51c※视觉~合集1
我自己的原文哦~https://blog.51cto.com/whaosoft/13436882在计算机视觉领域,评估对象检测模型对于了解其准确性和性能至关重要。此评估的常用指标是交集比 (IoU)、准确率、召回率和平均准确率 (mAP)。这些指标全面衡量了对象检测模型识别和分类图像中对象的能力。在这篇博文中,我们将深入探讨每个概念,解释如何计算它们,并提供 Python 代码来演示如何计算它们。
我自己的原文哦~ https://blog.51cto.com/whaosoft/13436882
一、目标检测中的 IoU、Precision、Recall 和 mAP
在计算机视觉领域,评估对象检测模型对于了解其准确性和性能至关重要。此评估的常用指标是交集比 (IoU)、准确率、召回率和平均准确率 (mAP)。这些指标全面衡量了对象检测模型识别和分类图像中对象的能力。在这篇博文中,我们将深入探讨每个概念,解释如何计算它们,并提供 Python 代码来演示如何计算它们。
1. 交并比(IoU)

交并比 (IoU)是对象检测中使用的一个重要指标,用于测量两个边界框之间的重叠度:预测边界框和真实边界框。
IoU的公式为:
IoU=交集面积 / 并集面积
计算 IoU 的步骤:
- 交叉区域:这是预测边界框和地面真实边界框之间的重叠区域。
- 联合面积:这是预测和地面真实边界框覆盖的总面积。联合计算如下:联合=预测框面积+地面真实框面积-交叉面积
IoU 分数: IoU 范围从 0 到 1,其中:
- 1 表示预测框与基本事实完全匹配。
- 0 表示预测框和真实框之间没有重叠。
计算 IoU 的 Python 代码:
def compute_iou(box1, box2):
"""
Compute Intersection over Union (IoU) between two bounding boxes.
Parameters:
box1 (list): [x_min, y_min, x_max, y_max] of the first bounding box.
box2 (list): [x_min, y_min, x_max, y_max] of the second bounding box.
Returns:
float: IoU score.
"""
x1_inter = max(box1[0], box2[0])
y1_inter = max(box1[1], box2[1])
x2_inter = min(box1[2], box2[2])
y2_inter = min(box1[3], box2[3])
intersection = max(0, x2_inter - x1_inter) * max(0, y2_inter - y1_inter)
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = area_box1 + area_box2 - intersection
return intersection / union if union > 0 else 0.0
intersection = max(0, x2_inter - x1_inter) * max(0, y2_inter - y1_inter)
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = area_box1 + area_box2 - intersection
return intersection / union if union > 0 else 0.0在此函数中,我们通过查找两个框之间的重叠来计算交集面积。然后计算并集面积,并根据交集面积与并集面积的比率得出 IoU 分数。
2. 精确率和召回率

精确率和召回率是评估分类模型的基本指标,但它们在对象检测任务中也发挥着至关重要的作用。
精确率是指所有正预测(真阳性 + 假阳性)中正确的正预测(真阳性)的比例。在物体检测中,精度表示预测的边界框中有多少是相关的。
精确率 = 真正例 /(真正例+假正例)
召回率是指所有实际阳性实例(真阳性+假阴性)中正确的阳性预测(真阳性)的比例。召回率告诉我们模型识别所有真实对象的程度。
召回率 = 真正例 /(真正例+假阴性)
在目标检测的背景下:
- 真正例 (TP):与地面真实边界框具有高 IoU(大于定义的阈值,例如 0.5)的预测边界框。
- 假阳性(FP):预测的边界框与任何地面真实边界框没有足够的重叠。
- 假阴性(FN):模型未检测到的真实边界框。
计算精确率和召回率的 Python 代码:
def calculate_precision_recall(tp, fp, fn):
"""
Calculate Precision and Recall.
Parameters:
tp (int): Number of True Positives.
fp (int): Number of False Positives.
fn (int): Number of False Negatives.
Returns:
tuple: (precision, recall)
"""
precision = tp / (tp + fp + np.finfo(float).eps)
recall = tp / (tp + fn + np.finfo(float).eps)
return precision, recall3. 平均准确率(mAP)
平均精度 (mAP)是评估对象检测模型性能的最广泛使用的指标之一。mAP 考虑所有类别和 IoU 阈值的精度和召回率。
计算mAP的步骤:
1. 平均精度(AP):首先,我们计算每个类别的平均精度(AP) 。AP 是通过计算精度-召回率曲线下的面积获得的。
2. mAP:然后计算所有类别的平均精度分数的平均值以获得 mAP。
该过程包括:
- 按置信度得分对预测边界框进行排序。
- 迭代每个类,计算真正例 (TP) 和假正例 (FP),并生成精确召回值。
- 最后,计算每个类的AP并取平均值得到mAP。
计算mAP的Python代码:
def calculate_average_precision(recall, precision):
"""
Compute Average Precision (AP) using precision-recall curve.
Parameters:
recall (numpy.array): Array of recall values.
precision (numpy.array): Array of precision values.
Returns:
float: Average precision score.
"""
recall = np.concatenate(([0], recall, [1]))
precision = np.concatenate(([0], precision, [0]))
for i in range(len(precision) - 1, 0, -1):
precision[i - 1] = max(precision[i - 1], precision[i])
idx = np.where(recall[1:] != recall[:-1])[0]
ap = np.sum((recall[idx + 1] - recall[idx]) * precision[idx + 1])
return ap
def calculate_map(gt_df, pred_df, iou_threshold=0.4):
"""
Compute mean Average Precision (mAP) for object detection.
Parameters:
gt_df (pd.DataFrame): Ground truth dataframe.
pred_df (pd.DataFrame): Predicted dataframe.
iou_threshold (float): IoU threshold for considering a detection as a true positive.
Returns:
float: mAP score.
"""
unique_classes = gt_df['class'].unique()
ap_list = []
for cls in unique_classes:
gt_cls = gt_df[gt_df['class'] == cls]
pred_cls = pred_df[pred_df['class'] == cls]
if pred_cls.empty:
continue
pred_cls = pred_cls.sort_values(by='confidence', ascending=False).reset_index(drop=True)
tp = np.zeros(len(pred_cls))
fp = np.zeros(len(pred_cls))
gt_used = {}
for pred_idx, pred_row in pred_cls.iterrows():
gt_boxes = gt_cls[gt_cls['image_id'] == pred_row['image_id']]
best_iou = 0
best_gt_idx = None
for gt_idx, gt_row in gt_boxes.iterrows():
iou = compute_iou([pred_row['xmin'], pred_row['ymin'], pred_row['xmax'], pred_row['ymax']],
[gt_row['xmin'], gt_row['ymin'], gt_row['xmax'], gt_row['ymax']])
if iou > best_iou:
best_iou = iou
best_gt_idx = gt_idx
if best_iou >= iou_threshold and best_gt_idx not in gt_used:
tp[pred_idx] = 1
gt_used[best_gt_idx] = True
else:
fp[pred_idx] = 1
tp_cumsum = np.cumsum(tp)
fp_cumsum = np.cumsum(fp)
recall = tp_cumsum / len(gt_cls) if len(gt_cls) > 0 else np.zeros(len(tp_cumsum))
precision = tp_cumsum / (tp_cumsum + fp_cumsum + np.finfo(float).eps)
ap = calculate_average_precision(recall, precision)
ap_list.append(ap)
return np.mean(ap_list) if ap_list else 0.0总 结
IoU、Precision、Recall 和 mAP 是评估对象检测模型的重要指标。它们可以洞悉模型在检测对象、最大限度减少误报和确保检测到所有对象方面的表现。
- IoU测量预测框和真实框之间的重叠。
- 精确度关注的是积极预测的准确性。
- 召回率强调模型检测所有相关实例的能力。
- mAP是一个综合指标,它对多个 IoU 阈值和类别的精度进行平均。
通过使用提供的 Python 代码,您可以轻松计算这些指标并评估对象检测模型的性能。无论您使用的是 YOLO、SSD 还是 Faster R-CNN,这些指标都将帮助您微调模型以获得更好的结果。
....
二、图像分割算法
机器视觉系统基于数字图像中的信息进行决策。若系统算法不分主次,让所有图像数据都参与到目标识别或分类的计算过程中,机器视觉系统的实时性就很难得到保证。为了确保系统的实时性,最大限度地利用系统的能力,有必要关注"关键信息”。在机器视觉工程实践中,通常会先确定一个或多个能有效代表被测目标的量化特征,再基于这些特征完成机器决策任务,从而提高系统自动识别的能力。
图像分割是简化机器视觉算法的有效手段之一。它将图像分成一些有意义的区域,以便特征提取过程可基于这些区域提取目标的特征。此处提到的区域是指其中所有像素都相邻或相接触的集合,是像素的连通集。连通集中任意两个像素之间都存在一条完全由该集合的元素构成的连通路径。连通路径是一条可在相邻像素间移动的路径。
图像分割的基础是像素的相似性和跳变性,如灰度、纹理相似或突变等。经图像分割过程得到的区域一般互不交叠,每个区域内部的某种特性相同或接近,而不同区域间的特性则有明显差别。
图像分割的方法较多,依据处理的对象不同可分为点、线和区域分割法。若根据分割算法来分,则有阈值分割法、边缘分割法、区域分割法和形态学分割法等,如下图所示:

1 图像阈值分割
图像阈值分割(thresholding)是一种最常用的图像分割方法,可将图像按照不同灰度分成两个或多个等间隔或不等间隔灰度区间,对目标与背景有较强对比度的图像分割特别有用。主要利用检测目标与背景在灰度上的差异,选取一个或多个灰度阈值,并根据像素灰度与阈值的比较结果对像素进行分类,用不同的数值分别标记不同类别的像素,从而生成二值图像。由于物体与背景以及不同物体之间的灰度通常存在明显差异,在图像灰度直方图中会呈现明显的峰值,因此,若选择图像灰度直方图中灰度分布的谷底作为阈值,即可对图像进行分割。
阈值分割法可分为全局阈值分割法(Global Thresholding)和局部阈值分割法(localthresholding)。
- 全局阈值分割法会基于整幅图像的像素统计信息,选取固定的灰度阈值。它适用于每一幅待处理图像中光照都均匀分布,或多幅图像有一致照明的场合;
- 局部阈值分割法则基于邻域内像素的统计信息,为每个像素计算阈值。它对光线呈倾斜梯度分布或待测目标有阴影的情况特别有效,而在这类情况下全局阈值分割法通常会失效。
1.1 全局阈值分割
全局阈值分割法包括手动阈值分割(manual thresholding)和自动阈值分割
(automatic thresholding)两大类。手动阈值分割方法需要人为确定阈值;自动阈值分割方法基于图像的灰度直方图来确定灰度阈值。
1.1.1手动阈值分割
手动阈值分割法的阈值选取是关键。若阈值过高,会有过多的目标像素点被误分为背景,阈值选得过低,则会出现相反的情况。
常见的方法有P分法(P-tile)和直方图谷底法。P分法是由Doyle于1962年提出的,该方法根据先验概率来设定阈值,使目标或背景的像素比例等于先验概率。直方图谷底法选取图像直方图各峰之间的谷底作为图像分割阈值。下图显示了基于图像灰度直方图选择单个阈值或多个阈值的例子:

NlVision使用IMAQ Threshold实现手动单灰度区间的图像分割。它和其他图像分割函数都位于LabVIEW的视觉与运动→lmageProcessing→Processing图像处理函数选板中,如下图所示:

函数说明及使用可参见帮助手册:
通过使用单个灰度区间对硬币图像进行分割的示例,了解手动阈值分割实现方法,程序设计思路如下所示:
- 程序一开始先将原图coins.jpg读入内存,并使用图像显示控件显示;
- 此后,程序使用IMAQ GetlmageSize获取图像的尺寸,并为图像处理分配缓冲,以方便图像分割算法使用;
- 以上准备工作完成后,程序便进入实现图像阈值分割功能的While循环;
- While循环中代表阈值分割方法的变量Type、代表局部分割方法配置参数的变量Local、代表自动阈值分割方法配置参数的变量Automatic、代表手动阈值分割方法配置参数的变量Manual以及代表聚类分割方法配置参数的变量Number of Class被捆绑为簇,经由寄存器与其前一次的值进行比较;
- 若簇中任一参数发生变化,或者当循环执行第一步时,条件结构True分支中的图像分割代码就会被执行;
- 具体执行何种图像分割代码,由Type参数控制。Type参数对应于前面板上的Tab控件,当用户选择Manual选项卡时,程序就执行Manual分支中的IMAQ Threshold,完成对图像的人工分割;
- 默认情况下IMAQ Threshold使用1替换所有指定灰度范围内的像素值,用0替换所有灰度范围外的像素值,以生成二值图像。也可通过设置参数,使灰度区间内的像素保持原值不变,而只把灰度范围之外的背景像素值更改为0;
- 当用户在前面板上更改了任何与手动分割相关的参数时,While循环将更新图像分割的结果。
程序设计如下所示:

程序效果如下所示:

手动阈值分割方法需要人为确定阈值。由于所选定的阈值不仅作用于整幅图像,还作用于所有使用该方法处理的图像,因此它适用于可采集单幅光照分布比较均匀的图像,且能获取多幅图像之间光照相对一致的机器视觉系统。为了能消除人工设定阈值的主观性,使机器视觉系统能适应不同图像间照明不一致的情况,需要研究各种自动阈值分割方法。
项目资源下载请参见:LabVIEW图像全局阈值分割_labview阈值分割-其它文档类资源-CSDN下载
1.1.2自动阈值分割
自动阈值分割方法基于图像的灰度直方图来确定灰度阈值。由于这类算法会基于每幅图像的直方图来计算适合该图像的分割阈值,因此即使机器视觉系统采集的各个图像之间有不同的光照,它们也能正常工作。
NlVision支持5种自动阈值分割方法,包括:聚类法(Clustering)、最大类间方差法(Inter-Class Variance)、最大嫡法(Entropy) 、均匀性度量法(Metric)和矩保持法(Moments Preserving)。
其中聚类法是唯一支持将图像分割为两类以上像素点的分割方法,其余4种方法都是针对较为严格的二值分割情况而设计的。
聚类法是一种按照图像像素灰度特征的接近程度分割成多个类的迭代分割方法。常见的聚类算法有K均值(K-Mean)和模糊C均值(FuzzyCMean)算法。
K均值算法是MacQueen于1967年提出的一种解决聚类问题的经典算法。它先任选K个初始值,将它们作为类中心,并根据这些值将其余像素分别归入离它最近的类中。此后再计算新类的均值重新作为新类的中心,并迭代执行前面的分类步骤,直到新旧类均值之差小于某阈值或完全相同为止。其基本算法如下:
1、从样本集中任意选择K个对象作为初始聚类中心;
2、对于剩余样本,根据它们与这些聚类中心的距离(绝对偏差或欧氏距离),将它们分配到与其最近的类(由聚类中心代表);
3、计算每个新类中像素的均值作为新的聚类中心;
4、重复第2和3步,直至相应的新旧类聚类中心之差小于某一阈值或完全相同为止。
K均值算法假定每个样本只能属于某一类,而且若用于图像分割,在图像中的某一类或几类像素较少时,它很难保留像素较多的类别中的图像细节。
模糊C均值算法是在模糊数学基础上对K均值算法的推广,它通过最优化一个模糊目标函数实现聚类。模糊C均值算法不像K均值算法那样认为每个点只能属于某一类,而是计算每个点对各类的隶属度,用隶属度更好地描述边缘像素亦此亦彼的特点。因此,模糊C均值算法较适合图像中存在不确定性和模糊性的情况。
若仅仅要将图像分为目标和背景两类,可以使用迭代法对像素进行聚类,其算法如下:
1、选择一个初始阈值T(通常取图像的平均灰度);
2、用T将像素分割为灰度小于T的G1和大于T的G2两类,并计算G1和G2类中像素的平均灰度值m1和m2;
3、重新设定阈值T=(m1+m2)/2。
4、重复步骤2和3,直到连续迭代中的T值之差小于某一阈值或完全相同为止。
NlVision使用IMAQ AutoBThreshold和IMAQ AutoMThreshold实现迭代法和多个目标的聚类分割法。这两个VI位于LabVIEW的视觉与运动→lmage Processing→Processing图像处理函数选板中,见博文1.1.1手动阈值分割内容部分所示。
通过一个案例,了解使用IMAQ AutoBThreshold实现自动迭代聚类法的方法。
在程序中使用时,只需根据情况通过参数Method选择需要的方法即可,程序设计可见1.1.1 手动阈值分割内容部分所示。
使用迭代聚类法自动将图像coins.jpg分割为目标和背景图像的实例。程序继续沿用了1.1.1、手动阈值分割中实例的结构,运行时选择自动阈值分类选项卡Automatic中的迭代聚类法Cluster并设置目标类型Object Type为亮背景中的暗目标。观察程序运行结果可发现,目标与背景被清晰地分割开来,如下所示:

项目资源下载请参见:LabVIEW图像全局阈值分割_labview阈值分割-其它文档类资源-CSDN下载
1.2 局部阈值分割
局部阈值分割法(Local Thresholding)又称为局部自适应阈值分割法 (LocallyAdaptiveThresholding)或可变阈值处理。它在像素的某一邻域内以一个或多个指定像素的特性(如灰度范围、方差、均值或标准差)为图像中的每一点计算阈值。由于要遍历所有图像中的像素,因此邻域的大小对该算法的执行速度会有较大影响。一般来说,邻域的尺寸略大于要分割的最小目标即可。
全局阈值分割法的一个缺点是其在图像和背景灰度差异较明显时容易忽略细节。Niblack二值化算法用于解决此类问题,这种算法的基本思想是对每一个像素点f(i,j),计算其邻域内像素点的均值m (i,j)和方差2(i, j),然后根据以下逻辑对图像进行分割:
1、每个像素计算T(i, j) =m (i, j) +k 2 (i, j),其中k为偏差系数(deviationfactor),通常取0.2;
2、若f (i, j) > T (i, j) ,则将该像素归为目标,否则归为背景。
NlVision使用IMAQ LocalThreshold实现局部阈值分割法,它位于LabVIEW的视觉与运动→lmage Processing→Processing图像处理函数选板中,见博文1.1.1、手动阈值分割内容部分所示。
IMAQLocalThreshold为了增强算法的实时性和鲁棒性,提供了两种优化算法:一是使用最大类间方差法的背景纠正法,另一种是Niblack二值化算法(Niblack Algorithm)。
通过一个案例,了解使用Niblack二值化算法对图像进行分割的方法。
程序设计可见1.1.1 手动阈值分割内容部分所示,运行时选择局部阈值分割选项卡local中的Niblack算法,并设置目标类型Object Type为亮背景中的暗目标。Niblack算法的偏离参数被设置为1,窗口大小被设置为64×64(略大于字符)。
观察程序运行结果可以发现,虽然图像的亮度分布不均(中间部分的亮度高于周围亮度),但是局部阈值分割算法也能较好地对图像进行分割,效果如下所示:

项目资源下载请参见:LabVIEW图像全局阈值分割_labview阈值分割-其它文档类资源-CSDN下载
1.3 阈值分割算法比较
在使用这些图像分割方法时,常遇到背景和目标之间分界不清的问题。这种情况下,可以先对图像进行预处理,再进行分割。常用的预处理方法包括灰度变换(LUT)、直方图均衡、空域或频域滤波等。使用线灰度工具观察一条跨边缘的线段上的灰度分布,也有助于选择合适的阈值。此外,形态学处理可以对分割后的二值图像进行纠正,以滤除阈值分割过程的错误选择。
下表对上述各种灰度阈值方法进行了汇总和比较。

几种阈值分割方法比较

全局自动阈值分割的几种方法的比较
若要对彩色图像进行阈值化,必须对各个颜色分量设置阈值。只有各颜色分量都满足阈值条件的像素点才能被置为1,否则被置为0。
例如,若要对RGB彩色图像进行阈值化,可以确定要分析目标的红绿蓝各颜色分量的范围,然后再为各颜色分量指定阈值范围。HSL彩色图像的分割很有特点,由于亮度分量(Luminance)代表图像的灰度,色度(Hue)包含图像的主要颜色信息,而Saturation分量代表颜色的饱和度,因此可以选择包含所有亮度值的阈值范围,使图像分割独立于图像的灰度信息,而仅仅根据需要选择不同的色度和饱和度阈值区间即可。
NIVision使用IMAQ ColorThreshold实现彩色图像的阈值分割,它位于LabVIEW的视觉与运动→lmage Processing→Color Processing彩色图像处理函数选板中,如下所示:

函数说明及使用可参见帮助手册:

2 图像边缘分割
图像中目标的边缘是一组相连的像素,它是图像中目标的基本特征之一。这些像素位于灰度不连续(间断或跳变)的两个区域的边界上。由于各种噪声的影响,机器视觉系统采集到的图像中,目标边缘处像素的灰度变化并不都是理想的阶跃式跳变,而通常遵循渐进的变化方式。因此,可以用下图所示的模型来表示图像中目标的边缘。

边缘的模型
边缘模型中常用的参数包括边缘强度(edge strength)、边缘长度(edge length)、边缘位置(edge location)和边缘极性(edge polarity),具体所示如下所示:
- 边缘强度又称为边缘对比度,指可识别边缘相对于背景的最小灰度差异。边缘强度的大小因光照条件和目标的灰度特性不同而异。若整个场景中光照较弱,则边缘强度较低。若图像中某一目标相对于其他目标亮度很高,则较低亮度目标的边缘强度会被压低。
- 边缘长度是指能确保所设定边缘强度出现的距离,它由边缘像素灰度的变化率决定。灰度变化较缓慢的边缘,其边缘长度应较大。
- 边缘位置是指代表边缘的像素在图像中的位置坐标。
- 边缘极性代表边缘为上升沿还是下降沿,它通常用于指明搜索算法的方向。当边缘处的灰度为递增变化时,其极性为正,反之为负。
边缘分割法基于目标的边缘特征,先使用边缘检测算法检测图像中目标的边缘(如点、线、目标轮廓等),然后再利用像素点的空间关系,根据设定的条件将边缘连接为检测目标的封闭轮廓(contour)。得到的目标轮廓可作为各区域的边界,用于图像分割。
从算法实现的角度来看,可以基于提取到的目标轮廓点构建ROI数据结构,再将ROI转化为遮罩图像。此后,对遮罩图像进行填充,再与图像进行遮罩运算,即可轻而易举地将图像划分为不同区域。下图显示了使用点、线及目标边缘将图像分割为不同区域的示意图。

边缘检测算法主要是对图像灰度变化进行度量,提取图像中不连续的灰度特征,以此定位边缘点。现有的图像处理书籍和资料中多数用相当多的篇幅介绍边缘检测和图像分割。然而若考虑实时性和鲁棒性,这些算法并不见得都适用于机器视觉系统。
2.1 点检测
传统的点检测技术常基于以下模板(以3×3模板为例,但不失一般性)运算进行判别∶

如果设定一个非负的灰度阈值T,并从图像(或ROI)的左上角开始逐点从左到右、从上到下进行扫描,且对于每个像素,都以其为模板中心进行模板运算,则结果超出门限时,即可认为检测到一个孤立点,亦即有下式成立∶

传统点检测方法认为图像中孤立点与其邻域内像素的灰度(即背景)有较大差异,因此通常使用系数之和为0的模板运算获得中心像素的灰度变化,并根据该变化和阈值T来决定是否为孤立点。

虽然传统点检测方法对孤立点的检测较为有效,但它不能判断检测到的孤立点是否边缘点。此外,由于传统点检测方法计算量大,实时性较差,因此有必要寻找更适合机器视觉系统的方法。
本文讲解一种常用的点检测方法,通过限定搜索区域和搜索数量来提高检测的实时性。这种方法最简单直接的应用就是基于一维像素序列上的灰度变化,沿指定方向寻找上升边缘和下降边缘,来进行各种判断。而一维像素序列可基于图像中的任意路径获得,如线段、矩形、旋转矩形、同心圆弧、椭圆、多边形或任意形状。
下图显示了这种从像素序列一端开始搜索上升和下降边缘的简易方法。对于每个像素点,它都会通过比较该点的像素灰度与边缘阈值来判断其是否为边缘点。为了尽可能消除噪声干扰,在判定上升和下降边缘时,可在理想阈值的基础上设定一个裕量(hysteresis),当搜索到第一个大于或等于“理想阈值加上裕量”的像素时,就将该点指定为沿该线搜索到的上升边缘。紧接着,该方法将继续向前寻找第一个小于或等于“理想阈值减去裕量"的像素,找到时就将该点指定为下降边缘。如此循环往复,直到找到所有上升和下降边缘为止。

上升和下降边缘的检测
在实际工作中,由于图像中的目标可能为暗目标,因此找到的第一个边缘点也可能为下降边缘。此种情况下,找到第一个边缘以后的搜索方法与上述过程类似。
多数情况下,基于图像自身的像素分辨率找到的边缘点位置就能满足各种机器视觉检测的需求。但是在某些特殊情况下,由于传感器尺寸或成本方面的限制,即使机器视觉系统的镜头与相机传感器匹配且光照条件较好,采集到的图像也很难满足对最小分辨率的需求。这种情况下,可以使用亚像素(subpixel)边缘定位法来寻找满足系统分辨率要求的边缘点位置。
亚像素是当物理上已经无法在相邻像素间增加更多像素时,使用各种线性、抛物线或多次插值算法,在相邻像素之间插入多个“虚拟像素"以提高测量精度的手段。通常情况下,亚像素边缘点存在于图像中逐渐发生过渡变化的区域,可以利用多项式插值等多种方法获得边缘点的亚像素位置,以提高边缘点检测的精度。例如,可按照以下流程使用抛物线插值法(parabolic interpolation)进行亚像素边缘定位,如下所示:

