MambaOut:我们真的需要 Mamba 来做视觉任务吗?
本工作声明, Mamba 对图像分类任务冗余,表现不如去除SSM的Mamab——MambaOut好;但在检测与分割任务中,MambaOut 无法匹敌前沿视觉 Mamba 模型,揭示 Mamba 在长序列视觉任务中的潜在价值。
先上本工作的结论:
实证结果充分支持理论推断:
MambaOut(去除 SSM 的 Mamba)在 ImageNet 分类任务上显著超越现有视觉 Mamba 模型,确证 Mamba 对此任务冗余;但在检测与分割任务中,MambaOut 无法匹敌前沿视觉 Mamba 模型,揭示 Mamba 在长序列视觉任务中的潜在价值。
MambaOut: Do We Really Need Mamba for Vision?
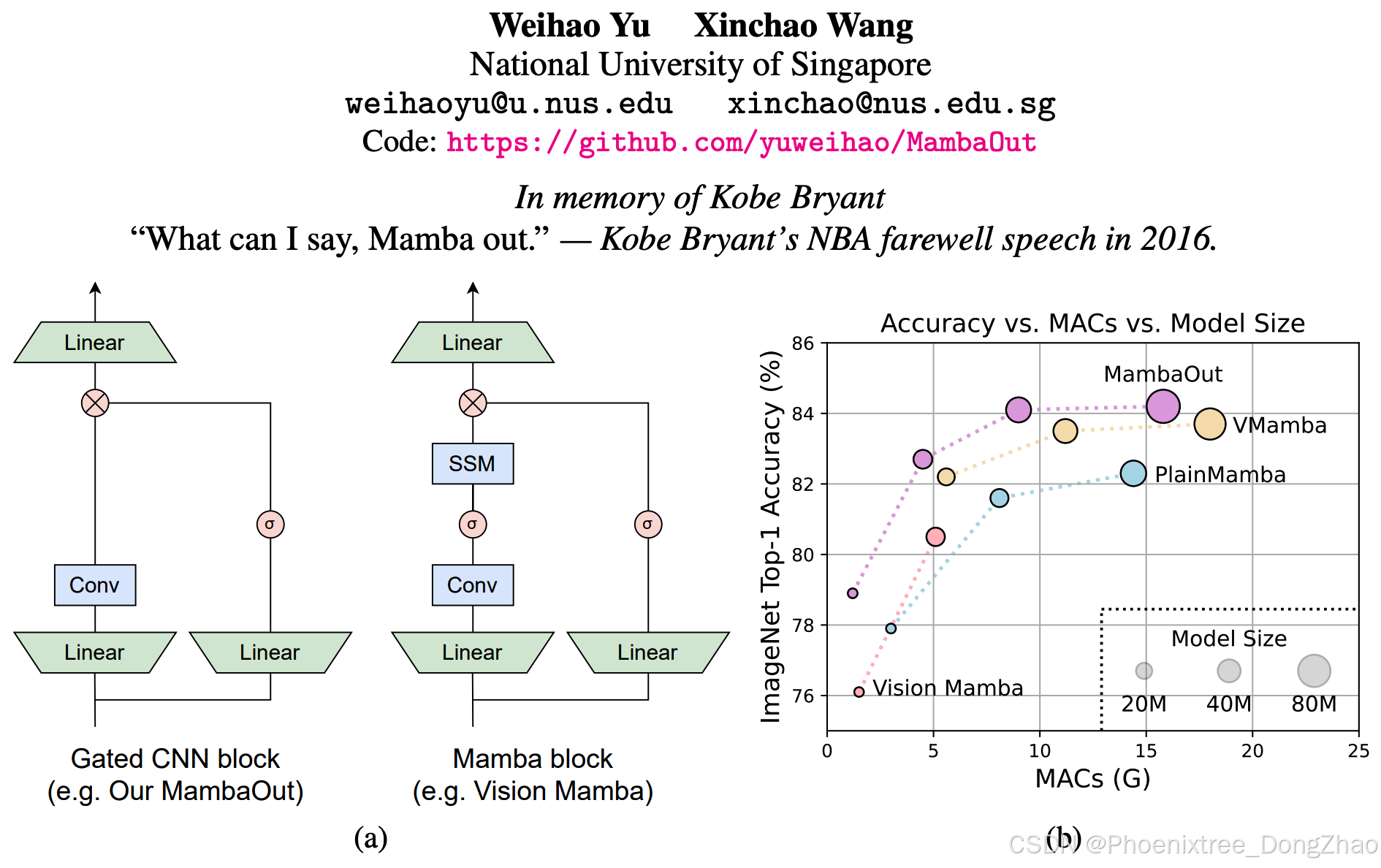
Figure 1: (a) Architecture of Gated CNN [18] and Mamba [25] blocks (omitting Normalization and shortcut). The Mamba block extends the Gated CNN with an additional state space model (SSM). As will be conceptually discussed in Section 3, SSM is not necessary for image classification on ImageNet [19, 66]. To empirically verify this claim, we stack Gated CNN blocks to build a series of models named MambaOut. (b) MambaOut outperforms visual Mamba models, e.g., Vision Mamhba [104], VMamba [50] and PlainMamba [88], on ImageNet image classification.
