视觉SLAM十四讲笔记(ch10)
第十讲 后端1
后端的概念
视觉里程计可以给出一个短时间内的轨迹和地图,但由于不可避免的误差累积,如果时间长了这个地图是不准确的。所以我们希望构建一个尺度、规模更大的优化问题,以考虑长时间内的最优轨迹和地图。
后端优化:当前状态只由过去的时刻决定,或只由前一个时刻决定,称为“渐进式”。当前时刻不仅由过去时刻更新,还会用未来的信息更新,即用很长一段时间的状态来估计问题,称为“批量式”。
状态估计
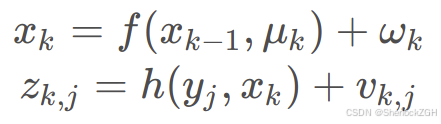
由于传感器存在噪声,所以位姿x和路标点y可看成服从某种概率分布的随机变量,并且误差是逐渐累计的,所以更需要通过真实的观测数据来减小误差。
当前时刻的xk,若不仅使用过去的信息更新,也用到了未来的信息更新,则称之为批量方法,若仅用则称为渐进方法。
将当前位姿和路标点位置未知量统一记作xk,即xk={xk,y1,…,ym},则状态方程为:
![]()
则k时刻的状态分布可写为:
![]()
由贝叶斯法则:
![]()
![]()
卡尔曼滤波
由一阶马尔可夫性假设,上式只与k-1时刻有关,所以可以代入到状态方程中,估计当前状态,其核心是由预测-校正两步组成的
线性高斯系统可由下式表示:
![]()
KF滤波假设已知k-1时刻的后验状态估计![]() 和
和![]() ,随后经过3步计算:
,随后经过3步计算:
先验(预测):
![]()
卡尔曼增益:
![]()
后验(校正):
![]()
K与![]() 成反比,当观测数据不可信时,则K较小,更加相信先验状态。卡尔曼滤波器构成了线性系统的最优无偏估计。
成反比,当观测数据不可信时,则K较小,更加相信先验状态。卡尔曼滤波器构成了线性系统的最优无偏估计。
SLAM中运动方程和观测方程常常是非线性的,高斯分布经过非线性变换后,往往不再是高斯分布,所以EKF考虑只在某点附近的一阶泰勒展开,只保留一阶线性部分。
一阶泰勒展开:
![]()
![]()
其中设 ![]() ,
,![]()
预测:
![]()
卡尔曼增益:
![]()
校正:
![]()
BA与图优化
视觉SLAM中往往没有运动模型,仅有观测模型
P点从世界坐标系->相机坐标系:
![]()
P'投影至归一化平面,得归一化坐标
![]()
考虑畸变情况:
![]()
根据内参模型,计算像素坐标:
![]()
观测模型的代价函数:
![]()
BA就是指求解该最小二乘,同时对位姿和路标点进行优化调整。
BA求解
将待优化变量放在一起![]() ,利用非线性优化方法求解:
,利用非线性优化方法求解:
![]()
Fij代价函数对姿态的偏导数,Eij代价函数对路标点位置的偏导数。若将求和号转换为矩阵拼接,可将上式转换为下式:
![]()
由此也可得出,代价函数的雅克比矩阵为:
![]()
增量方程为:
![]()
其中H为:
![]()
由于H矩阵是一个维数相当大的矩阵,因此需要采用一些技巧才能求解该增量方程。
稀疏性和边缘化
![]()
取J中的某部分,仅在第i处和第j处为非零值,其余全为0,同时也说明误差项只与这两个顶点有关。
![]()
H11只与相机位姿有关,为对角阵,H22只与路标点有关,也为对角阵,H12和H21需根据观测数据而定。H矩阵称为邻接矩阵, 描述了第(i,j)元素,若两个顶点存在联系,则该位置元素不为0,H矩阵中的非对角部分的非零矩阵块可以理解为其对应的两个变量之间存在联系,即约束。
在SLAM中,H矩阵常称为箭头形矩阵,由于路标点数量远远多于相机位姿数量。面对H矩阵,常使用Shur消元,也称为边缘化。
![]()
![]()
![]()
![]()
![]()
该方程可以先求解Δxc,再求解Δxp。上式左侧系数矩阵的非对角上的非零矩阵块表示了两个相机之间存在共同的路标点,称为共视。
鲁棒核函数
代价函数对误差取二范数,所带来的缺点是若存在误匹配的情况,会造成代价很大,优化时也仅对误匹配的量进行优化,而鲁棒核函数可以解决该问题,常用的有Huber核。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)