【小白也能看懂】YOLOv5 + VOC2012 超详细环境配置与模型训练教程(含数据集转换)
本教程将手把手带你完成YOLOv5从环境搭建到模型训练的全过程,针对VOC2012数据集进行详细说明。教程面向零基础学习者,每个步骤都包含详细说明和验证方法。
🔍 适合人群:想学习YOLOv5目标检测的零基础新手
🧰 实验系统:Windows 10 / 11 + Miniconda
📁 项目路径:D:/yolov5_project
📦 数据集:Pascal VOC 2012
✅ 实现目标:成功完成YOLOv5模型训练
一、前期准备概览(必看)
在开始配置环境和训练模型前,我们需要准备以下内容:
| 项目 | 说明 |
|---|---|
| ✅ Miniconda | Python 虚拟环境管理,推荐使用 Python 3.8 |
| ✅ YOLOv5 官方代码 | 使用 Ultralytics 提供的最新版 YOLOv5 |
| ✅ VOC2012 数据集 | 图像识别经典数据集,共20类 |
| ✅ 数据格式转换 | 将VOC格式数据转换为YOLO格式 |
| ✅ 配置文件修改 | 修改YOLOv5中的数据配置文件,指向本地数据集 |
二、安装与环境配置(非常详细)
2.1 安装 Miniconda(Python管理神器)
- 推荐版本:Miniconda3 + Python 3.8
- 下载地址(64位 Windows):
👉 https://repo.anaconda.com/miniconda/Miniconda3-py38_4.12.0-Windows-x86_64.exe
安装步骤:
- 双击安装包,点击 Next
- 勾选 “Add Miniconda to my PATH environment variable”
- 安装完成后,打开 命令提示符 CMD,输入以下命令检查是否生效:
conda --version
⚠️ 出现版本号如
conda 4.12.0即为成功!
可以参考这篇文章见详细步骤:miniconda安装
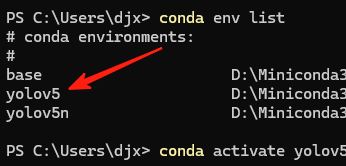
2.2 创建YOLOv5专属环境
ps:如果开着vpn,创建环境的时候记得关闭一下,不然会出现**CondaSSLError: Encountered an SSL error**
#逐条运行
conda create -n yolov5 python=3.8 -y
conda activate yolov5
2.3 下载YOLOv5官方代码
cd D:/yolov5_project
git clone https://github.com/ultralytics/yolov5.git
进入代码目录:
cd yolov5
2.4 安装PyTorch(CPU版本示例)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
✅ 验证安装是否成功:
python -c "import torch; print(f'PyTorch版本: {torch.__version__}, 设备: {torch.device(\"cpu\")}')"
输出示例:
PyTorch版本: 2.4.1+cpu, 设备: cpu
2.5 安装YOLOv5依赖
pip install -r requirements.txt
完整安装流程示例
# 1. 创建并激活环境
conda create -n yolov5 python=3.8
conda activate yolov5
# 2. 安装PyTorch CPU版
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 3. 安装YOLOv5其他依赖
cd D:\yolov5_project\yolov5
pip install -r requirements.txt
# 4. 验证
python -c "import torch; print(f'PyTorch版本: {torch.__version__}, 设备: {torch.device('cpu')}')"
三、准备VOC2012数据集并转换格式
3.1 下载VOC2012数据集
下载地址(约2GB):
👉 http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
将其解压到:
D:/yolov5_project/VOC2012/
3.2 创建转换脚本(VOC → YOLO)