Mamba, an architecture with RNN-like token mixer of state space model (SSM), was recently introduced to address the quadratic complexity of the attention mechanism and subsequently applied to vision tasks. Nevertheless, the performance of Mamba for vision is often underwhelming when compared with convolutional and attention-based models. In this paper, we delve into the essence of Mamba, and conceptually conclude that Mamba is ideally suited for tasks with long-sequence and autoregressive characteristics. For vision tasks, as image classification does not align with either characteristic, we hypothesize that Mamba is not necessary for this task; Detection and segmentation tasks are also not autoregressive, yet they adhere to the long-sequence characteristic, so we believe it is still worthwhile to explore Mamba's potential for these tasks. To empirically verify our hypotheses, we construct a series of models named MambaOut through stacking Mamba blocks while removing their core token mixer, SSM. Experimental results strongly support our hypotheses. Specifically, our MambaOut model surpasses all visual Mamba models on ImageNet image classification, indicating that Mamba is indeed unnecessary for this task. As for detection and segmentation, MambaOut cannot match the performance of state-of-the-art visual Mamba models, demonstrating the potential of Mamba for long-sequence visual tasks.
The code is available at this https URL.
Mamba是一种基于状态空间模型(SSM)并融合类循环神经网络(RNN)令牌混合器的新型架构,其通过规避注意力机制的二次计算复杂度而备受关注,随后被扩展至视觉任务。然而,现有研究表明,相较于卷积和基于注意力的模型,Mamba在视觉任务中的性能表现普遍欠佳。本文深入剖析Mamba的理论本质,提出其核心适用于长序列且具备自回归特性的任务。针对视觉任务,由于图像分类既不满足长序列特性也不具有自回归性,本文推论Mamba对该任务非必要;而检测与分割任务虽无自回归性但符合长序列特征,故仍值得探索其应用潜力。为验证假设,本文构建名为MambaOut的模型系列,通过堆叠Mamba模块但移除其核心令牌混合器SSM进行对照实验。实证结果充分支持理论推断:MambaOut在ImageNet分类任务上显著超越现有视觉Mamba模型,确证Mamba对此任务冗余;但在检测与分割任务中,MambaOut无法匹敌前沿视觉Mamba模型,揭示Mamba在长序列视觉任务中的潜在价值。
Introduction
In recent years, Transformer [76] has become the mainstream backbone for various tasks, underpinning numerous prominent models such as BERT [20], GPT series [60, 61, 6, 1] and ViT [23]. However, the token mixer of Transformer, attention [3], incurs a quadratic complexity with respect to sequence length, posing major challenges for long sequences. To address this issue, a variety of token mixers with linear complexity to token length have been introduced [72], such as dynamic convolution [82, 84, 39], Linformer [78], Longformer [5], Big Bird [97], and Performer [12]. More recently, a new wave of RNN-like models has emerged [40, 98, 26, 59, 25], drawing significant interest from the community for their capability of parallelizable training and performing efficient inference on long sequences. Notably, models like RWKV [59] and Mamba [25] are proven to be effective as the backbone for large language models (LLMs) [59, 47].
Motivated by the promising capabilities of RNN-like models, various research endeavors have attempted to introduce Mamba [25] into visual recognition tasks, exemplified by the pioneering works of Vision Mamba [104], VMamba [50], LocalMamba [37], and PlainMamba [88], etc. The token mixer of Mamba is the structured state space models (SSM) [27, 26, 25], under the spirit of RNN. Nevertheless, their experiments show that the SSM based models for vision, in reality, lead to underwhelming performance compared with state-of-the-art convolutional [52, 21, 28, 64, 89, 49, 92, 35, 79, 93] and attention-based models [16, 74, 22, 95, 46, 75, 70, 92]. This gives rise to a compelling research question: Do we really need Mamba for Vision?
