从零开始的Elasticsearch学习-springboot整合Elasticsearch(响应式)
本文介绍springboot整合Elasticsearch,响应式api的演示。官方文档和api手册官网查看不同版本更改springboot 整合 es 非响应式学习Spring WebFlux可以进行异步和非阻塞的I/O操作------->适用于处理大量的并发请求Spring WebFlux可以使用Flux和Mono等响应式类型来处理数据流------->适用于构建实时数据处理和事件驱动的应用当
从零开始的Elasticsearch学习-springboot整合Elasticsearch(响应式)
一、前言
本文介绍springboot整合Elasticsearch,响应式api的演示。
二、环境准备
2.1环境配置
本文演示使用的springboot版本:2.5.1(对应的spring-data-elasticsearch为4.2.1)
elasticsearch版本:7.5.0 elasticsearch安装教程
kibana版本:7.5.0
使用swagger或postman发送请求测试接口(本文使用swagger)
2.2版本对应关系
spring-data-elasticsearch和elasticsearch版本对应:官网查看
一般情况:
- Spring Data Elasticsearch 5.x 系列通常与 Elasticsearch 8.x 版本兼容。
- Spring Data Elasticsearch 4.x 系列通常与 Elasticsearch 7.x 版本兼容。
- Spring Data Elasticsearch 3.x 系列通常与 Elasticsearch 6.x 版本兼容。
- Spring Data Elasticsearch 2.x 系列通常与 Elasticsearch 5.x 版本兼容。
出现问题就按官网版本对应配置
三、Maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- Spring WebFlux (响应式Web) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
需要spring-data-es和响应式web支持
四、配置
4.1application.yml配置
spring:
data:
elasticsearch:
client:
reactive: # 响应式Elasticsearch客户端配置
username: docker-cluster # Elasticsearch的用户名
password: # Elasticsearch的密码(此处为空,需要填写实际密码)
endpoints: # Elasticsearch集群的节点地址列表
- node_ip:9200
- node1_ip:9200
- node_ip:9201
4.2java代码配置
这里我们学习一下springboot对es的自动配置,照葫芦画瓢
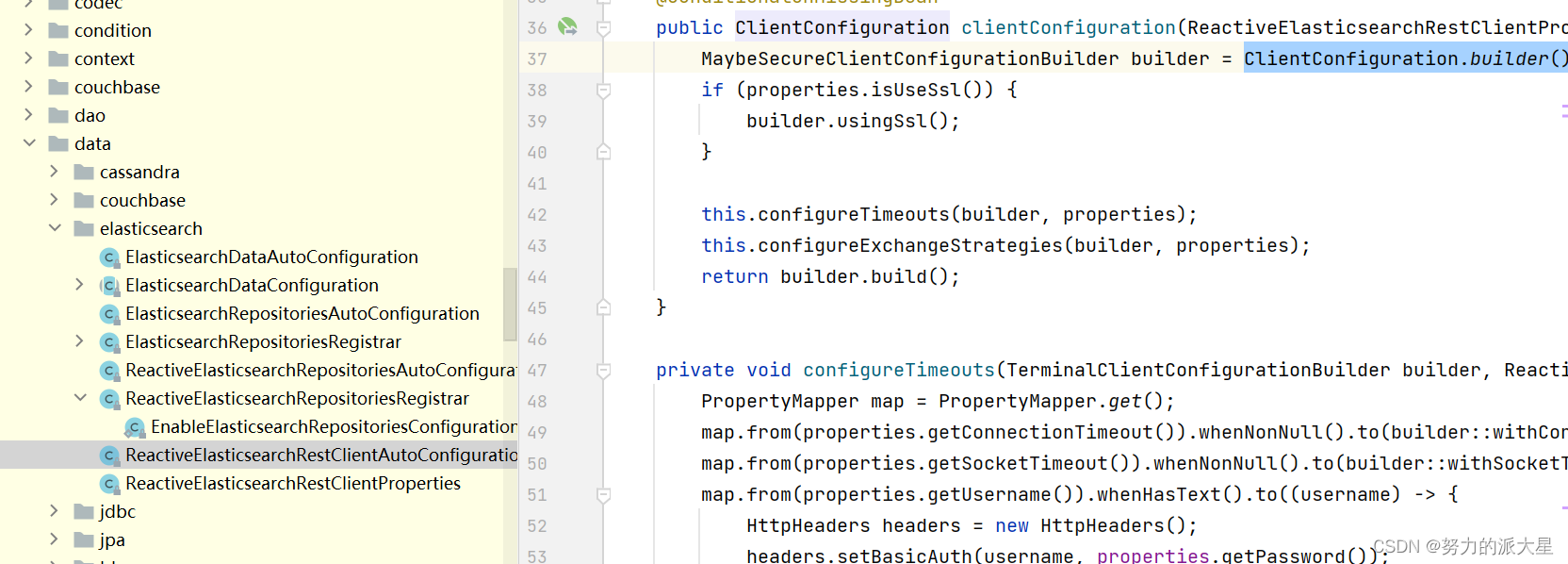
@Configuration
@EnableReactiveElasticsearchRepositories(basePackages = "com.xj.demo.repository")
public class ReactiveElasticsearchConfig {
@Bean
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("node1_ip:9200","node2_ip:9200","node3_ip:9200")
.build();
}
@Bean
public ReactiveElasticsearchClient reactiveElasticsearchClient(ClientConfiguration clientConfiguration) {
return ReactiveRestClients.create(clientConfiguration);
}
//配置ReactiveElasticsearchTemplate模板,这里为了方便就直接复制AbstractReactiveElasticsearchConfiguration默认的
//如果是继承AbstractReactiveElasticsearchConfiguration的方式可以不用配置,如果要配置就重写下列方法
