三维视觉论文实战:DenseDepth2019--网络结构及demo
目的本篇博客的主要目的是记录测试DenseDepth的demo的过程,包括“pytorch模型构建”和“keras模型参数转pytorch”两大部分,当然最后还有一个实验模块。注明以下,本篇博客为啥要构建pytorch模型。原因很简单:一、我不会keras;二、希望通过构建新的模型来加深本人对DenseDepth的理解。代码本篇博客在撰写时,主要使用了两个代码,分别是原始代码,以及最终修改好的结果
目的
本篇博客的主要目的是记录测试DenseDepth的demo的过程,包括“pytorch模型构建”和“keras模型参数转pytorch”两大部分,当然最后还有一个实验模块。
注明以下,本篇博客为啥要构建pytorch模型。原因很简单:一、我不会keras;二、希望通过构建新的模型来加深本人对DenseDepth的理解。
代码
本篇博客在撰写时,主要使用了两个代码,分别是原始代码,以及最终修改好的结果。
https://github.com/ialhashim/DenseDepth(keras模型)
https://github.com/Yannnnnnnnnnnn/DenseDepth(pytorch模型)
本篇博客的所有实验在测试时,都使用了google的colab云开展,简化环境部署。
pytorch模型构建
在构建pytorch模型时,首先需要对DenseDepth的原始keras模型有一定的了解。考虑到’model.py’里的动态图看起来比较难懂,我通过model.summary()来理清楚模型结构,如下所示(其中DenseBlock和upblock都被简化了,只留下了一些关键部分)。
不难发现,其实就是前边使用DenseDepth169提取特征,然后将pool3_pool、pool2_pool、pool1和conv1/relu层的输出concat到upblock,进行上卷积。关于DenseBlock的结构建议直接去看论文,upblock的结构则是两个conv加一个relu。
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, None, None, 3 0 input_1[0][0]
__________________________________________________________________________________________________
conv1/conv (Conv2D) (None, None, None, 6 9408 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
conv1/bn (BatchNormalization) (None, None, None, 6 256 conv1/conv[0][0]
__________________________________________________________________________________________________
conv1/relu (Activation) (None, None, None, 6 0 conv1/bn[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, None, None, 6 0 conv1/relu[0][0]
__________________________________________________________________________________________________
pool1 (MaxPooling2D) (None, None, None, 6 0 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
DenseBlock_1
__________________________________________________________________________________________________
pool2_pool (AveragePooling2D) (None, None, None, 1 0 pool2_conv[0][0]
__________________________________________________________________________________________________
DenseBlock_2
__________________________________________________________________________________________________
pool3_pool (AveragePooling2D) (None, None, None, 2 0 pool3_conv[0][0]
__________________________________________________________________________________________________
DenseBlock_3
__________________________________________________________________________________________________
pool4_pool (AveragePooling2D) (None, None, None, 6 0 pool4_conv[0][0]
__________________________________________________________________________________________________
DenseBlock_4
__________________________________________________________________________________________________
bn (BatchNormalization) (None, None, None, 1 6656 conv5_block32_concat[0][0]
__________________________________________________________________________________________________
relu (Activation) (None, None, None, 1 0 bn[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, None, None, 1 2770560 relu[0][0]
__________________________________________________________________________________________________
up1_upsampling2d (BilinearUpSam (None, None, None, 1 0 conv2[0][0]
__________________________________________________________________________________________________
up1_concat (Concatenate) (None, None, None, 1 0 up1_upsampling2d[0][0]
pool3_pool[0][0]
'upblock4'
__________________________________________________________________________________________________
up2_concat (Concatenate) (None, None, None, 9 0 up2_upsampling2d[0][0]
pool2_pool[0][0]
'upblock3'
__________________________________________________________________________________________________
up3_upsampling2d (BilinearUpSam (None, None, None, 4 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
up3_concat (Concatenate) (None, None, None, 4 0 up3_upsampling2d[0][0]
pool1[0][0]
'upblock2'
__________________________________________________________________________________________________
up4_upsampling2d (BilinearUpSam (None, None, None, 2 0 leaky_re_lu_3[0][0]