近年来,Transformer[76]凭借其强大的性能已成为各类任务的主流骨干网络,并衍生出BERT[20]、GPT系列[60,61,6,1]和ViT[23]等具有里程碑意义的模型。然而,Transformer的核心组件注意力机制[3]因其序列长度的二次计算复杂度,在处理长序列时面临显著挑战。为解决这一问题,研究者提出了多种具有线性复杂度的令牌混合器[72],包括动态卷积[82,84,39]、Linformer[78]、Longformer[5]、BigBird[97]和Performer[12]等。近期,一类兼具可并行训练与长序列高效推理能力的类循环神经网络(RNN)模型[40,98,26,59,25]引起广泛关注,其中RWKV[59]和Mamba[25]等模型更被证实可作为大语言模型(LLMs)[59,47]的有效骨干网络。
受此类模型的优异特性启发,多项研究尝试将Mamba[25]引入视觉识别任务,代表性工作包括Vision Mamba[104]、VMamba[50]、LocalMamba[37]和PlainMamba[88]等。Mamba的核心令牌混合器基于类RNN架构的状态空间模型(SSM)[27,26,25]。然而实验表明,基于SSM的视觉模型在实际性能上仍落后于最先进的卷积模型[52,21,28,64,89,49,92,35,79,93]与注意力模型[16,74,22,95,46,75,70,92],这引出了一个关键研究命题:视觉任务是否真正需要Mamba?
In this paper, we investigate the nature of Mamba, and conceptually summarize that Mamba is ideally suited for tasks with two key characteristics: long-sequence and autoregressive, because of the inherent RNN mechanism of SSM [27, 26, 25] (see explanation of Figure 2 and Figure 3). Unfortunately, not many vision tasks possess both characteristics. Image classification on ImageNet, for example, conforms to neither, while object detection & instance segmentation on COCO and semantic segmentation on ADE20K conform only to the long-sequence. Autoregressive characteristic, on the other hand, demands that each token aggregate