@Bean
public ReactiveElasticsearchOperations reactiveElasticsearchTemplate(ElasticsearchConverter elasticsearchConverter, ReactiveElasticsearchClient reactiveElasticsearchClient) {
ReactiveElasticsearchTemplate template = new ReactiveElasticsearchTemplate(reactiveElasticsearchClient, elasticsearchConverter);
template.setIndicesOptions(this.indicesOptions());
template.setRefreshPolicy(this.refreshPolicy());
return template;
}
@Nullable
protected RefreshPolicy refreshPolicy() {
return null;
}
@Nullable
protected IndicesOptions indicesOptions() {
return IndicesOptions.strictExpandOpenAndForbidClosed();
}
}
解释:@EnableReactiveElasticsearchRepositories:启用对响应式Elasticsearch仓库的支持,
basePackages属性用于指定扫描响应式Elasticsearch仓库接口的基础包路径,类似mybatis的@MapperScan如果非响应式已经配置了clientConfiguration,可以共用一个bean,这里就不用再配置clientConfiguration
这里也可以继承AbstractReactiveElasticsearchConfigurationl类重写reactiveElasticsearchClient方法来配置 。
相比于yml配置,在代码中配置可以可以更加详细。
五、Spring WebFlux
简单学习下几个概念,以便于下面的学习,详细学习官网地址:Spring WebFlux
5.1 Spring WebFlux概念
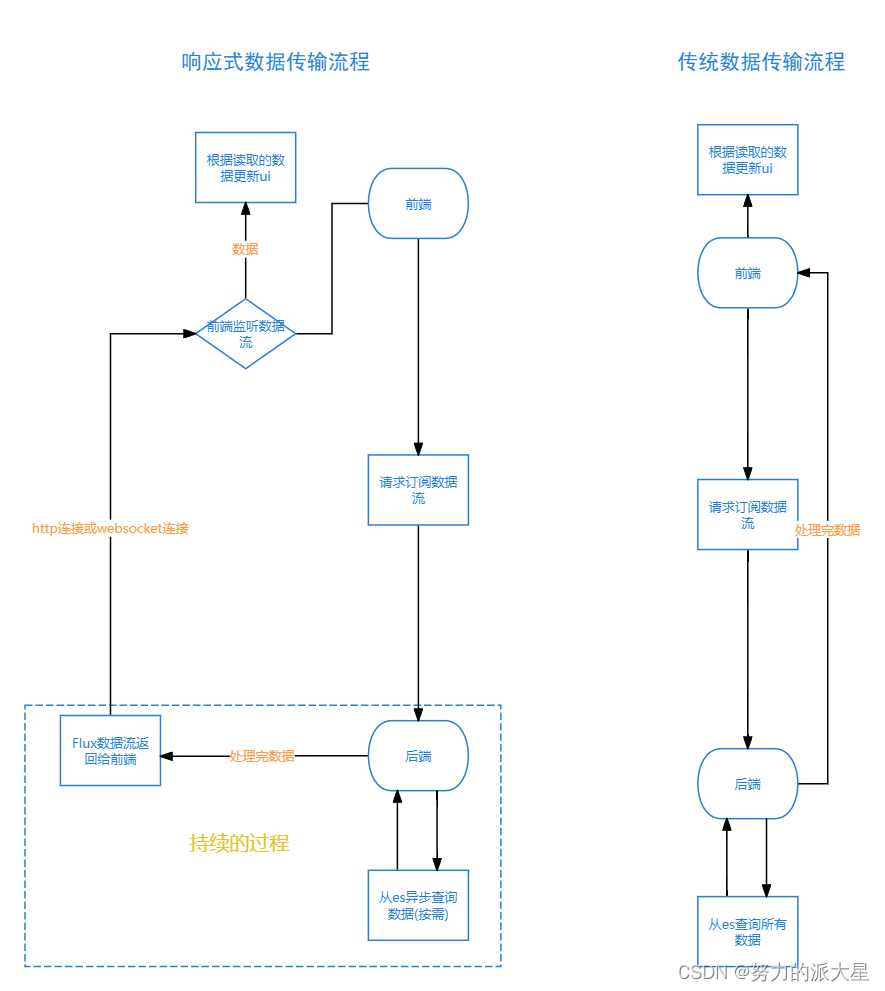
响应式编程和异步非阻塞的Web开发,与传统的spring mvc同步阻塞对应。
通俗讲:响应式编程就是通过数据流的方式返回数据给前端,数据流就是可以一部分一部分的发数据,非响应式就是一下把前端所需要的全部数据发过去。
5.2 spring webFlux下的类:Flux和Mono
Flux
Flux是Publisher的一个实现,它代表了一个可以发射多个值的响应式流。Flux可以发射多个事件,也可以发射错误或完成信号。它允许操作者对事件序列进行处理,如过滤、映射、合并等。Flux是冷数据流(cold stream),意味着它不会立即发射数据,而是在有订阅者订阅时才开始发射数据。
Mono
Mono也是Publisher的一个实现,但它专门用于发射最多一个值的响应式流。Mono适用于那些只返回单个结果的操作,例如数据库查询或异步计算。如果操作成功,Mono会发射一个单一的值和一个完成信号;如果操作失败,它会发射一个错误信号。
解释:它们扮演下面数据流的角色,由它们管理数据发给消费者。
5.3 响应式编程中的几个角色
生产者 (Publishers)
在Spring WebFlux中,生产者是指产生数据流的实体。这些生产者通常是后端服务中的组件,它们负责从数据源(如数据库、文件系统、外部API等)检索数据,并将数据封装成响应式流。具体来说:
- Controller:在WebFlux中,控制器通过调用业务逻辑和数据访问层的方法来处理HTTP请求,并返回
Mono或Flux对象。控制器充当生产者的角色,因为它产生了响应的数据流。 - Service Layer:服务层组件通常包含业务逻辑和数据访问逻辑。它们通过与数据库交互、调用外部服务或执行复杂计算来产生数据流。
- Reactive Repository:使用Spring Data Reactive库时,仓库接口定义了数据访问操作,它们通过返回
Mono或Flux来生产数据流。
消费者 (Subscribers)
消费者是指订阅并消费数据流的实体。在WebFlux应用程序中,消费者通常是前端客户端,但也可以是其他服务或应用程序。具体来说:
- 前端应用:前端应用通过HTTP请求订阅后端服务提供的
Mono或Flux数据流,并消费数据以更新UI或进行其他处理。 - 其他服务:在微服务架构中,一个服务可能会订阅另一个服务提供的
Mono或Flux数据流,以便进行进一步的处理或集成。
数据流 (Data Streams)
数据流是指在生产者和消费者之间传输的数据序列。在Spring WebFlux中,数据流通常是响应式的,并且可以通过Flux或Mono对象来表示。具体来说:
- Flux:表示一个可以发射多个值的数据流。在WebFlux中,
Flux通常用于处理可能返回多个数据项的场景,如列表数据、分页结果或实时数据流。 - Mono:表示一个最多只能发射一个值的数据流。
Mono用于处理单个数据项的查询结果或异步操作的结果。
解释:可以假设生产者是厨师,数据源是服务员,消费者是客人,数据是菜,客人点了很多菜。
非响应式编程:没有服务员,厨师做完全部菜品再端给客人,客人等了很久,后面还需要花很多时间吃菜
响应式编程:厨师每做一道菜,服务员端给客人,客人可以立即吃菜
5.4 spring mvc与springweflux
springmvc更适用于传统的Web应用程序,特别是那些主要涉及创建、读取、更新和删除(CRUD)操作的应用程序,适用于同步阻塞的Web应用。
springweflux有异步非阻塞特性,主要用于构建异步、非阻塞的响应式Web应用程序,更适用于需要处理大量并发请求、对性能要求较高的场景。
以请求elasticsearch服务为例
5.5 小知识
1.springweflux异步非阻塞体现在哪里
"异步"意味着一个操作的发起和完成是分开的,操作在后台进行,而不会立即得到结果。在这个操作完成之前,其他操作可以继续执行。在 WebFlux 中,这意味着当你发起一个数据库查询或发出一个 HTTP 请求时,你不需要等待这个操作完成就能继续执行后续的代码。当操作完成时,通常会有一个回调函数被调用,或者使用返回的数据流(如 Flux 或 Mono)来处理结果。
"非阻塞"意味着一个操作(通常是 I/O 操作)的发起不会挂起或阻塞调用它的线程。在传统的多线程模型中,如果线程发起了一个阻塞的操作(如网络请求或数据库访问),在该操作完成之前,线程会被挂起,无法执行其他任务。在非阻塞模型中,线程可以在发起操作后立即去执行其他任务,而不需要等待操作完成。
以从elasticsearch查数据为例,io(像网络操作和数据库访问等)操作是阻塞的,如果是以传统的方式查数据,比如要从elasticsearch服务器查一万条数据返回给前端,就要先全部查完,再把一万条数据加载到内存中处理(比如序列化等操作),最后全部返回。当前线程会一直等你查完,程序才能继续执行,这样就被阻塞了。而如果是响应式编程,首先线程不会等待数据查询而阻塞而是继续处理其他任务。一旦数据到达,系统会通过回调函数或事件触发的方式通知线程。
2.Flux和Mono类究竟干了什么,为什么要把数据封装到该类型里面返回
Flux和Mono的主要作用就是构建数据处理流,这个流就像管道一样,数据通过管道发送给前端,Flux和Mono可以控制数据的流速以及发生故障的情况。
把数据封装到Flux和Mono可以简单理解为把数据交给Flux或Mono处理,把一个整体的数据分割来处理和发送,数据像水流一样缓慢流向前端
3.需要什么网络协议来保持长时间的连接状态和持续发送数据过程
WebSockets或带有SSE机制的HTTP/2 ,都可以进行双向通信。
4.实时数据处理和数据按需加载
实时数据处理:Spring WebFlux适合构建需要实时数据处理和事件驱动的应用,例如聊天应用、实时数据仪表板等。
每当客户端请求新的数据批次时(例如,用户滚动到页面底部,触发加载更多网页信息),它会向Flux流请求下一个数据批次。Flux流会从Elasticsearch服务器中检索相应的数据,并将它们发送给客户端。客户端接收到数据后,会将其展示给用户。这个过程可以非常平滑,用户几乎感受不到延迟。
5.误区
spring webflux这种机制并不代表其性能更优,而是在高并发的情况下,在相同的服务器资源的情况下可以并发处理更多的请求。
5.6总结
Spring WebFlux可以进行异步和非阻塞的I/O操作------->适用于处理大量的并发请求
Spring WebFlux可以使用Flux和Mono等响应式类型来处理数据流------->适用于构建实时数据处理和事件驱动的应用
六、使用ReactiveElasticsearchTemplate模板