1、基于图像像素沿某一线段寻找边缘点;
2、选择检测到的边缘像素点(xo,yo)及与其左右相邻的两个点(x-1,y-1)和(x1,y1)作为抛物线插值的3个点;
3、根据已知的3个点计算抛物线方程y=ax2+bx+c的系数a和b;
4、由于抛物线方程在x=-b*2a处有极值,因此可选择该处为相对于最近像素点的亚像素边缘。
虽然基于亚像素定位法可以提高测量精度,但是由于计算量增加,程序的实时性也会相对降低。因此在实际中总是需要在速度与精度之间进行取舍。
NIVision使用位于LabVIEW的视觉与运动→Machine Vision→Caliper函数选板中的IMAQ SimpleEdge实现上述沿一维像素序列检测边缘点的方法,如下所示:
函数说明及使用可参见帮助手册:

通过使用IMAQ Simple Edge检测零部件边缘点的实例,了解其使用方法,程序设计思路如下所示:
- 程序开始先为图像处理分配内存并指定了一条线段作为图像的初始ROI;
- 程序在执行第一个循环时,先由IMAQ Clear Overlap清除图像中的叠加图层,然后由IMAQROIProfile返回初始ROI所覆盖的一维像素序列,并绘制该ROI上的像素灰度变化曲线;
- IMAQSimple Edge可以基于事先设置的边缘灰度阈值和抗噪裕量,返回像素序列中的边缘点数量和位置。必要时也可以通过设置亚像素精度参数Sub-Pixel Accuracy为True来提高算法的检测精度;
- OverlayPoints with User Specified Size.vi可以按照检测到的边缘位置,以指定的颜色和尺寸在图像中标记出它们的位置;
- 当循环继续执行时,程序将检查控制算法执行的参数Process或Threshold Parameters簇是否被改变,或者图像控件中是否有ROl绘制事件发生;
- 当任何一个变化发生时,分支结构中的代码将被再次执行;
- 程序直到用户单击Stop按钮退出并释放内存为止。
程序设计如下所示:

程序还显示了用户绘制矩形ROI时,程序检测所有该矩形ROI上的边缘点的情况,注意,在此过程中用户设置了相对阈值方式来检测边缘,效果如下所示:

(观看视频,请点击文末原文链接)
项目资源下载请参见:LabVIEW机器视觉检测零部件边缘点_labview图像分割-其它文档类资源-CSDN下载
2.2 线检测
传统的线边缘检测技术常基于以下各种方向模板运算进行判别:
本文提出一种适合机器视觉系统的直线检测方法,思路如下所示:
1、将搜索路径从一维扩展至二维。不是沿某一条搜索路径搜索边缘,而是沿图像中多条搜索路径进行边缘检测;
2、基于检测到的边缘点,使用曲线拟合的方法确定目标边缘。
理论上来讲,该方法适合任意形式的搜索路径和可能拟合的曲线。然而,无论对于搜索路径还是最终需要拟合的边缘线来说,直线、圆(圆弧)和椭圆最为实用,因此以下将主要介绍基于这几种路径的方法。
沿矩形ROI区域内多条直线搜索边缘点的矩形耙(Rectangle Rake)是最常用的工具之一。矩形耙工具因其形状像耙子而得名,如下图所示。矩形耙基于矩形ROI内部平行于矩形ROI的多条线搜索边缘点。对于水平放置的或旋转过的水平矩形ROI,可以沿这些线从左到右或从右到左进行搜索。如果需要从上到下或从下到上搜索边缘,则可使用垂直放置或旋转过的垂直矩形ROI。与一维边缘点检测方法类似,矩形耙可以搜索各条搜索线上的上升边缘、下降边缘、首尾或所有边缘点,以及边缘强度最大的最佳边缘点。

矩形耙
同心耙(Concentric Rake)与矩形耙工作原理类似,它基于圆形或同心圆弧ROI区域内的多条线进行搜索,这些线与圆或圆弧同心。使用同心耙搜索时,既可沿顺时针方向搜索,也可沿逆时针方向搜索。如下所示:

同心耙
轮辐(Spoke)工具因其形状酷似自行车的轮辐而得名,它也基于圆形或同心圆弧ROI区域进行搜索,但与同心耙工具不同,其搜索线是一组从圆心到外边缘的辐射状线条。使用轮辐工具时,既可从圆心向外搜索,也可从外部向圆心方向搜索。如下所示:
轮辐搜索
NlVision使用位于LabVIEW的视觉与运动→Machine Vision→Caliper函数选板中的IMAQ Rake 3、IMAQ Concentric Rake 3和IMAQ Spoke 4实现矩形耙、同心耙和轮辐边缘点检测算法,如下图所示:

函数说明及使用可参见帮助手册:

NlVision使用位于LabVIEW的视觉与运动→Machine Vision→AnalyticGeometry解析几何函数选板中的IMAQ Fit Line、IMAQ Fit Circle 2和IMAQ FitEllipse 2实现基于离散特征数据点的直线、圆或椭圆的拟合,如下图所示。这些VI所使用的曲线拟合算法是在传统曲线拟合方法的基础上进行优化后得到的。

函数说明及使用可参见帮助手册:

工业中常需要对“喷雾"的角度进行测量,例如在生产汽车喷油嘴时,就可以通过检测其喷雾的角度来判断产品的质量。当喷油嘴无喷雾或喷雾的边缘夹角达不到某个指定的角度时,即可认为产品不合格。为了计算喷雾角度,需要先找到喷雾的两条边缘线。为此,可以先使用矩形耙或同心耙,获得喷雾两个边缘上的两组边缘点,再使用直线拟合得到两条边缘线。
通过使用同心耙和直线拟合检测工业喷雾装置边缘的实例,了解其使用方法,程序设计思路如下所示:
- 程序将轮询的输入量全部捆绑成簇,一开始先进行一系列准备工作,包括读入图像,为图像处理分配内存以及创建一个起始角度为180°,终止角为360°同心圆弧形的ROI;
- 随后,程序清除图像中的叠加图层,并使用同心耙函数IMAQ Concentric Rake 3沿逆时针方向(SearchDirection的值为0)检测各条线上的首尾边缘点。步长StepSize被设置为3个像素,这意味着同心耙中每隔3个像素就有一个用于搜索边缘的同心圆弧;
- 检测到的边缘点由Sub-OverlayPointswithSpecified Zize.vi以红色在图像上标记了出来;
- 最后程序在使用IMAQ Fit Line分别将检测到的两组边缘点拟合成两条直线后,用IMAQ
- OverlayLine以黄色显示在图像上。
程序设计如下所示:

程序还允许人工在图像中绘制矩形耙或同心耙或调整各类参数,以观察直线检测的效果,效果如下所示:
一旦获得两条喷雾的边缘线,就能很容易通过以下方法计算喷雾的夹角。值得一提的是,NI Vision为图像夹角测量提供了专门的函数,开发人员无须关注这些计算细节就能直接获得稳定的测量结果。

计算平面上两条直线的夹角
项目资源下载请参见:LabVIEW工业喷雾装置边缘检测_labview图像分割-其它文档类资源-CSDN下载
2.3 轮廓提取
轮廓(contour)是指可以在图像中勾勒出目标外形(shape)的一组相互连接的曲线(curve)。这些曲线由一系列目标物的边缘点组成。由曲线构成的轮廓,通常会勾勒出被测目标的外形。因此,基于目标的轮廓可以轻而易举地实现图像分割。
在Nl Vision中,为了基于目标物的轮廓对图像进行分割,可以先将提取到的轮廓信息转换为ROI,再由ROI获得遮罩图像,此后经图像的遮罩运算即可将图像划分为不同区域。下图显示了基于目标轮廓的图像分割过程。

基于目标轮廓的图像分割过程
目标的轮廓提取可分为搜索曲线种子(Search Curve Seed)、追踪曲线(Tracingcurve)、曲线连接(Curve Connection)和轮廓选择(Contour Selection)几个步骤。
其中搜索曲线种子和追踪曲线的过程又统称为曲线提取(curve Extraction)过程。曲线的种子点(Seed Point)是曲线追踪过程的起始点,合格的曲线种子点应满足两个条件,一是其边缘强度应大于设定的阈值,二是它不能属于已知曲线上的像素点。若用Pi,代表(i,j)处像素的灰度,则(i,j)处的边缘强度Ci,可由以下公式计算:

NlVision使用IMAQ Extract Contour封装了包括搜索曲线种子、追踪曲线、曲线连接和轮廓选择几个步骤在内的所有目标轮廓提取过程,它位于LabVIEW的视觉与运动→Machine Vision→ContourAnalysis函数选板中。
函数说明及使用可参见帮助手册:

IMAQExtract Contour可工作在常规模式(Normal)或均匀模式(Uniform Regions)两种模式下。当其工作在均匀模式下时,VI会假设图像中目标区域和背景区域的像素值分别为一致的灰度值,这有助于提高VI的执行效率。
通过使用IMAQ Extract Contour提取零部件工件轮廓的实例,了解其使用方法,程序设计思路如下所示:
- 程序一开始先将工件图像Clamp.png读入内存,并指定图像中的ROI区域;
- 进入主循环后,程序监测曲线提取过程的参数及图像显示控件中绘图事件(Draw),一旦有变化,程序就调用IMAQ Extract Contour从ROI中提取目标的轮廓,并由IMAQ Overlay Contour在图像中标记出最终选择的目标轮廓。
程序设计如下所示:

程序还显示了从左到右搜索ROI时所提取到的最接近ROI左侧的目标轮廓图像,效果如下所示:

项目资源下载请参见:LabVIEW提取零部件工件轮廓_labview提取轮廓范例,labview轮廓提取怎么提取全部轮廓-其它文档类资源-CSDN下载
机器视觉系统基于分割后的图像信息来提取检测目标的特征,因而图像分割的质量直接决定机器能否快速准确地基于目标特征进行决策。阈值分割和边缘分割可以满足大多数机器视觉应用的要求,但是当所采集的图像质量较差,目标和背景的灰度差别不大或视场中被测目标有交叠时,其分割效果并不理想。在这种情况下就需要使用图像的区域分割法和形态学(Morphology)分割法。
3 图像形态学分割
形态学是用来研究生物形态结构和功能结构的学科,包括生物体的外观、结构、图案以及生物体的骨骼、器官内部功能结构等。它最早由歌德在其生物学研究中倡导,强调把生命形式当作有机的系统看待,反对只注重对生物体器官的分析。
图像的数学形态学处理既可作用于经阈值化处理得到的二值图像,也可用于处理灰度图像。灰度图像的形态学处理主要通过将像素灰度值变更为其邻域内像素的灰度最大或最小值来实现灰度图像的增强,包括降噪、背景矫正和平滑渐变的灰度特征等。它也可以通过扩展或收缩目标的亮度区域来改变目标的形状,增强目标边界的对比度。二值图像的形态学处理则主要用来去除经阈值化处理得到的二值图像中不需要的信息,如噪声相互重叠的目标边界等。当然,它也可以扩展或收缩目标边界来改变其形状。
图像的数学形态学处理包含多种计算形式,其中腐蚀(Erosion)、膨胀(Dilation)和击中—击不中(Hit-Miss)是3种最基本的形态学运算形式。通过对它们进行组合,可以进一步获得更多其他组合形式的运算,如开运算(Opening)和闭运算(Closing)、内形态梯度(Inner Gradient)和外形态梯度(Outer Gradient)运算、细化(Thinning)和加粗(Thickening)运算,适当开(Proper-Opening)和适当闭(Proper-Closing)运算以及自动中值(Auto-median)运算等。图像形态学处理运算汇总如下图所示:

3.1 像素的形态学处理
图像的形态学处理常表现为一种像素的邻域运算形式,它使用具有一定形态的结构元素与图像进行形态学运算,并进而研究图像各部分的关系,以寻求各种问题的解决方案。运算过程中,以下因素直接决定形态学处理的结果:
1、结构元素的尺寸(Structure Element Size);
2、结构元素的数值(Structure Element Value);
3、待处理图像的像素边框形状(Pixel Frame Shape);
4、形态学处理算法的类型。
其中,前3项直接决定哪些像素将参与形态学处理运算,而形态学算法的类型则决定了如何基于选定的像素进行邻域计算。
结构元素的尺寸和数值对形态学处理的影响如下图所示。结构元素通常为行、列数相同的奇数矩阵形式,它将中心元素与图像中待处理的像素对齐,依据其尺寸的大小在待处理像素邻域内划定了形态学运算的范围。也就是说,运算时仅考虑被结构元素覆盖的图像像素。程序开发过程中,结构元素可以用二维数组描述,常见的尺寸有3×3、5×5和7×7等几种。若指定的数组行、列数不同,则程序应能自动截取最接近的奇数矩阵。结构元素的尺寸越大,形态学处理的计算量就越大,相应的处理速度就越低。

形态学处理的算法决定了使用何种方法基于所选出的像素获得结构元素中心所覆盖像素的新值。
腐蚀、膨胀和击中—击不中是3种最基本的形态学算法。若用Po代表中心像素,用Pi代表基于像素边框和结构元素选出的像素,则3种算法的计算方法、用途及适用的图像类型如下表所示:

腐蚀和膨胀运算既可作用于灰度图像,也可作用于二值图像,但因图像类型不同,其作用也有差异。二值腐蚀运算常用来消除图像中相对背景亮度较高的孤立像素点,或根据所选结构元素特征,细化目标的轮廓。
计算时,仅当所有Pi值均为1时,二值腐蚀运算才将Po的值置为1。也就是说,若有任一个Pi值为0,二值腐蚀运算就将Po的值置为0。二值膨胀运算则常用于消除图像中孤立于颗粒内部的孔洞(即被灰度较高的像素所包围的区域),或根据所选结构元素特征扩展目标的轮廓。
计算时,若有任一个Pi值为1,二值膨胀运算就将Po的值置为1。从逻辑运算的角度来看,二值腐蚀相当于对Pi求与运算,二值膨胀相当于对Pi求或运算。若将它们作用于同一图像,二值膨胀运算则等效于对图像的背景进行二值腐蚀运算,因此它与二值腐蚀运算的效果刚好相反。
NlVision将上述的基本形态学处理算法封装在IMAQ Morphology和IMAQ GrayMorphology中,前者用于二值图像,后者用于灰度图像。它们位于LabVIEW的视觉与运动→Image Processing→Morphology函数选板中,如下图所示:

函数说明及使用可参见帮助手册:
通过使用IMAQ Morphology对电路板图像进行连续两次腐蚀操作,滤除图像中间部位斑点噪声的实例,了解其使用方法,程序设计思路如下:
- 程序在为图像处理分配内存后,先对读入的灰度图像进行了自动阈值化处理,然后进入主循环;
- 主循环监测任何与形态学处理相关的参数变化,若用户更改任一参数,则分支结构中的IMAQ Morphology就会被执行,并将形态学处理的结果显示在图像显示控件中。
程序设计如下所示:

由于处理结果为二值图像,因此应通过图像显示控件的右键菜单将其显示调色板设置为Binary以获取最佳显示效果,如下所示:

项目资源下载请参见:LabVIEW电路板图像腐蚀操作_labview图像分割-其它文档类资源-CSDN下载
3.2 颗粒的形态学处理
颗粒是指图像中相互连通的一组非0或灰度较高的像素所构成的区域。判断一个像素是否属于某一颗粒,要看它是否与该颗粒之间具有连通性(Connectivity)。例如,填充区域中的孔洞、移除与图像边界粘连的区域、滤除不需要的区域、分离重叠区域、搜索区域中的凸壳(Convex Hull)等。经过这些算法处理后的图像更适于进行基于颗粒的定量分析、提取目标的简易模型或进行目标识别。
数字图像中与像素邻接(Adjoining)的像素有8个,但是判断邻接的像素是否属于同一颗粒,就要依据某种连通性判断准则。
常见的连通性判断准则有4连通(Connectivity-4)和8连通(Connectivity-8)两种。
- 4连通准则认为,若像素在水平或垂直方向上与另一像素邻接,则这两像素属于同一颗粒;
- 8连通准则的判断条件则相对宽松,只要像素在水平、垂直或对角线方向上与另像素邻接,则就认为它们属于同一颗粒。
若像素与其水平或垂直方向上邻接像素的距离为D,则4连通认为像素与距其为D的邻接像素属于同一颗粒,而8连通则认为距离像素为D或D的像素与其属于同一颗粒。下图显示了4连通和8连通的结构,以及分别使用它们对同一图像中的像素进行判断时所得到的不同结果。
确定了连通性判断准则,就可以将二值图像中每个连通区域标记(Label)为能被独立识别的颗粒,以方便图像的分割和处理。
图像标记过程搜索二值图像中相互连通的各组像素(即颗粒),并将属于同一颗粒的像素值全部更改为某一固定的标记值,将二值图像的背景标记为0。考虑标记值等效于像素的灰度,可以使用8位或16位对标记值编码,这样就能直接将标记后的图像作为8位或16位灰度图像进行保存。
由此可知,图像标记过程的输入图像为二值图像,但其输出却是含有为每个颗粒都设置灰度标记值的灰度图像。其中灰度标记值的数量等于图像中颗粒的数量再加上用于背景的灰度标记值0。
图像标记过程要解决的另一问题是根据连通性判断准则寻找能快速确定各个独立颗粒的搜索算法。NI Vision将图像标记过程封装在位于LabVIEW的视觉与运动→lmage Processing→Processing函数选板的IMAQ Label中,如下图所示:

函数说明及使用可参见帮助手册:

但是NI的相关文档中并未说明该函数具体使用了何种搜索算法。图像标记最为常见的搜索算法如下:
1、逐行扫描像素,找到第一个非0像素作为种子点,为其设置专门的标记值;
2、从种子点开始按照连通性判断准则沿各个方向搜索与其连通的像素,并将其置为与种子点相同的标记值;
3、以各个连通的像素点为新的起点,沿各个方向搜索与其连通的未标记像素,并将其置为与起点相同的标记值。不断重复该过程,直到所有分支上的像素都被标记为止;
4、重新扫描图像中未被标记的点,将其作为种子点,重复步骤1到步骤3,直到所有像素均被标记为止。
虽然上述搜索算法比较直观,但其效率并不高,因此近几年涌现了大量的快速标记算法。例如,下述基于行程的标记方法就更快一些。
1、从第一行开始扫描图像,把其中连续的由非0像素组成的序列组成一个块,为其按递增的顺序设置标记值;
2、从第二行开始逐行扫描所有行里的块。如果它与前一行中的所有块都没有连通,则给它一个新的标记值;如果它仅与上一行中一个块连通,则将上一行的那个块的标记值赋给它;如果它与上一行两个以上的块有连通,则将当前和块及其相连的块标号均设置为上一行中块的最小标号;
3、重复步骤2,直到所有像素均被标记为止。
通过一个基于标记值从图像中分割出面积最大的标记区域的实际例子,了解其使用,程序设计思路如下:
- 程序一开始先为源图像和标记图像分配缓冲,然后执行对图像进行标记的LabelGraylmg.vi,它会先使用IMAQ Threshold函数对输入的灰度图像进行阈值化处理;
- 用IMAQ Morphology对阈值化得到的二值图像进行增强处理,然后再对二值图像中的颗粒进行标记;
- IMAQQuantify基于输入的遮罩图像对灰度区域进行统计,由于所分析的图像和遮罩图像均为LabelGraylmg.vi输出的标记图像,因此IMAQ Quantify输出的针对各颗粒的区域报告数组(Region Reports)簇元素中,灰度均值Mean Value就应恰好为各颗粒的标记值;
- MaxAreaIndex.vi基于Region Reports数组元素簇中的颗粒面积Area (Pixel)字段,寻找所有标记的颗粒中面积最大的一个,并返回其在数组中的索引;
- 使用该索引,就能从数组中得到面积最大的颗粒所用的标记值,而函数IMAQ LabelToROl就具备将一个或多个标记值(封装在数组中)对应的颗粒转换为ROl的能力。
程序设计如下所示:

效果如下所示:

项目资源下载请参见:LabVIEW从图像中分割出面积最大的标记区域_labview图像分割-其它文档类资源-CSDN下载
4 图像区域分割
区域分割是将图像按照相似性准则分成不同区域的过程,主要包括:基于形态学的分水岭分割法和区域生长、区域分裂合方法等。
分水岭法是基于拓扑理论的数学形态学的分割方法。其基本思想是:把图像中的颗粒看作测地学上的盆地,其中每一像素的灰度值表示该点的深度,每一个局部极小值及其影响区域称为集水盆地(Catchment Basin),而集水盆地的边界则形成分水岭。下图用一个简单的图像来说明分水岭分割法的原理。它首先计算图像的距离场,用像素到颗粒边界的最近距离作为它们的标记值。其次,它将距离场看作地形图,颗粒被看作盆地,而像素的标记值则被看作盆地各处的深度。若在距离场图像中画如图(b)所示的直线,则可得到图(e)所示的地形剖面图。
分水岭算法的实现可通过水淹过程来说明。假定水均匀地对盆地进行填充,则盆地中的最低点(离边界较远的点)首先被淹没,然后水会逐渐填满整个盆地。当水位到达一定高度的时候将会溢出,这时就可以在水溢出的地方划出分水岭。如果用颗粒的标记来模拟对盆地的填充过程,则重复上述过程直到整个图像上的点全部被淹没,这时所划出的一系列分水岭就可以将各个盆地分开,如图 (d)所示。分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声会使分水岭算法产生过度分割的现象。

下图对上述3种基于标记的分割过程进行了汇总。假定待分割的图像为已经过图像增强过程处理后的灰度图像,则先要对该图像进行全局或局部阈值化处理,以获得二值图像。由于经阈值化操作得到的二值图像中常含有噪声颗粒,而且感兴趣的颗粒可能已经被损坏或者被图像边界切断,因此在正式进行分割前,一般先要用形态学处理过程剔除噪声颗粒,对感兴趣的颗粒进行填充并剔除边界颗粒。经过这些修正操作后的二值图像中的颗粒不仅能更真实地代表目标,而且更便于分割。

区域生长是一种古老的图像分割方法,最早的区域生长图像分割方法是由Levine等提出的,其基本思想是将具有相似性质的像素集合起来构成区域。该方法先从图像中选定要分割目标内的一个像素或小块作为种子,再根据某种事先确定的准则,将邻域中与种子区域具有相同或相似性质的像素或区域与种子区域合并,此后继续将最新合并的像素或区域又作为新的种子继续进行合并的过程,直到再没有满足条件的像素能被包括进来为止。这种方式的关键是基于灰度、纹理、颜色等信息,选择合适的初始种子像素或区域和合理的生长准则。T.C.Pong等提出的基于小面(facet)模型的区域生长法是区域生长法的典型代表。
形态学重构(Morphological Reconstruction)可理解为一种有效的区域的生长方法。它基于源图像和一个与源图像大小相同且包含种子区域的标记图像(Marker lmage),对灰度图像或二值图像中的目标进行重构,以实现图像分割。在重构过程中,源图像在功能上相当于遮罩,标记图像用来对重构过程进行记录。重构的起始位置由标记图像中的种子区域或一组源图像中的种子像素来确定。
通过实现分水岭算法,来了解其使用方法,程序设计思路如下所示:
- 实例一开始先照例读取图像文件,为后续操作分配内存,随后进入主循环;
- 若主循环中监测的用户界面参数控件有变化,则程序就按照这些参数执行分支结构中的代码;
- 其中IMAQ Threshold用于对图像进行阈值化获取细胞的二值图像,IMAQRemoveParticle通过3次腐蚀运算来剔除噪声,IMAQConvex Hill对颗粒进行填充,而IMAQ RejectBorder则用于剔除边界颗粒;
- 经过这些优化处理后,二值图像中的颗粒更接近真实的血红细胞,且更便于后续对分支结构中代码所实现的4种算法进行图像分割。
程序设计如下所示:

效果如下所示:

项目资源下载请参见:LabVIEW图像区域分割算法_labview图像分割-其它文档类资源-CSDN下载
图像分割的质量直接决定机器能否快速准确地进行决策。当所采集的图像质量较差、目标和背景的灰度差别不大或视场中被测目标有交叠时,需要使用图像的形态学分割法和区域分割法来代替阈值分割法和边缘分割法。图像的数学形态学处理通常使用具有一定形态的结构元素与图像进行形态学运算,并进而研究图像各部分的关系,以解决噪声抑制、特征提取、边缘检测、图像分割、形状识别、纹理分析、图像恢复与重建、图像压缩等图像处理问题。它既可作用于经阈值化处理得到的二值图像,也可用于处理灰度图像。
....
三、语义分割、实例分割、全景分割
在计算机视觉中,术语“图像分割”或简称“分割”是指根据某些标准将图像分成像素组。 分割算法将图像作为输入并输出区域(或片段)的集合,这些区域(或片段)可以表示为:A. 轮廓集合,如下图所示:B. 一个掩码(灰度或颜色),其中每个段被分配一个唯一的灰度值或颜色来识别它。如下图所示:
什么是超像素
当我们根据颜色、纹理或其他低级基元对像素进行分组时,我们将这些感知组称为超像素——Ren和 Malik (2003)推广的一个术语。