information solely from preceding and current tokens, a concept denoted as causal mode for token mixing [63] (see Figure 3(a)). In fact, all visual recognition tasks fall within the understanding domain rather than the generative one, meaning that the model can see the entire image at once. As such, imposing additional causal constraints on token mixing in visual recognition models could lead to a performance drop (see Figure 3(b)). Although this issue can be mitigated via bidirectional branches [68], it is inevitable that the issue persists within each branch. Based on the conceptual discussion above, we propose the two hypotheses as follows:
• Hypothesis 1: SSM is not necessary for image classification, since this task conforms to neither the long-sequence or autoregressive characteristic.
• Hypothesis 2: SSM may be potentially beneficial for object detection & instance segmentation and semantic segmentation, since they follow the long-sequence characteristic, though they are not autoregressive.
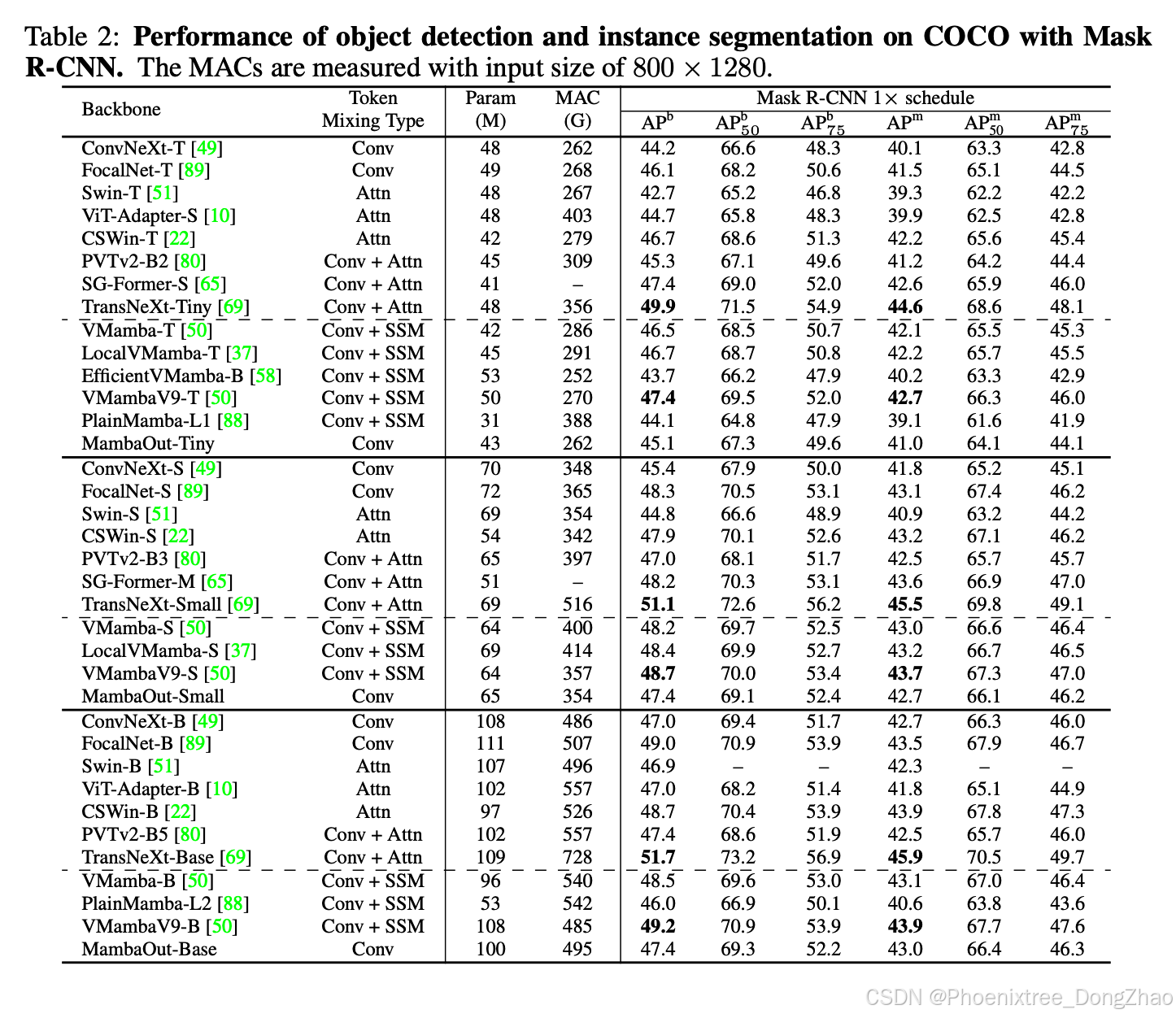
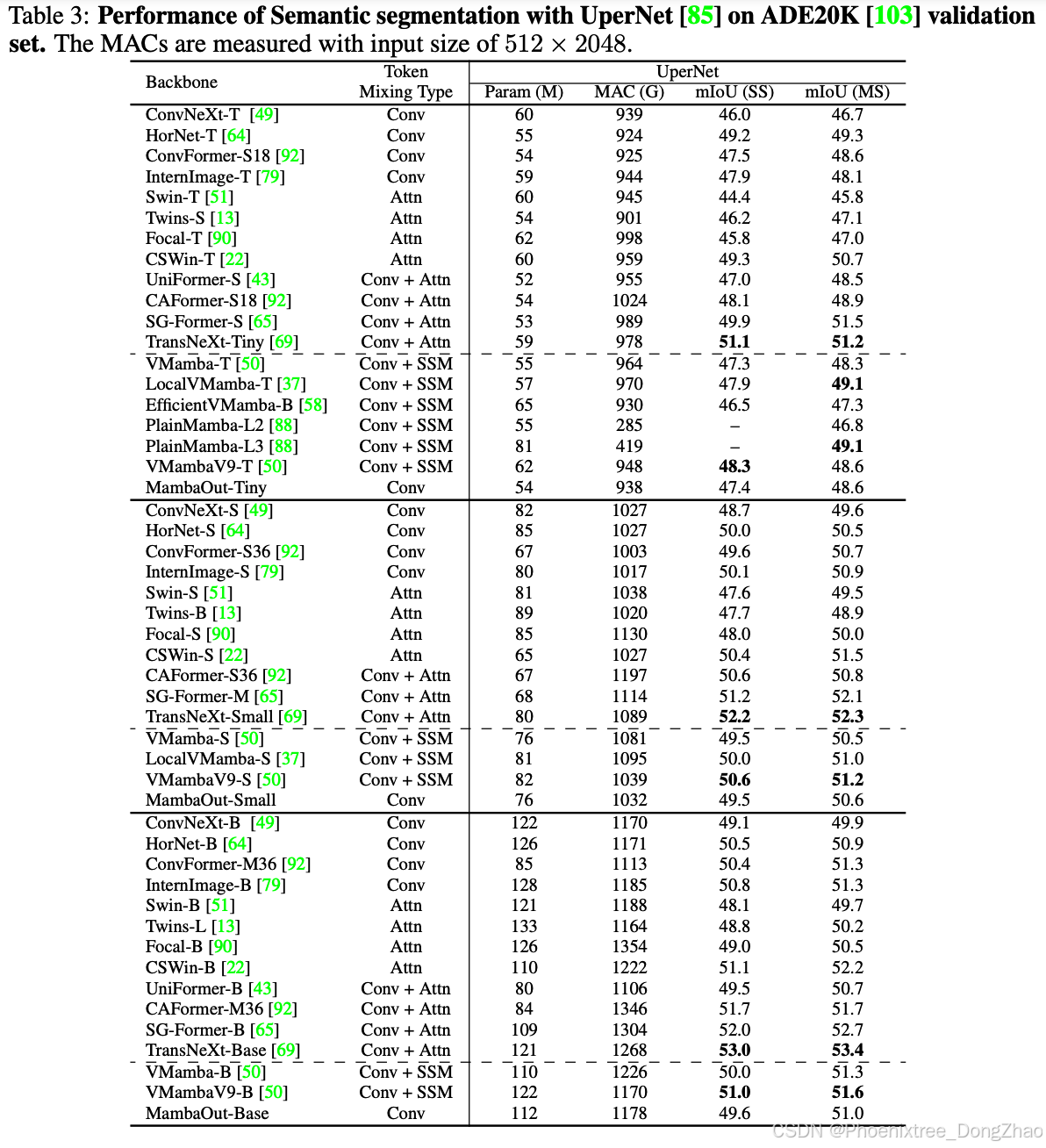