创建文件:D:/yolov5_project/voc_to_yolo.py
粘贴以下完整代码 👇
import os
import xml.etree.ElementTree as ET
import shutil
# 配置路径(按你的实际路径修改!)
VOC_ROOT = "D:/yolov5_project/VOC2012" # 原始VOC路径
YOLO_ROOT = "D:/yolov5_project/VOC2012_YOLO" # YOLO格式输出路径
# VOC类别列表(20类)
CLASSES = [
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
]
# 创建YOLO目录结构
os.makedirs(f"{YOLO_ROOT}/images/train", exist_ok=True)
os.makedirs(f"{YOLO_ROOT}/images/val", exist_ok=True)
os.makedirs(f"{YOLO_ROOT}/labels/train", exist_ok=True)
os.makedirs(f"{YOLO_ROOT}/labels/val", exist_ok=True)
# 从XML转换为YOLO格式标签
def convert_annotation(xml_file):
tree = ET.parse(f"{VOC_ROOT}/Annotations/{xml_file}")
root = tree.getroot()
w = int(root.find('size/width').text)
h = int(root.find('size/height').text)
txt_file = xml_file.replace('.xml', '.txt')
with open(f"{YOLO_ROOT}/labels/train/{txt_file}", 'w') as f:
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in CLASSES:
continue
cls_id = CLASSES.index(cls)
bbox = obj.find('bndbox')
xmin = float(bbox.find('xmin').text)
xmax = float(bbox.find('xmax').text)
ymin = float(bbox.find('ymin').text)
ymax = float(bbox.find('ymax').text)
# 转换为YOLO格式(归一化中心坐标和宽高)
x_center = (xmin + xmax) / 2 / w
y_center = (ymin + ymax) / 2 / h
width = (xmax - xmin) / w
height = (ymax - ymin) / h
f.write(f"{cls_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
# 复制图像并划分训练集/验证集
def copy_and_split():
# 读取VOC官方划分文件
def read_split(file):
with open(f"{VOC_ROOT}/ImageSets/Main/{file}", 'r') as f:
return [line.strip() for line in f.readlines()]
train_files = read_split("train.txt") # 训练集文件名列表(无后缀)
val_files = read_split("val.txt") # 验证集文件名列表(无后缀)
# 处理训练集
for file_name in train_files:
# 复制图像
shutil.copy(
f"{VOC_ROOT}/JPEGImages/{file_name}.jpg",
f"{YOLO_ROOT}/images/train/{file_name}.jpg"
)
# 生成标签(已在convert_annotation中处理)
# 处理验证集
for file_name in val_files:
shutil.copy(
f"{VOC_ROOT}/JPEGImages/{file_name}.jpg",
f"{YOLO_ROOT}/images/val/{file_name}.jpg"
)
# 移动标签到val目录
shutil.move(
f"{YOLO_ROOT}/labels/train/{file_name}.txt",
f"{YOLO_ROOT}/labels/val/{file_name}.txt"
)
# 生成train.txt和val.txt路径列表
with open(f"{YOLO_ROOT}/train.txt", 'w') as f:
for file_name in train_files:
f.write(f"{YOLO_ROOT}/images/train/{file_name}.jpg\n")
with open(f"{YOLO_ROOT}/val.txt", 'w') as f:
for file_name in val_files:
f.write(f"{YOLO_ROOT}/images/val/{file_name}.jpg\n")
# 执行转换和划分
if __name__ == "__main__":
# 第一步:转换所有XML标签到YOLO格式(暂存到labels/train)
for xml_file in os.listdir(f"{VOC_ROOT}/Annotations"):
if xml_file.endswith('.xml'):
convert_annotation(xml_file)
# 第二步:划分训练集/验证集
copy_and_split()
print("转换和划分完成!")