ReactiveElasticsearchTemplate是ReactiveElasticsearchOperations的默认实现。
我只用swagger测一下返回结果,这里如果没有前端代码,无法测试响应式接口,无法验证其是否按预期进行分批流式发送数据,可以编写一个简单的模拟前端应用程序,使用响应式库(如React或Vue.js with RxJS)来发起请求。可以控制前端的行为,包括请求的发送频率和数据的消费方式。
6.1 实体类EsBlog
@Data
@TypeAlias("blog")
@Document(indexName = "blog")
public class EsBlog {
@Id
private String id;
/**
* 博客类型
*/
@Field(type = FieldType.Keyword)
private Integer type;
/**
* 博客标题
*/
@Field(type = FieldType.Keyword)
private String title;
/**
* 博客简介
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String summary;
/**
* 博客内容
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
}
6.2 基本的增删改查
@ApiOperation(value = "添加或更新更新文档", notes = "使用提供的数据添加或更新文档")
@PutMapping("/saveAndUpdate")
public Mono<EsBlog> updateDocument(@RequestBody EsBlog esBlog) {
return reactiveElasticsearchTemplate.save(esBlog, IndexCoordinates.of("blog"));
}
@ApiOperation(value = "删除文档", notes = "根据唯一ID从Elasticsearch删除文档")
@DeleteMapping("/delete/{id}")
public Mono<String> deleteDocument(@PathVariable String id) {
return reactiveElasticsearchTemplate.delete(id, EsBlog.class);
}
@ApiOperation(value = "根据ID获取文档", notes = "根据唯一ID从Elasticsearch检索文档")
@GetMapping("/get/{id}")
public Mono<EsBlog> getDocument(@PathVariable String id) {
return reactiveElasticsearchTemplate.get(id, EsBlog.class);
}
6.3 统计文档数量
@ApiOperation(value = "统计文档数量", notes = "检索Elasticsearch中所有文档的总数")
@GetMapping("/count")
public Mono<Long> countDocuments() {
return reactiveElasticsearchTemplate.count(EsBlog.class);
}
6.4 复杂查询
1.查询EsBlog类对应索引所有文档并分页显示
@GetMapping(value = "/getAll", produces = MediaType.APPLICATION_JSON_VALUE)
@ApiOperation(value = "查询EsBlog类对应索引所有文档并分页显示", notes = "查询EsBlog类对应索引所有文档并分页显示")
public Flux<EsBlog> getAllEntities(
@RequestParam(name = "currentPage", required = false, defaultValue = "1") Integer currentPage,
@RequestParam(name = "size", required = false, defaultValue = "10") Integer size) {
return reactiveElasticsearchTemplate.search(
