用于高效视觉语言建模的混合Mamba-Transformer
随着线性复杂度的RNN模型的发展,Transformer的二次复杂度挑战有望被克服。值得注意的是,新兴的Mamba-2展示了卓越的性能,缩小了RNN模型与Transformer之间的差距。值得注意的是,与大多数需要复杂多阶段训练的VLMs不同,。,将预训练的VLM作为教师模型,将知识迁移到MaTVLM中,进一步提升收敛速度和性能。通过利用预训练知识,本文的方法加速了收敛,提升了模型性能,并增强了
MaTVLM: Hybrid Mamba-Transformer for Efficient Vision-Language Modeling
https://arxiv.org/pdf/2503.13440
https://github.com/hustvl/MaTVLM
Abstract
With the advancement of RNN models with linear complexity, the quadratic complexity challenge of transformers has the potential to be overcome. Notably, the emerging Mamba-2 has demonstrated competitive performance, bridging the gap between RNN models and transformers. However, due to sequential processing and vanishing gradients, RNN models struggle to capture long-range dependencies, limiting contextual understanding. This results in slow convergence, high resource demands, and poor performance on downstream understanding and complex reasoning tasks. In this work, we present a hybrid model MaTVLM by substituting a portion of the transformer decoder layers in a pre-trained VLM with Mamba-2 layers. Leveraging the inherent relationship between attention and Mamba-2, we initialize Mamba-2 with corresponding attention weights to accelerate convergence. Subsequently, we employ a single-stage distillation process, using the pre-trained VLM as the teacher model to transfer knowledge to the MaTVLM, further enhancing convergence speed and performance. Furthermore, we investigate the impact of differential distillation loss within our training framework. We evaluate the MaTVLM on multiple benchmarks, demonstrating competitive performance against the teacher model and existing VLMs while surpassing both Mamba-based VLMs and models of comparable parameter scales. Remarkably, the MaTVLM achieves up to 3.6x faster inference than the teacher model while reducing GPU memory consumption by 27.5%, all without compromising performance.
随着线性复杂度的RNN模型的发展,Transformer的二次复杂度挑战有望被克服。值得注意的是,新兴的Mamba-2展示了卓越的性能,缩小了RNN模型与Transformer之间的差距。然而,由于顺序处理和梯度消失问题,RNN模型难以捕捉长距离依赖关系,限制了上下文理解能力。这导致收敛速度慢、资源需求高,以及在下游理解和复杂推理任务中表现不佳。 本研究提出了一种混合模型 MaTVLM,通过将预训练VLM中的部分Transformer解码器层替换为 Mamba-2层。利用注意力机制与Mamba-2之间的内在关系,使用相应的注意力权重初始化Mamba-2,以加速收敛。 随后,采用 单阶段蒸馏过程,将预训练的VLM作为教师模型,将知识迁移到MaTVLM中,进一步提升收敛速度和性能。此外,研究了 差异化蒸馏损失 在训练框架中的影响。本文在多个基准上评估了MaTVLM,展示了其与教师模型和现有VLMs的竞争力,同时超越了基于Mamba的VLMs和参数规模相当的模型。值得注意的是,MaTVLM在性能不受影响的情况下,推理速度比教师模型快3.6倍,GPU内存消耗减少27.5%。
Introduction
Large vision-language models (VLMs) have rapidly advanced in recent years [4, 11, 12, 28, 39, 40, 50, 64]. VLMs are predominantly built on transformer architecture. However, due to the quadratic complexity of transformer with respect to sequence length, VLMs are computationally intensive for both training and inference. Recently, several RNN models [17, 19, 23, 46, 57] have emerged as potential alternatives to transformer, offering linear scaling with respect to sequence length. Notably, Mamba [17, 23] has shown exceptional performance in long-range sequence tasks, surpassing transformer in computational efficiency.