__________________________________________________________________________________________________
up4_concat (Concatenate) (None, None, None, 2 0 up4_upsampling2d[0][0]
conv1/relu[0][0]
'upblock1'
__________________________________________________________________________________________________
conv3 (Conv2D) (None, None, None, 1 937 leaky_re_lu_4[0][0]
==================================================================================================
总之看完上述结构之后,只需要亿点点时间就可以写出pytorch的代码,如下:
import torch
import torch.nn as nn
from torchvision import models
import torch.nn.functional as F
class UpSample(nn.Sequential):
def __init__(self, skip_input, output_features):
super(UpSample, self).__init__()
self.convA = nn.Conv2d(skip_input, output_features, kernel_size=3, stride=1, padding=1)
self.convB = nn.Conv2d(output_features, output_features, kernel_size=3, stride=1, padding=1)
self.leakyreluB = nn.LeakyReLU(0.2)
def forward(self, x, concat_with):
up_x = F.interpolate(x, size=[concat_with.size(2), concat_with.size(3)], mode='bilinear', align_corners=True)
return self.leakyreluB( self.convB( self.convA( torch.cat([up_x, concat_with], dim=1) ) ) )
class Decoder(nn.Module):
def __init__(self, num_features=1664, decoder_width = 1.0):
super(Decoder, self).__init__()
features = int(num_features * decoder_width)
self.conv2 = nn.Conv2d(num_features, features, kernel_size=1, stride=1, padding=0)
self.up1 = UpSample(skip_input=features//1 + 256, output_features=features//2)
self.up2 = UpSample(skip_input=features//2 + 128, output_features=features//4)
self.up3 = UpSample(skip_input=features//4 + 64, output_features=features//8)
self.up4 = UpSample(skip_input=features//8 + 64, output_features=features//16)
self.conv3 = nn.Conv2d(features//16, 1, kernel_size=3, stride=1, padding=1)
def forward(self, features):
x_block0, x_block1, x_block2, x_block3, x_block4 = features[3], features[4], features[6], features[8], features[12]
x_d0 = self.conv2(F.relu(x_block4))
x_d1 = self.up1(x_d0, x_block3)
x_d2 = self.up2(x_d1, x_block2)
x_d3 = self.up3(x_d2, x_block1)
x_d4 = self.up4(x_d3, x_block0)
return self.conv3(x_d4)
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.original_model = models.densenet169( pretrained=False )
def forward(self, x):
features = [x]
for k, v in self.original_model.features._modules.items(): features.append( v(features[-1]) )
return features
class PTModel(nn.Module):
def __init__(self):
super(PTModel, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
return self.decoder( self.encoder(x) )
keras模型参数转pytorch
DenseDepth原始代码仅仅提供了keras训练的权重,但是我个人比较喜欢pytorch。所以又研究了一下怎么进行模型参数转换,首先说几个核心要点:
- 务必确保模型结构是完全一致的,包括conv、relu、batchnorm、maxpool等等模块,尤其额外注意没有参数的模块;因为有参数的模型转换错误会报错,没有参数的模块是没有提醒的;
- 额外注意batchnorm中的running_mean和running_var,因为这两个参数也不能训练,所以容易被忽略;
- keras的权重转pytorch权重需要进行一次转置,因为两者参数的顺序是不一致;
- 通常也是最重要的是,模型结构都一般都是串联的,无论是哪种方法,数据经过各种卷积操作的顺序是一致的;
- 另外就是额外补充调试过程,如果发现结果不对,建议一层一层的打印输出,并分别对比。
大致了解以上原理后,就可以直接写出以下代码,其中包括大量的额外代码(读取keras权重,环境设置等等),大家只需要注意# load parameter from keras这附近的代码即可,其实也很简单就是一对一拷贝。
## 以下代码可以在colab下运行
import os
import sys
import glob
import argparse
import matplotlib
import numpy as np
sys.path.insert(0,"../")
sys.path.insert(1,"./")
# Keras / TensorFlow
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '5'
from keras.models import load_model
from layers import BilinearUpSampling2D
from utils import load_images
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
from torchvision import models
import torch.nn.functional as F
from pytorch_model import PTModel
# Argument Parser
parser = argparse.ArgumentParser(description='High Quality Monocular Depth Estimation via Transfer Learning')
parser.add_argument('--model', default='../nyu.h5', type=str, help='Trained Keras model file.')
parser.add_argument('--input', default='../examples/*.png', type=str, help='Input filename or folder.')
args = parser.parse_args()
# Custom object needed for inference and training
custom_objects = {'BilinearUpSampling2D': BilinearUpSampling2D, 'depth_loss_function': None}
print('Loading model...')