new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.withPageable(PageRequest.of(currentPage - 1, size))
.build(),
EsBlog.class
).map(SearchHit::getContent);
}
2.查询Elasticsearch中EsBlog对应索引所有匹配关键字的文档,倒序分页且关键字高亮显示,返回指定字段
@GetMapping("/searchByKeyWord")
@ApiOperation(value = "根据条件检索Elasticsearch中文档", notes = "查询Elasticsearch中EsBlog对应索引所有匹配关键字的文档,倒序分页且关键字高亮显示,返回指定字段")
public Flux<EsBlog> searchEntities(
@RequestParam(value = "keyWord") String keyWord,
@RequestParam(name = "currentPage", required = false, defaultValue = "1") Integer currentPage,
@RequestParam(name = "size", required = false, defaultValue = "10") Integer size) {
HighlightBuilder highlightBuilder = new HighlightBuilder().field("content")// 指定需要高亮的字段名为 "content"
.preTags("<em style='color:red'>") // 设置高亮文本前缀标签,这里使用红色显示
.postTags("</em>") // 设置高亮文本后缀标签
.fragmentSize(20) //每个高亮片段的最大长度为 20 个字符
.numOfFragments(1); //每个文档最多只能有 1 个高亮片段
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
// 添加一个多字段匹配查询,查询关键字为 keyWord
.withQuery(QueryBuilders.multiMatchQuery(keyWord, "title", "summary", "content"))
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))// 设置排序,按照 "id" 字段降序排序
.withHighlightBuilder(highlightBuilder) // 应用之前构建的高亮参数
.withPageable(PageRequest.of(currentPage, size))// 设置分页参数,当前页和每页大小
.withFields("id", "title", "summary", "content") // 设置返回的字段
.build();
return reactiveElasticsearchTemplate.search(searchQuery, EsBlog.class)
.map(SearchHit::getContent);
}
七、Reactive Elasticsearch Repositories
Reactive Elasticsearch Repositories使用了 Spring Data Repositories中的概念和方法,如 CRUD 操作、分页查询、排序等,但是以响应式编程的方式实现。
三个主要接口:
- ReactiveRepository:这是一个基本的响应式仓库接口,提供了一些基本的操作,如保存、删除和查询实体。
- ReactiveCrudRepository:这个接口继承自
ReactiveRepository,添加了额外的 CRUD 操作,例如根据 ID 保存实体、根据 ID 删除实体等。 - ReactiveSortingRepository:这个接口在
ReactiveCrudRepository的基础上添加了排序功能,允许你根据指定的字段对查询结果进行排序。
ReactiveSortingRepository继承ReactiveCrudRepository,ReactiveCrudRepository继承ReactiveRepositor
可以自定义接口继承这三个接口,使用接口中的默认方法或自定义方法查询。