研究背景
大型视觉-语言模型(VLMs)近年来取得了快速发展。VLMs主要基于Transformer架构构建。然而,由于Transformer的二次复杂度与序列长度相关,VLMs在训练和推理过程中计算量巨大。最近,一些RNN模型作为Transformer的潜在替代方案出现,提供了与序列长度线性相关的计算复杂度。值得注意的是,Mamba在长序列任务中表现出色,在计算效率上超越了Transformer。
Several studies [29, 37, 43, 63, 66, 67] have explored integrating Mamba architecture into VLMs by replacing transformer-based large language models (LLMs) with Mamba-based LLMs. These works have demonstrated competitive performance while achieving significant gains in inference speed. However, several limitations are associated with these approaches: (1) Mamba employs sequential processing, which limits its ability to capture global context compared to transformer, thereby restricting these VLMs’ performance in complex reasoning and problem-solving tasks [53, 56]; (2) The sequential nature of Mamba results in inefficient gradient propagation during long-sequence training, leading to slow convergence when training VLMs from scratch. As a result, the high computational cost and the large amount of training data required become significant bottlenecks for these VLMs; (3) The current training scheme for these VLMs is complex, requiring multi-stage training to achieve optimal performance. This process is both time-consuming and computationally expensive, making it difficult to scale Mamba-based VLMs for broader applications.
提出问题
多项研究探索了将Mamba架构集成到VLMs中,通过用基于Mamba的大型语言模型(LLMs)替代基于Transformer的LLMs。这些工作展示了在推理速度上显著提升的同时,保持了竞争力的性能。然而,这些方法存在一些局限性:(1) Mamba采用顺序处理,限制了其捕捉全局上下文的能力,从而影响了这些VLMs在复杂推理和问题解决任务中的表现;(2) Mamba的顺序特性导致长序列训练中梯度传播效率低下,使得从头训练VLMs时收敛速度较慢。因此,高计算成本和大规模训练数据需求成为这些VLMs的主要瓶颈;(3) 当前这些VLMs的训练方案复杂,需要多阶段训练才能达到最佳性能。这一过程既耗时又计算昂贵,限制了基于Mamba的VLMs在更广泛应用中的扩展。
To address the aforementioned issues, we propose a novel Mamba-Transformer Vision-Language Model (MaTVLM) that integrates Mamba-2 and transformer components, striking a balance between computational efficiency and overall performance. Firstly, attention and Mamba are inherently connected, removing the softmax from attention transforms it into a linear RNN, revealing its structural similarity to Mamba. We will analyze this relationship in detail in Sec. 3.2. Furthermore, studies applying Mamba to large language models (LLMs) [48, 49] have demonstrated that models hybridizing Mamba outperform both pure Mamba-based and transformer-based models on certain tasks. Motivated by this connection and empirical findings, combining Mamba with transformer components presents a promising direction, offering a trade-off between improved reasoning capabilities and computational efficiency. Specifically, we adopt the TinyLLaVA [64] as the base VLM and replace a portion of its transformer decoder layers with Mamba decoder layers while keeping the rest of the model unchanged.
To minimize the training cost of the MaTVLM while maximizing its performance, we propose to distill knowledge from the pre-trained base VLM. Firstly, we initialize Mamba-2 with the corresponding attention’s weights as mentioned in Sec. 3.2, which is important to accelerate the convergence of Mamba-2 layers. Moreover, during distillation training, we employ both probability distribution and layer-wise distillation losses to guide the learning process, making only Mamba-2 layers trainable while keeping transformer layers fixed. Notably, unlike most VLMs that require complex multi-stage training, our approach involves a single-stage distillation process.
