java获取微信xml数据格式的文件_(5)微信二次开发 之 XML格式数据解析
1、首先理解一下htmlhtml的全名是:HyperText Transfer markup language 超级文本标记语言,html本质上是一门标记(符合)语言,在html里,这些标记是事先定义(规则)好的,并且赋予了其特定的含义。有一套 固定的标记的集合。网页文件的扩展名是 .html或者 .htm,都是可行的。文档声明: 这里的doctype不管是大小写都是可以的,并且兼容html4/.
1、首先理解一下html
html的全名是:HyperText Transfer markup language 超级文本标记语言,html本质上是一门标记(符合)语言,在html里,这些标记是事先定义(规则)好的,并且赋予了其特定的含义。有一套 固定的标记的集合。
网页文件的扩展名是 .html或者 .htm,都是可行的。
文档声明: 这里的doctype不管是大小写都是可以的,并且兼容html4/html5。
html中的标记一般都是有开始标签和结束标签,例如:...、
...等标签。但是也有一些标签是没有内容主体的,可以直接写成:、
.
在html里的所有标签都是有固定含义的,不能自己随便去定义,虽然有一些是自定义的标签,但是最终还是继承和使用html的固定标签。
需要学习html4、html5、css2、css3等前段的开发,基础入门网站:http://www.w3school.com.cn/
编写html的时候使用的一些编辑器,例如:notepad++、editplus、hbuilder等。
2、理解XML
xml的全名是:Extensible Markup Language 可扩展标记语言,在xml文件里的所有标签都是可以自由定于的。
xml的扩展名为:.xml
xml文件头部信息为:<?xml version="1.0" ?>
xml文件有且只有一个跟节点
xml中的节点与节点之间可以允许嵌套
3、微信二次开发中使用XML的理解
由于微信协议数据传输其实就是采用xml格式进行传输,所以我们必须要了解xml的格式以及传输数据的解析和生成。
当微信A用户 -> 发送数据消息 -> 给B用户,中间需要微信服务器进行中转。例如:微信文本消息协议格式(该功能的数据传输是基于xml格式)
微信公众号开发文档地址:https://mp.weixin.qq.com/wiki
文本消息格式(用户发送给服务,服务器接收的格式)如下:
1
2
3
4 1348831860
5
6
7 1234567890123456
8
如图解析:
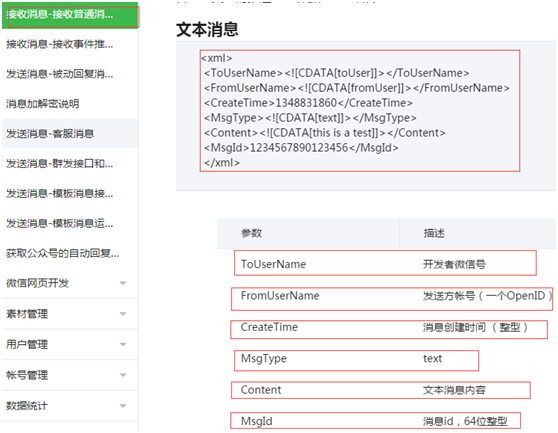
根据上面的xml格式,这类型的数据是指字符数据,CDATA是由character(字符)和data(数据)的简称缩写。
每个微信用户是通过openid来加以区分的,而openid就是根据个人的微信号进行一定的加密算法锁构成的,openid是由字母、数字、构成的一串字符串(该长度是28位)。在我们自己的微信服务器上收到的还是与原来的微信服务器所转发过来的xml格式串还是一致的。所以我们就需要在我们自己的服务器的程序里进行解析 xml格式串。
4、xml格式解析
目前在java里面对xml解析有4种方法:
1、DOM(Documemt Object Model)文档对象模型,Dom是一次性读取整个文档,如果xml文档比较大,节点比较多的情况下,解析的时候比较消耗资源、内存,性能比较低,不建议使用。
2、SAX(Simple API for XML)。使用SAX解析,是基于事件驱动方式来解析xml。解析器在读取xml文件根据读取的数据产生相应的事件,解析速度快,占用内存少,性能比较好。
3、DOM4J是第三方类库,对SAX解析进行了封装。
4、JDOM也是第三方类库,也是对SAX解析进行了封装。
DOM与SAX解析方式是java自带的,不需要第三方额外的jar包。二DOM4J和JDOM都是第三方开源的,使用的时候需要下载支持第三方支持的jar包。
5、声明一个xml文件使用4种方式进行解析
创建一个parseXml的java项目,将创建以一个studentMsg.xml文件,
如图显示:
编辑xml文件:
1 <?xml version="1.0"?>
2
3
4
5
6
7 小海
8 男
9 java开发
10 足球
11
12
13
14 婷菲
15 女
16 C#开发
17 跑步
18
19
这里的xml文件放在(我本地的位置):
/Users/wangxianhai/work_sts_01/parseXML/src/com/aixunma/xml/studentMsg.xml
6、声明XML文档内容信息的类
1 packagecom.aixunma.xml;2
3 /**
4 * XML文档内容信息的对应的字段5 *
类的描述:
6 *@Description: TODO
7 *@author小海
8 *@time:2017年4月29日 下午6:04:00
9 *@Vesion: 1.0
10 */11 public classXmlParam {12
13 public static final String LABLE_EMPLOYEE = "employee"; //员工标签
14 public static final String LABLE_NAME = "name"; //名称标签
15 public static final String LABLE_SEX = "sex"; //性别标签
16 public static final String LABLE_PROFESSION = "profession"; //职业标签
17 public static final String LABLE_HOBBY = "hobby"; //爱好标签
18
19 private intnumber;20 privateString name;21 privateString sex;22 privateString profession;23 privateString hobby;24