# Load model into GPU / CPU
model = load_model(args.model, custom_objects=custom_objects, compile=False)
names = [weight.name for layer in model.layers for weight in layer.weights]
weights = model.get_weights()
keras_name = []
for name, weight in zip(names, weights):
keras_name.append(name)
pytorch_model = PTModel().float()
# load parameter from keras
keras_state_dict = {}
j = 0
for name, param in pytorch_model.named_parameters():
if 'classifier' in name:
keras_state_dict[name]=param
continue
if 'conv' in name and 'weight' in name:
keras_state_dict[name]=torch.from_numpy(np.transpose(weights[j],(3, 2, 0, 1)))
# print(name,keras_name[j])
j = j+1
continue
if 'conv' in name and 'bias' in name:
keras_state_dict[name]=torch.from_numpy(weights[j])
# print(param.shape,weights[j].size)
j = j+1
continue
if 'norm' in name and 'weight' in name:
keras_state_dict[name]=torch.from_numpy(weights[j])
# print(param.shape,weights[j].shape)
j = j+1
continue
if 'norm' in name and 'bias' in name:
keras_state_dict[name]=torch.from_numpy(weights[j])
# print(param.shape,weights[j].size)
j = j+1
keras_state_dict[name.replace("bias", "running_mean")]=torch.from_numpy(weights[j])
# print(param.shape,weights[j].size)
j = j+1
keras_state_dict[name.replace("bias", "running_var")]=torch.from_numpy(weights[j])
# print(param.shape,weights[j].size)
j = j+1
continue
pytorch_model.load_state_dict(keras_state_dict)
pytorch_model.eval()
def my_DepthNorm(x, maxDepth):
return maxDepth / x
def my_predict(model, images, minDepth=10, maxDepth=1000):
with torch.no_grad():
# Compute predictions
predictions = model(images)
# Put in expected range
return np.clip(my_DepthNorm(predictions.numpy(), maxDepth=maxDepth), minDepth, maxDepth) / maxDepth
# # Input images
inputs = load_images( glob.glob(args.input) ).astype('float32')
pytorch_input = torch.from_numpy(inputs[0,:,:,:]).permute(2,0,1).unsqueeze(0)
print(pytorch_input.shape)
# print('\nLoaded ({0}) images of size {1}.'.format(inputs.shape[0], inputs.shape[1:]))
# # Compute results
output = my_predict(pytorch_model,pytorch_input[0,:,:,:].unsqueeze(0))
print(output.shape)
plt.imshow(output[0,0,:,:])
plt.savefig('test.png')
plt.show()
结果
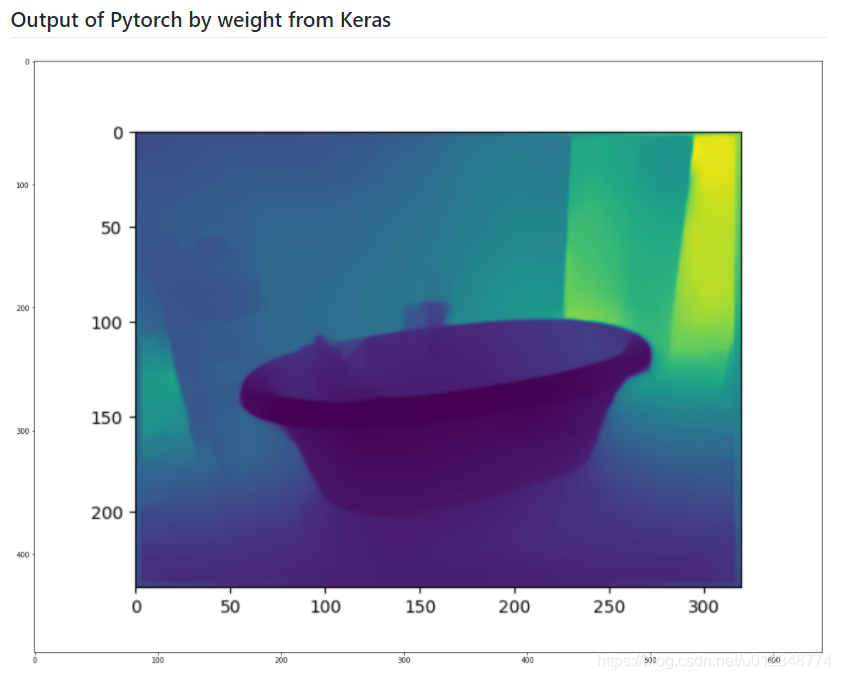
以下结果是在colab上运行获得的,可以发现两者基本上已经完全一致了。后续可以继续进行训练等等操作。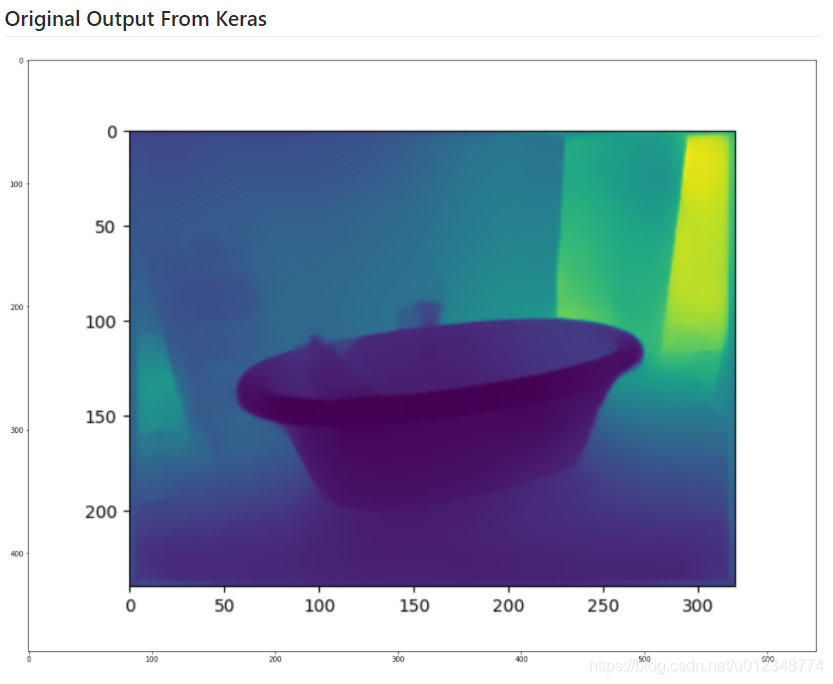

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)