具体方法
为了解决上述问题,本文提出了一种新颖的Mamba-Transformer视觉-语言模型(MaTVLM),通过集成Mamba-2和Transformer组件,在计算效率和整体性能之间取得平衡。首先,注意力机制与Mamba具有内在联系,移除注意力中的softmax后,它可转化为线性RNN,揭示了其与Mamba的结构相似性。本文将在第3.2节详细分析这一关系。此外,研究显示将Mamba应用于大型语言模型(LLMs)时,混合Mamba的模型在某些任务上优于纯Mamba和纯Transformer模型。基于这一联系和实证发现,将Mamba与Transformer组件结合,提供了一个在提升推理能力和计算效率之间权衡的有前景的方向。具体而言,采用TinyLLaVA作为基础VLM,并将其部分Transformer解码器层替换为Mamba解码器层,同时保持模型其余部分不变。
为了在最小化MaTVLM训练成本的同时最大化其性能,提出从预训练的基础VLM中蒸馏知识。首先,使用相应的注意力权重初始化Mamba-2,如第3.2节所述,这对于加速Mamba-2层的收敛至关重要。此外,在蒸馏训练过程中,采用概率分布和逐层蒸馏损失来指导学习过程,仅训练Mamba-2层,同时固定Transformer层。值得注意的是,与大多数需要复杂多阶段训练的VLMs不同,本文的方法采用单阶段蒸馏过程。
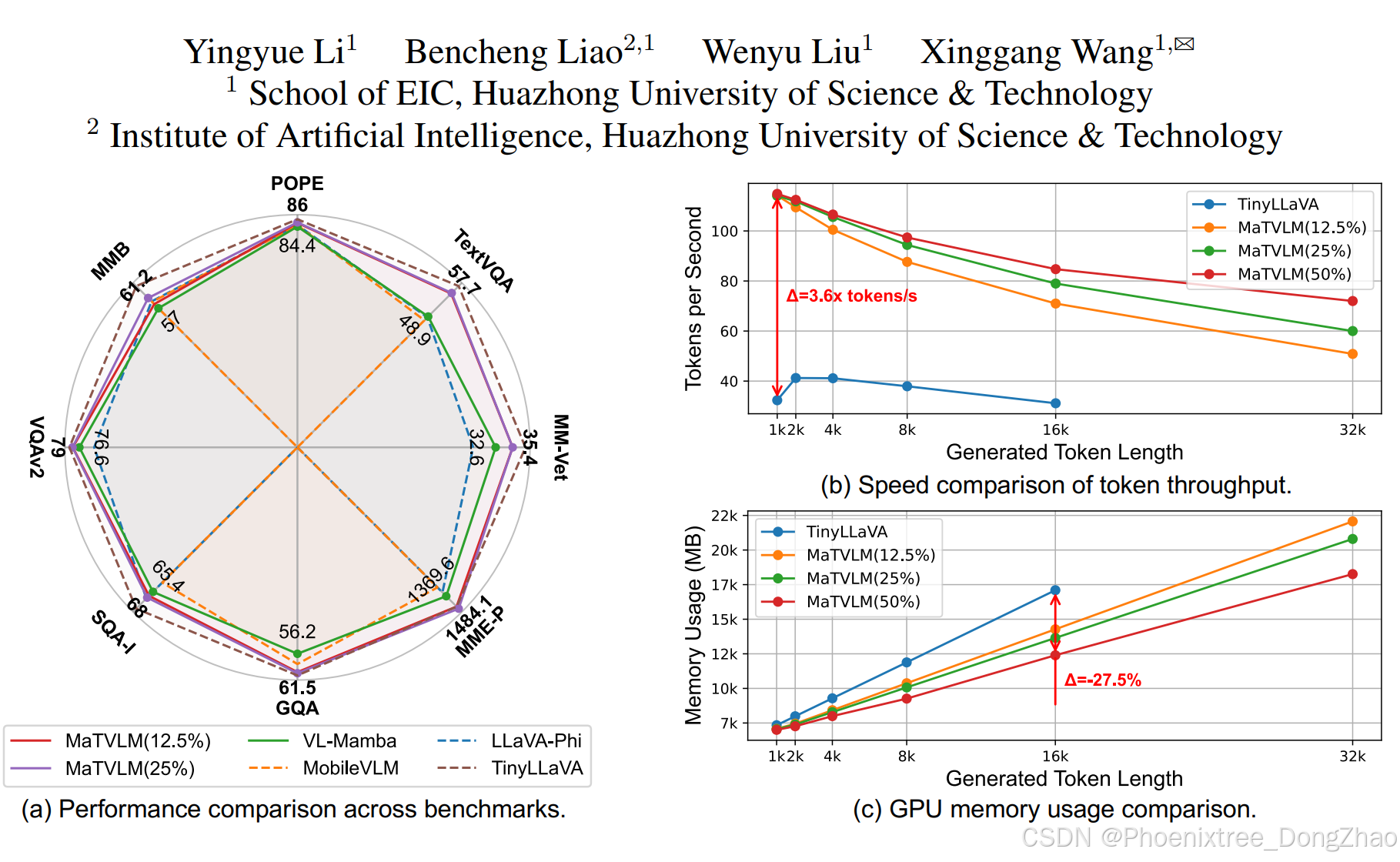
Despite the simplified training approach, our model demonstrates comprehensive performance across multiple benchmarks, as illustrated in Fig. 1. It exhibits competitive results when compared to the teacher model, TinyLLaVA, and outperforms Mamba-based VLMs as well as other transformer-based VLMs with similar parameter scales. The efficiency of our model is further emphasized by a 3.6× speedup and a 27.5% reduction in memory usage, thereby confirming its practical advantages in real-world applications. These results underscore the effectiveness of our approach, providing a promising avenue for future advancements in model development and optimization.