25 public intgetNumber() {26 returnnumber;27 }28 public void setNumber(intnumber) {29 this.number =number;30 }31 publicString getName() {32 returnname;33 }34 public voidsetName(String name) {35 this.name =name;36 }37 publicString getSex() {38 returnsex;39 }40 public voidsetSex(String sex) {41 this.sex =sex;42 }43 publicString getProfession() {44 returnprofession;45 }46 public voidsetProfession(String profession) {47 this.profession =profession;48 }49 publicString getHobby() {50 returnhobby;51 }52 public voidsetHobby(String hobby) {53 this.hobby =hobby;54 }55 @Override56 publicString toString() {57 StringBuilder builder = newStringBuilder();58 builder.append("number=").append(number).append("\n")59 .append("name=").append(name).append("\n")60 .append("sex=").append(sex).append("\n")61 .append("profession=").append(profession).append("\n")62 .append("hobby=").append(hobby).append("\n");63 returnbuilder.toString();64 }65 }
7、实现DOM方式解析xml
1 packagecom.aixunma.xml;2
3 importjava.io.File;4
5 importjavax.security.auth.login.LoginException;6 importjavax.xml.parsers.DocumentBuilder;7 importjavax.xml.parsers.DocumentBuilderFactory;8
9 importorg.apache.commons.lang.StringUtils;10 importorg.w3c.dom.Document;11 importorg.w3c.dom.Element;12 importorg.w3c.dom.Node;13 importorg.w3c.dom.NodeList;14
15 /**
16 * 使用DOM解析xml文件17 *
类的描述:
18 *@Description: TODO
19 *@author小海
20 *@time:2017年4月29日 下午2:28:27
21 *@Vesion: 1.0
22 */23 public classDomPaeseXML {24 /**
25 * 解析xml文档内容26 *@return
27 *@throwsException28 */
29 public static String parseXMl() throwsException {30
31 //1、创建一个文档构建工厂对象
32 final DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance();33
34 //2、通过工厂对象创建一个文档构造器对象
35 final DocumentBuilder db =dbf.newDocumentBuilder();36
37 //3、声明xml文件在本地的路径,并且加载该xml文件
38 final String path = "/Users/wangxianhai/work_sts_01/parseXML/src/com/aixunma/xml/studentMsg.xml";39 final File file = newFile(path);40
41 //4、通过文档构造器解析文件加载的对象成文档对象
42 final Document parse =db.parse(file);43
44 //5、通过文档对象获取头部节点
45 final Element headNode =parse.getDocumentElement();46
47 final StringBuilder builder = newStringBuilder();48
49 //6、通过头节遍历下面的子节点列表
50 final NodeList childNodes =headNode.getChildNodes();51 if (childNodes == null) {52 return "";53 }54 parseXmlToStr(childNodes, builder);55 returnbuilder.toString();56 }57
58 /**
59 * 将节点列表遍历生成字符串60 *@paramchildNodes 节点列表61 *@parambuilder 记录节点内容62 *@return
63 */
64 public staticStringBuilder parseXmlToStr(NodeList childNodes, StringBuilder builder) {65 //判断节点列表是否为空
66 if (childNodes == null) {67 returnbuilder;68 }69