3.3 运行脚本转换数据
cd D:/yolov5_project
python voc_to_yolo.py
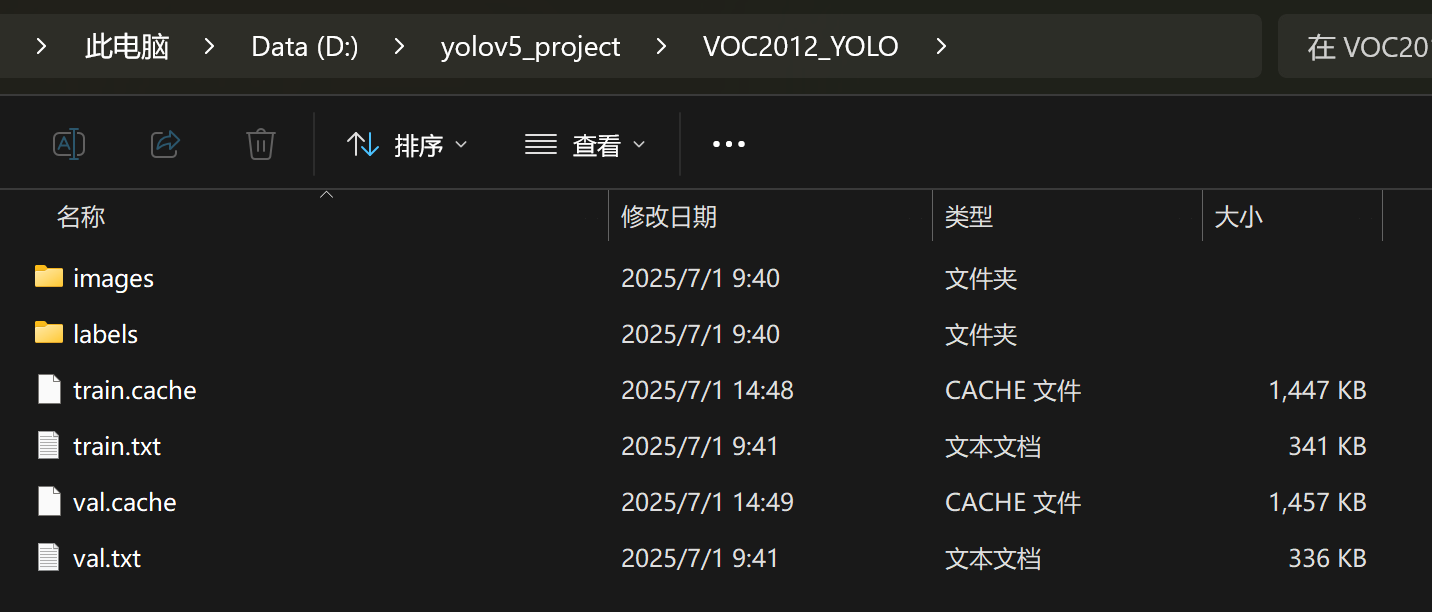
运行成功后,会生成以下文件夹结构:
VOC2012_YOLO/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
├── train.txt
├── val.txt
四、修改YOLOv5配置文件
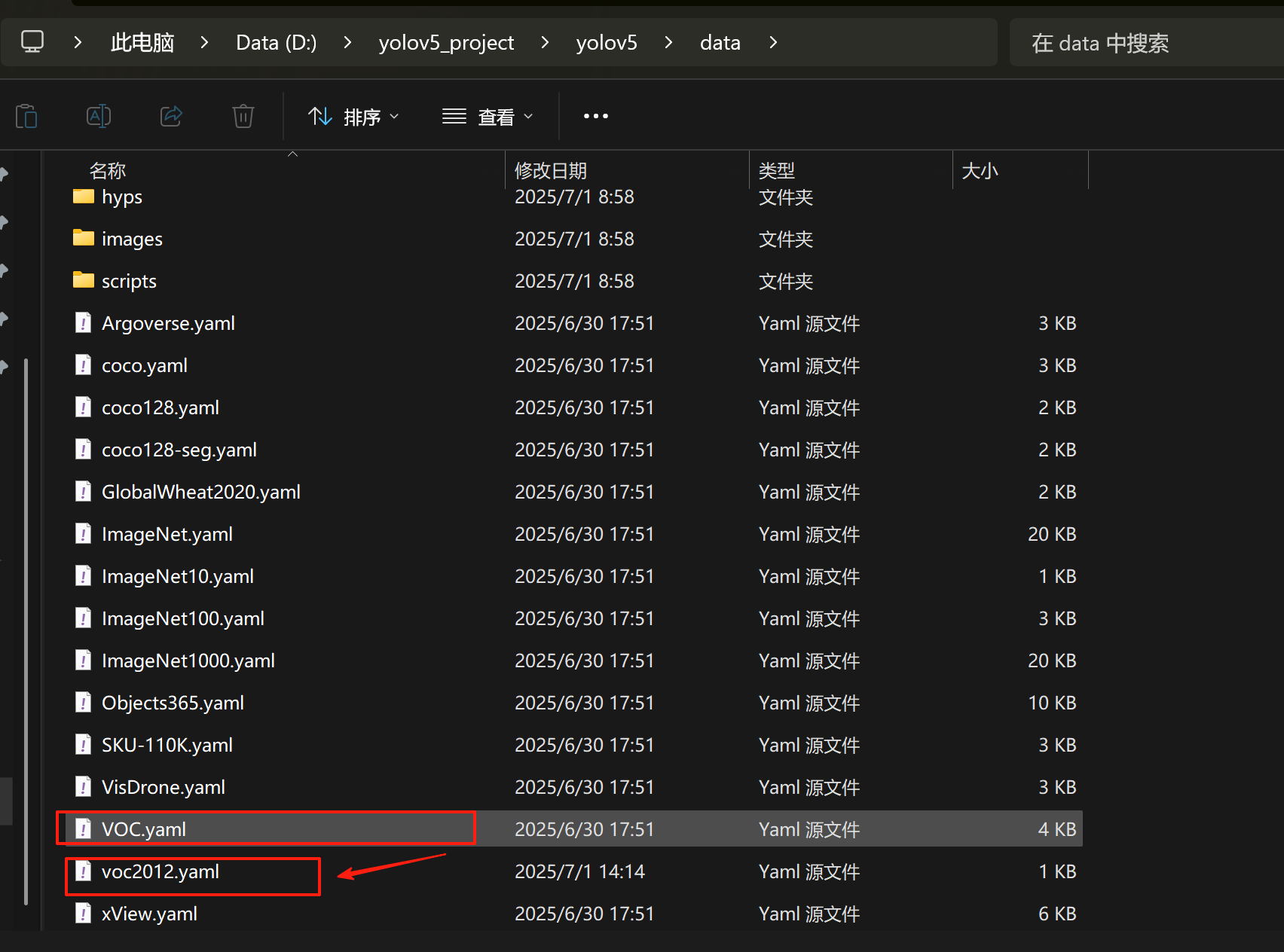
进入:
D:/yolov5_project/yolov5/data
复制一份 VOC.yaml,重命名为 voc2012.yaml
用文本编辑器(txt或者VScode)打开 voc2012.yaml,修改为以下内容:
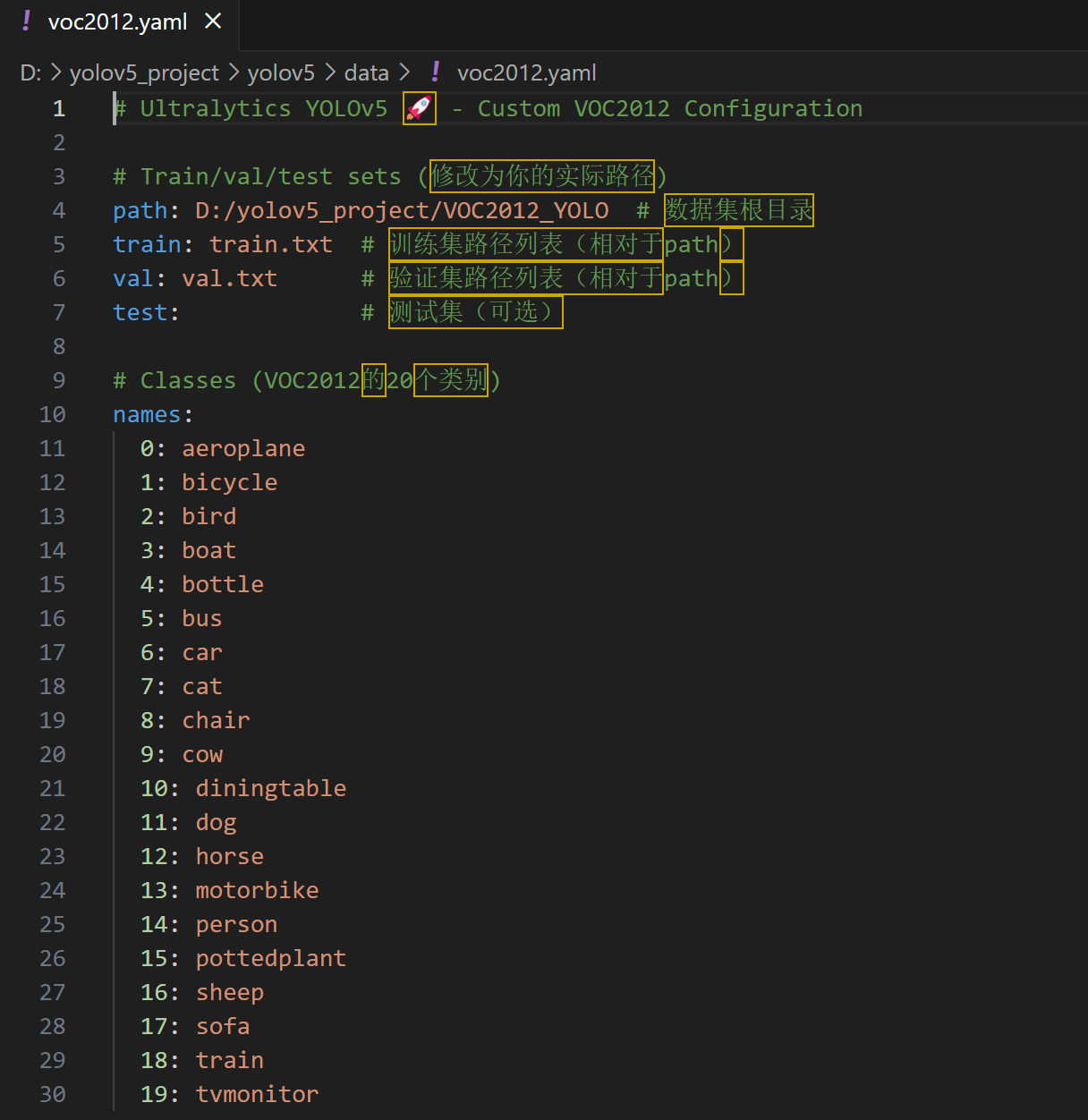
# Ultralytics YOLOv5 🚀 - Custom VOC2012 Configuration
path: D:/yolov5_project/VOC2012_YOLO
train: train.txt
val: val.txt
test:
names:
0: aeroplane
1: bicycle
2: bird
3: boat
4: bottle
5: bus
6: car
7: cat
8: chair
9: cow
10: diningtable
11: dog
12: horse
13: motorbike
14: person
15: pottedplant
16: sheep
17: sofa
18: train
19: tvmonitor
准备好了所有文件,就要开始训练模型了
五、开始训练YOLOv5模型!
确保你当前在conda环境下的 YOLOv5 目录下(也就是 (yolov5)D:/yolov5_project/yolov5):
