数据清洗——初级案例整理
文章目录一、快餐数据1.1 探索数据1.1.1 数据表一共多少行数据?有多少列1.1.2 是否存在缺失值?哪个字段?1.1.3 数据去重操作1.2 描述性统计1.2.1 被下单数最多的前五的商品(item_name)有哪些?1.2.2 在item_name这列中,一共有多少商品被下单?1.2.3 商品下单总数量是多少?1.2.4 目前item_price数据类型为?如何转换为浮点数?1.2.5 在
文章目录
- 一、快餐数据
-
- 1.1 探索数据
- 1.2 描述性统计
-
- 1.2.1 被下单数最多的前五的商品(item_name)有哪些?
- 1.2.2 在item_name这列中,一共有多少商品被下单?
- 1.2.3 商品下单总数量是多少?
- 1.2.4 目前item_price数据类型为?如何转换为浮点数?
- 1.2.5 在该数据集对应的时期内,收入(revenue)是多少?
- 1.2.6 在该数据集对应的时期内,一共有多少订单?
- 1.2.7 每一单(order)对应的平均总价是多少?
- 1.2.8 统计哪些item_name的choice_description缺失值最多?最多的5类item_name求出来?
- 1.2.9 上面5类item_name中,其choice_description的缺失值率是多少?
- 二、欧洲杯练习
-
- 2.1 探索数据
- 2.2 缺失值处理
- 2.3 描述性统计与数据预处理
-
- 2.3.1 有多少球队参与了2012欧洲杯?
- 2.3.2 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
- 2.3.3 对数据框discipline按照先Red Cards升序再Yellow Cards进行降序排序
- 2.3.4 计算每个球队拿到的黄牌数的平均值
- 2.3.5 找到进球数Goals超过6的球队数据
- 2.3.6 对比英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
- 2.3.7 euro中有哪些字段属于object类?
- 2.3.8 提取带百分号字符的字段到一个新的DataFrame中
- 2.3.9 在新DataFrame中,将带有百分号的字符转化为浮点型数据
- 2.3.10 在上表所有列标签中后面备注——(%)
- 三、电商数据清洗
-
- 3.1 读取文件
- 3.2 查看数据的前五行和后五行
- 3.3 了解数据各字段的信息
- 3.4 查看数值型字段的描述性统计信息
- 3.5 数据去重
- 3.6 查看卖家种类信息
- 3.7 查看位置种类信息
- 3.8 添加一列成交额=价格×成交量(位置放在 成交量之后)
- 3.9 选出价格最贵的十个宝贝的信息
- 3.10 挑选出成交额最多的十个宝贝的信息
- 3.11 查看位置是江苏、成交额是前五名的宝贝
- 3.12 挑选出卖家含有‘旗舰店’的行
- 3.13 求每个卖家的总成交额并按降序排序
- 3.14 画出随着卖家变化,总成交额的变化的折线图
- 3.15 以柱状图的形式画出总成交额并以降序排序
- 3.16 看每个位置的成交额总额并以降序排序
- 3.17 以饼图的形式画出各位置的成交额占比
- 四、Stockholm气温的数据分析
- 五、药品销售数据
- 六、餐厅订单详情表分析
一、快餐数据
import numpy as np,pandas as pd
snack= pd.read_csv(r"snack.csv",encoding="utf_8",sep="\t")
snack.head()
1.1 探索数据
1.1.1 数据表一共多少行数据?有多少列
snack.shape#返回df的形状,得知是几行几列数据
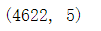
1.1.2 是否存在缺失值?哪个字段?
snack.isnull().sum()#快速统计每个字段缺失值的数量

1.1.3 数据去重操作
df=snack.drop_duplicates()#drop_duplicates函数用于删除重复记录
df.shape#再查看一下去重后是几行几列
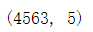
df.reset_index(drop=True,inplace=True)#重新编号索引
df.tail()#取后5行查看

df.isnull().sum()#再次统计去重后的每个字段缺失值的数量
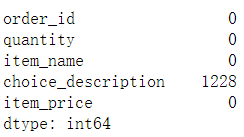
1.2 描述性统计
1.2.1 被下单数最多的前五的商品(item_name)有哪些?
df['item_name'].value_counts()#统计每件商品名出现的次数
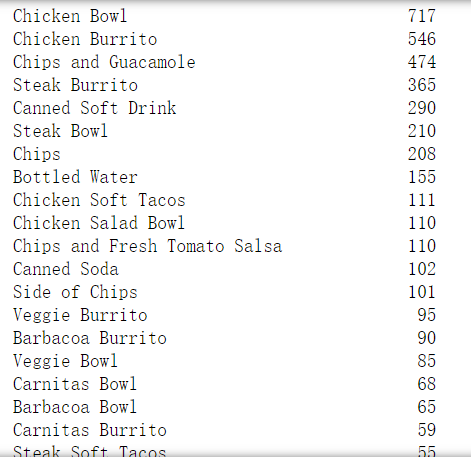
#按照item_name字段进行分组,然后求quantity的和
df.groupby('item_name')['quantity'].sum().nlargest()#nlargest默认获取最大的5个值
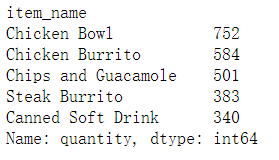
1.2.2 在item_name这列中,一共有多少商品被下单?
len(df.item_name.unique()) #unique()返回去重之后的结果
df.item_name.nunique() #nunique()返回非重复值统计的个数
len(df.groupby('item_name'))
len(df.item_name.value_counts())
len(df.drop_duplicates('item_name'))
#上面5种方法,任选一种都可以求出
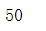
1.2.3 商品下单总数量是多少?
df.quantity.sum()
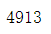
1.2.4 目前item_price数据类型为?如何转换为浮点数?
df.item_price.dtype#O指代的是object类型
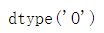
df.item_price=df.item_price.str[1:].astype(float)
df.head()
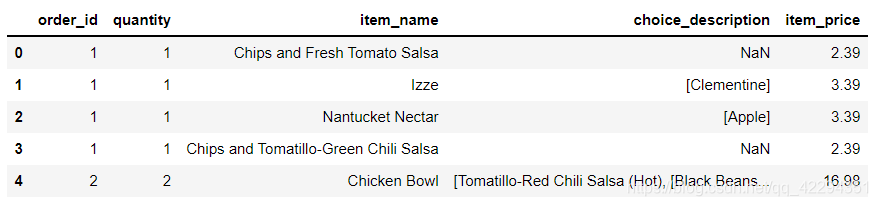
1.2.5 在该数据集对应的时期内,收入(revenue)是多少?
df['revenue']=df['quantity']*df['item_price']#收入=数量*单价
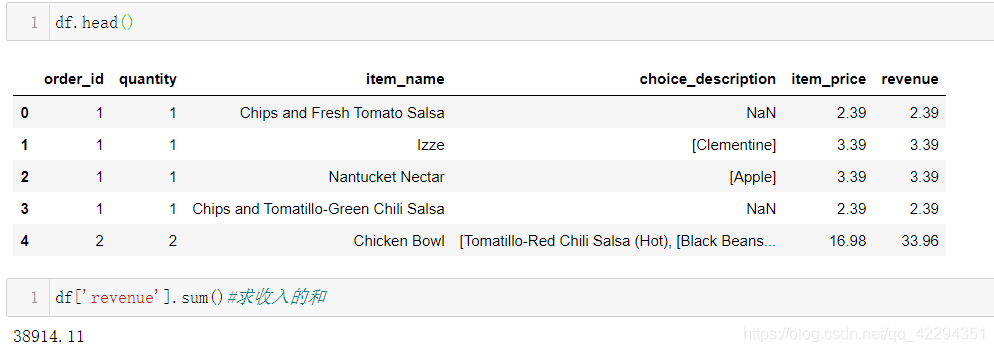
1.2.6 在该数据集对应的时期内,一共有多少订单?
df.order_id.nunique()#nunique()返回非重复值统计的个数
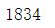
1.2.7 每一单(order)对应的平均总价是多少?
df.groupby('order_id')['revenue'].sum().mean()#按照id进行分组后求收入总和后的均值
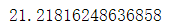
1.2.8 统计哪些item_name的choice_description缺失值最多?最多的5类item_name求出来?
b = df.groupby("item_name").apply(lambda x:x['choice_description'].isnull().sum()).nlargest()
b

#先筛选出choice_description有缺失值的数据,然后按照item_name进行分组并求quantity的数量,查看数量最大的5行数据
b=df[df.choice_description.isnull()].groupby('item_name')['quantity'].count().nlargest()
b

