oracle中rank与rownum,Oracle 中 rownum、row_number()、rank()、dense_rank() 函数的用法
?简介
在之前还以为在 Oracle中只能使用rownum这个伪列来实现分页,其实不然。在 Oracle也与 MSSQL一样,同样支持 row_number函数,以及和rank、dense_rank这两个函数。下面就来讨论rownum与row_number函数的区别,以及另外两个函数的使用。
1.rownum
rownum是 Oracle在查询时对结果集输出的一个伪列,这个列并不是真实存在的,当我们进行每一个 SELECT查询时,Oracle会帮我们自动生成这个序列号(rownum),该序列号是顺序递增的,用于标识行号。通常可以借助rownum来实现分页,下面来看具体实现,比如我们需要取emp表中4到6行的记录:
1)首先,我们来看一个奇怪的现象
SELECT*FROMempWHERErownum>=4ANDrownum<=6;
啪,一执行,呀,怎么没数据啊?这并不是我们写错了,要解释这个问题,我们先来看一个图,就明白其中原由了。
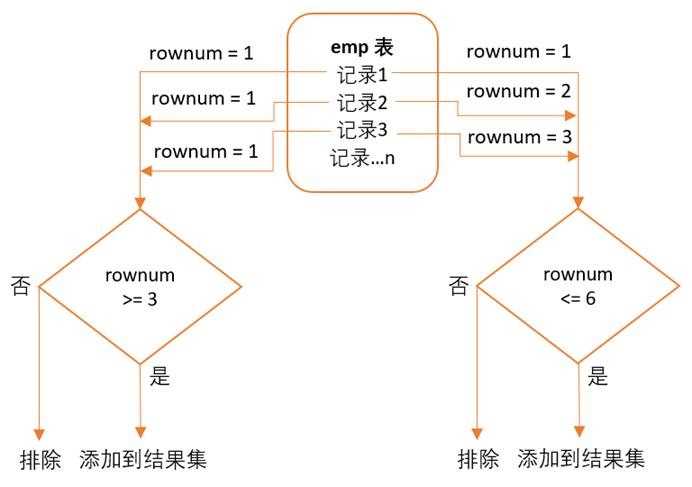
由图可以看出,当我们取出第一条记录时,此时(rownum = 1) >= 3不成立,所以该记录会被排除;然后再取第二条,此时任然rownum = 1,因为只有成功满足一条记录,rownum才会加1,所以不满足又被排除掉了。这样依次类推,最终都不满足条件,所以全部都被排除掉了。所以,以下语句始终查不出数据:
SELECT*FROMempWHERErownum>1;
然后,在看另外一边(就是接下来用的这种判断方式),首先取第一条(满足),第二条也满足,直到(rownum = 7) <= 6,所以会取出6条记录,此时rownum的值为1,2,3,4,5,6。好了,搞清楚原理后我们就来实现。
2)根据对rownum的分析,便改为以下语句
SELECTrownum,t1.*FROM(
SELECTrownumrnum,t1.*FROMemp t1WHERErownum<=6
)t1WHEREt1.rnum>=4;

这样,通过子查询,先取出前6行,再过滤掉前3行,就得到了我们需要的数据。注意:之前提过,每个 SELECT都会产生一个rownum序列号,所有上面会可以输出两个rownum序列号,dual也不例外:
SELECTt1.*,rownumFROMdual t1;

3)除了使用以上语句,我们还可以这样写
SELECTrownum,t1.*FROM(
SELECTrownumrnum,t1.*FROMemp t1
)t1WHEREt1.rnum>=4ANDrnum<=6;--或使用BETWEEN子句

同样,可以完成以上功能。但分析一下,这种方式视乎没有上面的方式效率高,因为,这里是先查出所有(先将 rownum分配好)数据,再进行第二次rownum过滤。
4)有时候,我们还需要通过排序后再分页,该怎么实现呢?
使用排序并分页,也需要注意以下问题。
首先,我们来看下排序的全部数据:
SELECT*FROMempORDERBYsal;
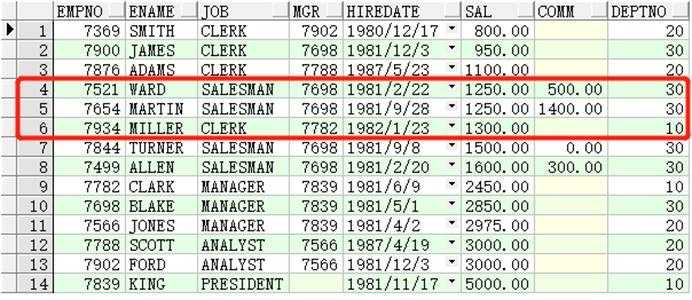
按照上面的要求,我们应该是取出empno(7521,7654,7934)的员工,OK。
不是说用第一种方式,效率很高么?那就来使用它实现,更改的后的 SQL:
SELECT*FROM(
SELECTrownumrnum,t1.*FROMemp t1WHERErownum<=6ORDERBYsal
)WHERErnum>=4;