70 //遍历节点列表
71 for (int i = 0; i < childNodes.getLength(); i++) {72 //获取子节点
73 final Node iemt =childNodes.item(i);74 //因为节点又好几种类型,需要判断属于ELEMENT_NODE类型的
75 if (iemt != null && iemt.getNodeType() ==Node.ELEMENT_NODE) {76 //节点的内容值
77 final String nodeValue =iemt.getFirstChild().getNodeValue();78 //如果值为为空,则不获取
79 if(StringUtils.isNotBlank(nodeValue)) {80 final String nodeName =iemt.getNodeName();81 builder.append(nodeName).append("\t").append(nodeValue).append("\n");82 }83 }84
85 //再次获取子节点的子节点列表
86 final NodeList childNodesNext =iemt.getChildNodes();87 parseXmlToStr(childNodesNext, builder); //继续回调该方法,获取子节点下的子节点
88 }89 returnbuilder;90 }91
92 //测试
93 public static void main(String[] args) throwsException {94 try{95 final String string =parseXMl();96 System.out.println(string);97 } catch(Exception e) {98 throw new LoginException("解析xml文件失败");99 }100 }101 }
8、实现SAX方式解析xml
1 packagecom.aixunma.xml;2
3 importjava.io.File;4 importjava.util.ArrayList;5 importjava.util.List;6
7 importjavax.security.auth.login.LoginException;8 importjavax.xml.parsers.SAXParser;9 importjavax.xml.parsers.SAXParserFactory;10
11 importorg.apache.commons.lang.math.NumberUtils;12 importorg.xml.sax.Attributes;13 importorg.xml.sax.SAXException;14 importorg.xml.sax.helpers.DefaultHandler;15
16 /**
17 * SAX解析XML文档信息18 *
类的描述:
19 *@Description: TODO
20 *@author小海
21 *@time:2017年4月29日 下午5:38:07
22 *@Vesion: 1.0
23 */24 public classSaxParseXML {25 public static String parseXml() throwsException {26 //1、创建一个SAX解析工厂对象
27 final SAXParserFactory spy =SAXParserFactory.newInstance();28
29 //2、通过工厂对象获取SAX解析对象
30 final SAXParser parser =spy.newSAXParser();31
32 //3、加载xml文件
33 final String path = "/Users/wangxianhai/work_sts_01/parseXML/src/com/aixunma/xml/studentMsg.xml";34 final File file = newFile(path);35
36
37 parser.parse(file, newMyDefaultHandler());38
39 return "1";40 }41
42 public static void main(String[] args) throwsException {43 try{44 parseXml();45 } catch(Exception e) {46 throw new LoginException("xml解析失败");47 }48 }49 }50 //内部了继承SAX的DefaultHandler的类,重新下面的方法,获取相应的信息
51 class MyDefaultHandler extendsDefaultHandler{52
53 private List xmlParamList = null;54 private XmlParam xmlParam = null;55 private String preTag = null; //记录解析时的上一个节点名称
56
57 /**
58 * 解析文档开始:初始化的作用59 */
60 @Override61 public void startDocument () throwsSAXException {62 System.out.println("-------解析xml开始-----");63 xmlParamList = new ArrayList();64 }65
66 /**
67 * 解析开始节点68 */
69 @Override70 public voidstartElement (String uri, String localName,71 String startName, Attributes attributes) throwsSAXException {72 if (XmlParam.LABLE_EMPLOYEE.equals(startName)) { //判断是否是employee员工开始标签