1.2.9 上面5类item_name中,其choice_description的缺失值率是多少?
缺失的/总共出现的次数=缺失率
c = df['item_name'].value_counts()[b.index]
c #得到这5个商品总出现次数

b/c #发现都是百分百缺失

二、欧洲杯练习
import pandas as pd,numpy as np
# Dataframe显示所有列
pd.set_option('display.max_columns', None)#数据太多的话不建议运行,不然运行会慢很多
euro = pd.read_csv("Euro2012_stats.csv")
euro.head()
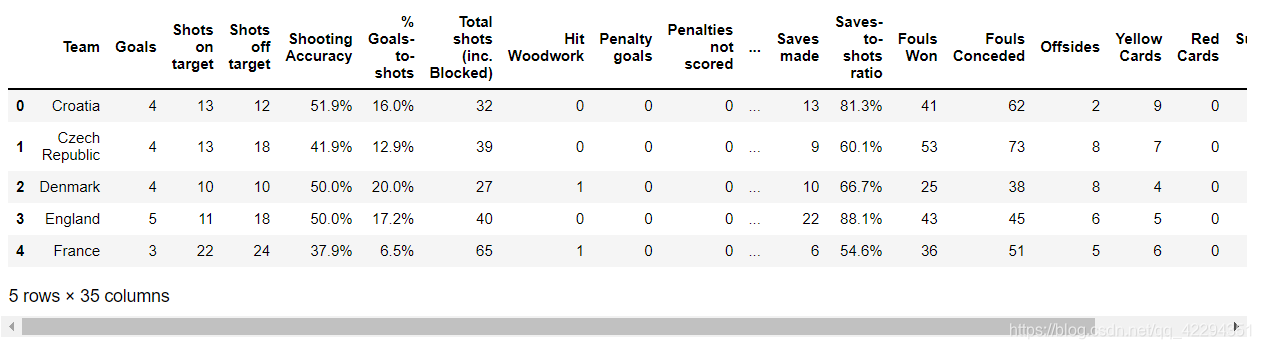
2.1 探索数据
euro.shape#查看有几行几列数据
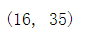
len(euro12.drop_duplicates())#没有重复行
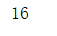
#查看是否存在缺失值,哪个字段?
euro.isnull().sum()
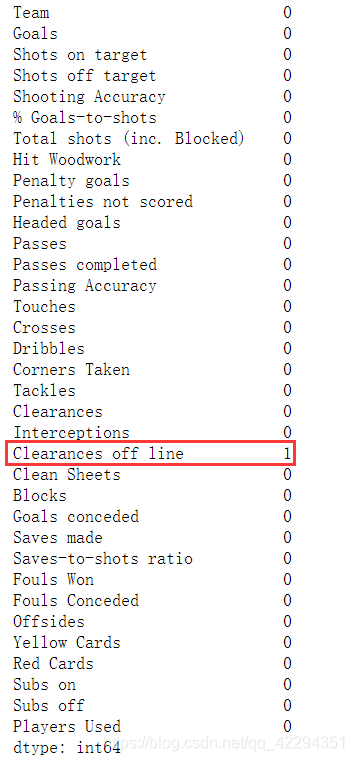
2.2 缺失值处理
euro['Clearances off line']
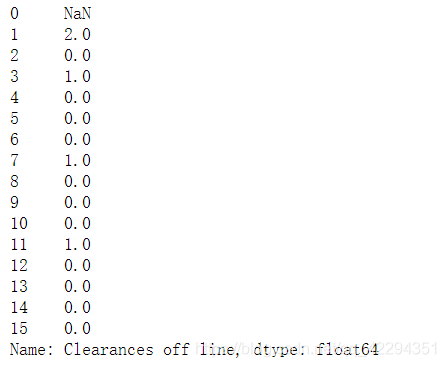
mode=euro['Clearances off line'].mode()[0]#用众数填补;[0]取出众数
mode
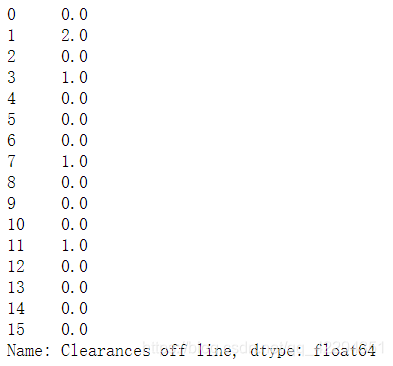
euro['Clearances off line']=euro['Clearances off line'].fillna(mode)#没有直接对原数据修改,所以要重新赋值
euro['Clearances off line']
2.3 描述性统计与数据预处理
2.3.1 有多少球队参与了2012欧洲杯?
euro.Team.nunique()
2.3.2 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
discipline=euro[['Team','Yellow Cards','Red Cards']]
discipline
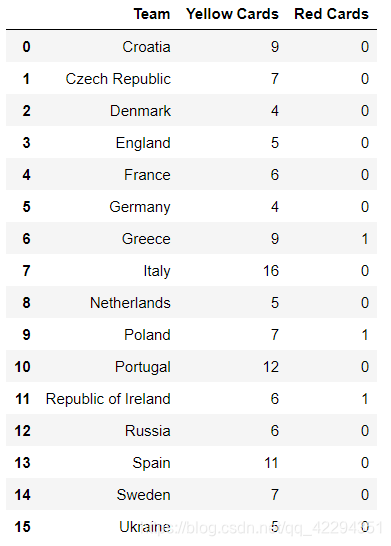
2.3.3 对数据框discipline按照先Red Cards升序再Yellow Cards进行降序排序
discipline.sort_values(['Red Cards','Yellow Cards'],ascending=[True,False])
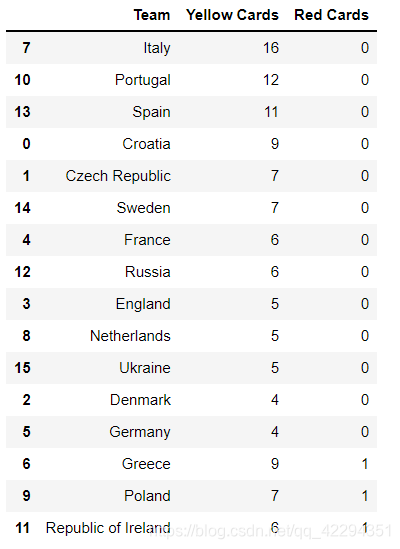
2.3.4 计算每个球队拿到的黄牌数的平均值
假设每支球队有重复出现,表存放的是这些球队在不同比赛的成绩,那么就要使用groupby以球队名字进行分组,再求每组黄牌的平均值
euro.groupby("Team")['Yellow Cards'].mean()
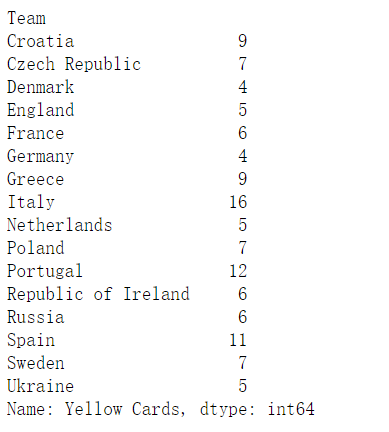
2.3.5 找到进球数Goals超过6的球队数据
euro[euro.Goals>6]
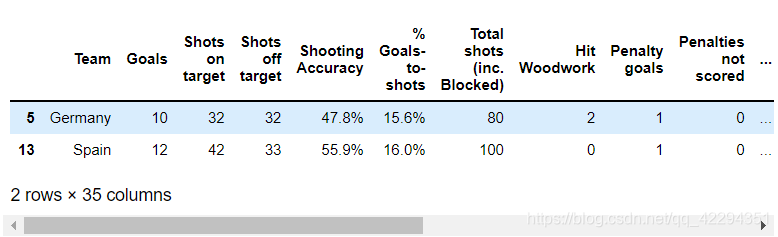
2.3.6 对比英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
euro1=euro[['Team','Shooting Accuracy']]
euro1
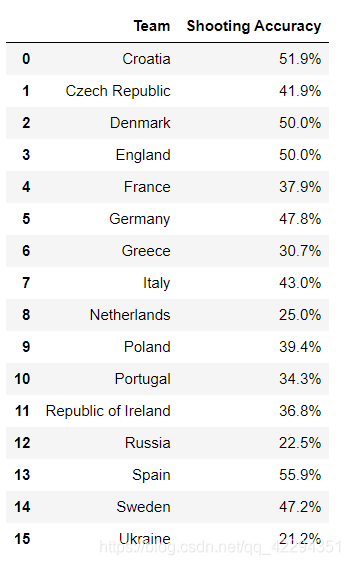
euro1[(euro1.Team=='Russia') | (euro1.Team=='England')|(euro1.Team=='Italy') ]
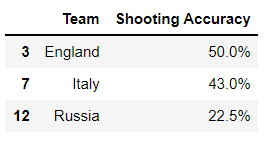
2.3.7 euro中有哪些字段属于object类?
a=euro.describe(include='object')#include='object'想查看非数字类型的列的统计指标
a
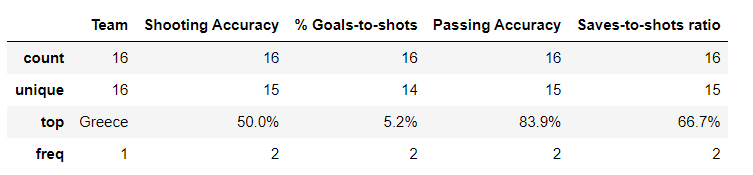
euro[a.columns]
2.3.8 提取带百分号字符的字段到一个新的DataFrame中
all(euro['Shooting Accuracy'].str[-1]=='%')#判断最后一个字符是不是%
c=[]
for i in a.columns:
if all(euro[i].str[-1]=='%'):
c.append(i)
c