结果是不是又纳闷了?怎么7698和7566也出来,而且还不是按我们预想的排序的!
好,我们再做个假设,以上语法是不是先查询出结果后,再将结果集过滤和排序的呢?为了验证这个疑点,很简单我们做以下测试:
SELECT*FROM(
SELECT*FROM(SELECTrownumrnum,t1.*FROMemp t1)
WHERErownum<=6ORDERBYsal
)WHERErnum>=4;

结果与前面的推断是一样的,就是先查询出结果(产生的 rownum是没有经过排序的),再排序,最后分页(过滤)。我们看一下未排序的原始数据:
SELECTrownum,t1.*FROMemp t1;
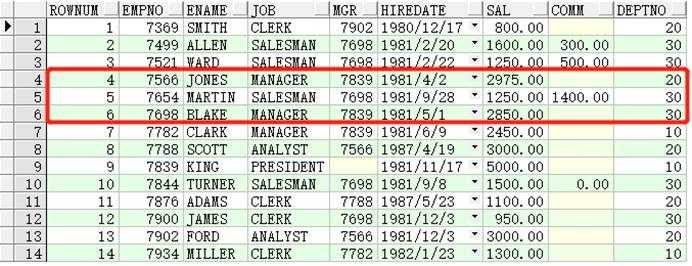
所以,我们得出一个结论:当我们同时过滤rownum和排序时,是先按默认的排序生成rownum后,再进行排序和过滤的。
5)其实上面的排序和分页,并不是准确有效的。因为我们需要的是,rownum的顺序是根据我们指定的排序产生的,这样再进行分页才是准确的。所以正确的排序和分页应该这样写:
SELECT*FROM(
SELECTrownumrnum,t1.*FROM(SELECT*FROMempORDERBYsal)t1
)WHERErnumBETWEEN4AND6;

执行步骤:先根据指定的字段排序;再产生rownum序列号;最后进行分页。
2.row_number()函数
在前面使用rownum实现分页,虽然是可以实现的,但是看似是否有点别扭。因为当需要对分页排序时,rownum总是先生成序列号再排序,其实这不时我们想要的。而row_number()函数则是先排序,再生成序列号。这也是row_number与rownum主要的区别。下面来看row_number()的使用:
n语法:
row_number() over([partition by col1] order by col2 [ASC | DESC] [,col3 [ASC | DESC]]...)
参数解释:
row_number() over():是固定写法,即不能单独使用row_nubmer()函数;
partition by:可选的。用于指定分组(或分开依据)的列,类似 SELECT中的 group by子句;
order by:用于指定排序的列,类似 SELECT中的order by子句。
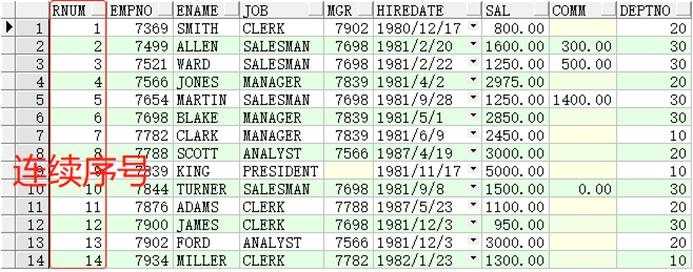
1.基本用法
SELECTrow_number()over(orderbyempno)ASrnum,t1.*FROMemp t1;
2.使用row_number()分页
SELECT*FROM(
SELECTrow_number()over(orderbyempno)ASrnum,t1.*FROMemp t1
)tWHEREt.rnumBETWEEN4AND6;