实验结果
尽管训练方法简化,本文的模型在多个基准测试中展现了全面的性能,如图1所示。与教师模型TinyLLaVA相比,它表现出竞争力的结果,并超越了基于Mamba的VLMs以及其他参数规模相当的基于Transformer的VLMs。模型的效率进一步体现在3.6倍的推理速度提升和27.5%的内存使用减少,从而确认了其在真实应用中的实际优势。这些结果证明了本文方法的有效性,为未来模型开发和优化提供了有前景的方向。
In summary, this paper makes three significant contributions:
• We propose a new hybrid VLM architecture MaTVLM that effectively integrates Mamba-2 and transformer components, balancing the computational efficiency with high-performance capabilities.
• We propose a novel single-stage knowledge distillation approach for the Mamba-Transformer hybrid VLMs. By leveraging pre-trained knowledge, our method accelerates convergence, enhances model performance, and strengthens visual-linguistic understanding.
• We demonstrate that our approach significantly achieves a 3.6× faster inference speed and a 27.5% reduction in memory usage while maintaining the competitive performance of the base VLM. Moreover, it outperforms Mamba-based VLMs and existing VLMs with similar parameter scales across multiple benchmarks.
总结而言,本文做出了三项重要贡献:
• 提出了一种新的混合VLM架构MaTVLM,有效集成了Mamba-2和Transformer组件,在计算效率和高性能能力之间取得平衡。
• 提出了一种新颖的单阶段知识蒸馏方法,适用于Mamba-Transformer混合VLMs。通过利用预训练知识,本文的方法加速了收敛,提升了模型性能,并增强了视觉-语言理解能力。
• 展示了本文的方法在保持基础VLM竞争力的同时,显著实现了3.6倍的推理速度提升和27.5%的内存使用减少。此外,它在多个基准测试中超越了基于Mamba的VLMs和现有参数规模相当的VLMs。
Method
Hybrid Attention with Mamba for VLMs