euro2=euro[c]
euro2
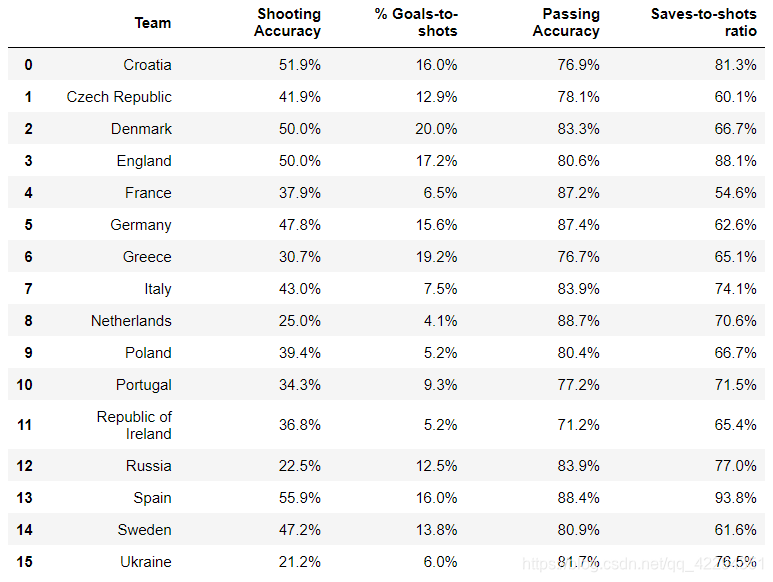
2.3.9 在新DataFrame中,将带有百分号的字符转化为浮点型数据
方法一 df.applymap()
- 使用df.applymap()基本操作对象是df中的每一个元素
- 先从表中拿一个元素出来,看看怎样可以达到你想要的结果
- 把尝试的过程写进自定义函数
- 把自定义函数放进df.applymap()进行运用
def change(x):
return float(x[:-1])/100
euro2.applymap(change)
#euro2.applymap(lambda x:float(x[:-1])/100)
方法二:用df.apply()
- apply()基本操作对象是一个个Series
- 可以拿出其中的一列进行尝试,看如果得到我们想要的结果
- 再把尝试的过程写成自定义函数
- 封装好自定义函数放到df.apply()里进行运用
def change1(x):
return x.str[:-1].astype(float)/100
euro3=euro2.apply(change1)
euro3
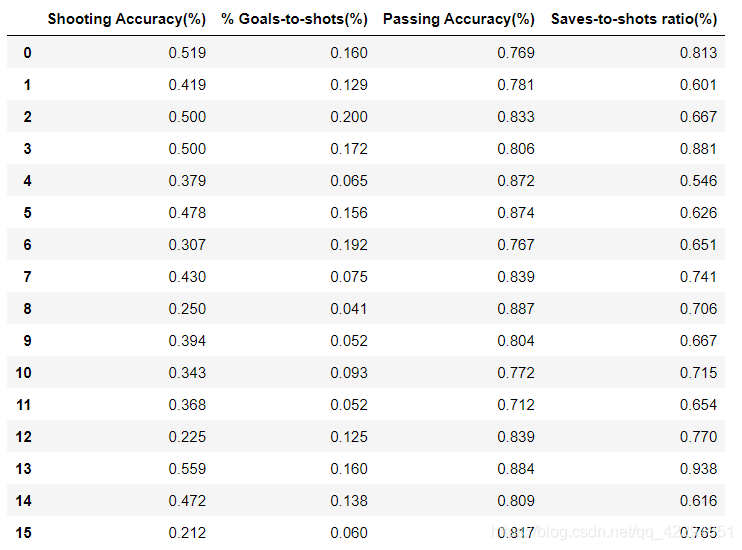
2.3.10 在上表所有列标签中后面备注——(%)
euro3.columns+='(%)'
euro3
三、电商数据清洗
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Simhei'] #显示中文,解决图中无法显示中文的问题
plt.rcParams['axes.unicode_minus']=False #设置显示中文后,负号显示受影响。解决坐标轴上乱码问题
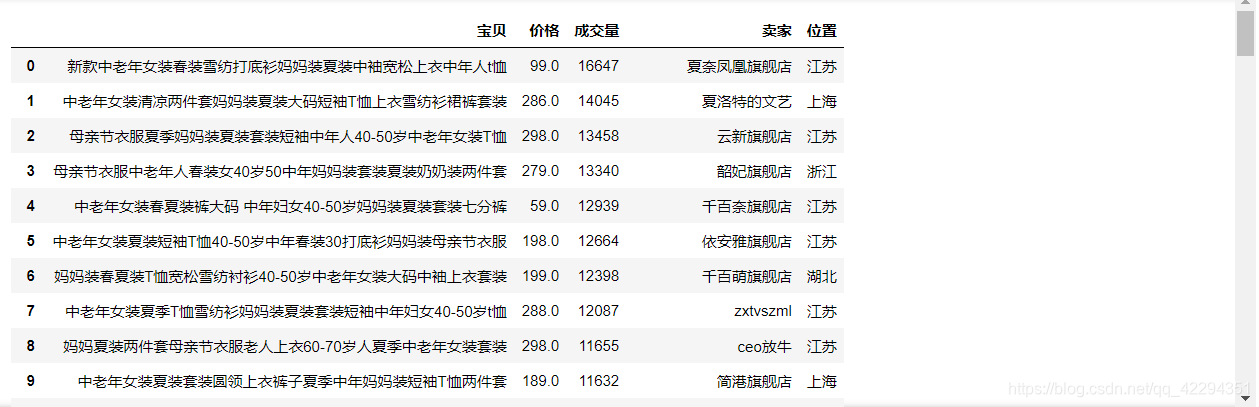
3.1 读取文件
df = pd.read_csv(r"taobao_data.csv")
df
3.2 查看数据的前五行和后五行
df.head()#前5行

df.tail()#后5行

3.3 了解数据各字段的信息
df.info()

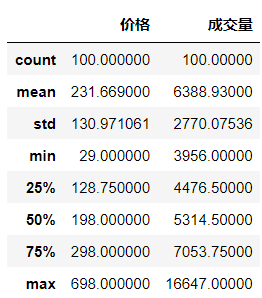
3.4 查看数值型字段的描述性统计信息
df.describe()
3.5 数据去重
df=df.drop_duplicates()
3.6 查看卖家种类信息
df.卖家.unique()#unique去重显示

3.7 查看位置种类信息
df.位置.value_counts()

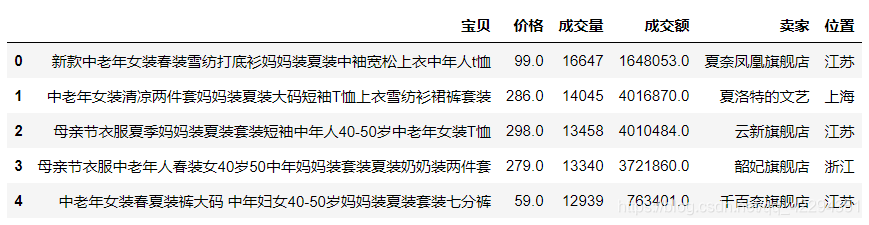
3.8 添加一列成交额=价格×成交量(位置放在 成交量之后)
df.insert(3,'成交额',df.价格*df.成交量) #3为位置,取的列名,数据
df.head()
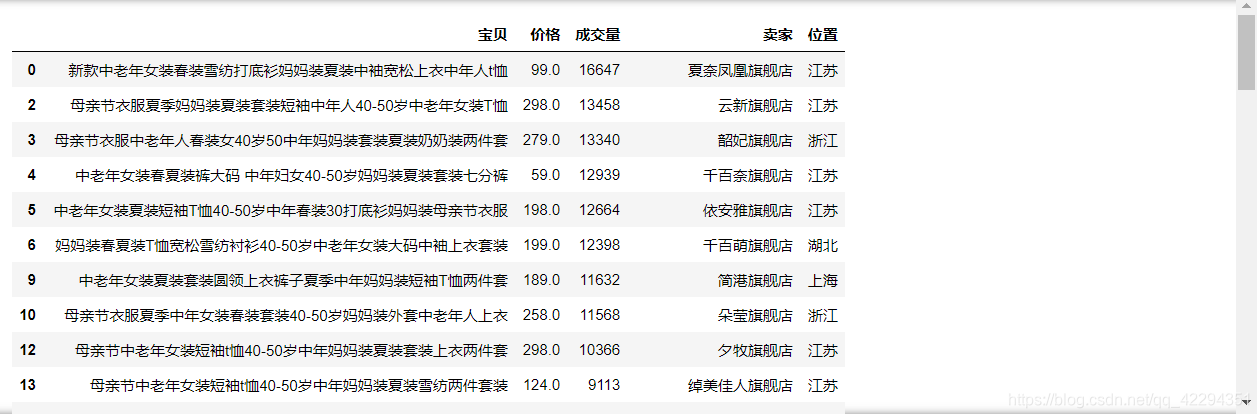
3.9 选出价格最贵的十个宝贝的信息
df.sort_values('价格',ascending=False).head(10)
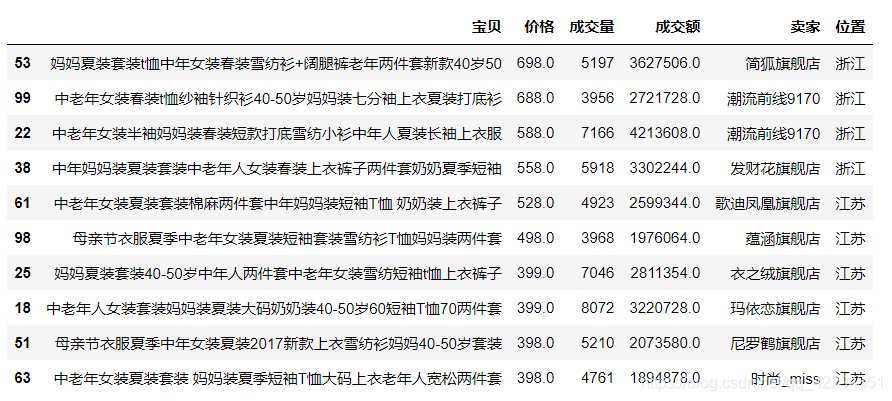
3.10 挑选出成交额最多的十个宝贝的信息
df.sort_values('成交额',ascending=False).head(10)
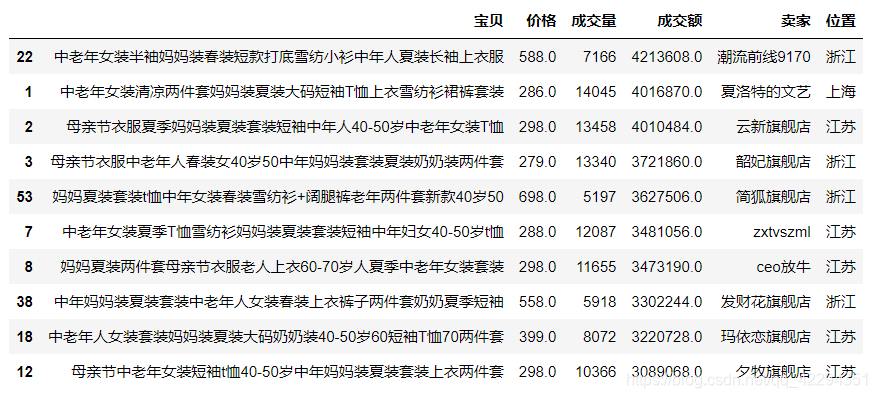
3.11 查看位置是江苏、成交额是前五名的宝贝
df[df.位置=='江苏'].sort_values('成交额',ascending=False).head()
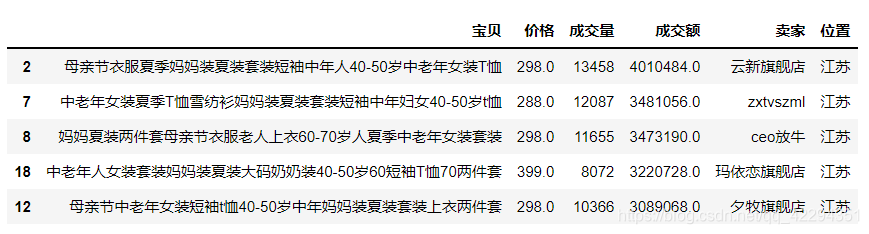
3.12 挑选出卖家含有‘旗舰店’的行
df[df.卖家.map(lambda x:'旗舰店' in x)]
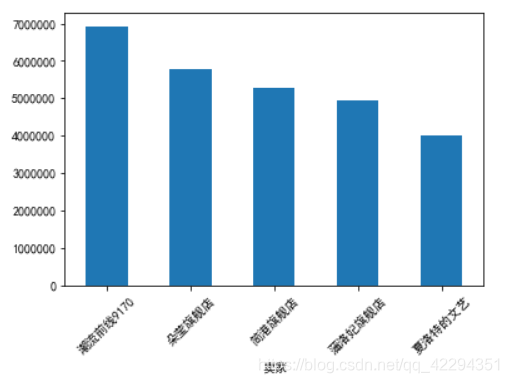
3.13 求每个卖家的总成交额并按降序排序
a=df.groupby('卖家')['成交额'].sum().sort_values(ascending=False)
a