上图中使用动画显示了超像素算法的输出。请注意,分割算法只是将具有相似颜色和纹理的像素分组。它不是试图将同一对象的各个部分组合在一起。
什么是语义分割 在语义分割中,目标是为图像中的每个像素分配一个标签(汽车、建筑物、人、道路、人行道、天空、树木等)。

上图 显示了语义分割的结果。掩码中的人用红色像素表示,草为浅绿色,树木为深绿色,天空为蓝色。 我们可以通过简单地检查该像素的掩码颜色是否为红色来判断哪些像素属于“人”类,但我们不能说两个红色的掩码像素属于同一个人还是不同的人。
什么是实例分割
实例分割是一个与目标检测密切相关的概念。但是,与对象检测不同,输出是包含对象的掩码(或轮廓)而不是边界框。与语义分割不同,我们不会标记图像中的每个像素;我们只对寻找特定对象的边界感兴趣。

上图显示了我们用Mask R-CNN的实例分割算法的示例输出。我们看到每个人的面具颜色不同,因此我们可以将它们区分开来。然而,并不是每个像素都有与之关联的类标签。
什么是全景分割
全景分割是语义分割和实例分割的结合。每个像素都被分配了一个类(例如人),但是如果一个类有多个实例,我们就知道哪个像素属于该类的哪个实例。

如上图所示,每个像素都有一个不同的颜色编码标签。例如,天空被编码为蓝色,树木被编码为深绿色,草被编码为浅绿色,人们被染成黄色、红色和紫色的不同部分。黄色和红色都指向同一个类【人】,但指向同一个类的不同实例。我们可以通过查看蒙版颜色来区分不同的人。
参考链接:https://learnopencv.com/image-segmentation/
....
四、直方图均衡揭秘
像 Vision Pro 一样提高图像对比度

了解图像直方图
在深入均衡之前,让我们先了解一下图像直方图。
直方图只是一个图表,显示图像中有多少像素具有每种可能的亮度级别(从 0 = 纯黑色到 255 = 8 位灰度图像的纯白色)。
读取直方图:
- 左偏直方图?→ 图像大多是深色的
- 右偏直方图?→ 图像大多是明亮的
- 窄直方图?→ 低对比度(细节被压缩)
- 宽而平坦的直方图?→ 高对比度(细节分布良好)
直方图有助于诊断曝光问题并指导阈值和对比拉伸等增强技术。
什么是直方图均衡?
直方图均衡重新分配像素强度以最大限度地提高对比度。它的工作原理是:
- 计算图像的直方图
- 计算累积分布函数 (CDF)
- 重新映射像素值,使直方图分布更均匀
为什么有效
- 如果图像太暗(像素聚集在 0 附近),则均衡会将它们拉伸到整个 0-255 范围内
- 如果图像太亮(像素接近 255),它会使某些区域变暗以平衡对比度
结果?均衡后,云、水纹理和阴影变得更加清晰!
全局均衡与自适应均衡 (CLAHE)
1. 全局直方图均衡
- 一次处理整个图像(在 OpenCV 中使用)cv2.equalizeHist()
- 最适合:均匀照明的图像
- 缺点:会使某些区域过亮并放大噪点
2. 自适应均衡(CLAHE — 对比度有限 AHE)
- 将图像划分为小图块并分别均衡每个图块
- 通过削波极端直方图箱来防止噪声放大
- 更适合:不均匀的照明(例如,同一图像中的阴影和高光)
OpenCV 中的 CLAHE:
import cv2
# Load image in grayscale
img = cv2.imread('input.jpg', cv2.IMREAD_GRAYSCALE)
# Apply CLAHE
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
clahe_img = clahe.apply(img)参数:
- clipLimit→ 控制对比度限制(更高 = 更激进)
- tileGridSize→ 更小的图块 = 更本地化的增强
何时使用直方图均衡
✅ 医学成像(X 射线、MRI、CT 扫描)— 增强微弱的细节
✅ 卫星和航空图像 — 提高朦胧或光线不足的场景
✅中的可见度 低光摄影 — 揭示暗图像
✅中隐藏的细节 计算机视觉预处理 — 帮助边缘检测、OCR 和物体识别
限制和何时避免
❌ 已经高对比度的图像 →均衡可能会降低质量
❌ 嘈杂的图像 → 可以放大颗粒感(使用 CLAHE 来减少这种情况)
❌ 彩色图像 → 直接将均衡应用于 RGB 通道会扭曲颜色(首先转换为 HSV/LAB)
❌ 不可逆 — 一旦应用,您将无法恢复到原始直方图
🛠️ 快速 OpenCV 指南:只需几行即可增强图像对比度
全局均衡
import cv2
img = cv2.imread('input.jpg', cv2.IMREAD_GRAYSCALE)
equalized = cv2.equalizeHist(img)
cv2.imshow('Original', img)
cv2.imshow('Equalized', equalized)
cv2.waitKey(0)CLAHE(自适应均衡)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
clahe_img = clahe.apply(img)直方图均衡是一种简单而强大的增强图像对比度的工具。无论您是处理医学扫描、卫星图像,还是只是改善深色照片,它都可以使隐藏的细节可见。
关键点:
✅ 对均匀照明图像
✅使用全局均衡 使用 CLAHE 进行非均匀照明(更好的局部对比度)
✅ 避免在已经高对比度或嘈杂的图像上过度使用它
....
五、16种图像二值化方法
ImageJ中图像二值化方法介绍
概述
二值图像分析在对象识别与模式匹配中有重要作用,同时也在机器人视觉中也是图像处理的关键步骤,选择不同图像二值化方法得到的结果也不尽相同。本文介绍超过十种以上的基于全局阈值的图像二值化方法,其中最大值为255表示白色, 0 表示黑色,H表示图像直方图。imageJ重要开源分支Fiji中已经实现了全局自动阈值16种方法。
ImageJ演示
首先来看一下原图,是一张人体细胞组织的图像,显示如下:

各种二值化方法生成的对应的二值图像图像显示如下:

迭代方法:
默认方式是通过迭代方法来求取阈值T,通过假设阈值T来分割图像为两部分,对各个部分求取均值M1与M2假设T' = (M1+M2) 不等于T则令T= T'然后继续迭代直到两者相等。
Huang阈值分割法:
方法来自于Huang L-K & Wang M-JJ模式识别论文《ImageThresholding By minimizing the measure of fuzziness》具体可以自己看论文。
InterModes阈值分割:
该方法假设直方图是一个双峰模式的直方图,对直方图使用平滑滤波迭代多次,知道只剩下两个最大的峰J与K则阈值为T=(J+K)/2, 如果图像形成直方图只会有一个单峰或者有大片平坦区域的时候,该方法不太适合。
IsoData阈值分割:
该方法基于Ridler, TW&Calvard的论文《Picture thresholding using an iterative selection method》该方法通过给定一个随机阈值假设127把图像分为对象与背景进行分割,计算两部分的均值,不断迭代,直到阈值大于复合均值为止。最终阈值为:阈值 = (背景像素均值+对象像素均值)/2。感兴趣可以自己看Paper。
Li阈值分割:
基于Li的最小交叉熵阈值迭代方法,感兴趣者可以看论文《Minimum CrossEntropy Thresholding》了解更多细节。
MaxEntropy(最大熵值分割):
基于Kapur-Sahoo-Wong的《Maximum Entropy thresholdingmethod》方法实现该算法,ImageJ Fiji中已经实现。
均值方法分割:
使用灰度图像计算所有像素值的均值作为阈值实现图像二值化分割方法。
MinError(最小错误):
迭代算法基于Kittler与Illingworth的最小错误阈值分割方法,初始开始迭代的阈值为均值。除了ImageJ中已有实现,此方法在MATLAB中也有实现。
Minimum(最小阈值):
该方法类似于中间帧模式(InterModes),都是假设直方图有两个波峰,通过均值平滑滤波最终得到两个本地最大的波峰,阈值等于yt-1>yt<=yt+1。该方法主要用于细胞图像分析,相关论文见《TheAnalysis of cell images》。MATLAB中同样也实现了该方法。
Moments(几何矩阈值):
该方法是根据Tsai.W的论文《Moment-preserving thresholding: anew approach》
Otsu阈值
Otsu主要是图像直方图进行阈值分类,从0~255之间,然后求它们的最小内方差对应直方图灰度索引值作为阈值实现图像二值化,OpenCV中已经实现,而且是OpenCV2.x全局阈值二值化方法。
Percentile阈值
该方法假设前景像素ptile=0.5,然后对直方图按照灰度强度从0~255作为每个阈值分割通过迭代寻找最小比重值,最终得到阈值T。
RenyiEntropy(雷尼熵阈值分割)
跟最大熵值方法类似,唯一不同是用Renyi熵计算公式取代广义熵值公式。

最大熵值为:

其中q取值不同决定阈值不同。通常q取1或者2。
Shanbhag(阈值分割)
该方法同样是基于直方图熵值实现的阈值分割方法。具体可以参考《Utilization of information measure as a means of image thresholding》了解原理。
Triangle(三角阈值分割)
该方法是假设直方图只有一个波峰(单峰直方图)使用如下方法求得最大距离对应的直方图灰度值即为阈值。OpenCV在其3.x版本中已经实现该方法。

Yen(阈值分割)
该方法是基于直方图数据的最大相关条件实现的二值图像分割方法。
16种方法Java源代码实现下载地址:
https://github.com/fiji/Auto_Threshold
....
六、图像分割详解
从传统方法到深度学习大模型
什么是图像分割?
图像分割可以精确地划分边界,使模型能够像素级地理解图像内容。例如,假设您正在分析一张道路照片。通过图像分割,您可以识别所有与道路完全重合的像素。这样,您得到的就不是一个简单的标签,而是一张详细的地图,显示道路在图像中的精确形状、边界和位置。

图像分割、分类与检测
图像分割与分类和检测一样,是理解和表示视觉数据内容的常用方法。它们之间的区别如下。
1. 图像分类
分类是计算机视觉中最简单的形式。它可以预测图像的总体类别,例如在“猫”和“狗”之间进行选择。但它无法告诉你这些物体具体在哪里。如果同一张照片中同时出现狗和猫,标准的分类器通常只会选择其中一个,因为它为每张图像分配一个标签。而多标签图像分类模型则会将图像同时标记为“猫”和“狗”。

2. 目标检测
目标检测不仅能对图像中的物体进行分类,还能通过在每个检测到的物体周围绘制边界框来显示它们的位置。虽然检测解决了定位问题,但它生成的边界框只能粗略估计物体的位置和形状。

3. 图像分割
分割技术能够提供更精细、像素级的对象定位。它并非使用边界框,而是创建掩码来精确勾勒出每个对象所占据的像素范围。这使得分割技术在需要精细空间感知能力的任务中尤为有用,例如自动驾驶汽车。在这些任务中,系统不仅需要检测到道路的存在,还需要识别道路的精确路径和边界,以确保车辆始终行驶在道路上。
图像分割类型:语义分割、实例分割和全景分割
图像分割可以大致分为三大类:语义分割、实例分割和全景分割。
语义分割
语义分割根据图像中每个像素所代表的内容对其进行分类:道路、天空、汽车、人,而不区分具体的个体。例如,
如果一张照片中有四辆车,所有汽车像素都共享同一个标签:汽车。模型理解图像中包含什么,但无法区分哪个具体是哪个对象。这使得语义分割非常适合表面分析、土地覆盖制图或材料分类等任务,在这些任务中,识别类别比追踪单个对象更为重要。
实例分割
实例分割更进一步。这项任务不仅识别对象类别,还能区分同一类别的不同实例。因此,图像中的每辆车不再被标记为同一个车辆分割区域,而是拥有各自独特的掩码,并带有“车辆 1”、“车辆 2”等标签。这使得模型能够区分属于同一类别的多个对象。
全景分割
全景分割将语义分割和实例分割结合起来,形成一个统一的方法。它为单个对象实例(例如人或车辆)分配独特的掩码,同时将背景区域(例如天空、道路或草地)标记为单个分割区域,因为这些区域没有多个实例。这使得我们能够全面理解场景,既捕捉到独特的对象,也捕捉到环境的整体结构。

传统分割技术
在深度学习成为图像分割的默认方法之前,人们使用多种传统方法,根据颜色、强度或纹理来分割图像区域。这些技术至今仍然非常有用,尤其是在不需要神经网络全部权重的情况下。
阈值
阈值分割是最简单的图像分割技术之一。它根据像素的强度值将图像分割成前景和背景。当物体与其背景之间存在明显差异时,例如白纸上的黑色文字,阈值分割就非常有用。

颜色空间分割
基于颜色的分割方法将颜色值相似的像素分组。与亮度不同,这种方法侧重于颜色,因此在图像中不同物体可以通过颜色区分时效果很好,例如区分照片中不同颜色的水果。

边缘检测
基于边缘的分割方法通过检测像素强度的急剧变化来识别物体边界。它突出图像中形状的轮廓,因此可用于识别不同的物体或结构细节,例如建筑物、道路或树叶的边缘。

分水岭分割
分水岭分割法将图像视为由山丘和山谷组成的地形。它从低洼区域“淹没”图像,并在两股“洪水”交汇处标记边界。这有助于分离接触或重叠的物体,例如显微图像中的硬币或细胞。

传统细分技术的优缺点
这些方法快速且轻便。但是,它们对光照变化、阴影和纹理变化非常敏感。
因此,它们通常用作深度学习模型的预处理或后处理步骤,而不是完整的解决方案。
它们还具有不需要任何标记训练数据的优势,这使得它们非常适合在受控环境中进行快速实验或分析。
深度学习在分割中的应用
深度学习彻底改变了图像分割方式。现代模型不再依赖手工调优的滤波器或边缘检测器,而是直接从数据中学习标记每个像素,从而比任何基于规则的系统更好地捕捉形状、边界和上下文信息。目前已涌现出几种核心的分割模型系列,每个模型都针对特定的细节层次和实际应用场景而设计。
语义分割模型
该类别中最常用的模型基于U-Net 架构及其众多变体。U-Net 引入了带有跳跃连接的编码器-解码器结构,使模型能够同时捕捉全局上下文和细粒度细节。现代版本在此基础上进行了改进,加入了注意力模块、Transformer 骨干网络和更优的特征融合技术。

实例分割模型
实例分割模型旨在将同一类别的不同对象区分开来。一个常见的例子是Mask R-CNN,它通过添加一个掩码预测分支来扩展目标检测流程,该分支为每个检测到的实例生成像素级掩码。

全景分割模型
全景模型将语义分割和实例分割整合到一个网络中。它们通常在大规模数据集(例如COCO-Panoptic和Cityscapes)上进行训练,这些数据集同时提供“事物”和“物品”的标注。最新的架构融合了检测和分割模块,以生成一致的、场景范围内的像素级标注。
交互式和基于提示的细分
诸如 Segment Anything Model ( SAM ) 和 PaliGemma 等视觉语言模型等新型方法,使得图像分割更加灵活。这些模型无需针对每个新数据集重新训练,即可通过点击、草图或文本提示等方式接收人类的指导。这使得用户能够即时将分割结果应用于新的类别或任务,从而弥合了视觉理解和自然语言交互之间的鸿沟。

如何选择细分模型
在图像分割方面,大多数模型都需要在准确性和速度之间做出权衡。但RF-DETR Seg可以兼顾两者。作为 Roboflow检测 Transformer的升级版,RF-DETR Seg 将目标检测和像素级分割整合到一个高效的模型中。
与 U-Net 或 Mask R-CNN 等老模型将检测和掩码预测分开进行不同,RF-DETR Seg 可以同时完成这两项任务,从而产生更清晰、更快速、更一致的结果。因此,您可以在 Roboflow 中训练、测试和部署 RF-DETR Seg,并立即获得一流的精度和低延迟。

....
七、图像特征提取(颜色,纹理,形状)
1.颜色特征提取
计算机视觉的特征提取算法研究至关重要。在一些算法中,一个高复杂度特征的提取可能能够解决问题(进行目标检测等目的),但这将以处理更多数据,需要更高的处理效果为代价。而颜色特征无需进行大量计算。只需将数字图像中的像素值进行相应转换,表现为数值即可。因此颜色特征以其低复杂度成为了一个较好的特征。
在图像处理中,我们可以将一个具体的像素点所呈现的颜色分多种方法分析,并提取出其颜色特征分量。比如通过手工标记区域提取一个特定区域(region)的颜色特征,用该区域在一个颜色空间三个分量各自的平均值表示,或者可以建立三个颜色直方图等方法。下面我们介绍一下颜色直方图和颜色矩的概念。
(1)颜色直方图:
颜色直方图用以反映图像颜色的组成分布,即各种颜色出现的概率。Swain和Ballard最先提出了应用颜色直方图进行图像特征提取的方法[40],首先利用颜色空间三个分量的剥离得到颜色直方图,之后通过观察实验数据发现将图像进行旋转变换、缩放变换、模糊变换后图像的颜色直方图改变不大,即图像直方图对图像的物理变换是不敏感的。因此常提取颜色特征并用颜色直方图应用于衡量和比较两幅图像的全局差。另外,如果图像可以分为多个区域,并且前景与背景颜色分布具有明显差异,则颜色直方图呈现双峰形。
颜色直方图也有其缺点:由于颜色直方图是全局颜色统计的结果,因此丢失了像素点间的位置特征。可能有几幅图像具有相同或相近的颜色直方图,但其图像像素位置分布完全不同。因此,图像与颜色直方图得多对一关系使得颜色直方图在识别前景物体上不能获得很好的效果。
考虑到颜色直方图的以上问题,主色调直方图便产生了。所谓主色调直方图基于假设少数几个像素的值能够表示图像中的绝大部分像素,即出现频率最高的几个像素被选为主色,仅用主色构成的主色调直方图描述一幅图像。这样的描述子并不会降低通过颜色特征进行匹配的效果,因为从某种角度将,频度出现很小的像素点可以被视为噪声。
(2)颜色矩:
颜色矩是一种有效的颜色特征,由Stricker和Orengo提出[41],该方法利用线性代数中矩的概念,将图像中的颜色分布用其矩表示。利用颜色一阶矩(平均值Average)、颜色二阶矩(方差Variance)和颜色三阶矩(偏斜度Skewness)来描述颜色分布。与颜色直方图不同,利用颜色矩进行图像描述无需量化图像特征。由于每个像素具有颜色空间的三个颜色通道,因此图像的颜色矩有9个分量来描述。由于颜色矩的维度较少,因此常将颜色矩与其他图像特征综合使用。
(3)颜色集:
以上两种方法通常用于两幅图像间全局或region之间的颜色比较、匹配等,而颜色集的方法致力于实现基于颜色实现对大规模图像的检索。颜色集的方法由Smith和Chang提出[42],该方法将颜色转化到HSV颜色空间后,将图像根据其颜色信息进行图像分割成若干region,并将颜色分为多个bin,每个region进行颜色空间量化建立颜色索引,进而建立二进制图像颜色索引表。为加快查找速度,还可以构造二分查找树进行特征检索。
2.纹理特征提取
一幅图像的纹理是在图像计算中经过量化的图像特征。图像纹理描述图像或其中小块区域的空间颜色分布和光强分布。纹理特征的提取分为基于结构的方法和基于统计数据的方法。一个基于结构的纹理特征提取方法是将所要检测的纹理进行建模,在图像中搜索重复的模式。该方法对人工合成的纹理识别效果较好。但对于交通图像中的纹理识别,基于统计数据的方法效果更好。
(1)LBP特征
LBP方法(Local binary patterns)是一个计算机视觉中用于图像特征分类的一个方法。LBP方法在1994年首先由T. Ojala, M.Pietikäinen, 和 D. Harwood 提出[43][44],用于纹理特征提取。后来LBP方法与HOG特征分类器联合使用,改善了一些数据集[45]上的检测效果。
对LBP特征向量进行提取的步骤如下:
首先将检测窗口划分为16×16的小区域(cell),对于每个cell中的一个像素,将其环形邻域内的8个点(也可以是环形邻域多个点,如图 3‑4. 应用LBP算法的三个邻域示例所示)进行顺时针或逆时针的比较,如果中心像素值比该邻点大,则将邻点赋值为1,否则赋值为0,这样每个点都会获得一个8位二进制数(通常转换为十进制数)。然后计算每个cell的直方图,即每个数字(假定是十进制数)出现的频率(也就是一个关于每一个像素点是否比邻域内点大的一个二进制序列进行统计),然后对该直方图进行归一化处理。最后将得到的每个cell的统计直方图进行连接,就得到了整幅图的LBP纹理特征,然后便可利用SVM或者其他机器学习算法进行分类了。
(2)灰度共生矩阵
灰度共生矩阵是另一种纹理特征提取方法,首先对于一幅图像定义一个方向(orientation)和一个以pixel为单位的步长(step),灰度共生矩阵T(N×N),则定义M(i,j)为灰度级为i和j的像素同时出现在一个点和沿所定义的方向跨度步长的点上的频率。其中N是灰度级划分数目。由于共生矩阵有方向和步长的组合定义,而决定频率的一个因素是对矩阵有贡献的像素数目,而这个数目要比总共数目少,且随着步长的增加而减少。因此所得到的共生矩阵是一个稀疏矩阵,所以灰度级划分N常常减少到8级。如在水平方向上计算左右方向上像素的共生矩阵,则为对称共生矩阵。类似的,如果仅考虑当前像素单方向(左或右)上的像素,则称为非对称共生矩阵。
[43]T. Ojala, M. Pietikäinen, and D. Harwood (1994), "Performance evaluation of texture measures with classification based on Kullback discrimination of distributions", Proceedings of the 12th IAPR International Conference on Pattern Recognition (ICPR 1994), vol. 1, pp. 582 - 585.
[44]T. Ojala, M. Pietikäinen, and D. Harwood (1996), "A Comparative Study of Texture Measures with Classification Based on Feature Distributions", Pattern Recognition, vol. 29, pp. 51-59.
[45]Xiaoyu Wang, Tony X. Han, Shuicheng Yan,"An HOG-LBP Human Detector with Partial Occlusion Handling", ICCV 2009
3.边缘特征提取
边缘检测是图形图像处理、计算机视觉和机器视觉中的一个基本工具,通常用于特征提取和特征检测,旨在检测一张数字图像中有明显变化的边缘或者不连续的区域,在一维空间中,类似的操作被称作步长检测(step detection)。边缘是一幅图像中不同屈原之间的边界线,通常一个边缘图像是一个二值图像。边缘检测的目的是捕捉亮度急剧变化的区域,而这些区域通常是我们关注的。在一幅图像中两度不连续的区域通常是以下几项之一:
# 图像深度不连续处
# 图像(梯度)朝向不连续处
# 图像光照(强度)不连续处
# 纹理变化处
理想情况下,对所给图像应用边缘检测器可以得到一系列连续的曲线,用于表示对象的边界。因此应用边缘检测算法所得到的结果将会大大减少图像数据量,从而过滤掉很多我们不需要的信息,留下图像的重要结构,所要处理的工作即被大大简化。然而,从普通图片上提取的边缘往往被图像的分割所破坏,也就是说,检测到的曲线通常不是连续的,有一些边缘曲线段开,就会丢失边缘线段,而且会出现一些我们不感兴趣的边缘。这就需要边缘检测算法的准确性。下面介绍两个本文实现的边缘检测算法:canny算子和sobel算子进行边缘检测。
(1)Canny算子边缘检测
Canny边缘检测算法基于一个多阶边缘算子,是由John F. Canny于1986年首先提出的[46],他不但给出了边缘检测的方法,也提出了边缘检测的计算理论。
Canny边缘检测器使用一个基于高斯模型派生的检测模型,因为未处理图像可能含有噪声,所以开始在原始图像上应用一个高斯滤波器,结果是一个轻度平滑的图像,以至于不至于被单个噪声像素干扰全局重要参数。
以一个5×5的高斯滤波模板为例(见公式3-7),对图像A应用高斯滤波可得B。下面对图像的光强梯度统计都基于图B。

一幅图像中的边缘可能在方向上各有所异,所以Canny算法用四个滤波器分别检测图像中的水平、垂直和对角线边缘。边缘检测器(如 Roberts, Prewitt, Sobel)值返回一个水平方向分量Gx和竖直方向分量Gy,由此边缘梯度和方向即可确定:

所有边缘的角度都在上述选定的四个方向(0°,45°,90°,135°)周围。下一步通过滞后性门限跟踪边缘线。
与小的光强梯度相比,数值较大的光强梯度更容易作为边缘线。在大多数图像中定义一个门限值来确定光强梯度取值多少适合作为边缘线通常是不可行的,因此Canny算法使用滞后作用确定门限值。该方法使用两个门限分别定义高低边界。假设所有的边缘应该不受噪声影响而且是连续的曲线。因此我们设置一个高门限用于判定确定是边缘的曲线,再由此出发,利用方向信息跟踪那些可追踪的图像边缘。当追踪该边缘时,应用低门限可以让我们追踪那些含有边缘的区域直到找到下一个曲线的起点。
如图 3‑5所示,(a)为原图的灰度图,(b)为高斯滤波平滑图,(c)和(d)分别是手动设置的高低门限值如图所示的canny边缘检测结果。根据多组图像数据测试发现,当canny高低门限值分别设置为50,150时能够保证大部分有效信息的保留且不会有过多冗余信息。因此后文中采用门限值[Thres1,Thres2]= 50,120 作为canny边缘检测参数。Opencv中以下代码实现:
cvCanny( dst,src, 50, 120, 3 );

