java openxml 操作 word,(三)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之html转word...
(三)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之html转word系列笔记传送门富文本转word文档准备待转换内容内容清理与格式化转换成word文档输出结果展示附加内容、常见错误结束语系列笔记传送门本系列笔记包含以下几篇,本篇主要是吹牛、理论、外加做个目录,等不及的可以直接传送门起飞:(一)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之基础篇(二)、
(三)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之html转word
系列笔记传送门
富文本转word文档
准备待转换内容
内容清理与格式化
转换成word文档
输出结果展示
附加内容、常见错误
结束语
系列笔记传送门
本系列笔记包含以下几篇,本篇主要是吹牛、理论、外加做个目录,等不及的可以直接传送门起飞:
(一)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之基础篇
(二)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之基础篇-图片在word结构中的存放、插入、替换图片
(三)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之html转word
(四)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之word转html(待更新…)
(五)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之word文件合并(待更新…)
(六)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之动态模板、占位符(待更新…)
(七)、JAVA基于OPENXML的word文档插入、合并、替换操作系列之模板综合应用、文字、图片、富文本内容填充(待更新…)
富文本转word文档
我们经常会遇到在项目中,需要将一段内容输出到word、 比如通过在你的项目中放一个富文本编辑器,通过用户的输入提交后,将它做一些处理之后这个内容生成一个word文档,然后提供用户下载使用,或者用户上传一个word文档,需要在你项目的界面上显示出来,那么这篇笔记或许可以帮到你, 当然这只是其中一个实现方案,网上有许多其他实现方案不在此做探讨
准备待转换内容
我们先来准备一段富文内容,通过OPENXML转成word需要一个完整的html格式文档,比如有不支持属性的、属性有单引号、没有引号的等各种不标准的HTML代码,在处理过程中会出错,或者被忽略掉。
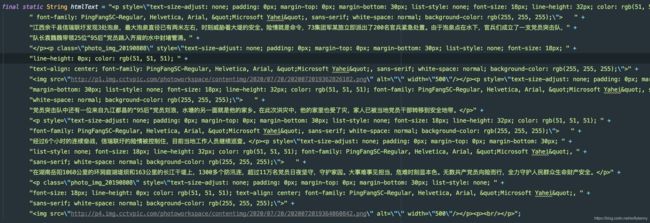
内容清理与格式化
此处我们通过借助 Jsoup来将html转为 xhtml ,操作之后html代码段就会被格式化属性="属性值" 这种标准的格式,当然还有更多其他效果,具体请自行动手体验。
public String cleanHtmlQuot(String htmlContent){
if(StringUtils.isBlank(htmlContent))
return htmlContent;
// 这步是将html代码中转义的代码进行恢复, 从富文编辑提交过来的内容,会进行一个特殊字符转义
// 去除本地图片(file://)或地址为空的图片,(?i)不区分大小写, 我的代码中去掉了,你可以不要
String unescape = StringEscapeUtils.unescapeHtml4(htmlContent)
.replaceAll("(?i)","");
return Jsoup.clean(unescape, user_content_filter)
.replace("windowtext","#000"); //windowtext 不识别,改成 #000
}
/**
* html 格式化,转成标准的 xhtml 格式
* 1px=0.75pt,常见的宋体9pt=12px pt=px乘以3/4。
* 1mm约等于2.83pt,A4尺寸是21cm*29.7cm,所以应该是594.3pt*840.51pt
* @param html
* @return
*/
public String html2xhtml(String html){
final Document htmldoc = Jsoup.parse( this.cleanHtmlQuot(trimNull(html)));
htmldoc.outputSettings().syntax(Document.OutputSettings.Syntax.xml).escapeMode(Entities.EscapeMode.xhtml);
return htmldoc.html();//.replaceAll("(?i)( )|( )"," ");
}
格式化后的效果是这样的, 没有它都给自动加上了
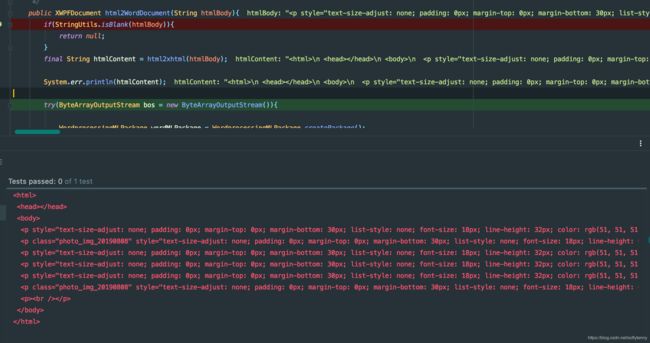
转换成word文档
此处通过 DOCX4J 将html内容转成POI的XWPFDocument对象,然后直接输出为word文档.
/**
* @param htmlBody
* @return
*/
public XWPFDocument html2WordDocument(String htmlBody){
if(StringUtils.isBlank(htmlBody)){
return null;
}
final String htmlContent = html2xhtml(htmlBody);
try(ByteArrayOutputStream bos = new ByteArrayOutputStream()){
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage();
XHTML2WordImporterImpl XHTMLImporterImpler = new XHTML2WordImporterImpl(wordMLPackage);
// XHTMLImporterImpler.setXHTMLImageHandler(new XHTML2WordImageHandler(XHTMLImporterImpler));
// 延迟解析比率 ,解决报错: java.io.IOException: Zip bomb detected!