3.14 画出随着卖家变化,总成交额的变化的折线图
plt.plot(range(len(a)),a);
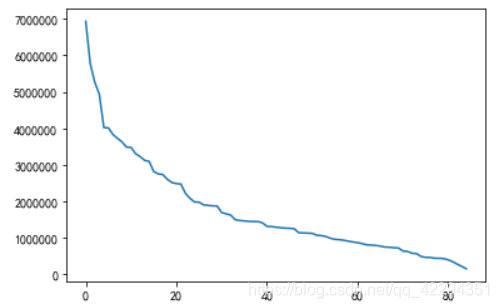
3.15 以柱状图的形式画出总成交额并以降序排序
b=a.head()
b.plot(kind='bar',rot=45);
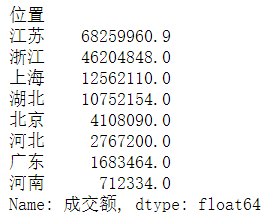
3.16 看每个位置的成交额总额并以降序排序
c=df.groupby('位置')['成交额'].sum().sort_values(ascending=False)
c
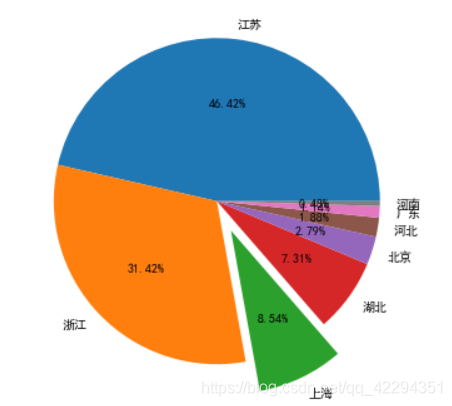
3.17 以饼图的形式画出各位置的成交额占比
上海的部分突出显示
plt.figure(figsize=(8,6))
plt.pie(c,labels=c.index,explode=(0,0,0.2,0,0,0,0,0),autopct='%.2f%%');
四、Stockholm气温的数据分析
#导入相关库
import pandas as pd
import numpy as np
import time
import datetime
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
4.1 outdoor表的分析
4.1.1 数据预处理
4.1.1.1 导入outdoor数据
data=pd.read_csv("temperature_outdoor_2014.csv",index_col=0)
data.head()
4.1.1.2 处理表头
data.columns=['datetime','temperature']#给列名
data
4.1.1.3 数据探索
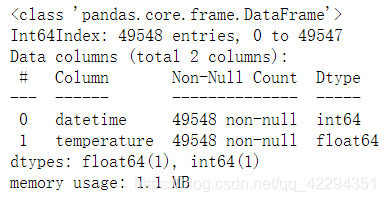
data.info()
data.isnull().sum()#没有缺失值

4.1.1.4 日期字段的转换
data['datetime']=pd.to_datetime(data['datetime'],unit='s')#unit='s'到秒
data
4.1.2 查看气温变化的情况
data2=data.copy()
data2
data.set_index('datetime',inplace=True)#set_index指定数据列设置为标签列
data
data2.set_index('datetime',inplace=True,drop=False)#inplace=True不删除原数据列
data2
4.1.2.1 数据按年分组后求平均气温
#单独把年月日提取出来
data2['year']=data2.datetime.dt.year
data2['month']=data2.datetime.dt.month
data2['day']=data2.datetime.dt.day
data2
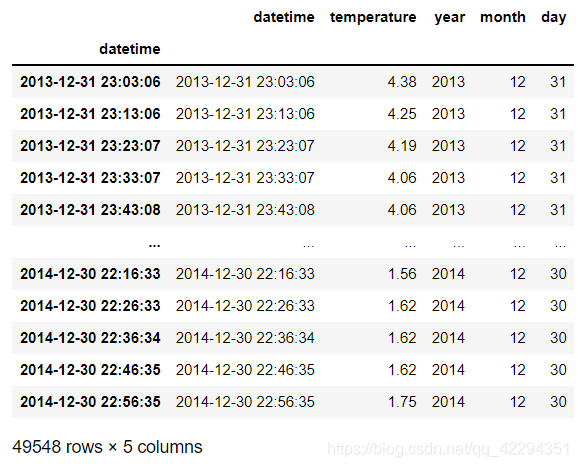
data2.groupby('year')['tempareture'].mean().plot(kind='bar',rot=45)#方法一:先分组,再求平均值
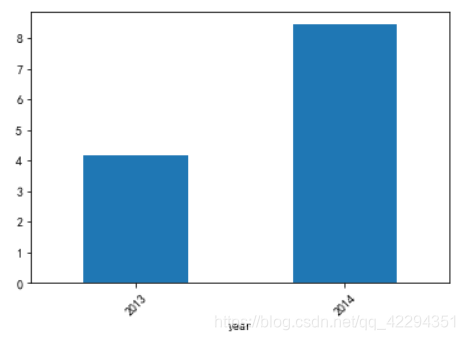
data.resample('Y')['temperature'].mean().plot(kind='bar',rot=45);#方法二,用resample()
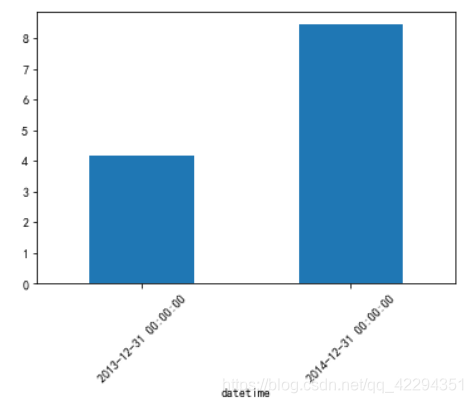
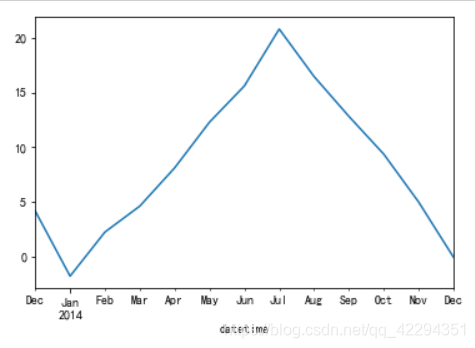
4.1.2.2 每月的平均气温的变化
data.resample('M')['temperature'].mean().plot();#法一
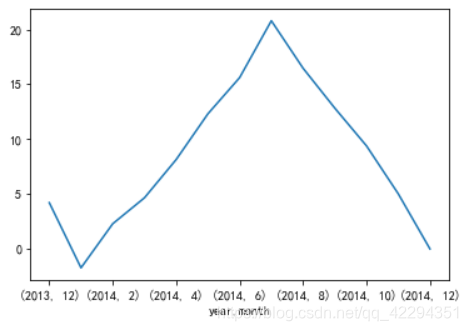
data2.groupby(['year','month'])['temperature'].mean().plot();#法二
4.1.2.3 数据一整年的气温变化
data.plot(figsize=(12,6));#12*6的画布
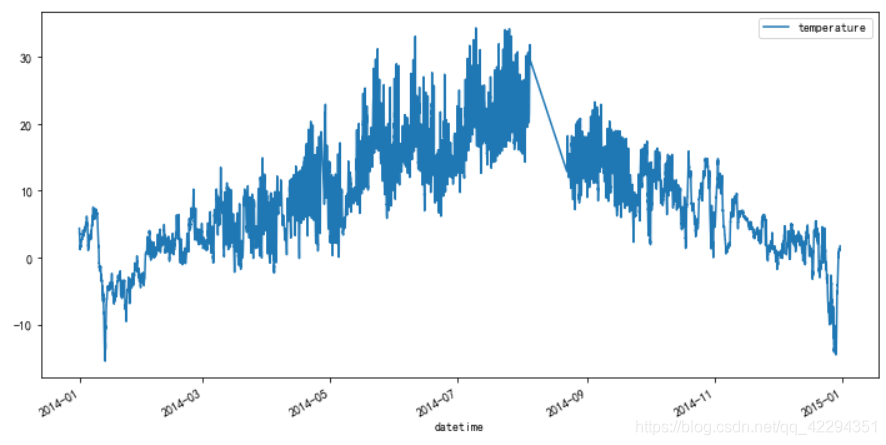
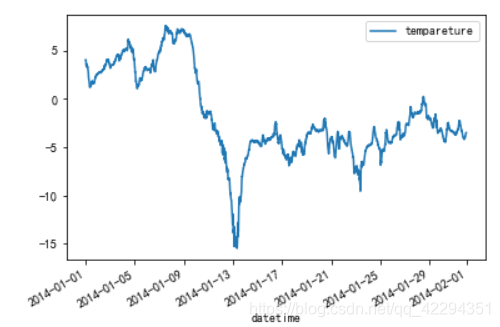
4.1.2.4 查看一月份的气温
data['2014-01'].plot();
data2[data2.month==1]['tempareture'].plot();
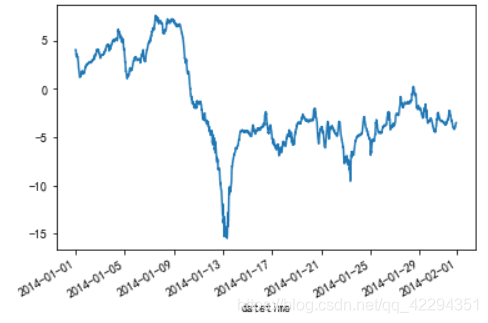
4.2 indoor表的处理
4.2.1 数据预处理
# 导入数据
data1=pd.read_csv('temperature_indoor_2014.tsv',sep='\t',header=None)
data1.head()
4.2.2 处理表头
data1.columns=['datetime','tempereture']#给列名
data1.head()
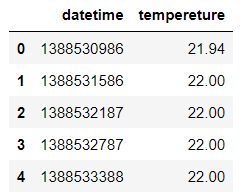
4.2.3 数据探索
data1.info()