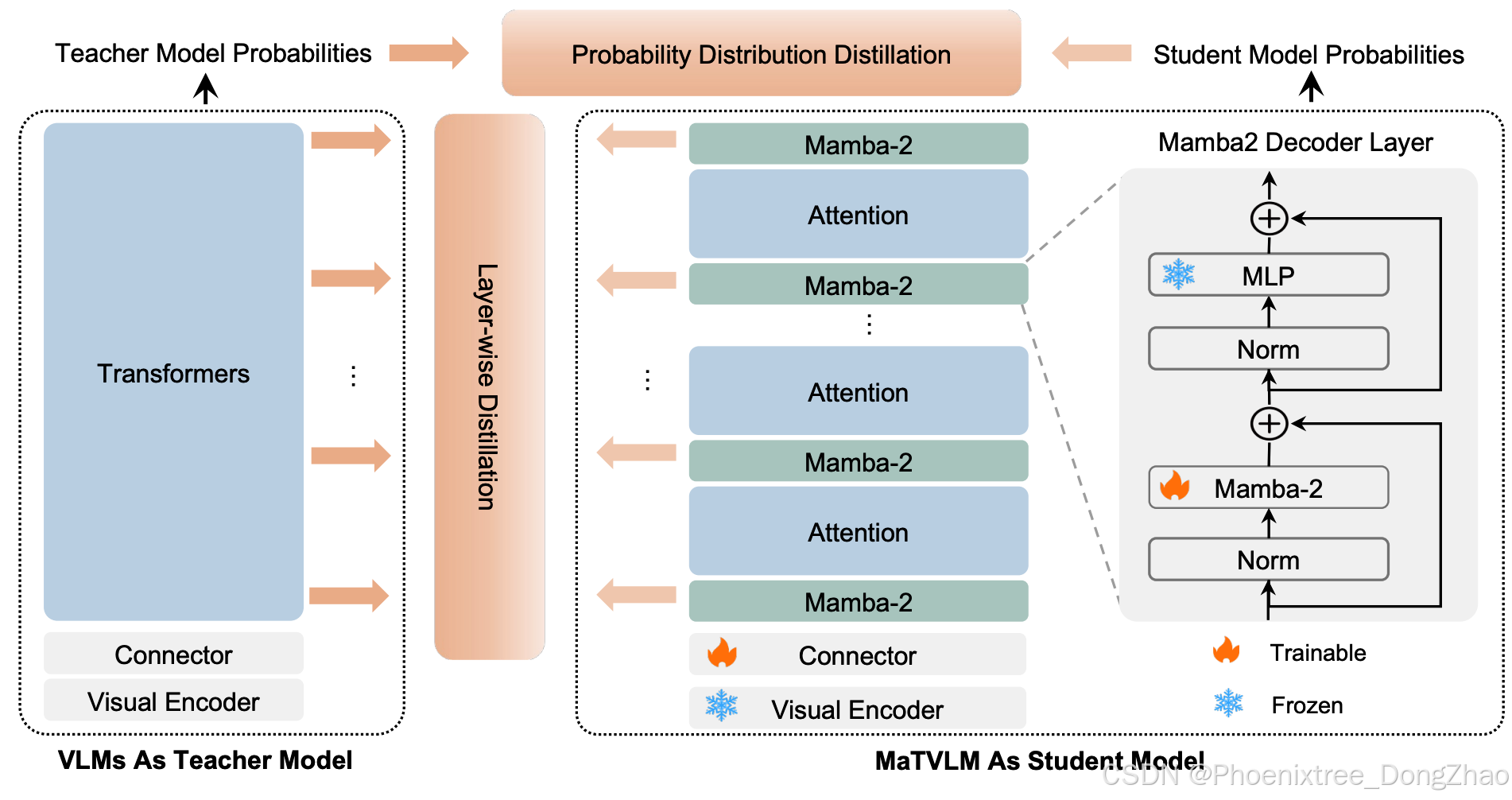
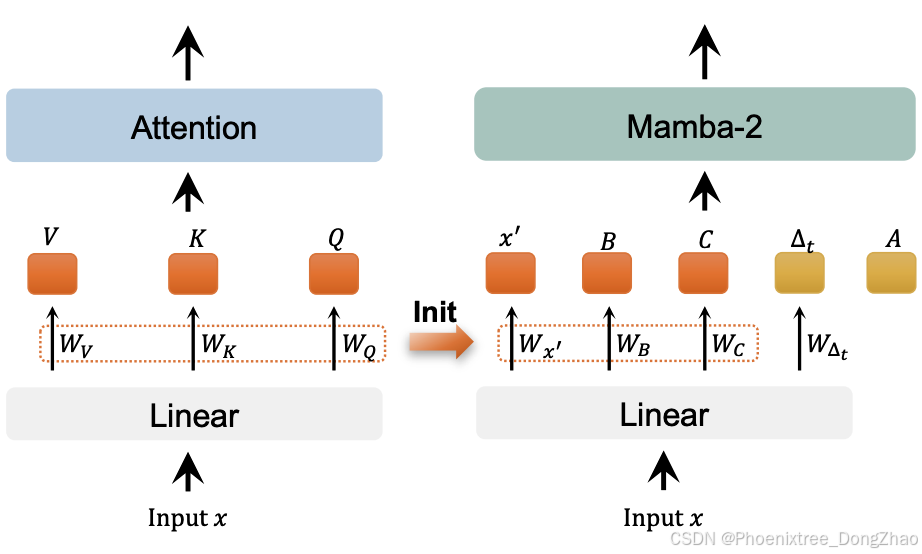
As shown in Fig. 2, the MaTVLM is built upon the pre-trained VLMs, comprising a vision encoder, a connector, and a language model. The language model originally consisted of transformer decoder layers, some of which are replaced with Mamba-2 decoder layers in our model. This replacement modifies only attention to Mamba-2 while leaving other components unchanged. Based on the configured proportions (e.g., 12.5%, 25%) of Mamba-2 decoder layers, we distribute them at equal intervals. Given that Mamba-2 shares certain connections with attention, some weights can be partially initialized from the original transformer layers, as detailed below.
Figure 2. The proposed MaTVLM integrates both Mamba-2 and transformer components. The model consists of a vision encoder, a connector, and a language model same as the base VLM. The language model is composed of both transformer decoder layers and Mamba2 decoder layers, where Mamba-2 layers replace only attention in transformer layers, while the other components remain unchanged. The model is trained using a knowledge distillation approach, incorporating probability distribution and layer-wise distillation loss. During the distillation training, only Mamba-2 layers and the connector are trainable, while transformer layers remain fixed.