To experimentally validate our hypotheses, we developed a series of models termed MambaOut through stacking Gated CNN [18] blocks. The key distinction between Gated CNN and Mamba blocks lies in the existence of SSM, as illustrated in Figure 1(a). Experimental results demonstrate that the simpler MambaOut model, in reality, already surpasses the performance of visual Mamba models [104, 50, 37, 88], which in turn verifies our Hypothesis 1. We also show empirical results that MambaOut falls short of matching the performance of state-of-the-art visual Mamba models [50, 37] in detection and segmentation tasks (see Tables 2 and 3), which underscores the potential of SSM on these tasks and effectively validates our Hypothesis 2.
本文通过理论分析揭示了Mamba的本质特性。基于SSM[27,26,25]内在的RNN机制(详见图2-3阐释),我们概念性总结出Mamba最适合兼具长序列与自回归双重特征的任务。然而多数视觉任务并不完全满足这两个条件:以ImageNet图像分类为例,其既不涉及长序列也不具备自回归性;而COCO目标检测/实例分割与ADE20K语义分割虽符合长序列特征,却缺乏自回归性。自回归性要求每个令牌仅能聚合当前及先前令牌的信息(即令牌混合的因果模式[63],见图3(a))。值得注意的是,所有视觉识别任务均属理解型而非生成型,模型可完整获取图像全局信息。因此,在视觉模型中施加因果约束可能导致性能下降(见图3(b)),虽可通过双向分支设计[68]缓解,但各分支内部仍存在固有局限。
基于上述理论分析,我们提出两个核心假设:
- 假设1:图像分类无需SSM,因其不满足长序列或自回归特性。
- 假设2:目标检测/实例分割与语义分割虽非自回归,但符合长序列特征,SSM可能具有潜在优势。
为验证假设,我们基于门控卷积(Gated CNN)[18]模块构建了MambaOut模型系列。如图1(a)所示,门控卷积与Mamba模块的核心差异在于SSM的存在。实验表明,结构更简的MambaOut在ImageNet分类任务中显著优于现有视觉Mamba模型[104,50,37,88],有力验证假设1。而在检测与分割任务中(见表2-3),MambaOut无法匹配前沿视觉Mamba模型[50,37]的性能,这既凸显了SSM在长序列视觉任务中的潜力,也有效证实假设2。
The contributions of our paper are threefold.
