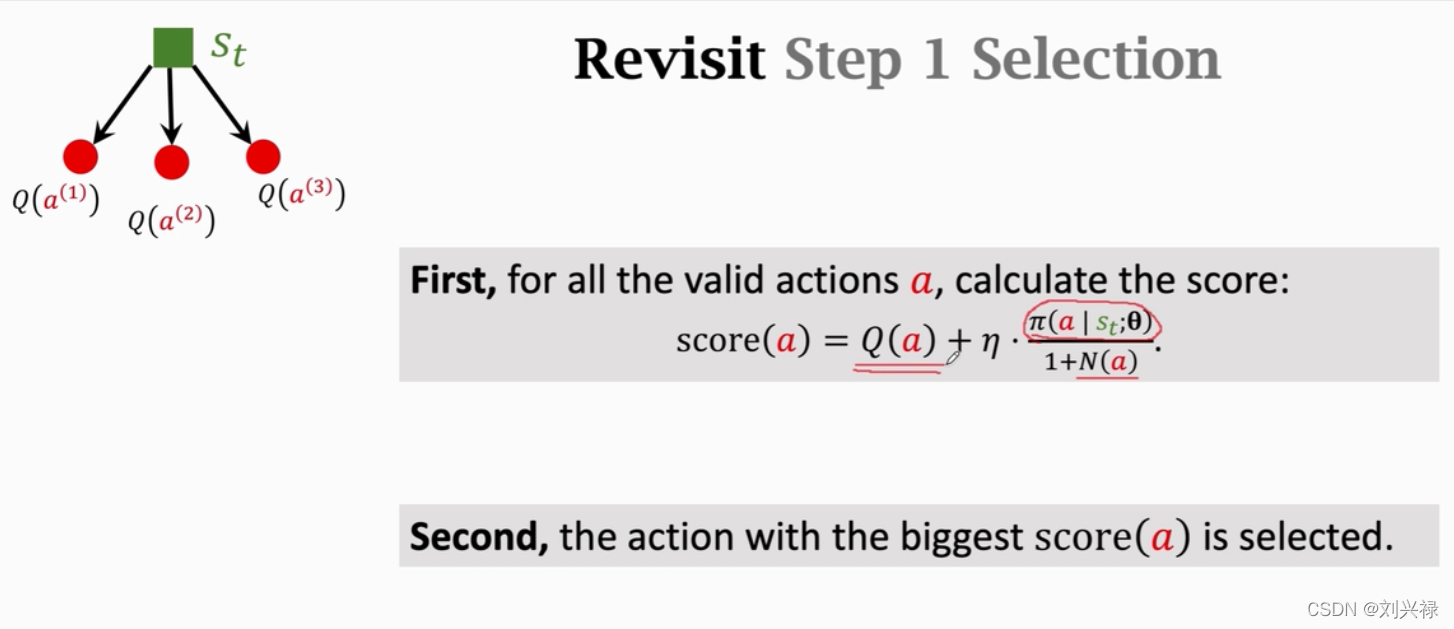
Mente Carlo Tree Search

















魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)