(2)Sobel算子边缘检测
和Canny算子类似,Sobel算子[47]也是利用梯度信息对图像进行边缘检测的。对图像进行边缘检测时,计算每个像素的梯度并给出不同方向从明到暗的最大变化及其变化率。这个结果显示出图片在该点亮度变化为“急剧”还是“平滑”,由此可以判断该区域成为边缘的概率。在实际操作中,这个成为边缘的可能性(称为magnitude)计算比计算方向更为可靠,也更为便捷。在图像中的每个像素点,梯度向量只想亮度增长最大的方向,该梯度向量的长度对应于该方向的光强变化率。这就说明在同一像素图像上一个区域的某点的sobel算子是一个零向量,而且在边缘线上的点上有一组向量值为亮度梯度。
数学上在原图像上应用3×3的掩膜计算水平和垂直两个方向的变化梯度近似值。如果我们定义A为源图像,和分别作为一幅图像的水平近似梯度和垂直近似梯度,计算方式如下:

式3-9中,*表示二维卷积运算。这里建立的坐标系在x坐标方向向右,y坐标方向向下,在图像中的每个点,用式3-8描述总梯度大小及方向。用Sobel算子进行边缘检测结果见图 3‑6所示。

....
八、机器视觉照明类型与应用场景详解
在机器视觉系统中,光照是最重要的因素之一。即使机器视觉系统配备了高分辨率摄像头和最新的AI模型,如果光照条件差,系统也无法正常工作。

光线与表面、边缘、纹理和颜色的相互作用决定了相机捕捉到的内容以及人工智能模型能够学习到的内容。如果光照不稳定(过暗、过亮、反射过强或阴影过多),视觉系统可能无法正常工作。
机器视觉照明的关键在于,在关键区域最大化对比度,在无关区域最小化对比度。其目标是生成清晰、一致的图像,以便人工智能能够可靠地进行分析。
本指南将详细介绍设计高性能视觉系统所需的核心照明技术、滤光片类型和实用注意事项,这些系统可用于自动化、质量检测、机器人或人工智能驱动的制造工作流程。如需设置机器视觉照明系统方面的指导,请咨询人工智能专家。
计算机视觉中的照明类型和照明技术
机器视觉系统采用不同的照明设置。其目标是在最大程度提高目标特征对比度的同时,最大程度地减少不必要的干扰。以下是几种关键几何形状,它们会产生不同的光与物体表面相互作用。
背光
背光照明是机器视觉中最有效、应用最广泛的照明技术之一。在这种设置中,光源位于物体后方,使相机直接对准明亮的背景。这会产生极高的对比度,形成清晰锐利的暗部轮廓,从而能够轻松地检测轮廓并高精度地测量形状。

背光技术可用于检查零件是否存在、验证孔洞或间隙、以亚像素精度检测边缘以及执行精确测量任务。它也是确认拾取放置或机器人系统中零件方向的理想选择。
背光检测对不透明和半透明物体均适用。不透明物体在背光下呈现清晰的轮廓,便于进行尺寸和形状检查;而半透明材料则能显示缺陷或厚度差异。其可靠性和即时对比度使其成为高精度工业和制药检测的首选。
明场照明(定向/局部)
明场照明是机器视觉中最常用的照明方式。它的工作原理类似于普通的灯或手电筒,光线从与相机相同的方向照射物体。这种照明方式使朝向光源的表面显得明亮,而使倾斜或不平整的区域显得较暗。由于这种自然的对比度,明场照明非常有效地展现了表面细节,例如划痕、边缘、标记和纹理变化。明场照明可以分为以下几种类型:
轴向环形照明
环形灯是目前最流行的明场照明方案,因为它的光源直接围绕相机镜头。这种设计安装简便,能够为相机正前方提供明亮均匀的照明。它尤其适用于小型平面部件,并且通常会略微倾斜以避免出现光斑。环形灯能够提供清晰均匀的照明,无需复杂的设置即可展现表面细节。

离轴明场
离轴明场照明使用一个独立的LED灯,该灯位于距离摄像机视角约15°的位置。虽然摄像机仍保持与物体垂直,但倾斜的光线会产生细微的阴影,从而显现出高度差、凸起边缘和细微的表面纹理。这使得它非常适合检测凸起、台阶、凹槽或其他在正射光下可能被遮挡的地形特征。

条形照明
条形照片使用细长的灯管照亮物体的特定区域或边缘。必要时,可以将多盏条形灯组合起来,从不同方向提供照明。根据安装位置的不同,条形灯可以减少光亮部分的反射,或增强哑光表面的对比度。它们尤其适用于大型物体或需要远距离照明的场合。

暗场照明
暗场照明以极低的角度(通常为 45° 或更大)将光线照射到物体上,使大部分光线反射出相机。只有凸起的边缘、划痕或纹理区域才能捕捉到光线并呈现明亮状态,而平坦的表面则保持黑暗。由于这种强烈的对比度,暗场照明非常适用于检测反光部件、揭示细微的表面缺陷、突出雕刻或压印标记、检测轮廓和高度变化,以及辅助在纹理材料上进行光学字符识别 (OCR)。当光源非常靠近物体时,这种技术效果最佳,能够清晰地展现细微的地形特征。

漫射光(全亮场)
漫射光是一种光线在到达物体之前会向各个方向散射的照明方式,它能营造出柔和均匀的光线,避免产生生硬的阴影或强烈的反射。光线并非来自单一方向,而是从各个方向环绕物体,使整个表面均匀明亮。这有助于相机清晰地拍摄光滑、弯曲或不平整的表面,避免出现眩光、光斑或暗区。以下是主要的漫射光类型:
穹顶照明(漫射穹顶)
穹顶照明采用中空的穹顶状结构,内衬LED灯。摄像机通过顶部的开口进行拍摄,穹顶将光线均匀地散射到物体上。这样可以产生非常均匀的照明,消除光斑,并使曲面或反光表面呈现光滑的哑光效果。它常用于检测汽车零部件、塑料零件以及其他反射导致标准照明不可靠的物体。

漫射轴向照明 (DOAL)
漫射轴上照明 (DOAL) 使用分光镜将光线沿相机光轴方向垂直向下照射。通过结合直接照明和漫射照明,这种方法可以生成明亮、无眩光的平面反射表面图像。DOAL 通常用于晶圆、CD/DVD 和半导体元件等对表面均匀性和细节可见性要求极高的应用。

同轴照明
同轴照明是一种特殊的明场照明方式,光线沿与摄像机视角相同的路径垂直向下照射到物体上。一个以45°角放置的分光镜将光线重新导向物体表面,摄像机也通过该分光镜进行拍摄。这种方式能够产生均匀无阴影的照明,使平坦的反射表面呈现均匀明亮的效果,避免眩光和光斑。由于光线垂直照射物体,因此更容易观察到光滑材料上的细微细节和表面纹理变化。

同轴照明非常适合检测抛光金属、玻璃、镜子和其他反射表面。它常用于读取光亮部件上的文字或代码、检测半导体晶圆以及检测细微的纹理差异,尤其适用于需要无阴影照明的场合。
结构化激光线照明
结构化激光线照明技术将一条细而高强度的激光线投射到物体表面,以测量其形状、高度或轮廓。当激光线照射到物体上时,会根据表面几何形状发生弯曲或位移。倾斜放置的相机捕捉到这种形变,软件则将这些变化转换为精确的三维信息。
这项技术在检测高度变化、测量尺寸、检查边缘以及创建零件的三维轮廓方面极其有效。由于激光线具有很强的对比度和非常窄的照明模式,即使在标准照明失效的黑暗、复杂或纹理表面上,它也能可靠地工作。结构光照明广泛应用于三维检测、缺陷检测、机器人引导以及需要精确测量高度或形状的应用中。

机器视觉中的光学滤波器类型
光学滤光片是放置在相机或光源前的小型元件,用于控制进入视觉系统的光波长。它们非常重要,因为它们可以滤除不需要的光线、减少眩光并提高对比度。这有助于相机仅聚焦于能够突出目标特征的波长。滤光片通常用于机器视觉系统中,尤其是在光照条件难以控制或需要对特定颜色、反射或材料进行选择性波长过滤的情况下。

上面的示例图像展示了不同的滤镜如何改变相机捕捉到的画面。红色滤镜会突出显示反射红光的特征,而蓝色滤镜则会突出显示反射蓝光的特征,从而使某些细节清晰可见,而另一些细节则消失不见。
通过选择合适的光学滤光片,您可以控制哪些波长的光到达相机,并增强对您的检测最重要的功能。
带通滤波器
带通滤波器只允许特定波长范围(一种特定颜色的光)的光到达相机,并阻挡所有其他光线。这有助于消除环境光的影响,并产生强烈而一致的对比度。带通滤波器通常与相同颜色的 LED 灯配合使用,即使在光线条件不佳的情况下,也能使拍摄对象清晰突出。

长通滤波器
长通滤波器允许较长波长的光(例如红色或红外线)通过,同时阻挡较短波长的光(例如蓝色或绿色)。这些滤波器可用于检测对红外光响应更佳的材料、减少反射表面的眩光,或深入观察半透明材料。当普通照明无法显示足够细节时,长通滤波器可以增强可见度。
短通滤波器
短波通滤波器允许波长较短的光(蓝光或紫外光)通过,而阻挡波长较长的光。这使其成为紫外线检测、荧光成像以及需要清晰显示细微纹理或微小缺陷的检测应用的理想选择。通过阻挡红外光,短波通滤波器可以防止图像过曝,即使在强光下也能保持较高的对比度。
偏振滤光片
偏光滤镜可以消除金属、塑料或玻璃等光滑表面的眩光和反射。它的工作原理是只允许沿一个方向振动的光波通过。这样就能显现出通常会被强光反射遮挡的表面细节,例如划痕、印刷文字或图案。将相机上的偏光镜与光源上的偏光镜配合使用(交叉偏光)可以最大程度地减少眩光。

中性密度(ND)滤镜
中性密度滤镜(ND滤镜)可以减少到达相机的光线总量,而不会改变色彩。它的作用就像是给眼睛戴上太阳镜。当场景过亮、光源非常强或相机需要更长的曝光时间时,就需要使用ND滤镜。它们有助于防止过度曝光,并在高强度照明环境下保持图像清晰度。

近红外截止/红外截止滤光片
红外截止滤光片可以阻挡红外波长,只允许可见光通过。大多数彩色相机都配备了红外截止滤光片,因为红外光会影响色彩准确度并降低对比度。

紫外线过滤器
紫外线滤光片可以阻挡紫外线,同时允许可见光通过。紫外线会使某些材料产生雾状或不必要的荧光,因此阻挡紫外线可以获得更清晰、更锐利的图像。当自然阳光或紫外线检测环境导致噪声或对比度问题时,通常会使用紫外线滤光片。

彩色滤光片(红色、绿色、蓝色滤光片)
基本滤色片只允许一种原色到达传感器。当某些特征在特定颜色下对比度最佳时,就会使用滤色片。例如,红光可以突出金属表面的缺陷,而蓝光则可以凸显塑料的纹理。使用滤色片可以简化图像并提高算法性能。

最佳照明的考虑因素
为机器视觉系统设计照明不仅仅是选择灯具,还需要了解环境、物体以及不同类型的光与材料的相互作用。良好的照明必须能够产生强烈的对比度,保持光照的一致性,并在检测装置的物理限制范围内可靠地工作。
立即检查环境
相机和物体周围的空间直接影响可使用的照明方式。机器、机器人、传送带或固定装置可能会限制灯具的放置距离、尺寸或照射角度。工作距离也会影响亮度,距离越远,所需的灯具功率越大或尺寸越大。高速生产线通常需要强光或频闪照明来凝固运动画面。
环境光是另一个主要影响因素,工厂照明会降低对比度或产生眩光。为了解决这个问题,工程师会使用频闪灯、防护罩或光学滤光片来阻挡不需要的波长。当照明条件无法完全控制时,防护罩尤其有用。
样品/光相互作用
每种材料对光的反应都不同。光滑的反光表面在定向照明下可能会产生眩光,而哑光表面则能均匀散射光线,更容易照明。曲面物体通常需要漫射光以避免出现亮点,而纹理或地形表面则适合使用低角度暗场照明,这种照明方式可以突出边缘和高度变化。透明或半透明材料可能需要背光或特定波长的光才能展现其内部结构。根据材料的不同,光线可以被反射、吸收或透射,选择合适的波长可以显著提高对比度。
颜色和波长方面的考虑
不同波长的光能揭示物体的不同特征。将照明颜色与要突出显示的特征相匹配,可以显著提高检测效果。蓝光适合观察精细细节,红光可以增强轮廓,红外光可以穿透某些材料,紫外光则可以显示荧光或肉眼不可见的标记。对于颜色检测,稳定的白光和色温至关重要。使用带有彩色LED的单色相机通常比仅依靠白光和彩色传感器能产生更好的对比度。
选择合适的照明
系统化的方法有助于确保可靠的照明设置:
- 确定需要检测的特征,例如边缘、表面缺陷、存在/缺失、印刷、颜色或 3D 形状。
- 评估您的工作环境,包括空间限制、工作距离和环境光线。防护罩和过滤器有助于稳定工作环境。
- 分析样品,考虑其反射率、形状和材质。根据这些特性选择合适的照明几何形状和波长。
- 使用光学滤光片阻挡不必要的光线,减少眩光,提高对比度。
- 测试多种照明几何形状,因为最佳解决方案通常是通过并排比较几个选项来发现的。
....
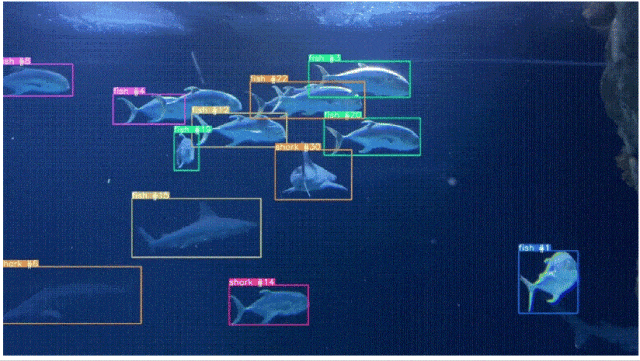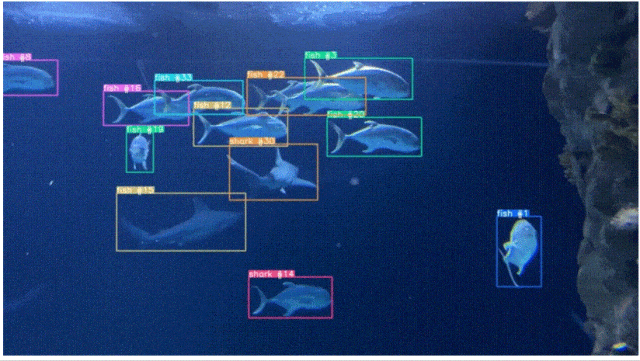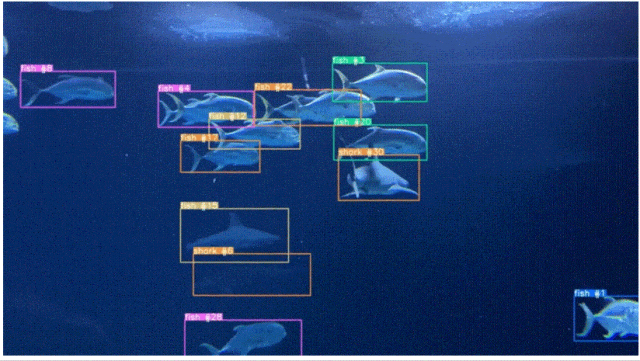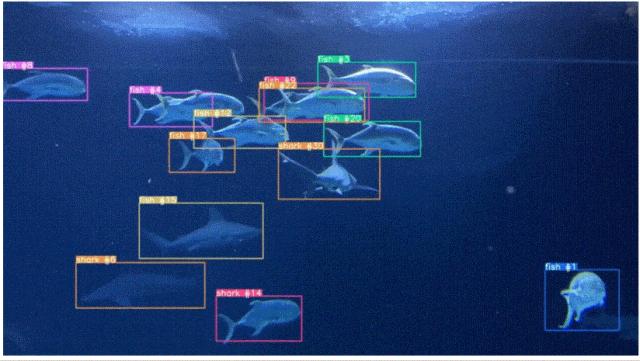
九、物体计数的四大案例
计数物体是一项我们认为理所当然的人类任务。这看起来很简单,但要实现它需要进行大量处理,并且在能够计数目标方面需要获得非常有用的信息。
想象一下,一个农民走过他的田地,在一棵树下停下来,问自己:“这棵树上有多少苹果?这个问题看似普通,但却蕴含着巨大的价值。
了解计数有助于农民估计产量、管理收获和计划分配。然而,人类计数是不可能大规模的。
这就是计算机视觉自动物体计数的强大功能:教机器快速准确地查看和计数。

计算图像中的苹果数量
使用计算机视觉进行目标计数概述
在本文中,我们将探索使用计算机视觉进行目标计数,从基本概念到实际应用。您将学习:
- 什么是目标计数以及为什么它很重要。
- 图像计数与视频计数之间的区别。
- 机器面临的挑战(例如遮挡、重叠和重复)。
- 制造、医疗保健、农业和仓储等领域的实际行业应用。
- 如何使用 Roboflow 等工具简化了从数据集创建到模型部署的过程。
- 为什么基于变压器的 RF-DETR 模型在具有挑战性的条件下进行计数特别强大。
- 最后,如何构建目标计数应用程序:
- 基于图像的物体计数
- 基于视频的物体计数
- 视频中基于区域的计数
- 实时摄像机馈送中的目标计数
什么是目标计数?
计算机视觉中的目标计数是系统自动识别和计算图像或视频帧中特定目标实例的任务。核心目标是检测和枚举图像或视频中场景中出现的感兴趣目标(例如,人、车辆、产品)的数量。
这种方法适用于不同的设置:
- 在图像中,系统会一次计算所有可见实例。
- 在视频片段中,它会跟踪和计数物体在场景中移动,例如穿过门口的人或通过检查站的汽车。
我们将在本文后面探讨图像和视频中的计数目标。
目标计数的核心概念
计算机视觉中的物体计数围绕着一个基本问题:
“图像或视频中存在多少特定类型的目标?”
对于人类来说,这项任务是第二天性。在计算机视觉中,目标是训练机器以自动化和可靠的方式复制人类的这种能力。
目标计数的本质在于三个主要步骤:
- 了解要计算的内容:系统首先需要定义什么算作感兴趣目标。这可以是任何东西,从人和汽车到动物、工具或制造零件。
- 找到每个实例:定义目标类型后,系统必须识别场景中该目标的每个单独出现。每个检测到的目标都被视为一个单独的实例。
- 保持准确计数:对于找到的每个目标实例,系统都会递增一个计数器。最终输出是一个数字,表示存在多少个此类目标。
如何计算图像中的目标
对图像中的目标进行计数的过程通常涉及以下关键步骤:

- 图像采集:以静止图像的形式捕获输入数据。这用作进一步处理的原始输入。
- 目标检测或定位:应用计算机视觉模型来识别和定位图像中感兴趣的目标。此步骤在每个目标周围输出边界框或分割蒙版。
- 目标计数:通过对各个检测相加来计算检测到的目标的总数。每个有效的边界框或分段实例都被视为一个计数。
如何计算视频中的目标
对视频中的目标进行计数不仅涉及检测单个帧中的目标,还涉及随着时间的推移跟踪它们以避免重复。该过程通常包括以下阶段:

- 检测:将预训练的目标检测模型应用于每个视频帧。它通过在感兴趣的目标周围绘制边界框来识别和定位感兴趣的目标,提供当前帧中每个目标的位置和类标签。
- 跟踪:检测到目标后,跟踪算法(例如 SORT、DeepSORT 或 ByteTrack)会为每个目标分配一个唯一的 ID,并在后续帧中跟踪它。这可确保在整个视频中始终识别相同的目标,即使在它移动时也是如此。
- 计数:系统维护目标 ID 的注册表,并且仅对每个目标进行一次计数。在以下情况下可以触发计数:
- 目标穿过预定义的线或区域(线交叉逻辑)。
- 场景中将显示一个新的目标 ID。
- 目标完成特定路径或退出帧。
这种方法通过防止重复计数同一目标并随着时间的推移保持一致性来确保准确、实时的计数。
物体计数的挑战
尽管物体计数概念看似简单,但一些挑战使物体计数成为机器的一项不平凡的任务。这些都是:
- 区分相似目标:相同类型的目标可能看起来非常接近、重叠或看起来几乎相同。系统必须准确识别并分离它们。
- 避免重复计数:特别是在视频流中,系统必须确保移动目标不会被计数不止一次。
- 处理遮挡和杂乱:目标的一部分可能隐藏在其他目标后面或部分超出帧,需要系统进行智能猜测。
- 适应可变性:照明变化、摄像机角度、物体大小和背景复杂性都会影响计数的准确性。
目标计数是识别和统计图像或视频中单个目标数量的自动化过程。核心目标是检测每个不同的目标实例并生成准确的计数,类似于人的方式,但由具有一致性和规模的机器完成。简单来说,这就像训练计算机看着一个场景并说:
“有 7 个人”或“12 辆车经过”。
这项基础任务是许多实际应用的支柱,在这些应用中,理解数量至关重要。
如何使用计算机视觉对物体进行计数(4 个示例)
用 RF-DETR,并为以下任务构建示例:
- 图像中的目标计数
- 视频中的物体计数
- 区域内物体计数(基于视频)
- 实时摄像机源中的目标计数
示例 #1:图像中的目标计数
在此示例中,我们将使用 RF-DETR 基本模型接受图像并检测目标。

import cv2
import numpy as np
import supervision as sv
from collections import Counter
import matplotlib.pyplot as plt
from PIL import Image
from inference_sdk import InferenceHTTPClient
# Load original image
image_path = "dogs.png"
image_bgr = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="YOUR_API_KEY"
)
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="object-counting-image",
images={
"image": image_path
},
use_cache=False
)
# Parse predictions
predictions = result[0]["output"]["predictions"]
xyxy = []
confidences = []
class_names = []
for pred in predictions:
conf = pred["confidence"]
cls = pred["class"]
x_c, y_c = pred["x"], pred["y"]
w, h = pred["width"], pred["height"]
x1 = x_c - w / 2
y1 = y_c - h / 2
x2 = x_c + w / 2
y2 = y_c + h / 2
xyxy.append([x1, y1, x2, y2])
confidences.append(conf)
class_names.append(cls)
xyxy = np.array(xyxy, dtype=float)
confidences = np.array(confidences, dtype=float)
class_names = np.array(class_names)
# Assign per-class object numbers
per_class_counter = Counter()
labels = []
for cls, conf in zip(class_names, confidences):
per_class_counter[cls] += 1
count = per_class_counter[cls]
labels.append(f"{cls} #{count} ({conf:.2f})")
# Supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
cnotallow=confidences,
class_id=np.zeros(len(xyxy), dtype=int)
)
# Visualize
annotated = image_rgb.copy()
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
annotated = box_annotator.annotate(scene=annotated, detectinotallow=detections)
annotated = label_annotator.annotate(scene=annotated, detectinotallow=detections, labels=labels)
# Display
plt.figure(figsize=(12, 10))
plt.imshow(annotated)
plt.axis("off")
plt.title("Object Counts: " + ", ".join(f"{k}: {v}" for k, v in per_class_counter.items()))
plt.show()在以下输入图像上运行脚本:

将生成类似于以下内容的输出:

示例 #2:视频中的目标计数

此工作流结合了对象检测模型 (rf-detr-base) 和 ByteTrack 块。检测模型识别每个视频帧中的对象(如人、狗等),而 ByteTrack 为每个对象分配一个唯一的 ID 并跨帧跟踪它。
此设置对于对象计数至关重要,因为它可以确保对象无论在视频中出现多长时间,都只计数一次。该工作流程输出原始预测和跟踪信息,使其可用于累积计数应用程序。
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
from collections import defaultdict
# === Output video config ===
output_path = "output_object_counting.mp4"
video_writer = None
output_fps = 30
output_size = None
# Object ID and count state
id_registry = {} # (class_name, tracker_id) -> object_number
next_object_number = defaultdict(int) # class_name -> next id (starting from 1)
total_class_counts = defaultdict(int) # class_name -> total seen ever
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
# Data extraction
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
labels = []
per_frame_counter = defaultdict(int)
# Assign IDs and prepare labels
for i, (cls_name, trk_id, conf) in enumerate(zip(class_names, tracker_ids, confidences)):
key = (cls_name, int(trk_id))
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1
obj_number = id_registry[key]
per_frame_counter[cls_name] += 1
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Build supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
cnotallow=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Annotate with supervision
annotated = box_annotator.annotate(scene=frame.copy(), detectinotallow=detections)
annotated = label_annotator.annotate(scene=annotated, detectinotallow=detections, labels=labels)
# Draw global count summary (cumulative)
y0 = 30
for i, (cls, cnt) in enumerate(total_class_counts.items()):
text = f"{cls} Total: {cnt}"
cv2.putText(
annotated, text,
(10, y0 + i * 30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 255), 2, cv2.LINE_AA
)
# Init video writer
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, output_size)
# Show + save frame
cv2_imshow(annotated)
video_writer.write(annotated)
# Roboflow inference pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_predictinotallow=my_sink
)
pipeline.start()
pipeline.join()
# Final cleanup
if video_writer:
video_writer.release()
cv2.destroyAllWindows()