73 final String attrValue = attributes.getValue("number"); //工号74 //初始化xmlParam对象
75 xmlParam = newXmlParam();76 xmlParam.setNumber(NumberUtils.toInt(attrValue, 0)); //转化成int类型,默认值是0表示没有暂时没有工号
77 }78 preTag = startName; //将正在解析的节点名称赋给preTag
79 }80
81 /**
82 * 解析结束节点83 */
84 @Override85 public void endElement (String uri, String localName, String endName) throwsSAXException {86 if (XmlParam.LABLE_EMPLOYEE.equals(endName)) { //判断是否是employee员工结束标签87 //将xmlParam对象加入list集合
88 xmlParamList.add(xmlParam);89 }90 /*
91 * 注意这里要将preTag为null。当执行到小海的结束的时候,会调用92 * 这个节点结束方法,如果这里不把preTag置为null,根据startElement(....)方法,preTag的值还是number,93 * 会执行characters(char[] ch, int start, int length)这个方法94 * 而characters(....)方法判断preTag!=null,会执行if判断的代码,这样就会把空值赋值给book95 *96 * 总的来说每解析一对节点(不包括文档头节点和尾节点)执行方法顺序:97 * startElement(...)->characters(...)->endElement(...)98 */
99 preTag = null;100 }101
102 /**
103 * 获取节点内容104 */
105 @Override106 public void characters(char[] ch, int start, intlength) {107 if (preTag != null) {108 final String content = newString(ch, start, length);109 if(XmlParam.LABLE_NAME.equals(preTag)) {110 xmlParam.setName(content);111 } else if(XmlParam.LABLE_SEX.equals(preTag)) {112 xmlParam.setSex(content);113 } else if(XmlParam.LABLE_PROFESSION.equals(preTag)) {114 xmlParam.setProfession(content);115 } else if(XmlParam.LABLE_HOBBY.equals(preTag)) {116 xmlParam.setHobby(content);117 }118 }119 }120
121 /**
122 * 解析文档结束123 */
124 @Override125 public void endDocument () throwsSAXException {126 //输出数据
127 for(XmlParam xmlParam : xmlParamList) {128 System.out.println(xmlParam.toString());129 }130 System.out.println("-------解析xml结束-----");131 }132 }
9、实现DOM4J方式解析xml
1 packagecom.aixunma.xml;2
3 importjava.io.File;4 importjava.util.Iterator;5 importjava.util.List;6
7 importorg.apache.commons.lang.StringUtils;8 importorg.dom4j.Attribute;9 importorg.dom4j.Document;10 importorg.dom4j.Element;11 importorg.dom4j.io.SAXReader;12 importorg.junit.Test;13
14 /**
15 * 使用DOM4J解析XML文档、生成文档、操作节点、删除节点、添加节点16 *
类的描述:
17 *@Description: TODO
18 *@author小海
19 *@time:2017年4月29日 下午9:35:34
20 *@Vesion: 1.0
21 */22 public classDom4jParseXML {23
24 private static String PARSE_XML_PATH = "/Users/wangxianhai/work_sts_01/parseXML/src/com/aixunma/xml/studentMsg.xml";25
26 /**
27 * 解析XML文档28 *@throwsException29 */
30 @Test31 public void parseXml() throwsException {32 //1、创建SAXReader对象
33 final SAXReader reader = newSAXReader();34
35 //2、通过SAXReader对象读取xml文件生成Domcument文档对象
36 final Document document = reader.read(newFile(PARSE_XML_PATH));37