// 参考 https://stackoverflow.com/questions/46796874/java-io-ioexception-failed-to-read-zip-entry-source
ZipSecureFile.setMinInflateRatio(-1.0d);
wordMLPackage.getMainDocumentPart().getContent().addAll(XHTMLImporterImpler.convert(htmlContent,""));
wordMLPackage.save(bos);
// logger.info("tmpFile:{}", tmpFile.getAbsolutePath());
// wordMLPackage.save(new File("/Users/tenney/Desktop/word.docx"));
return verifyContent4MSOffice(new XWPFDocument(new ByteArrayInputStream(bos.toByteArray())));
} catch (Exception e) {
logger.error("解析HTML为WORD内容出错:{}", e.getMessage(), e);
}
return null;
}
@Test
public void html2Word() throws IOException {
WrodPlaceholderProcessor processor = new WrodPlaceholderProcessor(null,null,null);
long start = System.currentTimeMillis();
// XWPFDocument doc = processor.html2DOCXDocument(htmlText);
// System.err.println(processor.cleanHtmlQuot(htmlText));
XWPFDocument doc = processor.html2WordDocument(htmlText);
System.err.println(doc.getDocument().getBody().xmlText());
FileOutputStream dest = new FileOutputStream(new File("/Users/tenney/Desktop/2222222222.docx"));
// document.write(dest);
doc.write(dest);
// IOUtils.closeQuietly(dest);
System.err.println("用时:"+ (System.currentTimeMillis() - start) + " ms");
}
输出结果展示
转换过程会生成一个符合OPENXML规范的内容,如下
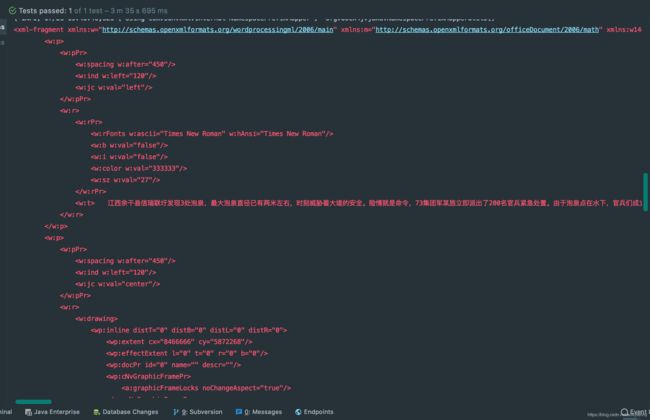
附加内容、常见错误
在我的实践过程中发现,转换表格时偶尔会出现,表格中转换出的行标签,却没有列内容引发报错,以下为我的解决方案,实现逻辑为:
在该行中创建一个列,并根据定义的列数进行列合并,最终目的其实就是转换为一个有效的空行。
/**
* 较验生成的内容是否符合微软office的格式要求
* @param document
* @return
*/
public XWPFDocument verifyContent4MSOffice(XWPFDocument document){
//较验表格
/**
*
* * * ....
*
* *
*
*
*
*
*
*
*
* *
*
* // 该处没有 tc(column),将导致ms office打开报错
*
*
* *
*
* * *
*
*
* *
*
*
*
*
*
*
*
* *
*
*
*
* *
*/
// document.getDocument().getBody().getSectPr().getPgSz();
document.getDocument().getBody().getTblList().forEach(tbl->{
// tbl.getTblPr().getTblW().setW(BigInteger.valueOf(2000));
// tbl.getTblPr().getTblW().setType(STTblWidth.DXA);
// tbl.getTblPr().addNewTblStyle().setVal("StyledTable");
CTTblGrid grid = tbl.getTblGrid();
List rows = tbl.getTrList();
try{
rows.forEach(row->{
if(row.getTcList() == null || row.getTcList().isEmpty()){
CTTc tc= row.addNewTc();
tc.addNewP().addNewR().addNewT();
if(grid != null){
CTTcPr pr = tc.addNewTcPr();
pr.addNewGridSpan().setVal(BigInteger.valueOf(grid.getGridColList().size()));
tc.setTcPr(pr);
}
}
});
}catch (Exception e){
logger.warn("较验文档内容有效性出错:{}", e.getMessage());
}
});
return document;
}
结束语
网上其实有很多html转成word的方法,鄙人也看过很多,比如直接通过POI实现的,甚至有手动逐个解析word中每个元素,比如图片、表格、段落等等然后再逐一用html代码拼出来的,当然这些方法我也用过,只是未能达到我的目的,要么转换的效果不够好,要么转换不完整,所以经过我长时间的折腾拼凑出这么一个方法,虽然也算不上很完美,但在我见过的方法中应该算是比较好用的了,唠叨这么一段只是提示一点解决问题的思路,方法千千万,每个方法也有每个方法特色和应用场景,找到适合自己的就是最完美的!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)