示例 #3:带视频的区域中的物体计数
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
from collections import defaultdict
# Output config
output_path = "output_zone_count_filtered.mp4"
video_writer = None
output_fps = 30
output_size = None
# Tracking state
id_registry = {}
next_object_number = defaultdict(int)
total_class_counts = defaultdict(int)
# Target class
TARGET_CLASS = "person"
# Zone polygon
polygon = np.array([[604, 876], [1313, 864], [1235, 535], [670, 544]])
zone = sv.PolygonZone(polygnotallow=polygon)
# Manual polygon drawer (removes supervision’s default center ID)
def draw_polygon(scene, polygon, color=(255, 255, 255), thickness=2):
points = polygon.reshape((-1, 1, 2)).astype(int)
return cv2.polylines(scene, [points], isClosed=True, color=color, thickness=thickness)
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
# Supervision detections
detections = sv.Detections(
xyxy=xyxy,
cnotallow=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Filter: by zone
in_zone_mask = zone.trigger(detections)
detections = detections[in_zone_mask]
filtered_class_names = class_names[in_zone_mask]
filtered_tracker_ids = tracker_ids[in_zone_mask]
filtered_confidences = confidences[in_zone_mask]
# Filter: by target class
final_mask = np.array([cls == TARGET_CLASS for cls in filtered_class_names])
detections = detections[final_mask]
filtered_class_names = filtered_class_names[final_mask]
filtered_tracker_ids = filtered_tracker_ids[final_mask]
filtered_confidences = filtered_confidences[final_mask]
# Tracking logic
current_ids_in_zone = set()
labels = []
for cls_name, trk_id, conf in zip(filtered_class_names, filtered_tracker_ids, filtered_confidences):
key = (cls_name, int(trk_id))
current_ids_in_zone.add(key)
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1 # Cumulative count
obj_number = id_registry[key]
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Annotate frame
annotated = box_annotator.annotate(scene=frame.copy(), detectinotallow=detections)
annotated = label_annotator.annotate(scene=annotated, detectinotallow=detections, labels=labels)
annotated = draw_polygon(annotated, polygon)
# Draw text on frame
cv2.putText(
annotated,
f"Total {TARGET_CLASS}(s) in Zone: {total_class_counts.get(TARGET_CLASS, 0)}",
(20, 120),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
cv2.putText(
annotated,
f"{TARGET_CLASS}(s) currently in Zone: {len(current_ids_in_zone)}",
(20,150),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
# Video output
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, (w, h))
cv2_imshow(annotated)
video_writer.write(annotated)
# Start pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_predictinotallow=my_sink
)
pipeline.start()
pipeline.join()
if video_writer:
video_writer.release()
cv2.destroyAllWindows()
示例 #4:实时摄像机中的对象计数
from inference import InferencePipeline
import cv2
def my_sink(result, video_frame):
# Start from the visualization image
frame = result["label_visualization"].numpy_image.copy()
# Read count safely
count = int(result.get("count", 0))
text = f"Count: {count}"
# Text styling
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.8
thickness = 2
margin = 12
# Compute background box for readability
(text_w, text_h), baseline = cv2.getTextSize(text, font, font_scale, thickness)
x, y = margin, margin + text_h
# Draw filled background rectangle (black) then white text
cv2.rectangle(
frame,
(x - 6, y - text_h - 6),
(x + text_w + 6, y + baseline + 6),
(0, 0, 0),
-1
)
cv2.putText(frame, text, (x, y), font, font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
# Show the frame
cv2.imshow("Object Counting", frame)
cv2.waitKey(1)
# initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-camera",
video_reference=0,
max_fps=30,
on_predictinotallow=my_sink
)
pipeline.start()
pipeline.join()
....
十、提高机器视觉检测精度的7种方法
机器视觉检测技术及应用,随着越来越多的制造商每天使用机器视觉系统对其生产设施进行检测,您在拥有合适的机器视觉检测解决方案的同时,还必须确保您的检测系统尽可能准确和高效。
在实际场景中,机器视觉检测设备在检测产品时的一些不稳定因素,会直接导致检测精度与效率受到很大的影响。
下面小矩就和大家一起分析如何根据分辨率,精度,公差的关系指导选型,以及视觉检测设备检测中不稳定的因素。
01 根据分辨率 精度 公差进行选型
▶分辨率(Resolution)
计算公式:分辨率 = 视野(Field of View)/像素(Pixel)
比如我要看的产品大小是30mm*10MM,使用200万像素(1600pixel*1200pixel)的相机。因为产品是长条形,为了把产品都放入到视野内,我们计算分辨率的时候要考虑长边对应,此时分辨率为:
分辨率 = 30mm/1600Pixel = 0.019mm/Pixel
▶精度(Accuracy)
计算公式:精度 = 分辨率 x 有效像素
精度的单位是mm。根据产品表面和照明状况的不同,我们可以通过放大图像观察辨别稳定像素的个数,从而得出精度。如果条件不允许实际测试观察,一般的规律是,如果使用正面打光,有效像素为1个,使用背光,有效像素为0.5个。
这个例子我们取1 Pixel,得到精度为0.019mm约等于0.02mm。
机器视觉系统的定位精度如何计算?
假如是30万像素的摄像机,监控的面积为640x480mm,其精度是不是就是1mm了?
30W相机分辨率640*480 正常这样算:用最长的边除去监控面积最长的边 即可,所以精度基本上是1mm,这个是理论值,如果你做测量或者表面划伤检测,肯定不准确,一个像素有可能无法凸显特征。
▶公差(Tolerance)
一般情况下,精度和公差的对应关系如下:

对一个项目来讲,我们是先从图纸上读到公差的要求。然后再根据上述关系,反推得出我们需要多少像素的相机。

测量时,首先要考虑的几大方面的有:相机、镜头、光源。
选择要考虑的因素有很大,这里依据一个经手的项目介绍一下精度方面需要考虑的问题。
项目要求:像素精度0.05mm、测量误差正负0.15mm。首先介绍一下相关的概念:
像素精度:一个像素在真实世界代表的距离,即拍摄视野/分辨率。例如我所使用的大华500万相机,分辨率2592*2048,在视野中长的一边100mm,即可拍到100mm的物体,那么在这一方向的像素精度为100/2592mm约为0.0386mm。
测量误差:使用算法测量的距离/长度与真实值的误差。
亚像素精度:亚像素精度是指相邻两像素之间细分情况,输入值通常为二分之一,三分之一或四分之一。即每个像素将被分为更小的单元从而对这些更小的单元实施插值算法。
例如,如果选择四分之一,就相当于每个像素在横向和纵向上都被当作四个像素来计算。实际测量或检测时需要考虑的还有很多,例如帧率、曝光、增益等。
02 影响机器视觉检测设备精度的因素
▶视觉检测设备不稳定因素:工业相机
工业相机的挑选关键考虑到其传感器类型、像素和帧数,在其中控制器分CCD与CMOS二种,CMOS光学镜头处理速度高,各元器件、电源电路中间间距很近,影响情况严重,显像噪音高。
CCD控制器照相机相对性于CMOS照相机具备敏感度高、噪音低和响应时间快的特性,在稳定性层面,CCD照相机的耐冲击与振动性也较强,一般来说,CCD控制器照相机在显像品质上和稳定性层面要好于CMOS照相机。
▶视觉检测设备不稳定因素:光源
光源具备变大图象的特点与缺点、消弱错乱及背景图的功效,立即影响键入数据信息的品质,因为沒有通用性的照明灯具,光源的设计方案一直是机器视觉技术的难题,一般须对于每一特殊的运用案例来挑选光源种类,也要依据实际自然环境对光源安的裝、光源的直射方法开展掂量,以超过最好实际效果。
不一样种类的光源稳定性存有差别,普遍的光源有环形光、条形光、面光源、背光源、同轴光、碗光等。因此,光源的选择差异,也是影响视觉检测设备的不稳定因素。
▶视觉检测设备不稳定因素:机器视觉软件
机器视觉软件稳定性对机器视觉技术的影响不容置疑,视觉识别系统终究会在电子计算机上利用计算机选用有目的性的优化算法开展图像滤波,边缘检测和边沿获取等一系列图象处理,不一样的图象处理和解析方式及其不一样的检验方式与计算方法,都是产生不一样的偏差,优化算法好坏决策精确测量精度的高低,因此,需要选择合适的机器视觉软件,这样才可以避免视觉检测设备精度变低。
矩视智能机器视觉低代码平台是一个面向机器视觉应用的云端协同开发平台,始终秉承0成本、0代码、0门槛、0硬件的产品理念。
平台以人工智能技术为核心,在机器视觉应用开发环节,为开发者提供图像采集、图像标注、算法开发、算法封装和应用集成的一站式完整工具链。覆盖字符识别、缺陷检测、目标定位、尺寸测量、3D测量、视频开发等上百项通用功能。
▪ 零成本:无需购买,平台免费开发,用户无限制使用
▪ 零门槛:无需任何图像知识,只需标注操作即可完成视觉算法开发
▪ 零代码:无需编写代码,只需“拖拉拽”式操作,开发可本地化部署的应用程序
▪ 零硬件:无需搭建本地开发环境,浏览器登陆即可在线使用

03 提视觉检测精度的7种方法
▶选择合适的光源
如果没有合适的光源,即使是最好的相机也无法捕捉到清晰的图像。对于某些应用,背光可能会产生最佳效果。在其他情况下,您可能需要明场照明或低角度线性阵列。您的系统集成商可以帮助您做出正确的选择。
▶校准光源
一旦您知道哪种类型的光源最好,可能仍需要进一步校准。调整照明系统的频率和波长,以减少来自生产环境或您正在使用的零件和材料上可能存在的涂层的噪音。
▶过滤灯光
机器视觉在保持一致的环境中效果最佳。但这可能很难保证一整天。环境光、重新布置的生产线和不断变化的产品都会影响照明。镜头过滤器可以帮助消除不需要的光。
▶触发功能
在某些情况下,生产环境中的电噪声会导致检测系统误触发。这可能会导致分析失败并导致产品不应该出现故障。触发功能可以帮助您避免这种情况。
▶添加AI技术
人工智能和嵌入式系统正变得越来越容易被各种制造商使用,人工智能可以通过基于强大的数据集做出更智能的决策来减少面积。
▶改善零件定位
一些合格的元件由于定位不良而未能通过检查。添加更精确的工具来固定零件进行检查可以提高机器视觉检查的准确性。
▶增加稳定性
生产环境中的设备经常会受到噪音和振动的影响,从而导致图像模糊,这可能导致不必要的故障和重复检查。
....
十一、相机校准的重要性
如果你曾经接触过计算机视觉,你可能听过有人说:“先校准一下相机。”我承认,刚开始使用OpenCV时,我多次跳过这一步。代码运行起来,检测也成功了(某种程度上),然后我就继续了。直到有一天,我的测量结果总是偏差几厘米,而我却找不到原因。正是在那时,我才深刻地认识到:相机校准不是可有可无的,而是基础性的。
我们看不到的问题
相机观察世界的方式与我们不同。光线穿过镜头时会发生弯曲,而这种弯曲会导致图像失真。直线会弯曲,距离也会变形。原本完美的网格边缘看起来略显臃肿。这被称为镜头畸变,每台相机都会或多或少地出现这种情况。

困扰计算机视觉任务的失真主要有两种类型:
径向畸变:这会使直线看起来弯曲,尤其是在画面边缘附近。广角镜头通常会出现桶形畸变(线条向外弯曲),而远摄镜头则会出现枕形畸变(线条向内弯曲)。
切向失真:当镜头与图像传感器不完全平行时,就会发生这种情况,导致图像的某些部分看起来歪斜或倾斜。
对于物体检测或简单分类等任务,这些失真可能不会影响你的系统。但当你需要精确测量、3D重建或机器人导航时,失真就会成为致命伤。
相机校准的实际作用
校准是对这些失真进行数学建模以便我们能够纠正它们的过程。它估计两组参数:
固有参数:这些参数特定于相机——焦距、光学中心和畸变系数。一旦计算出来,这些参数对于该相机而言就保持不变。
外部参数:这些参数描述了相机在3D空间中相对于场景的位置和方向。
利用这些参数,我们可以“去扭曲”图像——将扭曲的曲线重新变成直线,并确保像素测量值准确映射到现实世界的距离。
棋盘图案的选择原因

棋盘格图案已成为校准的黄金标准,这是有充分理由的:
易于检测:即使在不同的光照条件下,交替的黑白方块也清晰可见。
尖角:交叉点(角)在两个方向上具有梯度,使其成为精确亚像素定位的理想选择。
已知几何形状:由于正方形尺寸均匀且可测量,我们知道现实世界中每个角落的精确3D坐标。
通过从多个角度和距离拍摄该图案,我们收集了足够的数据来解决相机的内在和外在参数。
校准流程详解
OpenCV中的校准工作流程遵循以下步骤:
- 从不同角度和距离拍摄棋盘的多张图像(为了获得良好的效果,至少拍摄10-15张图像)
- 使用
cv2.findChessboardCorners()检测每幅图像中的棋盘格角点 - 使用
cv2.cornerSubPix()将角点位置细化至亚像素精度 - 通过将3D世界坐标和相应的2D图像坐标传递给
cv2.calibrateCamera()来校准相机 - 使用
cv2.undistort()和计算出的参数来消除未来图像的扭曲
相机矩阵和失真系数可以保存并重复用于该相机的所有未来图像,无需每次重新校准。

校准的关键应用场景
我以前以为校准只适用于机器人或3D重建。但事实证明,它在很多场景中都至关重要:
测量任务:测量图像的尺寸、距离或面积时,未校准的相机会给出错误数据
计算机视觉分析:在未失真数据上训练的模型在失真图像上表现不佳
增强现实:将虚拟物体准确地放置在现实世界场景中需要精确的相机参数
多摄像头系统:立体视觉和360度摄像头装置依赖校准进行深度估计和全景拼接
工业自动化:在质量控制或拾放机器人中,微小变形可能导致严重问题
跳过校准的实际代价
跳过校准看似省时,实则虚耗。系统最初可能“运行”,但之后会悄无声息地失效,测量值漂移,边缘情况会中断检测,调试也会变成一场噩梦。30分钟的校准过程可以避免数天的调试烦恼。
实用校准技巧
以下是我在实际项目中总结的经验:
- 使用高质量的打印棋盘格(或平面显示器显示)
- 以不同的距离、角度和位置捕捉图像
- 确保棋盘格填充每幅图像中框架的很大一部分
- 检查校准后的重投影误差(值接近零表示校准准确)
- 保存校准参数供重复使用
结论
相机校准并不光鲜亮丽,但却是区分“勉强可行”的系统和真正可靠运行的系统的关键步骤。如果您的计算机视觉应用涉及任何形式的测量、3D理解或精确定位,请不要跳过校准。花点时间好好校准,未来的您都会感谢这个决定。
....
十二、相机如何真实地呈现世界
你知道图像识别应该使用哪些镜头吗?

在深入探讨计算机视觉的深奥主题(例如图像预处理或神经网络分类)之前,我们需要打好坚实的基础。
因为首先我们必须明白:
光是如何转化为数据的?
换句话说——相机如何将光子转化为像素?
从光到像素
为了将物理光线转化为计算机可读取的数值数据,我们依靠图像传感器——我们相机的数字眼睛。
神奇之处就在这里:传感器将光子转换成电信号,然后将电信号转换成构成图像的像素值。
传感器类型
传感器有多种类型,每种类型都有不同的作用和应用场景:
面传感器(例如 CCD、CMOS 芯片)
用于捕捉物体图像(例如形状、矩形场景等)

线传感器
与面阵传感器类似,但像素排列成行——非常适合扫描仪等工业应用。

点传感器
仅记录单一强度值。而且它们不仅限于可见光——还有用于红外线 (IR)、紫外线 (UV)、X射线甚至无线电波(雷达传感器)的传感器。

CCD传感器
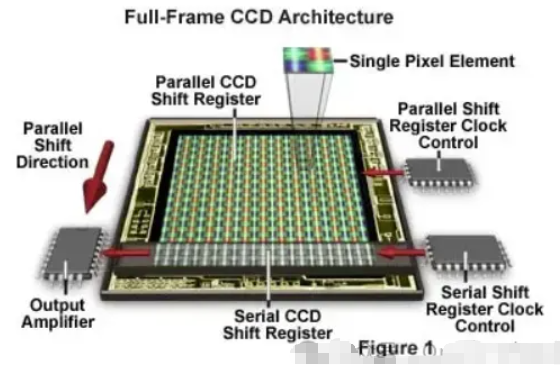
CCD (电荷耦合器件)就是一个经典的例子。
它由光敏像素和移位寄存器组成,像素之间由势垒隔开。
这些寄存器在读取过程中移动捕获的电荷——这就是图像数据被收集和传输的方式。
有多种类型:
- 全画幅传感器:几乎将整个表面用作传感器(需要机械快门)。
- 隔行传感器:具有交替的光敏区域和遮蔽区域,以加快读取速度。

首先进行积分,然后保存,接着进行垂直移位(步骤 1),然后逐个单元格地将数据移入输出寄存器,直到该行为空,然后再次进行垂直移位,依此类推。所需的时间称为快门日志。
每种传感器类型都有其自身的优势和劣势。
最终,图像质量取决于信号在转换过程中保持的清晰度和无噪声程度。
常见的CCD问题
如果你曾经在图像中看到过奇怪的垂直线或过曝条纹——那不是你的镜头的问题;那是物理现象。
- 光晕:在曝光过程中,当一个像素被光线过度填充并溢出到其相邻像素时发生的现象。
- 拖影:在读出过程中,当强光沿读出方向泄漏时发生。

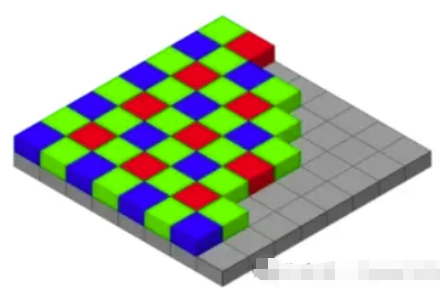
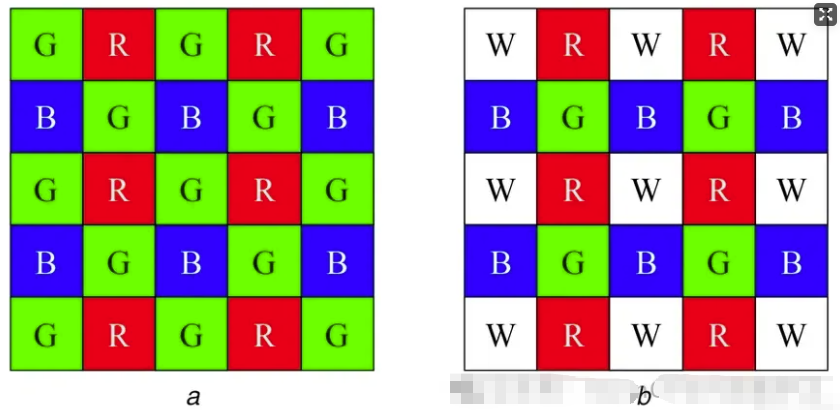
从黑白到彩色
相机中的光传感器主要检测的是强度,而不是颜色——因此,最初它们只能生成灰度图像。
为了增添色彩,我们可以:
- 将光光学地分成不同的波长(使用 3 个传感器分别检测 R、G 和 B)——但这很复杂。
- 或者使用彩色滤光片阵列(CFA) ——每个像素上都有微小的彩色滤光片。
最著名的 CFA 是拜耳图案(RGGB) ——其中绿色出现的频率是其他颜色的两倍,因为它是感知上最敏感的颜色。
如果一个像素缺少某种颜色(例如红色或蓝色),我们会根据其相邻像素进行插值——平均值计算速度很快,但插值计算能得到更好的结果。
还有RGBW模式,它增加了白色像素,以获得更好的弱光性能(例如在夜间)。
灰色部分是传感器,彩色部分是滤色片。
光学成像——透过镜头看世界
现在我们了解了传感器如何捕获光线——那么光线又是如何到达传感器的呢?
针孔相机模型——或Lochkameramodell——登场。
这是将三维现实投影到二维平面上的最简单模型。
有趣的事实:有些眼镜可以完全颠倒世界,但几分钟后你的大脑就会将其恢复原状——我们的视觉系统实际上会重新学习这种投影。
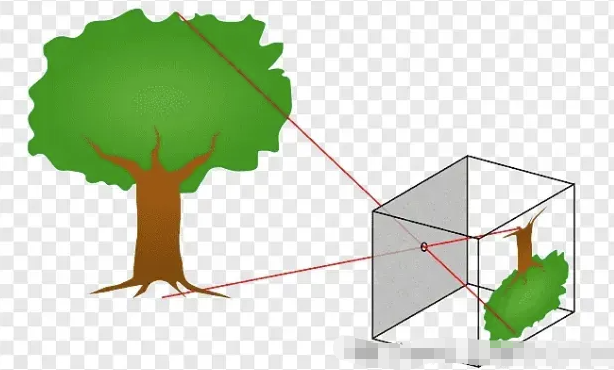
镜片类型:内视镜片、远视镜片、超远视镜片
- 以昆虫为中心的视角: “正常”视角(我们习惯看到的视角)。
- 远心投影:一种用于机器视觉进行精确测量的平行投影。
- 超中心:一次捕捉物体的多个面(用于检查瓶子、标签等)。
这些因素分别定义了世界如何投射到传感器上——而这种投射又深刻地影响着算法之后如何解释形状和距离。
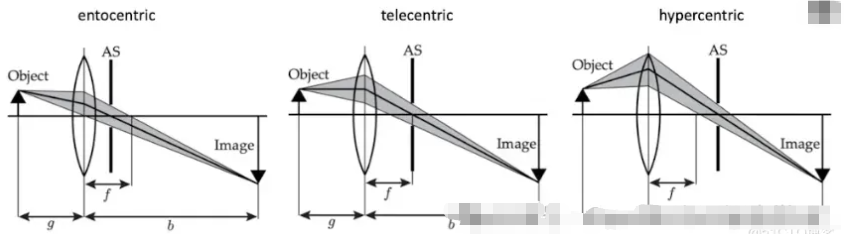
场景:

远程中心:

以过度中心视角为例

选择合适的镜头
在为计算机视觉系统选择镜头时,请考虑以下因素:
- 视角和焦距(定焦还是变焦?)
- 传感器兼容性(尺寸、安装方式等)
- 工作距离和孔径
- 分辨率(以每毫米线对数衡量)
- 光学质量——几何畸变和色差畸变
- 滤镜螺纹——用于特殊用途(例如红外截止滤镜、ND滤镜)
简而言之:你的视角决定了你眼中的世界是什么样的。
为什么这很重要
理解这些基本原理不仅仅是“相机理论”,它能区分一个好用的相机和一个坏的相机。
如果您想要可靠的目标检测或深度估计,您的数据源(摄像头)必须是干净的、经过校准的,并且能够被充分理解。
....
十三、开源目标跟踪算法
对象跟踪是一项计算机视觉任务,可以识别各种对象并通过视频帧跟踪它们。