data1.isnull().sum()

4.2.4 日期字段的转换
data1.datetime=pd.to_datetime(data1['datetime'],unit='s')
4.3 表合并
data
data1.set_index('datetime',inplace=True)
data1
data3=pd.concat([data,data1],axis=1)#合并两张表
data3
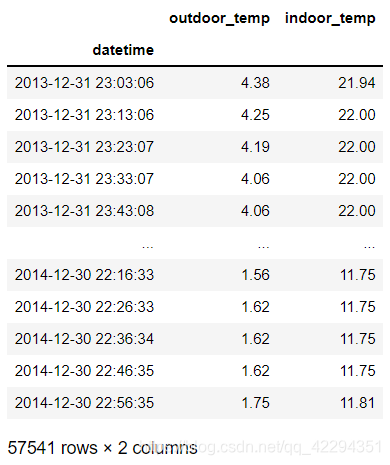
data3.columns=['outdoor_temp','indoor_temp']#修改列名
data3
4.3.1 室内外温度变化的对比
data3.plot(figsize=(10,6));
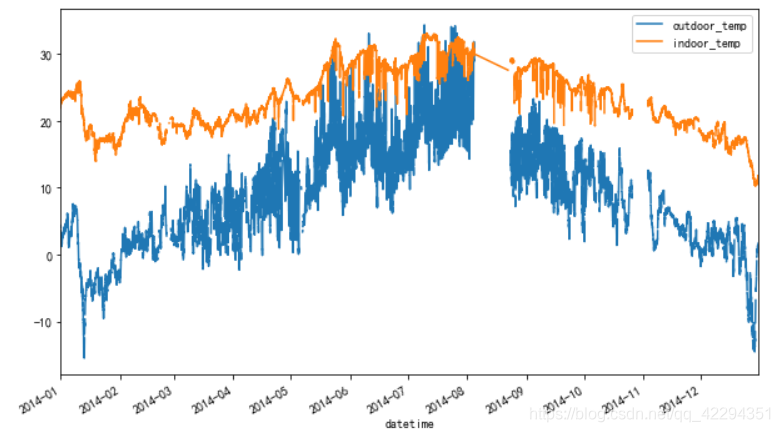
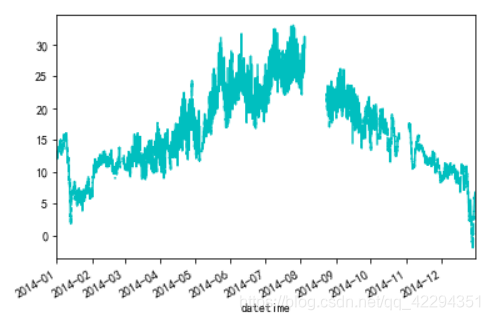
4.3.2 年度平均气温的变化
data3['avg_temp']=(data3['indoor_temp']+data3['outdoor_temp'])/2
data3['avg_temp'].plot(c='c');
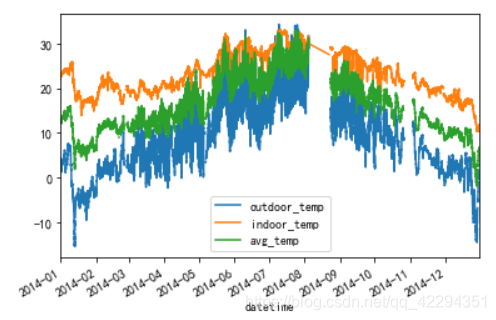
data3.plot();
五、药品销售数据
# 导入相关库
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# pd.set_option('display.max_columns', None) # 显示所有列
#pd.set_option('display.max_rows', None) # 显示所有行
import warnings
warnings.filterwarnings('ignore') #理解为不显示警告
np.set_printoptions(suppress=True) #np中不显示科学计数法
pd.set_option('display.float_format', lambda x: '%.0f' %x) #pd中不显示科学计数法
5.1 导入数据
hospital = pd.read_excel('医院2018年销售数据.xlsx')
hospital.head()
5.2 探索数据
# 查看数据基本信息
hospital.info()

#查看数据形状
hospital.shape
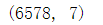
hospital.isnull().sum()

hospital[hospital.isnull().T.any()]#全部统计了后转置,对每一列,只要其中有True就让他显示,然后把为True的数据筛选出来
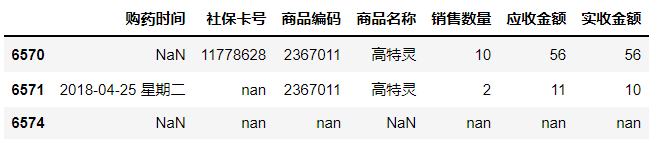
5.3 清洗数据
# 修改列名称
hospital.rename(columns={'购药时间':'销售时间'},inplace=True)#只换几个列名就用rename
hospital.head(10)
删除缺失数据 对于没有销售时间和社保卡号的数据是无效的
hospital.dropna(inplace=True)#dropna()剔除缺失值
hospital.isnull().sum()

对于销售时间应该是日期型,销售数量,应收金额和实收金额应该是数值型,即float型,而其他变量应该是字符型
hospital.销售时间
#销售时间那一列,需要把日期和星期分开
hospital['销售日期']=hospital.销售时间.str.split(' ').str[0]
hospital['销售星期']=hospital.销售时间.str.split(' ').str[1]
hospital.head()
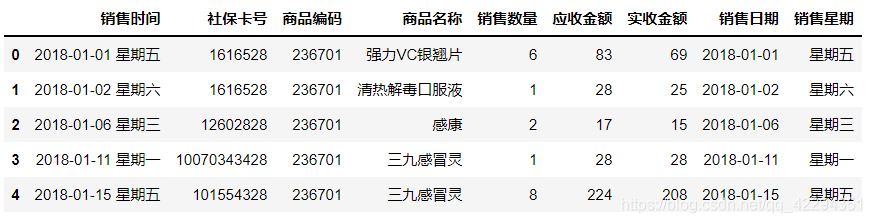
#有日期2018-2-29,18年2月没有29号所以报错,设置errors='coerce'将无效解析设置为空
hospital['销售日期']=pd.to_datetime(hospital['销售日期'],errors='coerce')
hospital.info()#检查数据类型

# 进行排序
#对数据按照时间排序
hospital=hospital.sort_values('销售时间')
hospital=hospital.reset_index(drop=True)#drop=True排序后把原本索引删掉,重新排列
hospital.head()
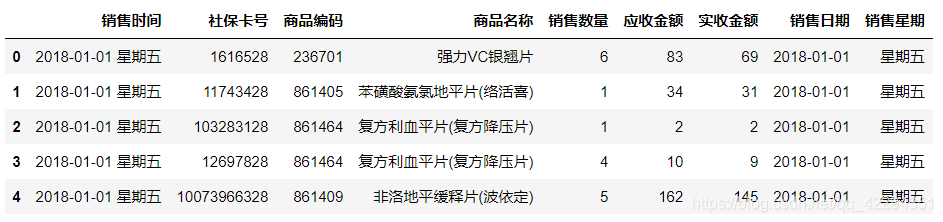
# 对数据进行统计
hospital.describe()
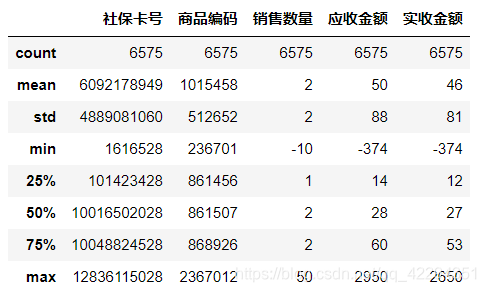
#对非数值数据进行统计
hospital.describe(include='object')