public interface EsBlogReactiveRepository extends ReactiveSortingRepository<EsBlog, String> {
Flux<EsBlog> findBy(String keyword);
}
7.1 使用仓库接口提供的方法
简单的增删改查,直接给代码:
@RestController()
@RequestMapping("/reactiveEs_repository")
@Api(value = "响应式api——repository", tags = "响应式api——repository")
public class ReactiveEsBlog_repositoryController {
private final EsBlogReactiveRepository reactiveRepository;
public ReactiveEsBlog_repositoryController(EsBlogReactiveRepository reactiveRepository) {
this.reactiveRepository = reactiveRepository;
}
@PostMapping("/saveBlog")
@ApiOperation(value = "保存博客", notes = "保存博客")
public Mono<EsBlog> save(@RequestBody EsBlog esBlog) {
return reactiveRepository.save(esBlog);
}
@PostMapping("/saveAllBlog")
@ApiOperation(value = "批量保存博客", notes = "批量保存博客")
public Flux<EsBlog> saveAll(@RequestBody List<EsBlog> list) {
return reactiveRepository.saveAll(list);
}
/**
* 异步向es存esblog
*/
@PostMapping("/saveAllBlog_reactive")
@ApiOperation(value = "批量保存博客", notes = "批量保存博客")
public Flux<EsBlog> saveAll_re(@RequestBody List<EsBlog> list) {
Flux<EsBlog> flux = Flux.fromIterable(list);
return reactiveRepository.saveAll(flux);
}
@GetMapping("/deleteBlogById")
@ApiOperation(value = "通过id删除博客", notes = "通过id删除博客")
public Mono<Void> deleteBlogById(String id) {
return reactiveRepository.deleteById(id);
}
@PostMapping("/deleteAllBlog")
@ApiOperation(value = "批量删除博客", notes = "批量删除博客")
public Mono<Void> deleteAll(@RequestBody List<EsBlog> list) {
return reactiveRepository.deleteAll(list);
}
@GetMapping("/searchById/{id}")
@ApiOperation(value = "通过id查询", notes = "通过id查询")
public Mono<EsBlog> searchById(@PathVariable String id) {
return reactiveRepository.findById(id);
}
@PostMapping("/searchByIds")
@ApiOperation(value = "通过id批量查询", notes = "通过id批量查询")
public Flux<EsBlog> searchAll(@RequestBody List<String> ids) {
return reactiveRepository.findAllById(ids);
}
// 查询所有,并根据id倒序排序
@GetMapping("/findAll")
@ApiOperation(value = "查询所有", notes = "查询所有")