了解视频中物体的位置有许多实际应用,尤其是在制造业和物流业。例如,物体跟踪可用于监控装配线、跟踪仓库中的库存,并帮助优化供应链管理。
在本文中,我们将探讨对象跟踪多年来的发展、工作原理以及前七种开源对象跟踪算法。
目标跟踪算法的演变
在我们了解对象跟踪的工作原理之前,让我们先了解它是如何产生的。
最初,在 20 世纪 80 年代末和 90 年代初,对象跟踪主要依赖于背景减法和帧差分技术等方法。这些方法具有开创性,但难以处理动态背景或光照条件的变化。
技术随着时间而发展,在 20 世纪 90 年代中后期,出现了基于特征的跟踪算法等新方法。很快,更复杂的跟踪解决方案问世,这些解决方案专注于物体的边缘和角落等特定特征。
20 世纪 90 年代,卡尔曼滤波和光流等机器学习技术的引入为高级跟踪铺平了道路。然而,真正的突破出现在 2010 年代,随着卷积神经网络(CNN) 和循环神经网络 (RNN) 等深度学习技术的发展。这些 AI 方法使复杂的物体跟踪具有更高的准确性、稳健性和适应性。如今的系统可以同时跟踪多个物体,即使在具有挑战性的条件下,也可以学习和适应新物体或环境。
目标跟踪算法的工作原理
对象跟踪的基本概念是使用算法检测视频中的对象并预测其在帧序列中的未来位置。它结合了对象检测和跟踪算法。对象检测使用参考帧中的边界框识别对象,而对象跟踪则预测其运动并在整个视频中跟踪它。一旦检测到对象,跟踪算法就可以从多个摄像机角度跟踪其在视频中随时间的运动,甚至可以同时跟踪多个对象。
其中涉及的几个关键技术如下:
- 特征提取:识别物体的独特特征,例如颜色、形状和纹理,以将其与背景和其他物体区分开来。
- 运动估计和轨迹预测:根据物体在前几帧中的运动预测物体的未来位置。
- 数据关联:为每个对象分配一个唯一的 ID,并确保它在各个帧之间保持一致,即使在部分遮挡或背景混乱的情况下也是如此。
- 重新识别:当物体超出画面范围或暂时被遮挡(例如另一个物体从其前面经过)时,重新识别方法可帮助软件在物体再次出现时检测并重新确定其身份。为此,通常使用基于深度学习的方法(如外观匹配)。
最流行的7个开源目标跟踪算法
ByteTrack
ByteTrack是一种用于多对象跟踪的计算机视觉算法。它为视频中的对象分配唯一的 ID 以跟踪每个对象。大多数跟踪方法仅使用得分高的检测框,而忽略得分较低的检测框,从而遗漏一些对象并导致轨迹碎片化。ByteTrack 通过在匹配过程中使用所有检测框(从高到低)来改善这种情况。
它根据运动相似性将高分检测框与现有轨迹匹配。轨迹是跟踪对象轨迹的短片段,用于保持随时间推移的连续跟踪。通过将高分检测框与轨迹匹配,ByteTrack 即使在部分被遮挡或快速移动时也能正确识别和跟踪对象。对于低分检测,ByteTrack 会根据对象与现有轨迹的相似性从背景中识别出对象。

由于 ByteTrack 可用于跟踪视频中的多个对象,因此它可以应用于波士顿动力公司的机器人在仓库中堆放箱子等场景。这些机器人使用机器视觉来精确地抬起、移动和放置箱子。ByteTrack 可以通过精确跟踪每个箱子的位置和移动来提高其效率。
Norfair
Tryolabs 的Norfair是一个轻量级且可自定义的对象跟踪库,可与大多数检测器配合使用。用户定义用于计算跟踪对象与新检测之间的距离的函数,该函数可以像欧几里得距离的一行代码一样简单,也可以使用嵌入或 Person ReID 模型等外部数据更复杂。
它还可以轻松集成到复杂的视频处理管道中,或用于从头开始构建视频推理循环。这使得 Norfair 适用于工厂工人监控、监控、体育分析和交通监控等应用。
Norfair 提供了几个预定义的距离函数,用户可以创建自己的函数来实现不同的跟踪策略。它支持各种视频分析应用程序并支持 Python 3.8+,Python 3.7 的最新版本是 Norfair 2.2.0。
MMTracking
MMTracking是一个免费的开源工具箱,旨在分析视频。它使用PyTorch构建,是名为 OpenMMLab 的大型项目的一部分。MMTracking 的独特之处在于它将多个视频分析任务整合到一个平台中。这些任务包括对象检测、对象跟踪,甚至视频实例分割。凭借其模块化设计,您可以轻松交换这些工具以创建满足您特定需求的自定义方法。
它还可以与其他 OpenMMLab 项目(尤其是MMDetection)很好地配合使用。这意味着您只需更改一些设置即可将 MMDetection 中可用的任何对象检测器与 MMTracking 一起使用。最重要的是,MMTracking 包含预构建的模型,这些模型的准确率非常高,有些甚至比原始版本更好。
MMTracking 非常适合需要高精度和高速度的应用,例如制造业中的自动检测和自动驾驶。其模块化设计允许轻松定制,使其成为各种视频分析任务的强大工具。
DeepSORT
DeepSORT(深度简单在线实时跟踪)是 SORT 算法的改进版本。它使用深度学习特征提取器来识别各种物体,非常适合同时跟踪多个物体。DeepSORT 使用卡尔曼滤波器来预测物体运动。它非常擅长处理物体之间的遮挡和相互作用,非常适合监控和人群监控应用。
FairMOT
FairMOT是一种基于无锚点物体检测架构 CenterNet 的跟踪方法。与其他将检测视为主要任务、将重新识别 (re-ID) 视为次要任务的框架不同,FairMOT 将这两项任务同等对待。它具有简单的网络结构,包含两个相似的分支:一个用于检测物体,另一个用于提取重新识别特征。
FairMOT 使用ResNet-34作为主干,以实现准确度和速度的良好平衡。它使用深度层聚合 (DLA) 增强了此主干,以组合来自多个层的信息。上采样模块中的可变形卷积可动态调整以适应不同的对象尺度和姿势,这有助于解决对齐问题。基于 CenterNet 的检测分支具有三个并行头,用于估计热图、对象中心偏移和边界框大小。re-ID 分支生成特征以识别对象。
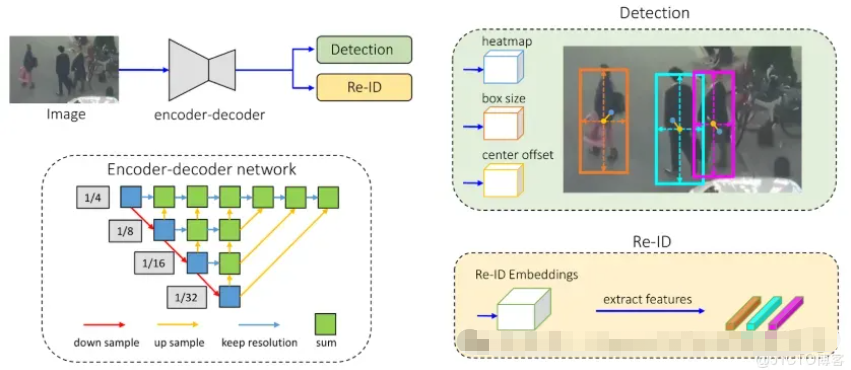
FairMOT 适用于需要平衡精度和速度的场景,例如制造车间的实时质量检测、安全监控和自动驾驶汽车导航。它能够处理遮挡和动态物体尺度,因此是这些应用的理想选择。
BoT-SORT
BoT-SORT(SORT 的技巧包)是一种跟踪多个物体的方法,它改进了 SORT(简单在线实时跟踪)等传统方法。特拉维夫大学的研究人员开发了 BoT-SORT,以便能够更准确、更可靠地跟踪物体。它结合了运动和外观信息来区分不同的物体并随着时间的推移保持它们的身份。

BoT-SORT 还包含一项称为“相机运动补偿 (CMC)”的功能,该功能考虑了相机的运动,因此即使相机不静止,物体跟踪也能保持准确。此外,BoT-SORT 使用更先进的卡尔曼滤波器,可以更精确地预测被跟踪物体的位置和大小。这些改进有助于 BoT-SORT 表现出色,即使在具有大量运动或拥挤场景的具有挑战性的情况下也是如此。它在标准数据集上的 MOTA(多物体跟踪准确度)、IDF1(身份 F1 分数)和 HOTA(高阶跟踪准确度)等关键性能指标中排名第一。
BoT-SORT 具有高精度和高稳定性的跟踪能力,是工业应用的理想选择。在大型仓库等环境中,光照条件可能会发生变化,其他物品经常会遮挡物体,但 BoT-SORT 仍能表现出色。它可用于跟踪包裹和托盘,以改善库存管理并降低物品丢失的风险。它能够监控货物从收货到发货的整个过程,有助于简化运营并提高供应链的可视性。精确的跟踪支持物流运营,实时更新每件物品的位置和状态。
StrongSORT
StrongSORT旨在改进经典的 DeepSORT 算法。它是为了解决多对象跟踪中的常见问题而开发的,例如检测准确性和对象关联。StrongSORT 使用强大的对象检测器、复杂的特征嵌入模型和多种技巧来提高跟踪性能。它还引入了两种新算法:AFLink(无外观链接)和 GSI(高斯平滑插值),它们有助于更准确地跟踪对象,而无需过度依赖外观特征。
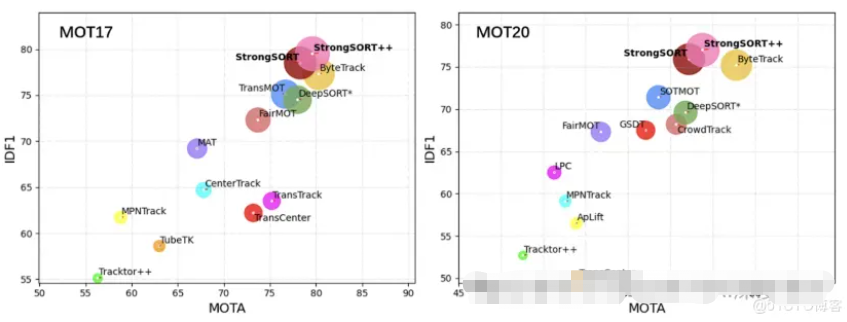
AFLink 和 GSI 都是轻量级的,易于集成到各种跟踪系统中。AFLink 仅使用时空信息即可帮助将轨迹链接在一起,使其既快速又准确。GSI 通过考虑运动信息来改进处理缺失检测的方式。这些改进使 StrongSORT 在多个公共基准测试中取得了最佳成绩,包括 MOT17、MOT20、DanceTrack 和 KITTI。
StrongSORT 的准确性和稳健性使其可用于需要非常仔细地跟踪物体的应用中。例如,假设有一个摄像头可以鸟瞰一个建筑工地,那里有许多重型车辆在不断移动。StrongSORT 可以实时监控这些车辆,帮助防止事故发生,并确保高效运营。它能够处理遮挡和多变的光照条件,即使在建筑工地动态且通常混乱的环境中也能可靠运行。
目标跟踪的挑战和限制
虽然对象跟踪技术已经取得了长足的进步,但仍然存在一些因素,导致难以获得一致的结果。使用这些对象跟踪工具时需要牢记的一些挑战和限制是:
遮挡:遮挡是指一个物体遮挡另一个物体,例如两个人擦肩而过,或者一辆车在桥下行驶。系统很难跟踪部分被遮挡的物体。
外观的变化:物体会根据其与相机的距离、角度或大小而看起来不同。
光照变化:光照变化会改变物体的外观,使检测和跟踪变得复杂。计算机视觉系统通常难以应对这些变化。
多摄像头跟踪:跨多个摄像头跟踪物体涉及一个称为 ReID 的过程,该过程涉及一组不同的算法。
可扩展性:针对许多摄像机或分散部署的扩展解决方案可能很复杂且昂贵,通常需要额外的基础设施或定制开发。
....
十四、视觉应掌握的必备工具
计算机视觉是一个使机器能够解释和理解视觉世界的领域。其应用正在迅速扩展,从医疗保健和自动驾驶汽车到安全系统和零售。
在本文中,我们将介绍每个计算机视觉开发人员(无论是初学者还是高级用户)都应该掌握的十个基本工具。这些工具的范围从用于图像处理的库到有助于机器学习工作流程的平台。
1. OpenCV
初级:
OpenCV 是一个流行的开源库,专为计算机视觉任务而设计。对于初学者来说,这是一个很好的起点,因为它可以让您轻松执行图像过滤、操作和基本功能检测等任务。使用 OpenCV,您可以先学习基本的图像处理技术,例如调整大小、裁剪和边缘检测,这些技术为更复杂的任务奠定了基础。
高级:
专家用户:随着您的进步,OpenCV 会提供各种功能,用于实时视频处理、对象检测和摄像机校准。高级用户可以将 OpenCV 用于高性能应用程序,包括将其与机器学习模型集成,或在实时系统中将其用于面部识别或增强现实等任务。
2. TensorFlow
初级:
TensorFlow 是 Google 开发的一个功能强大的框架,用于构建和训练机器学习模型,尤其是在深度学习方面。由于其广泛的文档和教程,它对初学者友好。作为新开发人员,您可以从用于图像分类和对象检测等任务的预构建模型开始,从而了解模型如何从数据中学习的基础知识。
免费 Tensorflow 训练营
高级:
对于高级用户,TensorFlow 的灵活性允许您构建复杂的神经网络,包括卷积神经网络 (CNN) 和用于高级图像识别任务的 Transformer。它能够从小型模型扩展到大型生产级应用程序,这使其成为任何计算机视觉专家的必备工具。此外,TensorFlow 还支持分布式训练,使其成为大规模数据集和高性能应用程序的理想选择。
3. PyTorch
初级:
PyTorch 由 Facebook 开发,是另一个广泛用于构建神经网络的深度学习框架。其简单的 Python 性质使初学者可以轻松掌握模型创建和训练的基础知识。初学者会喜欢 PyTorch 在创建用于图像分类的简单模型方面的灵活性,而不必担心太多的技术开销。
高级:
高级用户可以使用 PyTorch 的动态计算图,在构建复杂架构、自定义损失函数和优化器时提供更大的灵活性。对于研究人员来说,这是一个不错的选择,因为 PyTorch 提供了对视觉语言模型、生成对抗网络 (GAN) 和深度强化学习等尖端模型的无缝实验。由于其高效的内存管理和 GPU 支持,它在处理大型数据集方面也表现出色。
4. Keras
初级:
Keras 是一个运行在 TensorFlow 之上的高级神经网络 API。它非常适合初学者,因为它抽象了构建深度学习模型所涉及的大部分复杂性。借助 Keras,您可以快速为图像分类、对象检测等任务甚至更复杂的任务(如分割)构建模型原型,而无需具备广泛的深度学习算法知识。
高级:
专业用户:对于更有经验的开发人员来说,Keras 仍然是一个有用的工具,可以在深入研究自定义之前快速构建模型原型。Keras 不仅简化了流程,还允许用户通过直接与 TensorFlow 集成来扩展他们的项目,从而让高级用户能够控制微调模型和管理大型数据集的性能优化。
5. PaddlePaddle (用于光学字符识别的 PaddleOCR)
初级:
PaddlePaddle 由百度开发,通过其 PaddleOCR 模块提供了一种简单的方法来处理光学字符识别 (OCR) 任务。初学者可以快速设置 OCR 模型,以最少的代码从图像中提取文本。API 的简单性使您可以轻松地将预先训练的模型应用于您自己的项目,例如扫描文档或从图像中实时读取文本。
高级:
Professional 用户可以在自己的数据集上自定义架构和训练模型,从而受益于 PaddleOCR 的灵活性。该工具允许针对特定的 OCR 任务进行微调,例如多语言文本识别或手写文本提取。
PaddlePaddle 还可以与其他深度学习框架很好地集成,为复杂管道中的高级实验和开发提供了空间。
6. 标注工具(例如 Labelbox、Supervisely)
初级:
标注工具对于创建带注释的数据集至关重要,尤其是对于计算机视觉中的监督学习任务。Labelbox 和 Supervisely 等工具通过提供直观的用户界面简化了图像注释过程,使初学者可以更轻松地创建训练数据集。无论您是在执行简单的对象检测还是更高级的分割任务,这些工具都可以帮助您开始进行正确的数据标记。
高级:
处理大规模数据集的经验丰富的专业人员,Supervisely 等标记工具提供自动化功能,例如预注释或 AI 辅助标记,从而显着加快流程。这些工具还支持与您的机器学习管道集成,从而实现团队之间的无缝协作并大规模管理注释。专业人士还可以利用基于云的工具进行分布式标签、版本控制和数据集管理。
7. NVIDIA CUDA 和 cuDNN
初级:
CUDA 是 NVIDIA 开发的并行计算平台和编程模型,而 cuDNN 是用于深度神经网络的 GPU 加速库。对于初学者来说,这些工具可能看起来很技术性,但它们的主要目的是利用 GPU 功能加速深度学习模型的训练。通过在训练环境中正确设置 CUDA 和 cuDNN,可以显著提高模型训练的速度和优化,尤其是在使用 TensorFlow 和 PyTorch 等框架时。
高级:
专家可以利用 CUDA 和 cuDNN 的全部功能来优化高要求应用程序的性能。这包括为特定操作编写自定义 CUDA 内核、有效管理 GPU 内存以及微调神经网络训练以实现最大速度和可扩展性。这些工具对于使用大型数据集并需要模型具有顶级性能的开发人员来说是必不可少的。
8. YOLO(你只看一次)
初级:
YOLO 是一种快速对象检测算法,在实时应用程序中特别受欢迎。初学者可以使用预先训练好的 YOLO 模型,通过相对简单的代码快速检测图像或视频中的对象。YOLO 的易用性使 YOLO 成为那些希望探索对象检测而无需从头开始构建复杂模型的用户的绝佳切入点。
高级:
YOLO 提供了在自定义数据集上微调模型以检测特定对象的机会,从而提高了检测速度和准确性。YOLO 的轻量级特性使其能够部署在资源受限的环境(如移动设备)中,使其成为实时应用程序的首选解决方案。专业人士还可以尝试使用较新版本的 YOLO,调整参数以满足特定的项目需求。
9. DVC(数据版本控制)
初级:
DVC 是机器学习项目的版本控制系统。对于初学者,它有助于管理和跟踪数据集、模型文件和实验,从而轻松保持一切井井有条。DVC 不是像 Git 那样仅对代码进行版本控制,而是确保持续跟踪您正在处理的数据和模型,从而减少手动管理机器学习项目数据的麻烦。
高级:
专家用户可以将 DVC 用于大型项目,从而实现可重复性和跨团队协作。DVC 与现有工作流程完美集成,可以更轻松地管理多个实验、跟踪大型数据集中的更改以及根据以前的运行优化模型。对于复杂的机器学习管道,DVC 通过将所有内容保持在版本控制之下来帮助简化工作流程,确保从数据收集到模型部署的一致性。
10. Git 和 GitHub
初级:
Git 和 GitHub 是版本控制和协作的重要工具。初学者会发现 Git 对于管理项目历史记录和跟踪更改很有用,而 GitHub 允许与他人轻松共享代码。如果您刚开始接触计算机视觉,学习 Git 可以帮助您维护井井有条的项目工作流程、协作处理开源项目并熟悉基本的版本控制技术。
高级:
经验丰富的专业人员可以利用 Git 和 GitHub 来管理复杂的研究项目,处理来自多个开发人员的贡献,并确保大型存储库中的版本一致性。GitHub Actions 允许工作流程自动化,例如测试和部署模型,这对于机器学习管道中的持续集成和部署 (CI/CD) 特别有用。高级用户还可以从使用 Git LFS(大文件存储)来管理其 Git 项目中的大型数据集中受益。
综述
OpenCV 和 Keras 等工具为初学者提供了简单的切入点,而 PyTorch、TensorFlow 和 DVC 等高级选项则帮助经验丰富的开发人员应对更复杂的挑战。
使用 CUDA 进行 GPU 加速,使用 YOLO 进行高级对象检测,并使用标记工具进行高效数据管理,确保您可以有效地构建、训练和部署强大的模型。
....
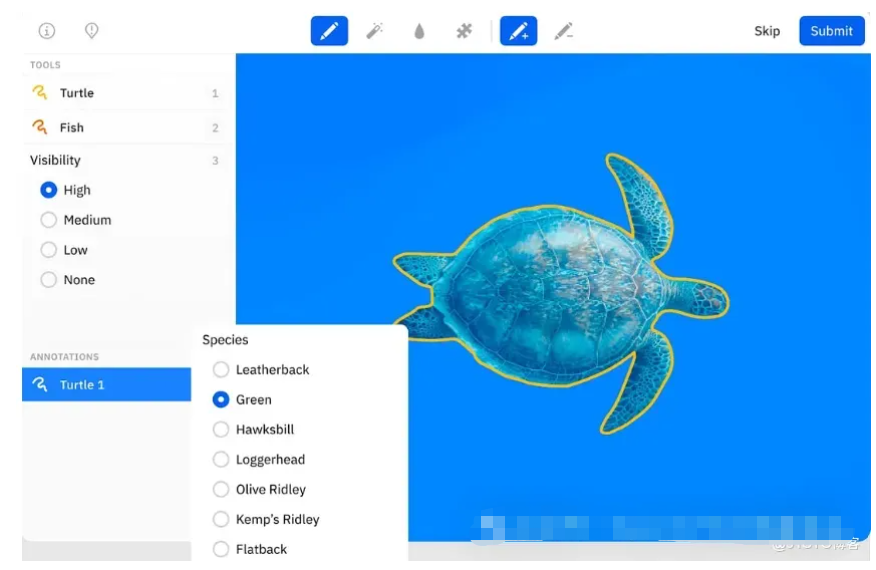
十五、视觉图像标注工具
什么是图像标注工具
图像标注工具用于标记一组视觉数据,以确保机器学习模型训练的准确性。换句话说,用于训练计算机视觉模型的数据质量与其输出的准确性直接相关。正确标记的数据意味着计算机视觉模型能够识别和分类对象。因此,为其提供高质量的数据不仅是成功的关键,也是提高效率和节省成本的关键。
图像标注适用于众多行业,从医疗应用到零售、制造和地理空间等等。例如,DICOM(医学数字成像和通信)是医疗行业使用的标准格式,涵盖X射线、CT扫描、MRI扫描和超声图像。其应用范围广泛,从医学到地理空间成像,再到开发用于自动照片编辑的AI照片编辑工具。经过标注和训练的计算机视觉算法可以解读重要的元数据,用于图像分割、目标检测、图像配准、疾病诊断和治疗计划。
虽然标记数据是训练机器学习模型的基础,但由于它通常依赖于人工注释,因此可能会出现错误,因此拥有一个简化和改进这一过程的工具是关键。
Encord
Encord是一个端到端数据开发平台,配备先进的图像标注工具,适用于复杂的计算机视觉和多模态用例。该平台提供先进的模型辅助标记和可定制的工作流程,以加速图像标注项目并构建可用于生产的模型。
对于需要处理高复杂度或大规模数据集的团队,Encord 是综合能力极强的选择。无论是医疗影像、卫星数据还是视频标注,它在多模态标注和生产级 MLOps 集成方面的支持堪称行业标杆:兼容所有主流数据类型(图像、视频、DICOM 医疗文件、地理空间数据、音频及文档);支持自定义标注流程,配备专业审核与质量检测工具以确保数据准确性;内置模型评估与监控功能,能迭代优化数据质量,形成 “标注 - 训练 - 反馈” 闭环;同时提供强大的 API 与 SDK,支持程序化接入,灵活适配现有工作流。
收费:采用定制化套餐模式,根据团队规模与具体需求定价。
官网:https://encord.com/?source=25
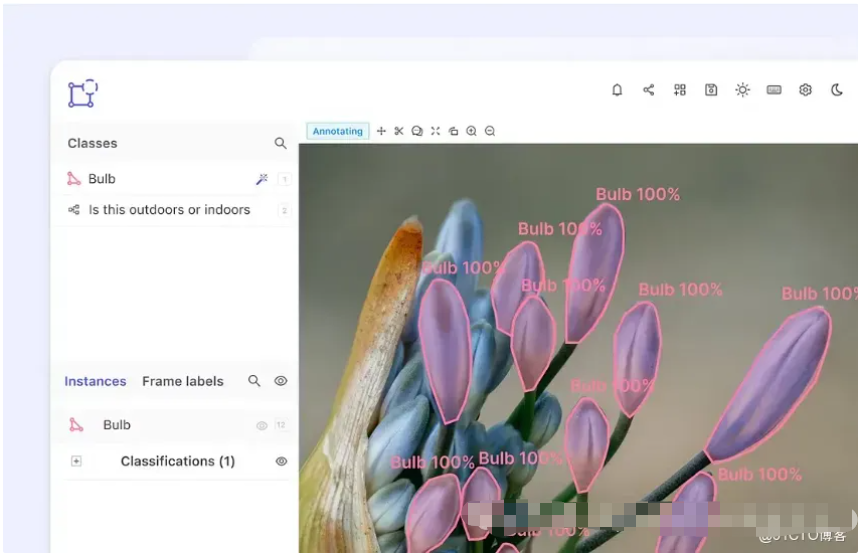
主要特点
- 人工智能辅助标记:利用 SOTA 自动标记功能(例如 Meta AI 的 Segment Anything 模型 ( SAM )),以 99% 的准确率自动完成 97% 的图像注释。
- 全套工具: Encord 支持一系列标签选项,例如边界框、可旋转框、多边形、折线、关键点和分类,以支持您的模型要求。
- 使用模型在环加速:将您自己的模型带到 Encord 平台或利用我们的一个代理预先标记数据集。
- 可扩展性:Encord 支持多达 500,000 张图像的大量数据集,让您可以扩展 AI 项目。
- 构建平衡的数据集: 在整合的可视化浏览器中筛选和切片数据集,并一键导出进行标记。Encord 支持深度搜索、筛选和元数据分析。
- 复杂本体:在数据模式中构建嵌套关系结构,以提高模型输出的质量。
- 批量分类:利用自然语言或相似性搜索选择大型数据集并进行批量标记,排队审核以加速标记操作。
- 构建可靠的质量控制工作流程:构建具有多步骤审查阶段和质量保证共识基准的强大工作流程。
- 查找并修复标签错误:自动显示标签错误,以将您的注意力转移到影响模型性能的标签上。
- 协作:通过权限控制用户角色,管理任务分配并无限扩展您的 MLOps 工作流程。
- 企业级安全性作为标准: Encord Annotate 符合通用数据保护条例(GDPR )、系统和组织控制 2 (SOC 2 ) 和健康保险流通与责任法案 ( HIPAA ) 标准,同时使用高级加密协议来确保数据隐私。
- 集成: Encord 让您完全掌控数据。安全连接您的原生云存储,并以编程方式控制工作流程。先进的 Python SDK 和 API 访问,轻松导出为 JSON 和COCO格式。
- 集成数据标记服务:将您的标记任务外包给经过审查、培训和专业的注释人员组成的专家团队。
涵盖的方式
- 图像
- 视频
- DICOM
- SAR
- 文件
- 音频
G2 评测总结
Encord 的评分为 4.8/5(基于 60 条评论)。用户更青睐 Encord 强大的本体功能,该功能能够为各种规模的数据定义丰富的分类法。此外,该平台的协作功能和精细的注释工具有助于用户提升注释质量。
亚马逊 SageMaker Ground Truth
Amazon SageMaker Ground Truth 是一个人机交互数据标记平台,提供标记大型数据集的功能。它提供自助服务和托管服务选项,帮助您简化多项 CV 任务的注释工作流程。
主要特点
- 数据生成:该平台提供工具来对几个数据点上的预训练模型进行微调,以生成合成数据样本,从而进行更多样化的训练。
- 模型评估: Sagemaker Ground Truth 让您能够通过人工反馈,根据准确性、相关性、毒性和偏见等多项指标来评估基础模型。
- 标签模板:它具有超过三十个标签模板,适用于多个 CV 和 NLP 任务,包括图像分类、对象检测、文本分类和命名实体识别 ( NER )。
- 交互式仪表板:该工具提供直观的仪表板和用户友好的界面,以监控多个项目的标签进度。
涵盖的方式
- 图像
- 视频
- 文本
- 点云
优点和缺点
优点:
- 自动标注
- 支持多种数据类型
- 可定制的标签工作流程
- 与 Amazon SageMaker 集成
缺点:
- 与非 AWS 服务结合使用可能会带来摩擦
- 对贴标机的控制有限
- 设置需要熟悉 AWS 的 IAM 策略、权限和一般 AWS 环境
- 可能缺乏某些小众或复杂项目所需的定制深度
G2 评测总结
Amazon SageMaker Ground Truth 的评分为 4.1/5(基于 19 条评论)。用户喜欢它的易用性和高级注释功能。然而,他们认为它价格昂贵,而且追踪标记性能具有挑战性。
Scale Rapid
Scale Rapid 是一个支持计算机视觉用例的数据和标签服务平台。它专注于人工反馈强化学习 ( RLHF )、用户体验优化、大型语言模型 (LLM) 和合成数据。
主要特点
- 支持的数据类型: Scale 允许您注释文本、图像、视频、音频和点云数据。
- 可定制的工作流程:提供根据特定项目要求和用例定制的标签工作流程。
- 数据标注服务:为图片、文本、音频、视频等多种数据类型提供高质量的数据标注服务。
- 可扩展性:能够处理大型注释项目并适应不断增长的数据集和注释需求。
涵盖的方式
- 图像
- 视频
- 测试
- 文件
- 音频
优点和缺点
优点:
- 通过人工参与标记实现高质量注释
- 针对速度进行了优化,即使在大型数据集上也能提供快速的交付时间
- 支持一系列复杂数据类型,包括 3D 点云和 LiDAR 数据
- 内置质量控制措施
缺点:
- 可能无法提供高度特定或非常规标签任务所需的深度定制
- 与一些竞争对手相比,自动化标签集成程度不够
- 不能直接集成到机器学习流程中
G2 评测总结
Scale Rapid 的评分为 4.4/5(基于 11 条评论)。用户表示它易于学习,无需复杂的安装程序。然而,他们认为该工具的用户界面略显笨重,且定价机制复杂。
Supervisely
Supervisely 是一个端到端的计算机视觉平台,提供多种用于标记图像和视频的注释工具。它具有基于 AI 的标记功能,允许用户通过高级机器学习模型自动化标记工作流程。
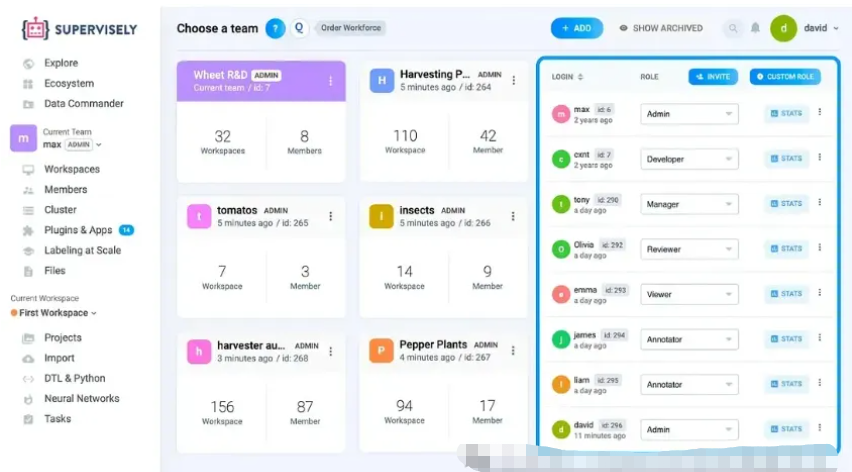
主要特点
- 多功能注释工具:它支持多种注释类型,包括边界框、多边形、折线、点和分割蒙版,以实现精确标记。
- 支持的数据类型: Supervisely 允许您标记图像、视频、点云和医学图像数据。
- 智能标签工具:根据您的使用情况,提供基于可定制神经网络的类别无关智能工具,用于捕获任何对象类型。
- 协作:该平台允许您与团队成员协作并分配相关的用户角色来跟踪问题和标记性能。
涵盖的方式
- 图像
- 视频
- 点云
- DICOM
优点和缺点
优点:
- 界面直观且高度可视化
- 提供针对高级注释类型(例如语义分割)的专用工具
- 整合人工智能辅助标签工具
- 用户可以创建自定义插件和脚本
缺点:
- 不提供内置的标签劳动力
- 缺乏一些高级工作流自动化功能
G2 评测总结
Supervisely 的评分为 4.7/5(基于 10 条评论)。用户喜欢该工具与 Supervisely 生态系统中多个应用的集成,这带来了流畅的用户体验。然而,其选项数量可能过于繁琐,而且平台存在延迟问题。
Labelbox
Labelbox 是一家成立于 2017 年的美国数据注释平台,它通过协作和模型评估工具为整理和标记数据集提供了统一的框架。
Labelbox 是一站式数据与模型管理的典型代表,将数据标注、模型集成与数据分析功能整合于一体,支持多种文件格式,且能与主流云服务及机器学习工具无缝对接。该工具覆盖从标注到训练的全流程,减少工具切换成本;支持主动学习(Active Learning),可优先标注对模型提升最关键的数据,提升效率;采用弹性扩展架构,能随业务增长快速扩容,成本可控性强;同时提供完善的 SDK 与 API 支持,便于技术团队二次开发与集成。
收费:提供免费基础版与付费进阶版,满足不同规模项目的需求。
官网:https://labelbox.com/?source=25
除了独立的图像标记平台外,该工具还提供由数据标记专家提供的托管注释服务。
主要特点
- 数据管理:Labelbox 提供 QA 工作流程和数据注释器性能跟踪。
- 可定制的标签界面:它具有用户友好的界面,为特定需求提供易于导航的编辑器。
- 自动化:允许与 AI 模型集成,实现自动数据标记,从而加速注释过程。
- 注释功能:它支持图像以外的多种数据类型的注释,包括文本、视频、音频、地理空间和医学图像。
涵盖的方式
- 图像
- 视频
- 文本
- 音频
优点和缺点
优点:
- 具有质量保证工具,例如共识评分和注释审查
- 包括人工智能辅助标记工具
- 与流行的机器学习框架和平台集成
缺点:
- 可能无法提供高度专业化的工作流程所需的深度定制
- 高度基于云,这可能会对数据治理严格的行业带来挑战
- 处理高分辨率图像或视频数据有时可能会影响平台性能
G2 评测总结
LabelBox 的评分为 4.7/5(基于 33 条评论)。用户认为该工具的数据管理功能很实用。然而,他们认为它在处理高分辨率图像时效果不佳。
Playment
Playment 是一家总部位于印度的端到端数据注释平台,成立于 2015 年,目前由 Telus 旗下运营。它通过聘请计算机视觉团队为多种用例注释训练数据,提供托管注释服务。