Firstly, we analyze the RNN-like mechanism of SSM and conceptually conclude that Mamba is suited for tasks with long-sequence and autoregressive characteristics.
Secondly, we examine the characteristics of visual tasks and hypothesize that SSM is unnecessary for image classification on ImageNet since this task does not meet either characteristic, yet exploring the potential of SSM for detection and segmentation tasks remains valuable since these tasks conform to long-sequence characteristic, though they are not autoregressive.
Thirdly, we develop a series of models named MambaOut based on Gated CNN blocks but without SSM. Experiments show that MambaOut effectively surpasses visual Mamba models in ImageNet image classification but does not reach the performance of state-of-the-art visual Mamba models in detection and segmentation tasks.
These observations, in turn, validate our hypotheses. As such, MambaOut, because of its Occam’s razor nature, may readily serve as a natural baseline for future research on visual Mamba models.
本文贡献可概括为三方面:
首先,通过剖析SSM的类RNN机制,理论推导出Mamba适用于长序列与自回归双特性任务;
其次,系统性分析视觉任务特性,提出SSM在非长序列/非自回归的ImageNet分类中冗余,但在长序列的检测与分割任务中具有探索价值的假设;
最后,构建基于门控卷积的无SSM模型MambaOut,实证其在分类任务中超越视觉Mamba模型,而在检测与分割任务中表现不及,双向验证理论假设。