python train.py --data data/voc2012.yaml --cfg models/yolov5n.yaml --weights yolov5s.pt --batch-size 4 --epochs 50 --device cpu --imgsz 224 --workers 0 --noautoanchor --cache ram --hyp data/hyps/hyp.scratch-low.yaml
以下是该 YOLOv5 训练命令的参数说明表格:
| 参数 | 值 | 说明 |
|---|---|---|
--data |
data/voc2012.yaml |
数据集配置文件路径,指定训练数据的路径、类别等信息(这里是 PASCAL VOC 2012 数据集)。 |
--cfg |
models/yolov5n.yaml |
模型结构配置文件,指定 YOLOv5 的网络架构(这里使用 yolov5n,即 nano 版)。 |
--weights |
yolov5s.pt |
预训练权重文件,用于迁移学习(这里使用 yolov5s.pt 的权重初始化模型)。 |
--batch-size |
4 |
每个批次的样本数量(batch size),这里设为 4(通常 GPU 训练会更大,如 16、32)。 |
--epochs |
50 |
训练的总轮数(epochs),这里设为 50 轮。 |
--device |
cpu |
训练设备,这里使用 CPU(如果是 GPU,可设为 0 或 cuda:0)。 |
--imgsz |
224 |
输入图像的尺寸(height × width),这里设为 224×224(默认通常是 640×640)。 |
--workers |
0 |
数据加载的线程数(DataLoader workers),设为 0 表示仅使用主线程(适用于调试或 CPU)。 |
--noautoanchor |
(无值) | 禁用自动计算 anchor 功能,使用默认的 anchor 尺寸。 |
--cache |
ram |