Formally, for the xt in the input sequence x = [x1, x2, . . . , xn], attention in a transformer decoder layer is defined as:
where d is the dimension of the input embedding, and WQ, WK, and WV are learnable weights.
When removing the softmax operation in Eq. 3, the attention becomes:
The above results can be reformulated in the form of a linear RNN as follows:
Comparing Eq. 5 with Eq. 2, we can observe the following mapping relationships between them:
Consequently, we initialize the aforementioned weights of Mamba-2 layers with the corresponding weights from transformer layers as shown in Fig. 3, while the remaining weights are initialized randomly. Apart from Mamba-2 layers, all other weights remain identical to those of the original transformer.
混合注意力与Mamba用于视觉语言模型
如图2所示,MaTVLM基于预训练的视觉语言模型(VLMs)构建,包含一个视觉编码器、一个连接器和一个语言模型。语言模型最初由Transformer解码器层组成,在本文的模型中,部分层被替换为Mamba-2解码器层。这种替换仅将注意力机制修改为Mamba-2,而其他组件保持不变。根据配置的Mamba-2解码器层比例(例如12.5%、25%),本文以等间隔分布它们。鉴于Mamba-2与注意力机制存在某些关联,部分权重可以从原始Transformer层中部分初始化,如下所述。
形式上,对于输入序列x = [x_1, x_2, . . . , x_n]中的x_t,Transformer解码器层中的注意力机制定义为:
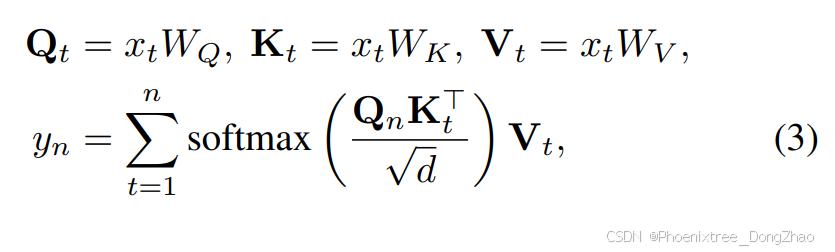
其中,d是输入嵌入的维度,WQ、WK和WV是可学习的权重。
当移除公式3中的softmax操作时,注意力机制变为:
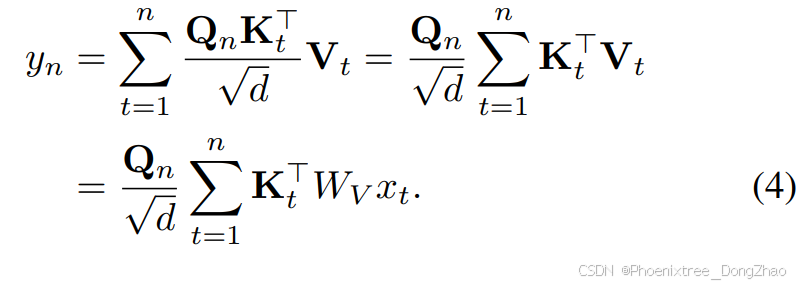
上述结果可以重新表述为线性RNN的形式:
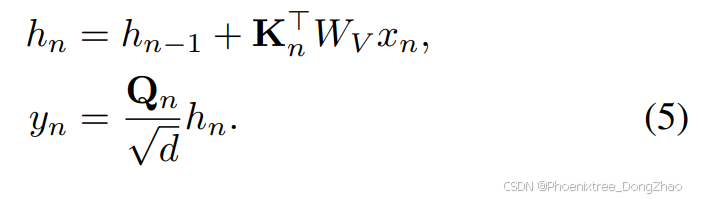
通过比较公式5与公式2,本文可以观察到它们之间的以下映射关系:
![]()
因此,本文使用Transformer层的对应权重初始化Mamba-2层的上述权重,如图3所示,而其余权重随机初始化。除了Mamba-2层,所有其他权重与原始Transformer保持一致。
Knowledge Distilling Transformers into Hybrid Models
To further enhance the performance of the MaTVLM, we propose a knowledge distillation method that transfers knowledge from transformer layers to Mamba-2 layers. We use a pre-trained VLM as the teacher model and our MaTVLM as the student model. We will introduce the distillation strategies in the following.