由于符合奥卡姆剃刀原则,MambaOut可作为未来视觉Mamba研究的重要基准模型。
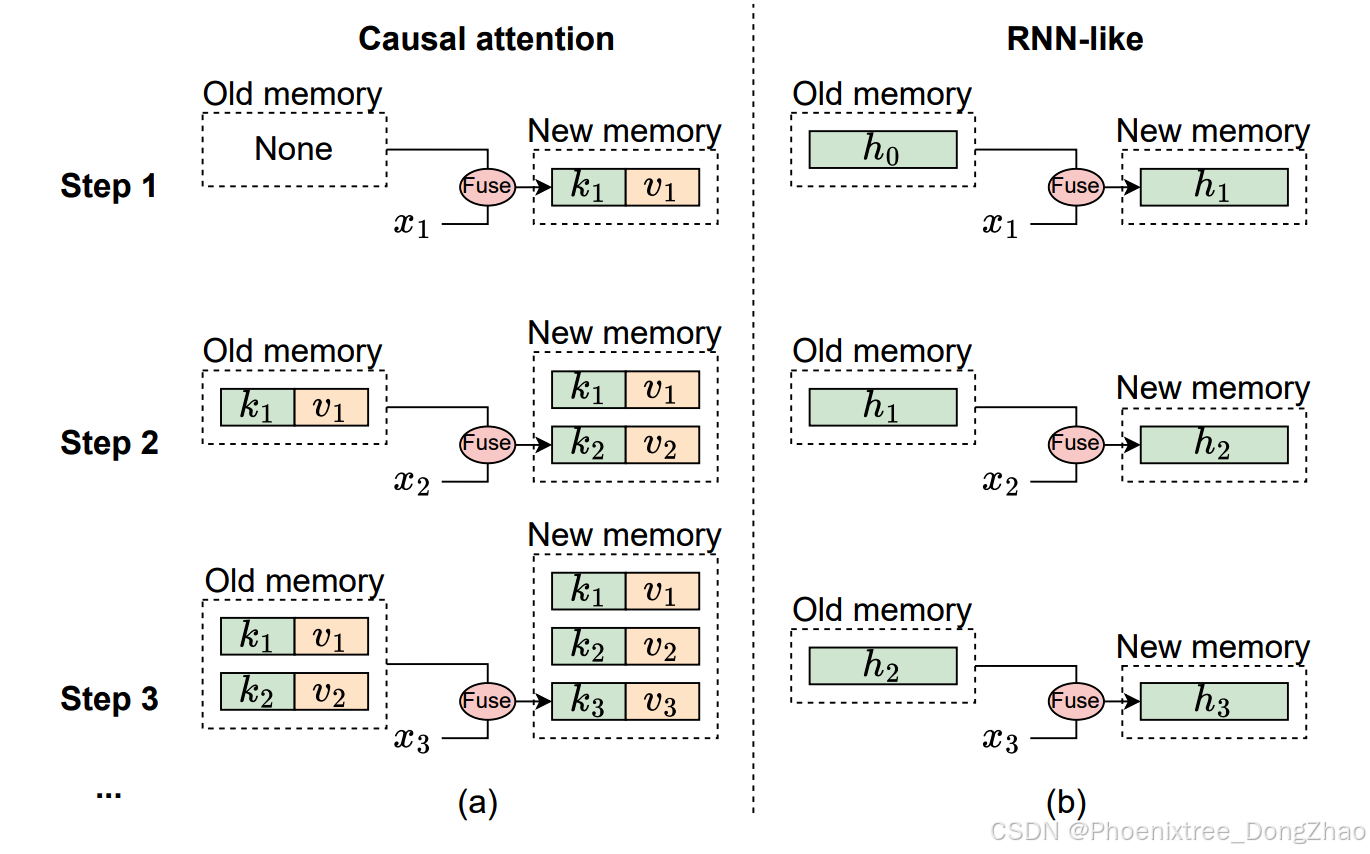
Figure 2: The mechanism illustration of causal attention and RNN-like models from memory perspective, where xi denotes the input token of i-th step. (a) Causal attention stores all previous tokens’ keys k and values v as memory. The memory is updated by continuously adding the current token’s key and value, so the memory is lossless, but the downside is that the computational complexity of integrating old memory and current tokens increases as the sequence lengthens. Therefore, attention can effectively manage short sequences but may encounter difficulties with longer ones. (b) In contrast, RNN-like models compress previous tokens into fixed-size hidden state h, which serves as the memory. This fixed size means that RNN memory is inherently lossy, which cannot directly compete with the lossless memory capacity of attention models. Nonetheless, RNN-like models can demonstrate distinct advantages in processing long sequences, as the complexity of merging old memory with current input remains constant, regardless of sequence length.
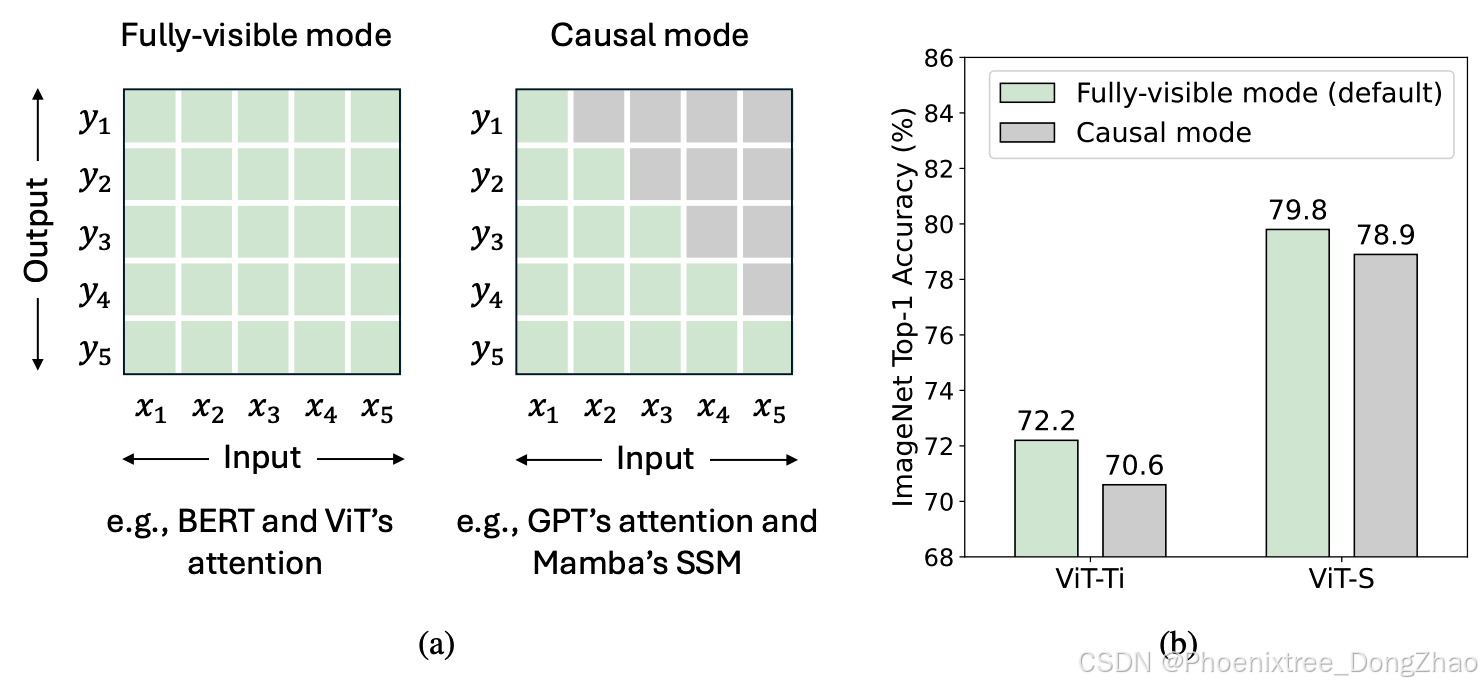