缓存数据集到 RAM 以加速训练(可选 ram / disk / False)。 |
--hyp |
data/hyps/hyp.scratch-low.yaml |
超参数配置文件,用于调整学习率、数据增强等(这里使用 scratch-low.yaml 低资源训练配置)。 |
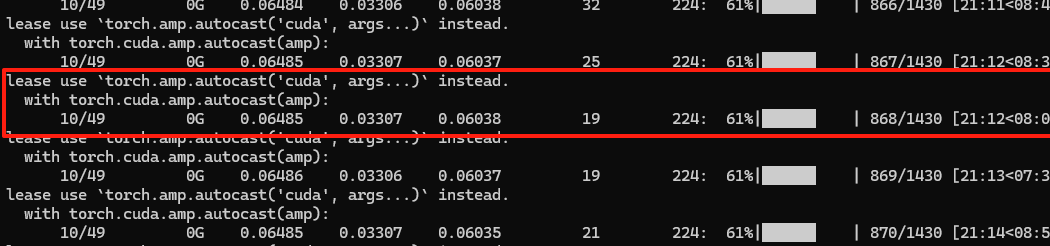
这是正在训练的模型,训练过程中的关键数值
10/49 0G 0.06485 0.03307 0.06038 19 224
这些数值从左到右分别是:
10/49- 当前 epoch / 总 epochs
- 示例:第 10 轮,共 49 轮。
0G- GPU 显存占用(单位:GB)
- 这里显示为0是因为我的电脑没有GPU
0.06485- 当前 batch 的损失(loss)
- 模型在当前 batch 计算出的损失值(如分类+检测的联合损失)。
0.03307- 移动平均损失(smooth loss)
- 对历史 batch 损失值的指数滑动平均(EMA),用于观察整体趋势。
0.06038- 验证集损失(val_loss)或其他指标
- 如果在训练中插入了验证步骤,可能是验证集损失;否则可能是其他指标(如 mAP@0.5)。
19- 当前 batch 的大小(batch size)
- 实际处理的样本数(可能因数据集大小不整除而调整)。
224- 输入图像的尺寸(height/width)
- 图像被缩放到
224x224像素(常见于分类或小目标检测)。
六、使用训练好的 YOLOv5 模型进行推理
你的训练结果保存在 D:\yolov5_project\yolov5\runs\train\exp 中,检查以下文件是否存在:
weights/best.pt:最佳模型权重文件(主要使用这个)。weights/last.pt:最后一次训练的权重文件。
YOLOv5 提供了 detect.py 脚本,可以直接调用训练好的模型进行检测。以下是具体步骤:
命令格式:
python detect.py --weights <模型路径> --source <输入数据路径> --conf <置信度阈值> --img-size <图像尺寸>
具体示例:
假设你想检测 D:\yolov5_project\VOC2012_YOLO\images 中的图像,运行以下命令:
cd D:\yolov5_project\yolov5
python detect.py --weights runs/train/exp3/weights/best.pt --source ../VOC2012_YOLO/images --conf 0.25 --img-size 640

参数说明:
--weights:指定训练好的模型权重路径(如best.pt)。--source:输入数据路径,可以是:- 单张图片(如
../test.jpg) - 文件夹(如
../VOC2012_YOLO/images) - 视频文件(如
../video.mp4) - 摄像头(如
0表示默认摄像头)
- 单张图片(如
--conf:置信度阈值(默认 0.25,可根据需求调整)。--img-size:输入图像的尺寸(默认 640,与训练时一致即可)。
检测完成后,结果会保存在:
D:\yolov5_project\yolov5\runs\detect\exp<序号>
原图
训练结果
七、总结与常见问题
1. Q: train.txt 路径写绝对路径还是相对路径?
A: 在 YAML 中路径是 相对于
path:配置项的目录。
2. Q: VOC转YOLO格式一定要自己写脚本吗?
A: 推荐自己写,可以掌握底层逻辑,当然也有现成的转换工具。
3. Q: CPU太慢怎么办?
A: 建议使用 Google Colab 或本地带 GPU 的机器。
🌟结语
本文从零开始,带你完整体验YOLOv5目标检测训练流程。如果你认真跟着做,一定可以收获一份属于自己的检测模型!
欢迎收藏、点赞、评论!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)