38 //3、获取根节点对象
39 final Element root =document.getRootElement();40
41 //4、遍历
42 listNodes(root);43 }44
45 /**
46 * 遍历节点47 *@paramnode48 */
49 public voidlistNodes(Element node) {50 //获取节点的名称
51 /*final String nodeName = node.getName();52
53 System.out.println(nodeName);*/
54
55 //遍历属性节点
56 final List attributes =node.attributes();57 for(Attribute attribute : attributes) {58 System.out.println(attribute.getName() + "=" +attribute.getText());59 }60
61 //获取当前节点的内容
62 if (StringUtils.isNotBlank(node.getTextTrim())) { //内容不为空的读取
63 System.out.println(node.getName() + "=" +node.getText());64 }65
66 //迭代该节点的所有子节点
67 final Iterator iterator =node.elementIterator();68 while(iterator.hasNext()) {69 Element el =(Element) iterator.next();70 listNodes(el); //使用递归
71 }72 }73 }
10、实现JDOM方式解析xml
1 packagecom.aixunma.xml;2
3 importjava.io.File;4 importjava.util.List;5
6 importorg.apache.commons.lang.StringUtils;7 importorg.jdom.Attribute;8 importorg.jdom.Document;9 importorg.jdom.Element;10 importorg.jdom.JDOMException;11 importorg.jdom.input.SAXBuilder;12 importorg.junit.Test;13
14 /**
15 * 使用JDOM解析XML文档信息16 *
类的描述:
17 *@Description: TODO
18 *@author小海
19 *@time:2017年5月1日 下午11:24:10
20 *@Vesion: 1.0
21 */22 public classJdomParseXML {23
24 private static String PARSE_XML_PATH = "/Users/wangxianhai/work_sts_01/parseXML/src/com/aixunma/xml/studentMsg.xml";25
26 /**
27 * 解析XML文档28 *@throwsException29 *@throwsJDOMException30 *@throwsException31 */
32 @Test33 public void parseXml() throwsJDOMException, Exception {34
35 //创建一个JDOM的SAX的构造器
36 final SAXBuilder builder = newSAXBuilder();37
38 //通过构造器获取文档对象
39 final Document document = builder.build(newFile(PARSE_XML_PATH));40
41 //获取文档的根元素
42 final Element root =document.getRootElement();43
44 //遍历
45 listNodes(root);46 }47
48 /**
49 * 遍历节点50 *@paramnode51 */
52 public voidlistNodes(Element node) {53 //获取节点的名称
54 /*final String name = node.getName();55 System.out.println(name);*/
56
57 //获取节点所有属性list集合
58 final List attributes =node.getAttributes();59 //遍历节点的所有属性
60 for(Attribute attribute : attributes) {61 System.out.println(attribute.getName() + "=" +attribute.getValue());62 }63
64 //获取节点存在的内容
65 if(StringUtils.isNotBlank(node.getTextTrim())) {66 System.out.println(node.getName() + "=" +node.getText());67 }68
69 //获取该节点下的所有子节点
70 List children =node.getChildren();71 for(Element element : children) {72 listNodes(element); //递归调用
73 }74 }75 }
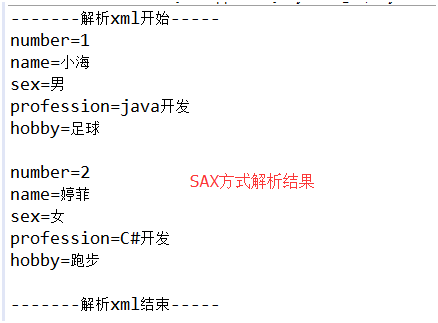
11、四种方式结果展示



12、致谢
感谢各位的阅读,希望对您有帮助,需要源码加QQ:963551706 谢谢!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)