# 应收金额和实收金额应该为正,所以剔除这两个变量为负数的样本
hospital=hospital[(hospital.应收金额>0)&(hospital.实收金额>0)]
hospital.describe()
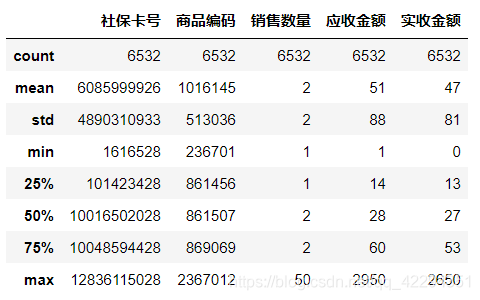
5.4 数据分析
5.4.1 月均消费次数
这里的月均消费次数定义为总次数除以月份,其中假如一个人一天买了两次药,只算做消费了一次,即计算次数的时候需要进行去重处理。
Total=len(hospital.groupby(['销售日期','社保卡号']))#以销售日期和社保卡号进行分组,分组后用len看有多少个组,代表消费了多少次
Total
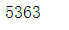
month=(hospital['销售日期'].max()-hospital['销售日期'].min()).days/30#最大日期减最小日期得到天数除30得到几个月
a=Total/month
print('月均消费次数为:',a)
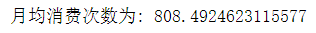
5.4.2 月均消费金额
月均消费金额为总金额除以月份,在计算总金额的时候不能去重,需要都计算上金额。
b=hospital['实收金额'].sum()/month
print('月均消费金额为:',b)
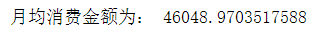
5.4.3 客单价
客单价就是总的消费金额除以总的购买次数。
c=hospital['实收金额'].sum()/Total
print('客单价为:',c)
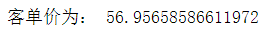
5.4.4 平均每个客户消费
消费总金额除以社保卡个数
hospital.社保卡号.nunique()
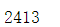
d=hospital['实收金额'].sum()/hospital.社保卡号.nunique()
print('平均每个客户消费金额为:',d)
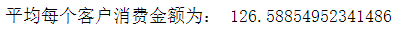
5.4.5 消费趋势
首先先来看一下每天的消费总金额的变化,把数据按天聚合,绘图,代码如下。
# 在操作之前先复制一份数据,防止影响清洗后的数据
df=hospital.copy()
# 重命名行(index)为销售时间所在列的值
df.set_index('销售日期',drop=False,inplace=True)
df.index.name='日期'
df
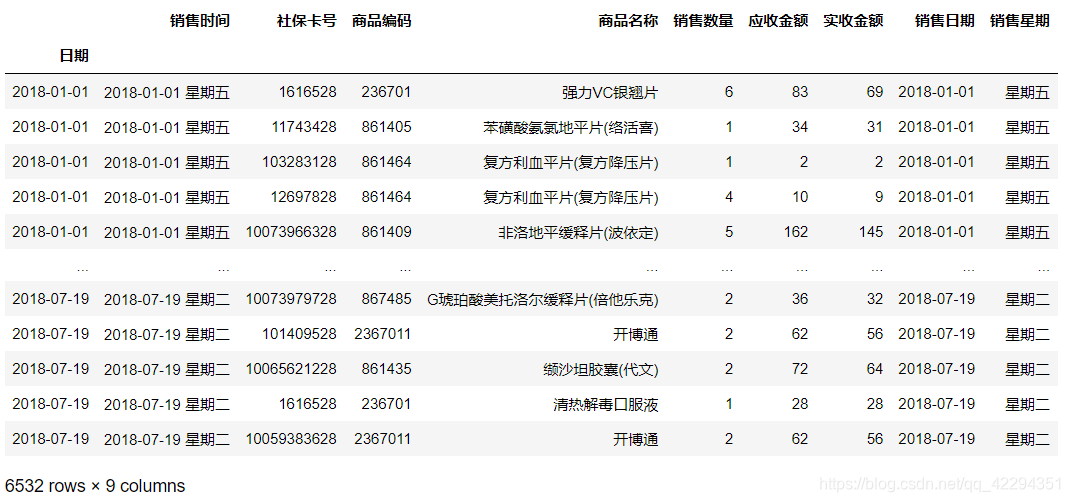
df.groupby('销售日期')['实收金额'].sum().plot();
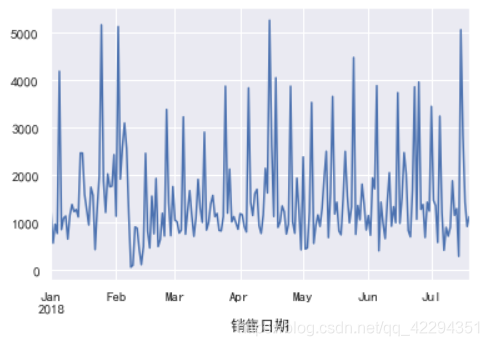
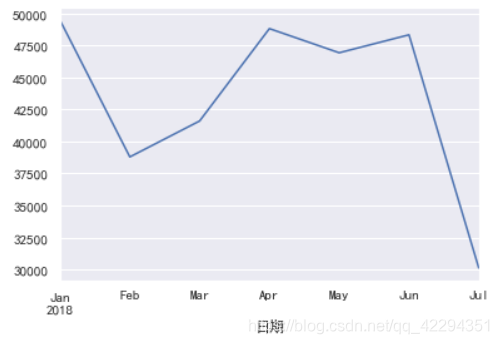
df.resample('m')['实收金额'].sum().plot();
df.resample('m')['应收金额'].count().plot(); #每月消费次数
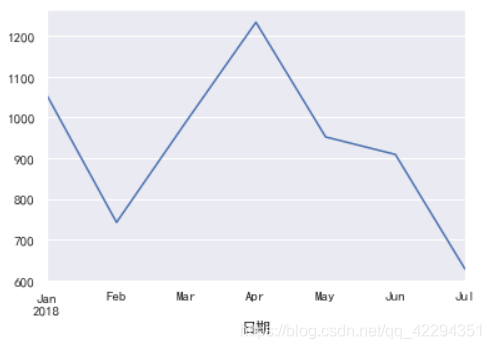
由图我们其实可以看出,该药店的销售总额和客流量基本成正比。二月份的客流量最少,同样销售业绩也最差,同样的四月份客流量最高,销售总额也最多。
但是六月份客流量变少了,而消费总额却变多了,可能是因为人均买的药更贵了,具体原因尚且不得而知,七月份的数据如此小的原因是因为七月份只统计了半个月的数据,数据不全,不能拿来做比较。
将销售数据按星期分组,得到如下结果。
df.groupby('销售星期')['实收金额'].sum().sort_values(ascending=False).plot(kind='bar');
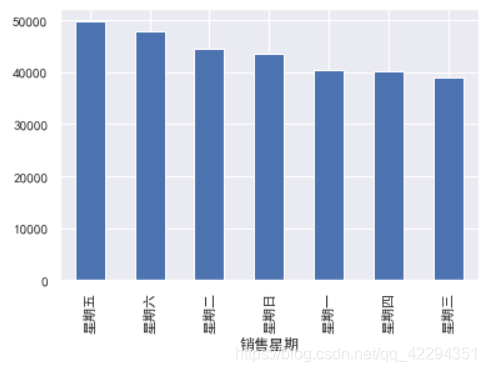