public Flux<EsBlog> findAll() {
return reactiveRepository.findAll(Sort.by("id").descending());
}
}
7.2 方法名的组合来定义查询
当你定义一个仓库接口并使用特定的方法名模式时,Spring Data 会根据这些模式自动构建查询。
常见的方法名组合及其对应的查询类型:
- findByXxx:用于执行基于字段的查询。例如,
findByTitle会构建一个查询,根据title字段的值来过滤文档。 - findAllByXxx:与
findByXxx类似,但返回所有匹配的文档,而不仅仅是第一个。 - findTopNByXxx:根据某个字段的值返回前 N 个匹配的文档。
- countByXxx:返回匹配某个条件的文档数量。
- existsByXxx:检查是否存在匹配某个条件的文档。
- deleteByXxx:删除匹配某个条件的文档。
xxx为文档的字段
分页和排序:
-
Page:结合Pageable对象使用,可以执行分页查询。
findAllByTitle(String title, Pageable pageable); -
Sort:结合Sort对象使用,可以对查询结果进行排序。
findAllByTitle(String title, Sort sort);
复杂的查询:
-
And、Or、Not:组合多个条件。
findByTitleAndTitle(String title, String summary); findByTitleOrSummary(String title, String summary); findByTitleNot(String title); -
Is、Between、LessThan、GreaterThan 等:用于特定条件的查询。
findByAgeIs(int age); findByAgeBetween(int min, int max); findByPriceLessThan(double price);
3.模糊查询:使用 Like 或 StartingWith 等后缀可以实现模糊查询:
// 模糊匹配 "title" 字段,类似于 SQL LIKE '%keyword%'
Flux<YourEntity> findByTitleLike(String keyword);
// 匹配 "title" 字段开始的关键字,类似于 SQL LIKE 'keyword%'
Flux<YourEntity> findByTitleStartingWith(String keyword);
这些方法的实现是由 Spring Data Elasticsearch 在运行时动态生成的,基于你定义的方法名和 Elasticsearch 的查询 DSL。
@Query自定义 JSON查询:
例如:
@Query("{\"match\": {\"title\": {\"query\": \"?0\"}}}")
Mono<Page<EsBlog>> findByTitle(String title, Pageable pageable);
?0:占位符,实现动态绑定,?0代表第一个参数,?1代表第二个参数。
@Query 注解中的 JSON 将会定义查询的主体,框架会处理 Pageable 对象并将分页参数应用到查询中,构成一个完整的查询语句。
word);
// 匹配 “title” 字段开始的关键字,类似于 SQL LIKE ‘keyword%’
Flux findByTitleStartingWith(String keyword);
> 这些方法的实现是由 Spring Data Elasticsearch 在运行时动态生成的,基于你定义的方法名和 Elasticsearch 的查询 DSL。
**@Query自定义 JSON查询**:
例如:
```java
@Query("{\"match\": {\"title\": {\"query\": \"?0\"}}}")
Mono<Page<EsBlog>> findByTitle(String title, Pageable pageable);
?0:占位符,实现动态绑定,?0代表第一个参数,?1代表第二个参数。
@Query 注解中的 JSON 将会定义查询的主体,框架会处理 Pageable 对象并将分页参数应用到查询中,构成一个完整的查询语句。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)