python-sklearn-聚类分析kmeans
【代码】python-sklearn-聚类分析kmeans。
·
聚类分析kmeans
#数据格式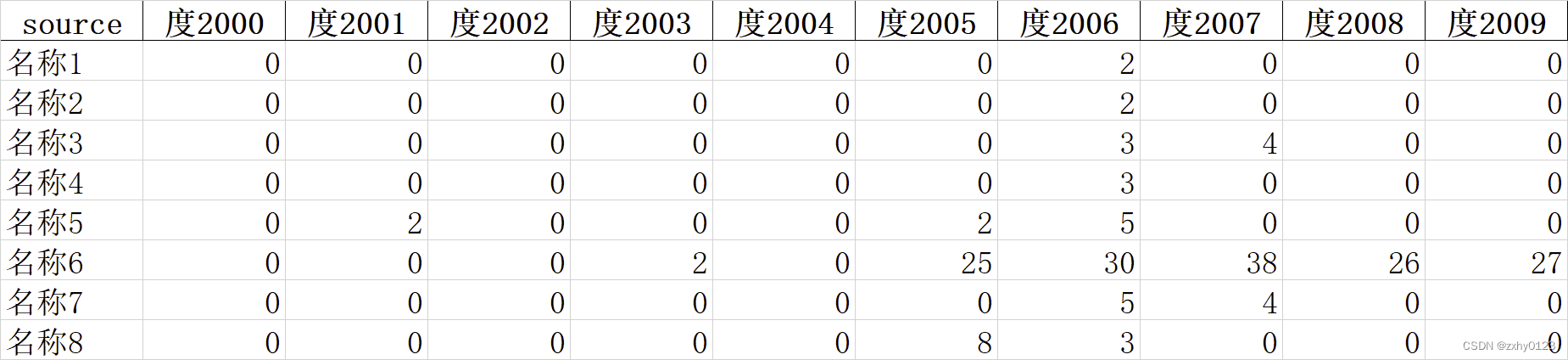
# -- coding: utf-8 --**
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram,linkage
import xlrd as xr
import pandas as pd
from sklearn import preprocessing
from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import KMeans
data23=pd.read_excel('历年节点度指标合并.xlsx',sheet_name='节点度指标',index_col='source')
row23=data23.iloc[:,0].size
# 设置为4个聚类中心
Kmeans = KMeans(n_clusters=4)
# 训练模型
Kmeans.fit(data23)
#获取聚类中心
Kmeans.cluster_centers_
#获取类别
leibie=Kmeans.labels_
# print(leibie)
leibie=pd.DataFrame(leibie)
leibie= leibie.rename(columns={0:'聚类类别'})
# print(leibie)
writer = pd.ExcelWriter('聚类类别.xlsx', engine='xlsxwriter',options={'strings_to_urls': False})
leibie.to_excel(writer, "聚类类别", index=False)
writer.save()
# print(len(leibie))
# #获取每个点到聚类中心的距离和
# Kmeans.inertia_
#插入数据
data23=pd.read_excel('历年节点度指标合并.xlsx',sheet_name='节点度指标')
leibie=pd.read_excel('聚类类别.xlsx',sheet_name='聚类类别')
row2=leibie.iloc[:,0].size
data23['聚类类别']=''
for i in range(row2):
data23.iloc[i,23]=leibie.iloc[i,0]
writer = pd.ExcelWriter('历年节点度指标聚类分析.xlsx', engine='xlsxwriter',options={'strings_to_urls': False})
data23.to_excel(writer, "节点度指标", index=False)
writer.save()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)