通过这里,我们可以发现,周五周六的销售总额要显著的的高于其他日期,即周五周六应该前来买药的人更多,销售的药品更多。
即每周的销售趋势是周日到周四销售总额会有波动,但是幅度不大,周五周六的销售总额相对较高,按月份比较的话,四月份的销售总额显著的高,而二月份的销售总额显著的低,猜测销售总额非常低是因为春节的缘故。
# 药品销售情况
#聚合统计各种药品的销售数量
df.groupby('商品名称')['销售数量'].sum()
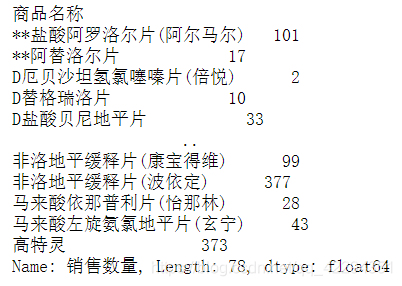
# 销售数量最多的十种药品
df.groupby('商品名称')['销售数量'].sum().nlargest(10)
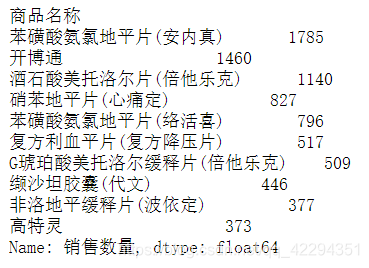
# 用条形图展示销售数量前十的药品
df.groupby('商品名称')['销售数量'].sum().nlargest(10).plot(kind='bar');
plt.xlabel('商品种类')
plt.ylabel('销售数量')
plt.title('商品销售前十');
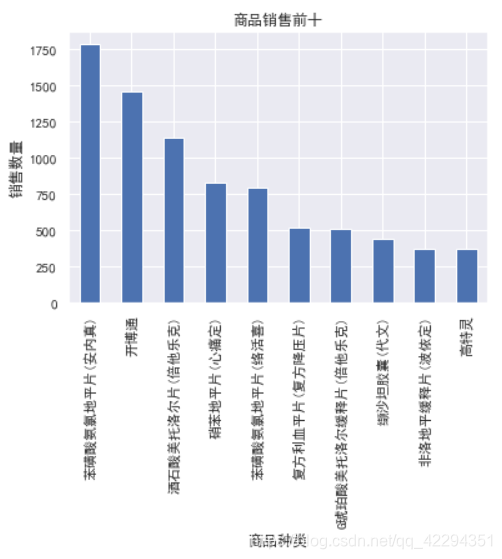
a=df.groupby('商品名称')['销售数量'].sum().nlargest(10)
a
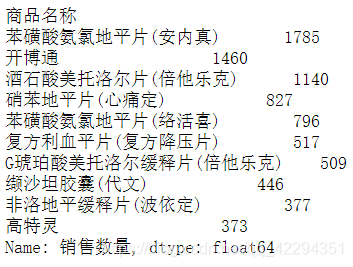
plt.bar(x=a.index,height=a)
plt.xticks(rotation=90);
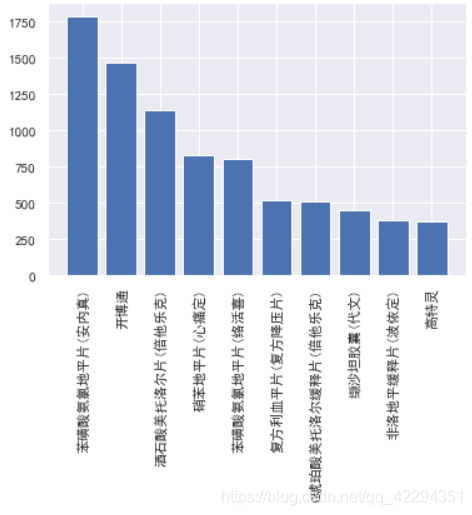
得到销售数量最多的前十种药品信息,这些信息将会有助于加强医院对药房的管理。
六、餐厅订单详情表分析
#导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
import warnings
warnings.filterwarnings('ignore') #理解为不显示警告
6.1 导入数据
raw_data=pd.read_excel("meal_order_detail.xlsx")
raw_data.head()
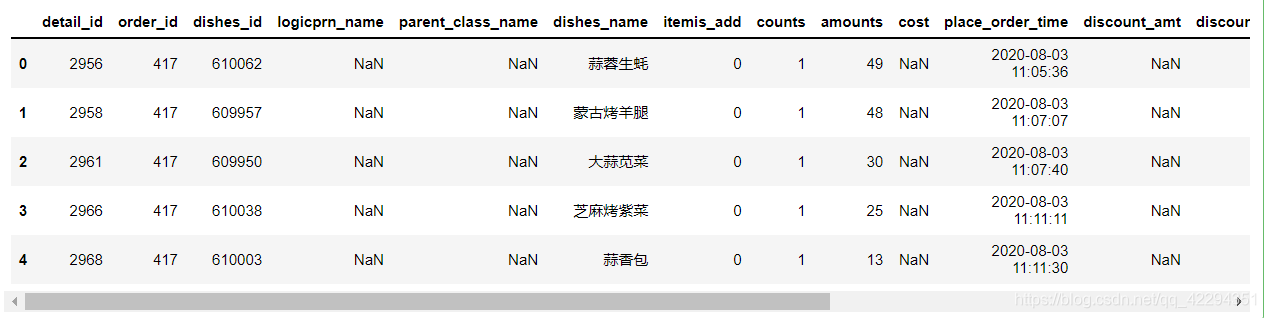
6.2 初步探索数据
df=raw_data.copy()
df.shape
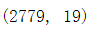
df.info()
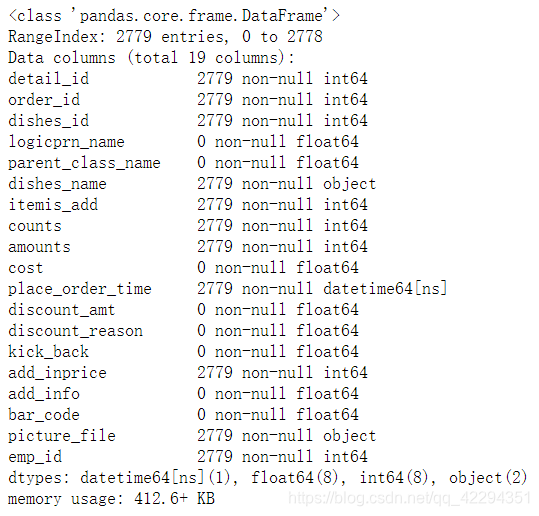
df.isnull().sum()
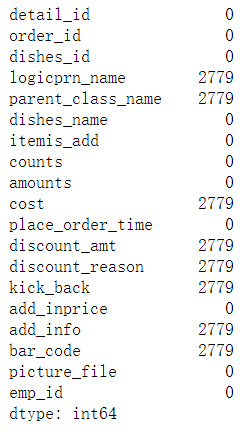
6.3 清洗数据
6.3.1 删除缺失的字段
df.dropna(axis=1,inplace=True) #inplace=False不直接修改原数据
df.shape
6.3.2 删除无用的字段
df.drop(columns='picture_file',axis=1,inplace=True)#picture_file里面放的是图片,没啥用
df.head()
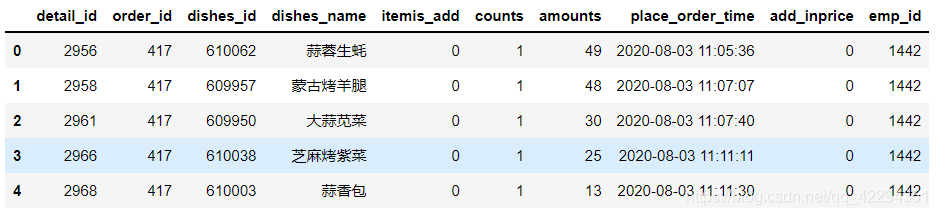
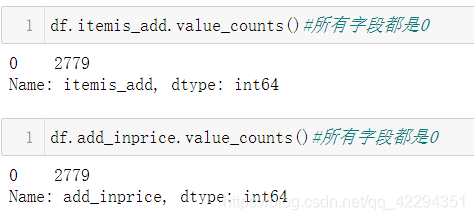
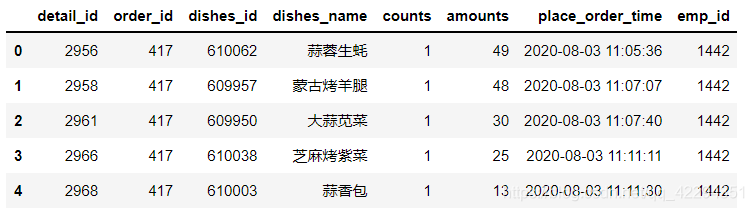
df.drop(columns=['itemis_add','add_inprice'],axis=1,inplace=True)#删除两个全0的无用字段
df.head()
6.3.3 检查是否存在重复值
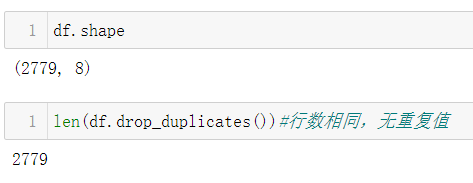
6.3.4 dishes_name字段处理
df.dishes_name.nunique()#返回非重复值统计的个数
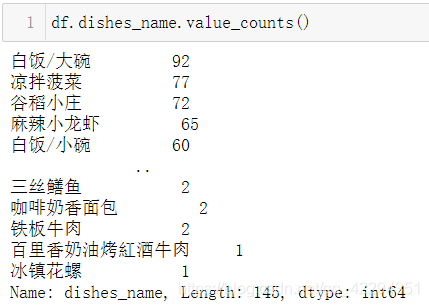
df.dishes_name.value_counts()#发现存在\r\n出现的字段名