是不是看上去,比使用rownum优雅了许多。
3.使用 partition by参数分区生成序号
当使用 partition by参数时,序号将可能不是唯一的,因为序号的生成只会在当前分区中唯一,下一个分区又将从1开始计算,例如:
SELECTrow_number()over(partitionbydeptnoorderbyempno)ASrnum,t1.*FROMemp t1;
3.rank()与dense_rank()函数
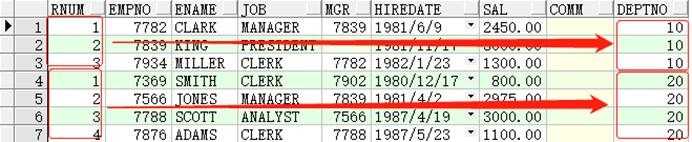
rank()与row_number()的区别在于,rank()会按照排序值相同的为一个序号(以下称为:块),第二个不同排序值将显示所有行的递增值,而不是当前序号加1。看示例:
SELECTrank()over(orderbyjob)rnum,job,enameFROMemp t1;
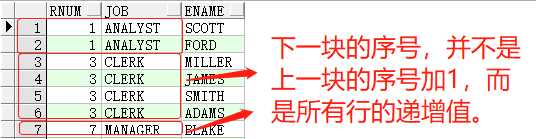
而 dense_rank()函数,与rank()区别在于,第二个不同排序值,是对当前序号值加1,看示例:
SELECTdense_rank()over(orderbyjob)rnum,job,enameFROMemp t1;
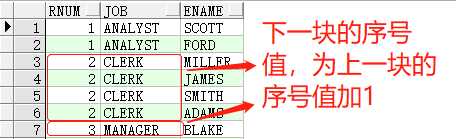
当指定 partition by参数时,将根据指定的字段分组,进行分组计算序号值,序号值只在当前分组中有效,例如:
SELECTrank()over(partitionbydeptnoorderbyjob)rnum,job,ename,deptnoFROMemp t1;
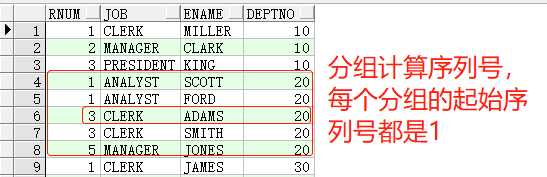
SELECTdense_rank()over(partitionbydeptnoorderbyjob)rnum,job,ename,deptnoFROMemp t1;
4.综合案例
1)查询前 100条记录
SELECT*FROMempWHERErownum<=100;
注意:如果以上语句需要排序后再筛选,并不是能使用rownum实现,而需要使用row_number()函数。
2)查出 4 ~ 6条的记录,并按员工编号排序(分页运用)
SELECT*FROM(SELECTrow_number()over(orderbyempno)rnum,t.*FROMemp t)t
WHEREt.rnum>=4ANDt.rnum<=6;

3)查出每个部门工资最高的员工
SELECT*FROM(SELECTrow_number()over(partitionbydeptnoorderbysalDESC)rnum,t.*FROMemp t)tWHEREt.rnum=1;

4)查出每个部门工资最高的所有员工(排名并列的)
SELECT*FROM(SELECTrank()over(partitionbydeptnoorderbysalDESC)rnum,t.*FROMemp t)tWHEREt.rnum=1;

5)查出每个部门工资排名第三的所有员工(排名并列的)
SELECT*FROM(SELECTdense_rank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t)tWHEREt.rnum=3;

注意:如果使用rank()是不行的,因为20号部门并列第二的员工有2个,序号3就被跳掉了,直接跳到了序号4,使用以下语句可以查看到:
SELECTrank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t;

所以,使用rank()将会得到错误的结果:
SELECT*FROM(SELECTrank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t)tWHEREt.rnum=3;

?总结
好了,关于排序函数就讨论到这里了,感觉有点难记住它们的区别。所以可以结合上面的案例去记忆:
1.如果需要取前多少条记录,就使用rownum伪列。rownum就类似于 SQL Server TOP子句的用法,但是rownum不能用于排序并过滤的场合。
2.如果取多少条到多少条的记录(分页),就是使用row_number()函数。
例如:查出 4 ~ 6条的记录,并按员工编号排序。
3.如果取某个组别中最大值记录或最小值的记录,也可以使用row_number()函数,并结合 partition by参数。
例如:查出每个部门工资最高的员工。
4.如果取某个组别中并列最大值或最小值得记录,就使用rank()函数,并结合 partition by参数。
例如:查出每个部门工资最高的所有员工。
5.如果取某个组别中并列排名几记录,就使用dense_rank()函数,并结合 partition by参数。
例如:查出每个部门工资排名第三的所有员工。
当然,以上只是举例,还有更多的用法需要我们去举一反三。
原文:https://www.cnblogs.com/abeam/p/12153362.html

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)