主要特点
- 数据标注服务:为各种数据类型提供高质量的数据标注服务,包括图像、视频、文本、传感器数据等。
- 支持:承包商和数据标签员的全球劳动力。
- 可扩展性:能够处理大规模注释项目并适应不断增长的数据集和注释需求。
- 音频标记工具:该工具具有语音识别训练平台,可以处理五百多种语言和方言。
涵盖的方式
- 图像
- 视频
- 点云
优点和缺点
优点:
- 在自动驾驶、地理空间分析和室内地图等复杂用例中表现出色
- 包括具有质量控制机制的人机交互流程
- 多个质量控制层,包括审计、共识评分和反馈循环
- 允许在工作流程中进行一些定制
缺点:
- 缺乏一些先进的人工智能辅助标签功能
- 主要基于云的平台,这可能会给严格数据隐私的组织带来挑战
G2 评测总结
Playment 的评分为 4.7/5(基于 11 条评论)。用户认为 Playment 的注释速度快且准确。然而,他们认为该工具价格昂贵,且自动标记功能需要进一步改进。
Appen
Appen 是一家成立于 1996 年的数据标签服务平台,是市场上最早、历史最悠久的解决方案提供商之一,为各行各业提供数据标签服务。2019 年,Appen 收购了Figure Eight,以扩展其软件能力,并帮助企业训练和改进其计算机视觉模型。

主要特点
- 数据标签服务:支持多种注释类型(边界框、多边形和图像分割)。
- 数据收集:数据采购(预先标记的数据集)、数据准备和真实世界模型评估。
- 自然语言处理:支持情感分析、实体识别和文本分类等自然语言处理 (NLP) 任务。
- 图像和视频分析:分析图像和视频以执行对象检测、图像分类和视频分割等任务。
涵盖的方式
- 文本
- 图像
- 音频
- 视频
优点和缺点
优点:
- 采用共识评分、准确性监控和注释审查等质量控制流程
- 可以与流行的机器学习工具和平台集成
- 多语言数据标记专业知识
缺点:
- 并非完全为实时反馈或迭代调整而设计
- 依赖于自己管理的员工,可能缺乏希望使用内部团队的公司所需的集成选项
G2 评测总结
Appen 的评分为 4.2/5(基于 28 条评论)。用户喜欢这款工具基于网页,无需特殊安装程序。然而,该平台的服务器经常崩溃,而且支持团队的响应速度很慢。
Dataloop
Dataloop 是一个位于以色列的数据标记平台,为数据管理和注释项目提供全面的解决方案。该工具提供涵盖图像、文本、音频和视频注释的数据标记功能,帮助企业训练和改进其机器学习模型。
主要特点
- 数据注释:支持多种图像注释任务,包括分类、检测和语义分割。
- 协作工具:它具有注释者之间的实时协作、项目共享和版本控制工具,可实现高效的团队合作。
- 数据管理:提供数据管理功能,包括数据版本控制、跟踪和组织,以简化工作流程。
- 模型管理: Dataloop 提供工具来管理不同模型版本并从模型市场下载 SOTA 模型。
涵盖的方式
- 图像
- 视频
优点和缺点
优点:
- 支持多种注释类型
- AI辅助标签功能
- 具有质量控制机制,包括注释审查和共识检查
- 与流行的机器学习工具和平台集成
缺点:
- 高度具体的工作流程或特定的注释要求可能需要额外的定制
- 对自然语言处理 (NLP) 或音频数据的工具和支持相对有限
G2 评测总结
Dataloop 的评分为 4.4/5(基于 90 条评论)。该工具的优点包括易用性和注释效率。然而,用户发现它学习起来比较困难,而且经常遇到性能问题。
SuperAnnotate
SuperAnnotate 是一个端到端 AI 平台,提供数据管理和自动注释工具,并支持 MLOps 功能。它还允许您使用带注释的数据和 RLHF 对 LLM 进行微调。
主要特点
- 多数据类型支持:用于标记视频、文本、音频和图像数据的多功能注释功能。
- AI辅助:集成AI辅助标注,加速标注流程,提高效率。
- 定制:提供可定制的注释界面和工作流程,以根据特定的项目要求定制注释任务。
- 导出格式:SuperAnnotate 支持多种数据格式,包括 JSON、COCO 和 Pascal VOC 等流行格式。
涵盖的方式
- 图像
- 文本
- 视频
- 音频
优点和缺点
优点:
- 支持多种注释类型
- 包括人工智能辅助标签功能
- 与流行的机器学习框架集成
缺点:
- 不提供内置注释器
- 不像其他平台那样专注于自然语言处理 (NLP) 任务
- 大型视频数据集或高分辨率媒体的挑战
G2 评测总结
SuperAnnotate 的评分为 4.9/5(基于 137 条评论)。用户认为该工具功能全面,界面直观。然而,也有人抱怨其自定义工作流程设置和高昂的价格。
V7 Labs
V7 是一家总部位于英国的数据注释平台,成立于 2018 年。该公司支持团队使用自动化流程和自定义工作流程注释图像和视频数据。该平台还提供模型和数据管理工具,帮助用户为可扩展的 AI 项目构建高质量的训练数据。

主要特点
- 协作能力:项目管理和自动化工作流程功能,具有实时协作和标记功能。
- 数据管理:该工具提供数据管理功能,包括过滤和排序数据的功能。它还有助于在团队和数据集级别组织和管理数据类。
- 自动注释:具有自动注释功能,可让您使用深度学习模型创建像素完美的多边形蒙版。
- 自动跟踪: V7 提供自动跟踪功能,用于长视频中的对象跟踪和实例分割。
涵盖的方式
- 图像
- 视频
- DICOM
优点和缺点
优点:
- 高级 AI 辅助标记功能
- 支持多种注释类型,包括边界框、多边形和关键点
- 与流行的机器学习框架和云存储提供商集成
缺点:
- 主要关注图像和视频数据,未针对 NLP 或音频任务进行优化
- 一些人工智能辅助功能和集成在本地部署中可能会受到限制,因为它们依赖于云基础设施
G2 评测总结
V7 的评分为 4.8/5(基于 52 条评论)。用户认为其自动化和协作功能非常有用。然而,他们认为 V7 缺乏文件操作选项,并且其排序和过滤功能在处理大文件时效果不佳。
Hive
Hive 是一个内容审核平台,提供深度学习模型来突出显示图片、视频、文本和音频中有害且露骨的内容。它还具有搜索和生成 API,可以可视化图片和视频之间的相似性,并根据文本提示生成图片。
主要特点
- 易于使用: Hive 提供直观的界面,具有多个内置图像和文本分类模型。
- 嵌入:该平台允许您快速创建文本嵌入,以构建基于检索增强生成 ( RAG ) 的 LLM。
- 搜索: Hive 提供丰富的网页搜索功能。您可以使用图片提示来检索类似图片的相关链接。
- 生成人工智能 (Gen AI): Hive 具有 API,可根据文本提示生成文本、图像和视频。
涵盖的方式
- 图像
- 文本
- 音频
优点和缺点
优点:
- 可以对图像进行实时审核
- 允许用户创建自定义审核类别和规则
- 包括强大的 API 选项,可无缝集成到现有工作流程中
缺点:
- 复杂案件仍需人工监督
- 对于利基领域或高度特定的内容类别可能不那么有效
- 一些定制挑战,例如专门的审核工作流程。
G2 评测总结
Hive 的评分为 4.6/5(基于 528 条评论)。用户认为其项目管理和协作功能很实用。然而,其界面导航困难,且存在一些小故障,导致操作复杂。
Label Studio
Label Studio 是一个流行的开源数据标注平台,用于标注各种类型的数据,包括图像、文本、音频和视频。它支持协作标注、自定义标注界面以及与机器学习 (ML) 流程的集成,以执行数据标注任务。

主要特点
- 可定制的标签界面:Label Studio 允许您通过灵活的配置标记数据,从而允许您根据特定任务定制注释界面。
- 协作工具:实时注释和项目共享功能,实现注释者之间的无缝协作。
- 导出格式:Label Studio 支持多种数据格式,包括 JSON、CSV、TSV 和 VOC XML(如 Pascal VOC),方便从不同来源进行机器学习任务的集成和注释。
- ML 管道: Label Studio 可让您将模型开发管道与数据标记项目连接起来。该方法允许您使用 ML 模型预测标签、评估模型性能并执行人工参与的标记。
涵盖的方式
- 图像
- 音频
- 文本
- 视频
优点和缺点
优点:
- 该平台是开源的,允许用户下载、定制和运行,无需支付许可费用
- 支持多种数据类型和注释类型
- 可定制的用户界面,允许用户创建适合特定项目需求的独特注释界面
- 与机器学习工作流程和其他平台的集成
缺点:
- 需要预标记或 AI 注释支持的用户需要集成第三方工具或自定义模型
- 未针对大规模高通量实时标记进行优化
- 对高级项目管理功能(如工作流自动化和任务优先级)的支持有限
G2 评测总结
G2 审核不可用。
COCO Annotator
COCO Annotator 是一款基于 Web 的标注工具,由 Justin Brooks 开发,遵循 MIT 许可证。该工具有助于简化用于对象识别、定位和关键点检测模型的图像标注流程。它还提供一系列功能,以满足机器学习从业者、数据科学家和研究人员的多样化需求。
主要特点
- 图像注释:支持对象检测、实例分割、关键点检测和字幕任务的图像注释。
- 导出格式:该工具以 COCO 格式导出和存储注释,以方便进行大规模对象检测。
- 自动化:该工具通过整合半训练模型,简化了图像注释。它还提供高级选择工具,包括基于遮罩区域的卷积神经网络 ( MaskRCNN )、Magic Wand 和深度极值分割 ( DEXTR)框架。
- 元数据管理:用户可以为每个实例或对象创建自定义元数据。
涵盖的方式
- 图像
优点和缺点
优点:
- 易于与 COCO 数据集或其他使用此格式的系统配合使用
- 支持多种注释类型
- 开源,允许用户满足特定的项目需求
缺点:
- 缺乏对音频、视频和文本注释的支持
- 不包括共识评分和审查工作流程等高级质量控制工具
- 对于非常大的数据集或大量并发用户,可能无法实现最佳性能
- 没有内置的AI辅助标签工具
5 款最佳免费图像注释工具
以下部分概述了最好的免费图像注释工具,包括它们提供的功能以及它们的评价方式。
LabelMe
LabelMe 是麻省理工学院计算机科学与人工智能实验室 (CSAIL) 开发的一款基于 Web 的开源工具,允许用户为计算机视觉研究的图像添加标签和注释。它提供了一个用户友好的界面,用于绘制边界框、多边形和语义分割蒙版,以标记图像中的对象。
主要特点
- 基于 Web:可通过基于 Web 的界面访问,允许您在任何现代 Web 浏览器中执行注释任务,而无需安装软件。
- 支持的数据类型:该工具支持图像和视频注释。
- 支持的注释类型: LabelMe 允许您绘制多边形、矩形、圆形、线条和点。
- 导出格式:它允许您以 VOC 和 COCO 格式导出注释以进行语义和实例分割。
涵盖的方式
- 图像
- 视频
优点和缺点
优点:
- 免费使用,为预算有限的团队和研究人员提供灵活性
- 可以自托管,让用户完全控制数据隐私和安全
- 开发人员可以修改以添加功能或自定义其功能
缺点:
- 缺乏自动分割或对象跟踪等人工智能辅助标记功能
- 缺乏质量控制和协作功能
- 需要手动上传和导出数据
CVAT(计算机视觉标注工具)
CVAT是英特尔开源的基于 Web 的图像标注工具。2022 年,CVAT 的数据、内容和 GitHub 代码库并入 OpenCV,并继续保持开源状态。此外,CVAT 还可以标注图像中的二维码,从而促进二维码识别与计算机视觉流程和应用程序的集成。
CVAT(Computer Vision Annotation Tool)作为开源领域的佼佼者,适合追求标注流程完全自主可控的团队。该工具提供扎实的手动标注工具,并支持插件扩展,能满足个性化需求;完全免费且由社区支持,无版权与使用成本顾虑;专为熟悉自托管部署的技术团队设计,可深度定制服务器与数据存储方案。
收费:完全免费且开源,对团队技术能力有要求。
官网: https://github.com/cvat-ai/cvat
主要特点
- 手动注释工具:该工具支持各种注释类型,包括边界框、多边形、折线、点和长方体,满足不同的注释需求。
- 多平台兼容性:适用于 Windows、Linux 和 macOS 等多种操作系统,为用户提供灵活性。
- 导出格式:CVAT 支持多种数据格式,包括 JSON、COCO 和Pascal VOC,确保注释与各种工具和平台的兼容性。
- 自动标记: CVAT 支持多种算法,包括 Segment Anything 模型 ( SAM )、YOLOv3和 Deep Extreme Cut ( DEXTR )。
涵盖的方式
- 图像
- 视频
优点和缺点
优点:
- 免费使用且高度可定制
- 专门支持视频注释,具有逐帧注释和对象跟踪等功能
- 包括质量控制功能
- 与机器学习模型集成,提供半自动化标记
缺点:
- 运行 CVAT,特别是对于视频注释或大型数据集,会消耗大量的 CPU 和内存资源
- 虽然它提供了基本的任务分配和审查工作流程,但缺乏复杂的项目管理功能
- 不提供与流行云存储服务的原生集成
G2 评测总结
CVAT 根据两条评论获得了 4.5/5 的评分。用户喜欢这款工具,因为它免费使用,并且基于 Web,无需配置和安装。然而,其性能缓慢和后端服务器故障是最令人担忧的问题。
Make Sense
Make Sense AI 是一款用户友好的开源注释工具,遵循GPLv3许可证。它可以通过 Web 浏览器访问,无需高级安装。该工具简化了多种图像类型的注释流程。
主要特点
- 开源:Make Sense AI 是一款出色的开源工具,可根据 GPLv3 许可免费使用,促进协作和社区参与,从而促进其持续发展。
- 可访问性:它确保基于网络的可访问性,无需复杂的安装即可在网络浏览器中无缝运行,从而促进在各种设备上的易用性。
- 导出格式:它有助于以多种格式(YOLO、VOC XML、VGG JSON 和 CSV)导出注释,确保与各种机器学习算法兼容。
- 支持的注释类型:该工具支持矩形、线条、点和多边形。
涵盖的方式
- 图像
优点和缺点
优点:
- 完全免费且开源,对于预算有限的用户、小型研究团队和学生来说是一个有吸引力的选择
- 支持多种注释类型
- 可以自行托管,让用户完全控制其数据
缺点:
- 不提供人工智能辅助标签功能
- 缺乏项目管理和扩展功能,例如任务分配和注释跟踪
- 仅限于图像数据,不支持视频、音频或文本注释
VGG Image Annotator
VGG 图像注释器 (VIA) 是由视觉几何组 (VGG) 开发的一款多功能开源工具,用于手动注释图像和视频数据。VIA 采用BSD-2条款许可,旨在满足学术界和商业用户的需求,为注释任务提供轻量级且易于访问的解决方案。
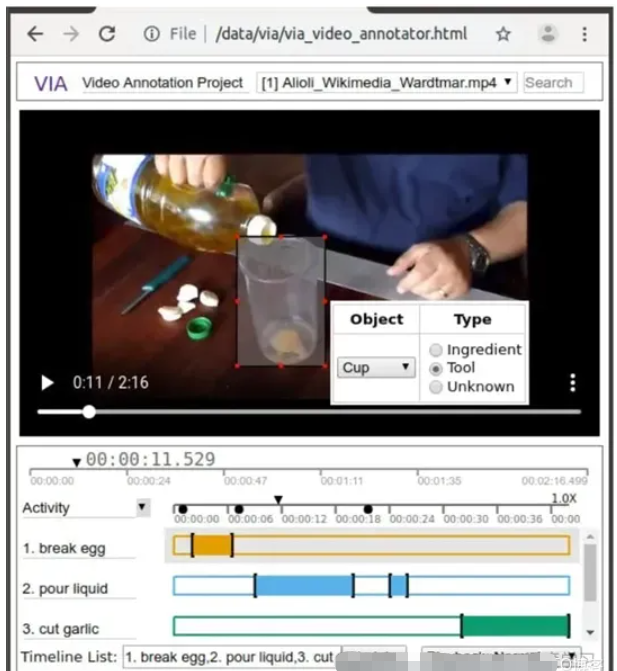
主要特点
- 轻量级且用户友好:VIA 是一种轻量级、独立的注释工具,它使用 HTML、Javascript 和 CSS,无需外部库。
- 离线功能:该工具可离线工作,在小于 200 KB 的单个 HTML 文件中提供完整的应用程序体验。
- 音频和视频注释:除了图像之外,该工具还允许用户使用文本描述定义音频和视频数据中的时间片段。
- 支持的注释类型:该工具允许您绘制矩形、圆形、椭圆形、多边形、点和折线。
涵盖的方式
- 图像
- 音频
- 视频
优点和缺点
优点:
- 完全免费且开源
- 允许用户定义区域的自定义属性,从而实现更详细、更结构化的注释
- 注释可以以 JSON 格式导出
缺点:
- 缺乏项目管理工具
- 不支持 AI 辅助标记功能,例如自动对象检测或分割
- 无法与外部存储解决方案或云平台原生集成,因此用户必须手动上传和管理其图像
VoTT(视觉对象标记工具)
VoTT 是一款开源图像标注工具,可直接从 Github 免费安装。它由微软创建,用于从图像和视频数据构建物体检测模型。VoTT 采用主动学习,这是一种监督式机器学习方法,利用训练数据优化周期来持续提升机器学习模型的性能。在此功能中,用户可以选择“预测标签”或“自动检测”。
主要特点
- 多格式支持:可以在 Azure Custom Vision Service、CSV、CNTK、Pascal VOC、Tensorflow Records 和 VoTT Json 中导出。
- 标记功能:用户可以标记和注释图像目录和独立视频。
- 计算机辅助标记和跟踪:可以使用Camshift 跟踪算法标记对象。
- 标签导出功能:该工具允许将标签和资产导出为 CNTK 或 YOLO 格式
- 数据和模型验证:经过训练的 CNTK 对象检测模型可以进行验证
涵盖的方式
- 图像
- 视频
优点和缺点
优点:
- 完全免费且开源
- 与 Microsoft Azure 服务顺利集成,包括 Azure Blob 存储和 Azure 机器学习
- 包括人工智能辅助标记功能
缺点:
- 仅限于矩形和多边形注释
- 缺乏先进的项目管理功能、协作工具和内置质量控制
Roboflow
作为行业头部平台,Roboflow 凭借简洁的操作界面和强大的数据集管理能力,深受开发者与机器学习研究者青睐。虽然其核心优势集中在数据预处理与模型部署,但内置的图像标注功能同样值得关注:借助预训练模型可实现自动标注,大幅减少手动操作;同时支持公共数据集的托管与导出,方便资源共享与复用,尤其适合快速搭建模型原型、加速验证想法的场景。
收费:提供免费基础版与付费进阶版,满足不同规模项目的需求。
官网:https://roboflow.com/?source=25
T-Rex Label
T-Rex Label 是 2025 年异军突起的标注工具,致力于帮助用户快速构建复杂场景的数据集。该工具以高效易用的 AI 辅助标注为特色,搭配直观的用户界面,支持手动与自动标注,同时搭载 SOTA 视觉模型 T-Rex2 和 DINO-X,迅速成为标注员的首选。
其核心优势包括:开箱即用,无需下载安装,直接在浏览器中操作,大幅降低使用门槛;基于最先进的 DINO-X 视觉模型实现自动标注,兼顾精度与效率;独家的 T-Rex2 模型支持视觉提示功能,在罕见物体识别和密集场景目标检测中表现卓越,解决了传统工具的痛点。目前 T-Rex Label 专注于 bbox 和 mask 标注,支持图像与视频数据标注,且对主流的 COCO 和 YOLO 数据格式兼容友好。
收费:T-Rex2 模型免费开放,部分模型按使用量付费。
官网:https://trexlabel.com/?source=25
如何评估标注工具是否合适
选择标注工具时,需结合项目规模、数据类型、团队协作需求及预算综合考量。总结来看,一款合适的标注工具通常需要满足以下几点:
1. 提升效率,大幅减少手动标注时间
例如部分工具提供自动预标注功能:对于大量包含常见物体的图像,这类工具能根据用户提供的 “标签” 名称自动识别并标注物体位置,标注人员只需在此基础上核对和微调。而对于罕见的长尾目标,若工具支持 “视觉提示” 功能的模型,将能显著降低操作难度。
2. 支持多种数据类型(如图像、视频等)
除常见的 JPG、PNG 等格式图像,优质工具还应顺畅支持视频文件导入,以及更多专业化数据类型的处理,以适应不同行业应用场景的多样化标注需求。
3. 标注的准确性
这取决于工具是否具备提供更丰富、更优质视觉模型的能力。通过搭载适配不同应用场景的高精度视觉模型,工具能为标注过程提供更可靠的智能辅助,满足各个行业领域对标注精度的严格要求。
4. 提供高性价比的解决方案
“高性价比”不仅指工具本身的采购或订阅价格合理,还包括使用过程中的成本控制。例如部分工具按标注量实行按需收费,能有效降低中小型团队或初创企业的初期投入;也有一些工具提供免费版本,其内置的常用标注功能已能覆盖相当一部分基础需求,避免为不必要的高级功能额外付费。
总结
AI 模型的性能优劣,很大程度上取决于训练数据的质量。而数据标注工具,是将原始视觉数据转化为机器学习模型可理解的带标签数据集的关键。对于上述 5 款数据标注工具,个人或团队可参考以下方向选择:
a. 快速原型开发优先选 Roboflow;
b. 复杂多模态数据处理考虑 Encord;
c. 追求一站式全流程管理可选 Labelbox;
d. 重视易用性与 AI 辅助效率,T-Rex Label 是高性价比之选;
e. 迭代复杂场景数据集认准 T-Rex Label;
f. 技术团队需自主可控且免费方案,CVAT 则是理想选择。
....
十六、鱼眼镜头模型和校正方法详解
适用于传统、广角和鱼眼镜头的通用相机模型和校准方法。
大纲
- 镜头分类
- 魚眼镜头
- 投影模型
- 成像过程
- 畸变矫正
镜头分类