df['dishes_name']=df.dishes_name.str.strip('\r\n')#strip()去除无用字符
df['dishes_name'].nunique()#返回非重复值统计的个数
6.3.5 添加money列(数量×价格)
df['money']=df['counts']*df['amounts']
df.head()
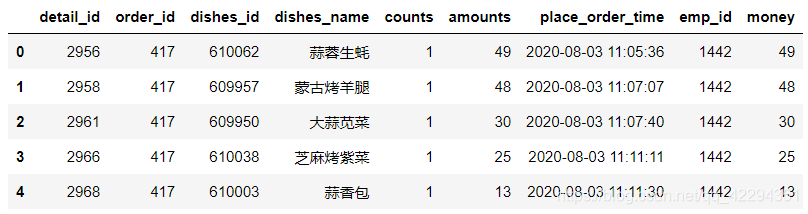
6.4 数据探索分析
6.4.1 一共有多少笔订单
df.order_id.nunique()
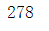
6.4.2 统计菜品价格的平均值
df.groupby('dishes_name')['amounts'].mean().mean()
6.4.3 什么菜最受欢迎
df.groupby('dishes_name')['counts'].sum().sort_values(ascending=False)#观察得到凉拌菠菜最受欢迎

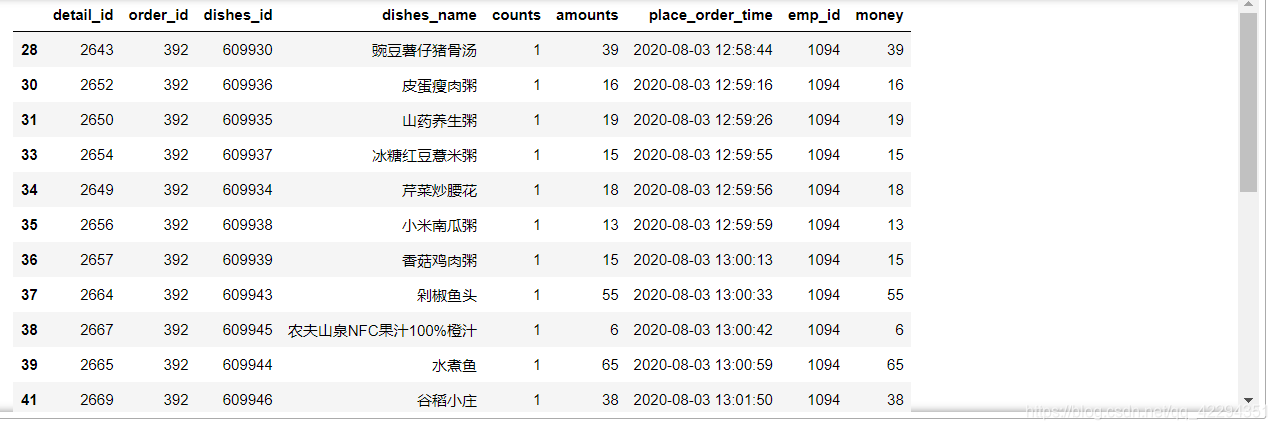
6.4.4 哪个id点的菜最多
6.4.4.1 只考虑菜的种类
df.order_id.value_counts()

df[df.order_id==392]
6.4.4.2 考虑数量
df.groupby('order_id')['counts'].sum().nlargest()

df[df.order_id==557]
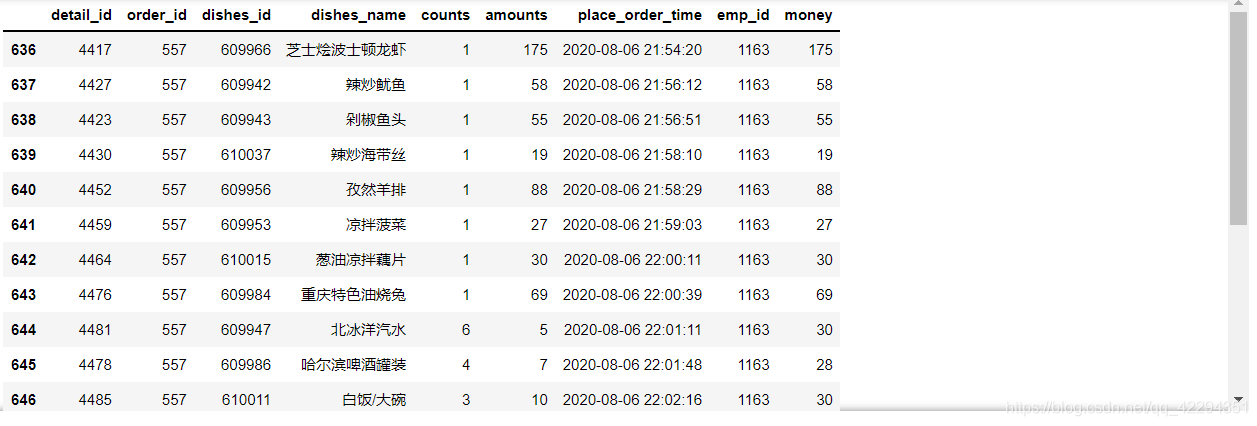
6.4.5 哪个id吃的平均菜价贵
6.4.5.1 只考虑种类
df.groupby('order_id')['amounts'].mean().sort_values(ascending=False) #菜单价求和除以种类的数量
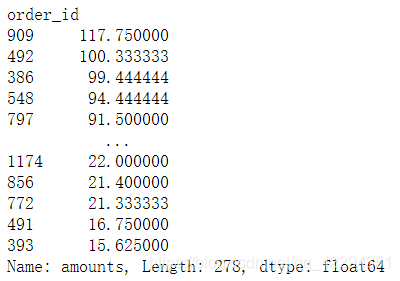
6.4.5.2 考虑数量
(df.groupby('order_id')['money'].sum()/df.groupby('order_id')['counts'].sum()).sort_values(ascending=False) #菜总价除菜品的数量
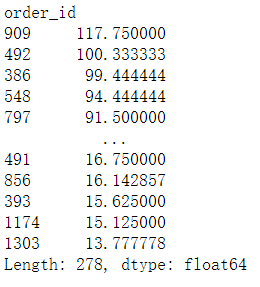
df[df.order_id==909]

6.5 添加时间相关的字段
df.place_order_time
df.set_index('place_order_time',drop=False,inplace=True)
df
df['hour']=df.place_order_time.dt.hour
df['day']=df.place_order_time.dt.day
df['weekday']=df.place_order_time.dt.weekday
df
#这里的0代表星期一,1代表星期二,对weekday这一列增加1,方便我们查看
df['weekday']=df['weekday']+1
df.head()
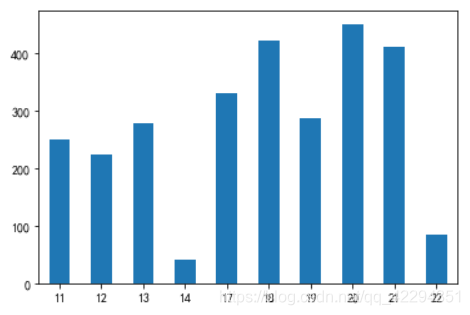
6.6 一天什么时候吃饭的人最多
df.hour.value_counts()
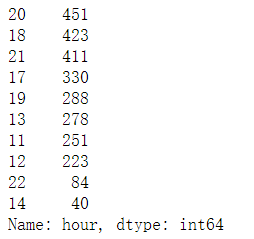
time_counts=df.hour.value_counts().sort_index()
time_counts.plot(kind='bar',rot=0);
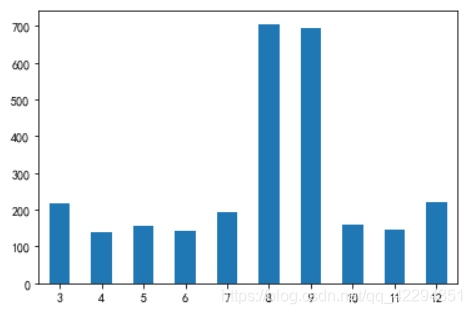
6.7 哪一天吃饭的人最多
df.day.value_counts()
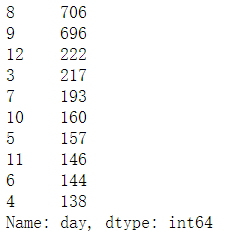
day_counts=df.day.value_counts().sort_index()
day_counts.plot(kind='bar',rot=0);
6.8 星期几吃饭的人最多
df.weekday.value_counts()
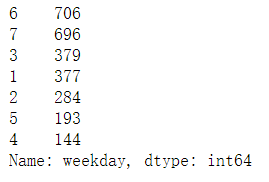
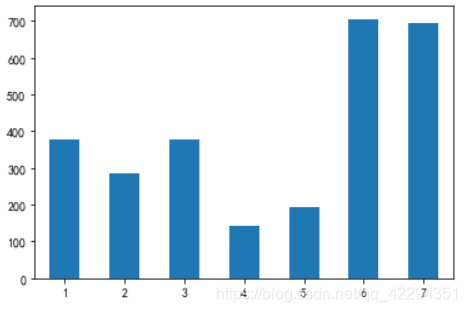
week_counts=df.weekday.value_counts().sort_index()
week_counts.plot(kind='bar',rot=0);
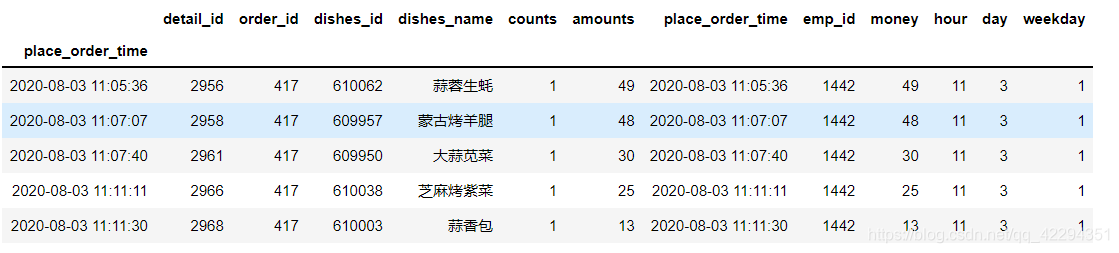
6.9 每日菜品的总价格、均价、中位数
df.head()
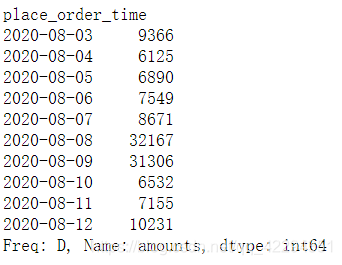
6.9.1 总价格
df.resample('D')['amounts'].sum() #只计算菜单价求和
df.resample('D')['money'].sum() #考虑数量
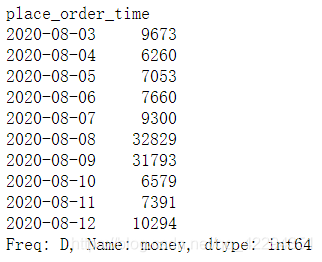
6.9.2 均价
df.resample('D')['amounts'].mean() #计算当日所有菜价的平均值
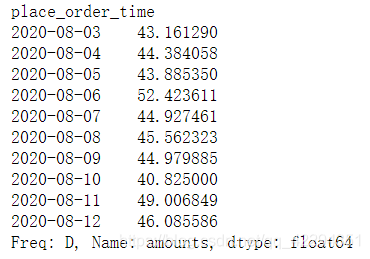
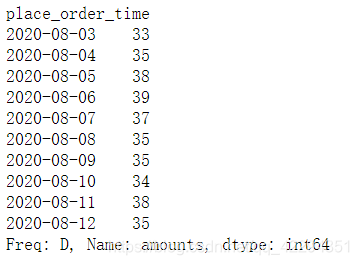
6.9.3 中位数
df.resample('D')['amounts'].median()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)