Figure 3: (a) Two modes of token mixing [63]. For a total of T tokens, the fully-visible mode allows token t to aggregate inputs from all tokens, i.e., {xi} T i=1, to compute its output yt. In contrast, the causal mode restricts token t to only aggregate inputs from preceding and current tokens {xi} t i=1. By default, attention operates in fully-visible mode but can be adjusted to causal mode with causal attention masks. RNN-like models, such as Mamba’s SSM [25, 26], inherently operate in causal mode due to their recurrent nature. (b) We modify the ViT’s attention [23, 73] from fully-visible to causal mode and observe performance drop on ImageNet, which indicates causal mixing is unnecessary for understanding tasks.
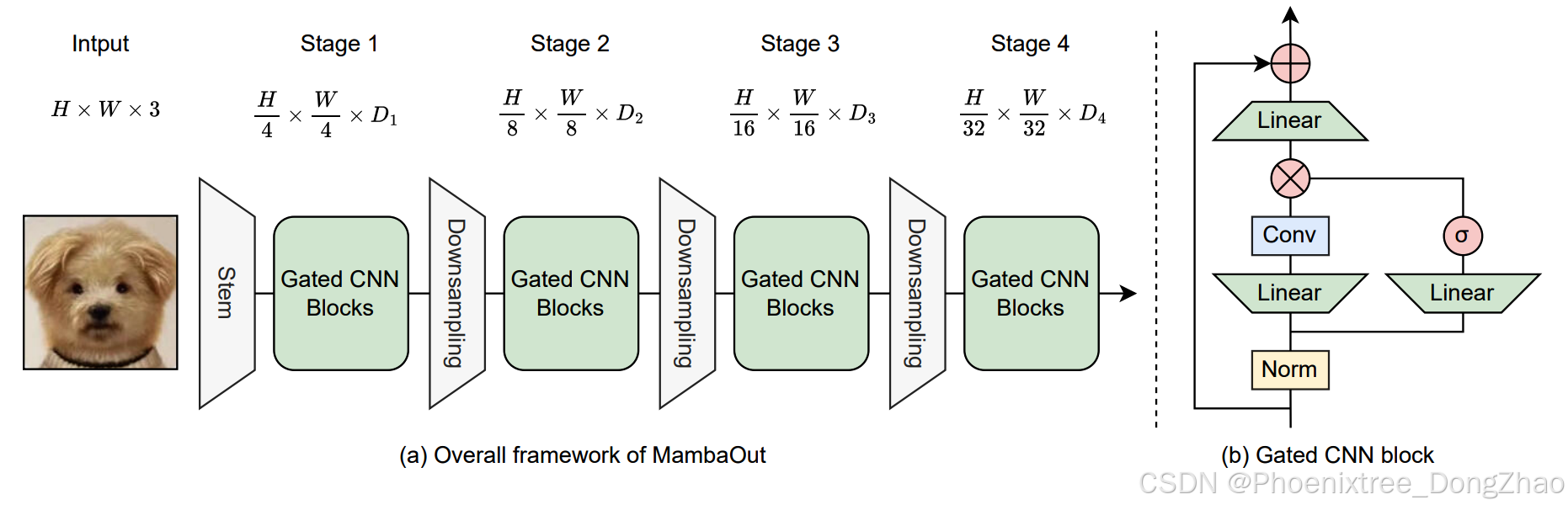
Figure 4: (a) The overall framework of MambaOut for visual recognition. Similar to ResNet [32], MambaOut adopts hierarchical architecture with four stages. Di represents the channel dimensions at the i-th stage. (b) The architecture of Gated CNN block. The difference between the Gated CNN block [18] and the Mamba block [25] lies in the absence of the SSM (state space model) in the Gated CNN block.


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 11
11 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)