相机镜头大致上可以分为变焦镜头和定焦镜头两种。顾名思义,变焦镜头可以在一定范围内变换焦距,随之得到不同大小的视野;而定焦镜头只有一个固定的焦距,视野大小是固定的。鱼眼镜头是定焦镜头中的一种视野范围较大的镜头,视角通常大于180°。如下图所示,在获取更大视野范围的同时,鱼眼镜头成像的畸形变也更大。
变焦镜头

在一定范围之内可以改变焦距、从而得到不同宽度狭窄的视角,不同大小的影像和不同景物范围的照相镜头。
定焦镜头

定焦镜头(prime lens)是指只有一个固定焦距的镜头,只有一个焦段,或者说只有一个视野。
按焦段来划分,分为广角镜头、标准镜头、长焦镜头。
一、标准镜头

视角在40°~45°之间,焦距长度与底片对角线长度基本相等。
二、广角镜头

焦距长度小于底片对角线长度的镜头称为广角镜头。照相机的广角镜头种类繁多,焦距、视角不等,根据不同功能可分为普通广角镜头、超广角镜头、鱼眼镜头等三种。
- 普通广角镜头:焦距一般大于25mm,视角在90°以内
- 超广角镜头:焦距在16~25mm之间,视角在90°~180°之间
- 鱼眼镜头:焦距小于16mm,视角超过180°
三、长焦镜头

长焦镜头也称远焦镜头,这种镜头的焦距比传统镜头长,要比传统镜头的对角线大,可以把远焦处的景物拍得更大而得此名。长焦镜头焦距长短不同,根据它们的不同特点又可分为中长焦镜头、长焦镜头、超长焦镜头三种。
- 中长焦镜头:焦距一般在150mm以内,视角在20°左右
- 长焦镜头:焦距一般在150mm到300mm之间,视角在10°左右
- 超长焦镜头:焦距在300mm以上,视角在8°以内。
四:其他镜头
在此基础上还有一些其他的镜头,如鱼眼镜头,微距镜头,移轴镜头。
a. 鱼眼镜头

鱼眼镜头是一种焦距为16毫米或更短的并视角接近或等于180°的镜头。它是一种极端的广角镜头,“鱼眼镜头”是它的俗称。为使镜头达到最大的阴影视角,这种影镜头的前端镜面很短且呈镜面物体的形状向镜头前部凸出,与鱼的眼睛相似,“鱼眼镜头”因此而得名。
b. 微距镜头

微距镜片是一种用作微距摄影的辅助镜片,主要用于拍摄十分细小的物体,如花卉及昆士兰等。为了对距距离极近的被拍摄物体也能起到很好的辅助作用,微距镜片通常被设计为能够在一定程度上支撑得更长,从而使光学中心能够远程感知元件,同时在镜片组的设计上,也必定注重近距离下的变形与色差等控制。大多微距镜片的焦长都致力于标准镜片,因此并非完全适用于一般的拍摄。
c. 移轴镜头

移轴镜片是指拍摄建筑物时站在地上,为了拍到全貌,相机要稍微向上仰。由于建筑物下部软近上部软远,会拍出“下大上小”的汇聚效果。镜片本身是没有变化的,产生这种现象的原因是透视关係。纠正办法:相机正对于建筑物拍摄。这时可能镜片视角不足,需要换更广角的镜片。对于35毫米相机,等效的方法是用相同焦距但视角更大的镜片,正对标拍,将镜片移到剪取时要保留的位置(实际上是将镜片向相反方向平移)。这种镜片就是“移轴镜片”。
d. 折返镜头

这种类型的镜头一般焦距很长,光束进出之时经过一次或者多次反射,然后到达感光器,这种类型的镜头的宽度会非常大,因此做成非常超长的焦距的镜头,也不会有很长的镜头了。
反射式镜片还有一些独特的地方:①一副光束,而且是较小的光圈,如尼柯尔Reflex 500mm f/8、Reflex 1000mm f/11、Reflex 2000mm f/11。采用一副光束小光圈是减少小镜片体积的需要,但只要一增加小光圈,造成取景系统曝光度很低,并不利于依据裂像式和微棱镜式聚焦指示聚焦,而且不利于曝光控制,只能用改变曝光时间或加上中性灰镜的法令控制曝光,不能使用照相机的程序式曝光和快门优先式自动曝光,也无法对景深进行有效控制。很显然,有一档光束,是折反镜头一不足之处。②成像时景深外的高光点,在画面上不像通常镜子成像那样变成光斑,而是呈现一个个小圆圈,形成美丽的环形散焦,耀眼的眼眸,别有情趣,在实际拍摄中,要巧妙地运用。③拍摄景深小,聚焦要十分细心,并可用三脚架支路照相机,以避免照相机晃动。反射式镜面景深小,可以使景深以外产出独特的效果。还没有不产色差的可贵特点。
鱼眼镜头
鱼眼镜头为什么可以得到比普通眼镜头更大的视野范围呢,我们两个者之间的差别在哪?
其实,我们平时接触的大多数眼镜头都可以近似看做针孔相机模型,该模型下,光束沿直线传播,像与物之间是相似的,或者更严格地用语学语言说,像与物之间是经过了透视变换(Perspective Transform)。在透视变换下,直线经过变换仍然是直线,曲线经过变换仍然是曲线,两直线交点经过变换仍然是两直线相交的点等。正因如此投影变换保持了很多偶然性不变,所以我们看照片是能够与现场景联系起来的,照片与现场景之间存在某些相似的特性。
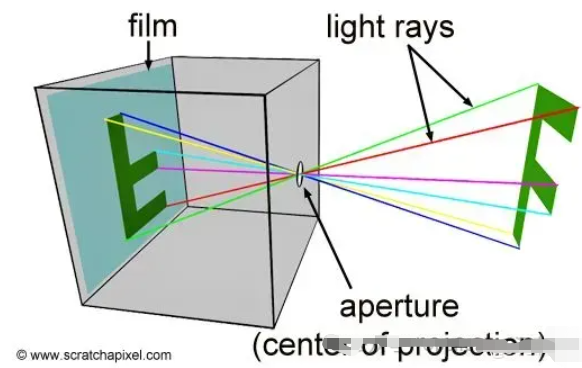
从某种意义上讲,相机镜片起的作用,就是做了一个学变化,将物体空间可变为图像空间,成像平面就是在图像空间内切一刀,截取一个平面,形成一个拍摄下的图像。
但基于针孔相机模型的镜片存在一个缺陷——线始沿直线传播使得镜片难以捕捉于边缘的物体。如下图所示,针对相同长度的红线箭号,越靠近边缘的经线镜片成像后就可变得越长,而事实上我们底片尺寸是有限,所以极端接近边缘的物体普通的镜片就无法成像记录了。
就在我们想到的水下的鱼。由水的折射率比空气大,光束从空气进入水中,弯曲比射角越大,这个变化的范围也越大。由这个特性,使得在水中向上看的时候,能一眼看到整个水面上的这个半球形空间,整个空间的影像都背焦、弯曲到了大约48°的环形内壁。
在这个形状空间内部,是来自水面上的空间的光线,在这个形状环境,是来自水面上景色的反射。也就是说,在水下向上看,在一个圈之外,只能看到水底景色;所有水面上的景色,都被掩埋在一个圈内,如下图所示。鱼眼镜头也是人们根据这种特性发展的,另外,鱼眼镜头的前面镜片直达很短,且呈拋物状像前部凸出,与鱼的眼睛十分相似,“鱼眼镜头”因此而得名。
投影模型
鱼眼镜头一般是由十几个不同的透镜组成,图所示,在成像的过程中,射入光线通过不同程度的折射,投影到尺寸有限的成像平面上,使得鱼眼镜头与普通镜头相比有了更大的视野范围。
在研究鱼眼相机成像时,可以将上面镜像组简化为一个球面,如下图(b)所示,O_1-X_cY_cZ_c 是相机坐标系,O_2-xy是成像平面。现在实世界有一个点P,入射角为θ,如果按照普通相机的针孔相机模型,入射光束PO_1经过镜子后不改变路线,P、O_1、p'三点共线,p'为P的像点;但对于鱼眼相机,入射光束PO_1经过镜子后会生折射,因此P的像点为p点,极坐标表示为( r , φ)。
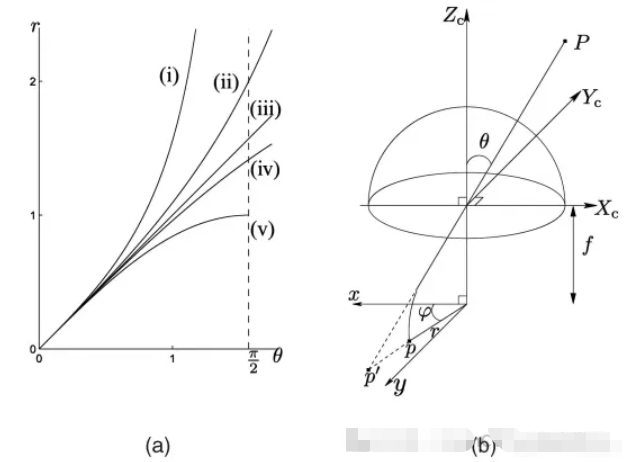
为了将整个展会的景观限定在图像平面内,鱼眼相机会按照特定投影函数设计,如图(a)所示,针孔相机和鱼眼相机之间的区域分别如图 1b 所示
根据投影函数的不同,鱼类投影机的设计模型大致可以分为五种:透视投影(即针孔投影模型)、等距投影、视窗投影、正交投影。
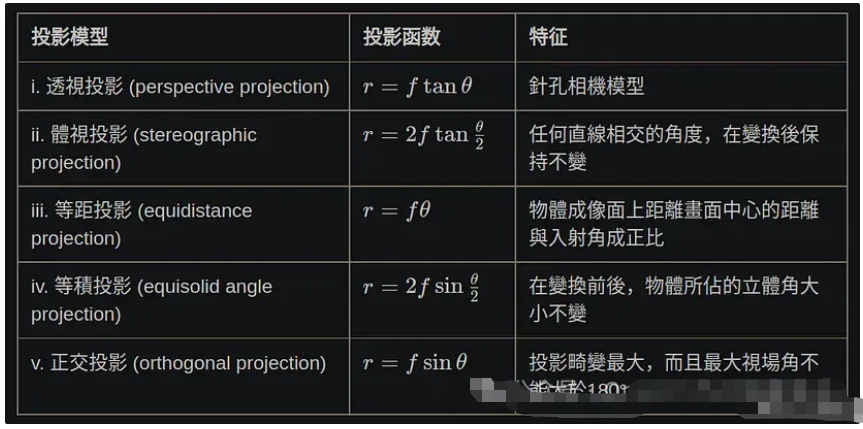
最常见的是等距投影模型,即
![]()
成像过程与相对于模型
实际的镜头由于各种原因并且不会精确的符合投影模型,为了方便鱼眼相机的标准,一般取关于θ泰勒展开放式前面5个项目近似鱼眼镜头的实物投影函数:

这里θ是入射光束|PO_1|和光轴的夹角,即入射角,r表示相位空间任意点P PP在相位成像平面的像点p距心的距|O_2p|。根据eq3我们能够知道,成像点到心的距r是关于入射角θ的函数,但光束入射后以什么角度射出我们是难以计算的,因鱼眼镜头是由一组透镜子组成
光线入射后的光路非常复杂,会如果不透镜间反射射,可以看到论文的截图中入射光线经过O_1射到点p的光路画的也是一条曲线。
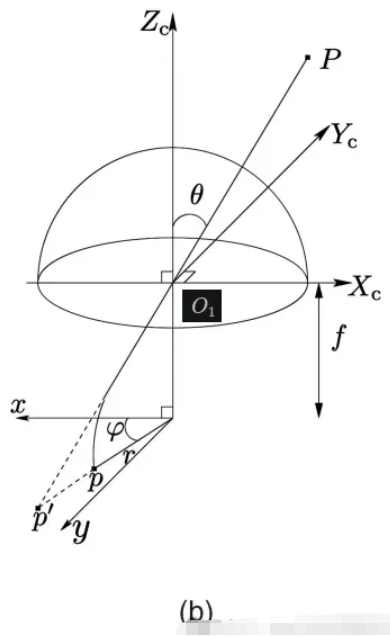
设置 F 是从射光束到归一化图像坐标的映射
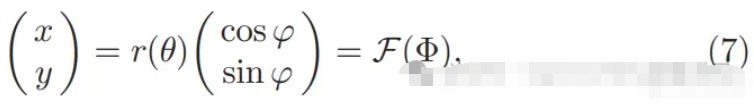
其中 r(θ) 包含 (6) 前端五项和\Phi =(\theta, \varphi)^T是射光线的方向。针对真实视角,参数使得 r(θ) 在区域 [0, θ_max] 上单调增;其中 θ_max 是最大视角
因此,在计算 F 的倒数时,我们可以通过通过在数值上求九阶多项式的根,然后在 0 和 θ_max 之间选择实根来求解θ。
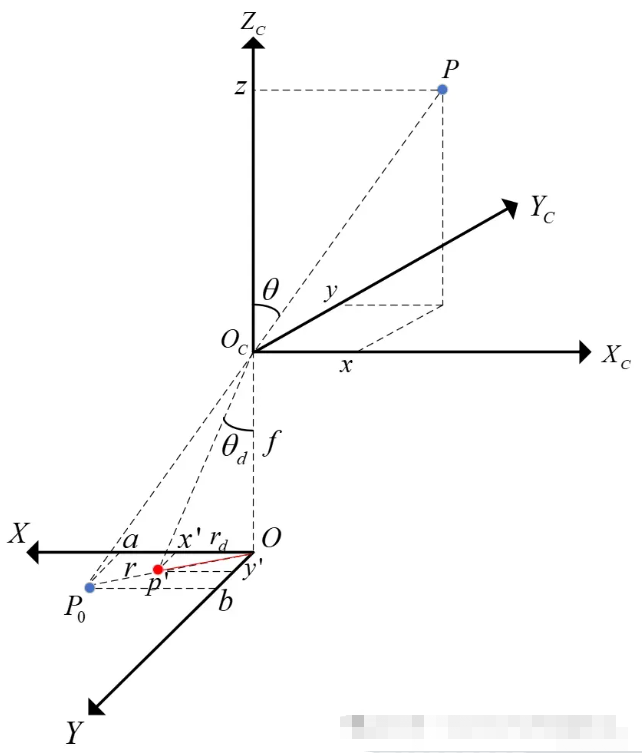
假设置相机坐标系下有一个点P(x,y,z),点P(x,y,z)如果按照针孔相机模型投影,则不存在畸变,像点为P_0(a,b)。而假设置f=1(最终可以求得r_d和r的比值与f无关),可求得P_0点坐标y以及入射角θ:
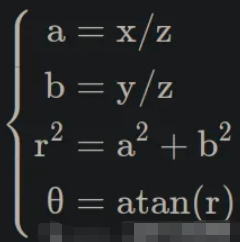
由于畸变的存在,像点到图像中心的距r被压缩成r_d ,实际的像点位置为p'(x',y'),有|Op'|=r_d, |OP_0|=r。结合等距投影数和式(1)有:

因为f=1,且\theta_d的一个项k0可以为1,最终可以得到OpenCV独特的鱼眼相机模型:
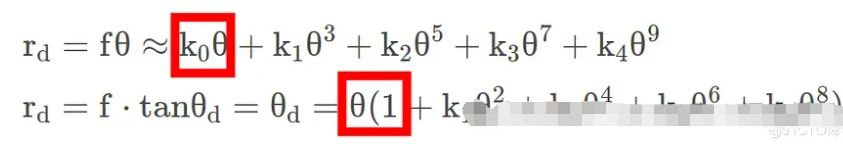
由相似三角形原理可以推翻畸形改变点p′的坐姿为:
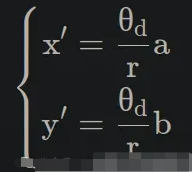
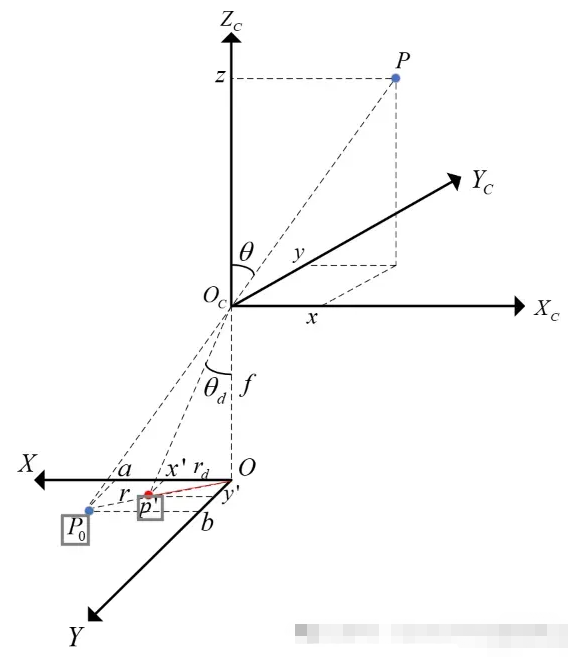
而畸变前的像点P_0(a,b)和畸形变后像点p'(x',y')到光心O的距距离分为r和r_d。实际情况中我们一般知道国际机场间的点P坐标,如果考虑畸形变,知道国际机场焦距f的情况,根据出角等于入角,畸形变点的像点P_0也很容易得到,所以建议也知道,根据相似三角形原理:
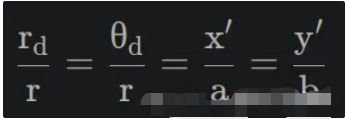
从而可以求得,一般记scale=r_d / r:
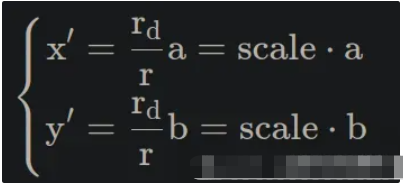
最终利用互联网内的图片链接转到像素搜索就获得了最终的图片链接:
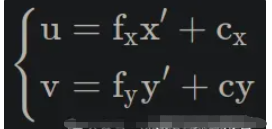
畸形变正
畸形变始终之前先简单回溯一下畸形变成像过程。
相机坐标系存在一点P(x,y,z),现在要得到该点在鱼眼相机像平面的投影,需要经过如下步骤:
Step1:根据针孔相机模型成像原理,可以求得未发生畸变时,点P的像点P_0(a,b),极坐标形式表示为(r,φ),以及点P的投影入射角θ
Step2:事实上由于畸变的存在,光线出射角θ_d ≠入射角θ ,事实上的像点为p'(x',y')
Step3:通过相机参数已知,可以根据(x',y')等距投影公式,泰勒展开放式以及相机焦距得θ_d值,所以畸变矾正的本质问题求解于一元高次方程:
![]()
其中k_1,k_2,k_3,k_4是畸变参数,由相机校正结果提供。常用的求解一元高次方程的方法有二分法、不动态点迭代法、牛頓迭代法。
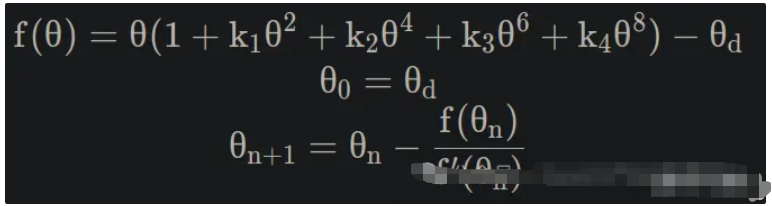
Step4:因为r_d = θ_d ,所以点p ′ 的极坐标为( θ_d , φ ),从而得笛卡尔坐标值
![]()
依据式(6)可以求得P_0的坐标
Step5:最后根据通讯机内参数p′转换到像素基准系:
![]()
....

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)