Figure 3. We initialize certain weights of Mamba-2 from attention based on their correspondence. Specifically, the linear weights of x, B, C in Mamba-2 are initialized from the linear weights of V, K, Q in the attention mechanism. The remaining parameters, including ∆t and A, are initialized randomly
Probability Distribution Distillation
First, our goal is to minimize the distance between probability distributions of the models, just the logits output by the models before applying the softmax function. This approach is widely adopted in knowledge distillation, as aligning the output distributions of the models allows the student model to gain a more nuanced understanding from the teacher model’s prediction. To achieve this, we use the Kullback-Leibler (KL) divergence with a temperature scaling factor as the loss function. The temperature factor adjusts the smoothness of the probability distributions, allowing the student model to capture finer details from the softened distribution of the teacher model. The loss function is defined as follows:
The softened probabilities Pt(i) and Ps(i) are calculated by applying a temperature-scaled softmax function to the logits of the teacher and student models, respectively:
where T is the temperature scaling factor, a higher temperature produces softer distributions, zt is the logit (pre-softmax output) from the teacher model, and zˆs is the corresponding logit from the student model.
将Transformer知识蒸馏到混合模型中
为了进一步提升MaTVLM的性能,本文提出了一种知识蒸馏方法,将知识从Transformer层迁移到Mamba-2层。本文使用预训练的VLM作为教师模型,并将本文的MaTVLM作为学生模型。接下来本文将介绍蒸馏策略。
概率分布蒸馏
首先,本文的目标是最小化模型概率分布之间的距离,即在应用softmax函数之前模型输出的logits。这种方法在知识蒸馏中被广泛采用,因为对齐模型的输出分布可以让学生模型从教师模型的预测中获得更细致的理解。为此,使用带有温度缩放因子的Kullback-Leibler(KL)散度作为损失函数。温度因子调整概率分布的平滑度,使学生模型能够从教师模型的软化分布中捕捉更精细的细节。损失函数定义如下:
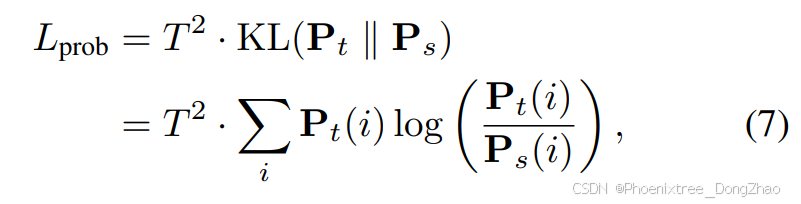
软化概率 P_t(i) 和 P_s(i) 通过将温度缩放的 softmax 函数应用于教师模型和学生模型的 logits 计算得出:
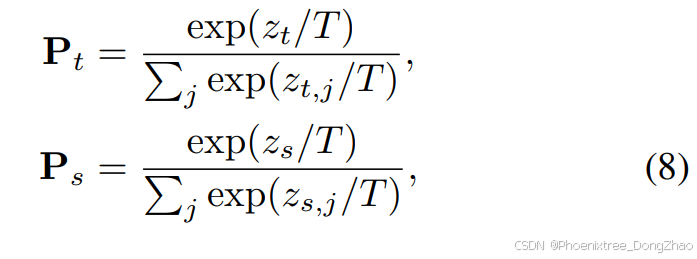
其中,T是温度缩放因子,较高的温度会产生更软的分布,z_t是教师模型的logit(softmax前的输出),zˆs是学生模型的对应logit。
Layer-wise Distillation
Moreover, to ensure that each Mamba layer in the student model aligns with its corresponding layer in the teacher model, we adopt a layer-wise distillation strategy. Specifically, this approach minimizes the L2 norm between the outputs of Mamba layers in the student model and the corresponding transformer layers in the teacher model when provided with the same input. These inputs are generated from the previous layer of the teacher model, ensuring consistency and continuity of context. By aligning intermediate feature representations, the student model can more effectively replicate the hierarchical feature extraction process of the teacher model, thereby enhancing its overall performance. Assume the Mamba layers’ position in the student model is l = [l1, l2, . . . , lm]. The corresponding loss function for this alignment is defined as:
where Tli (x) and Sli (x) represent the outputs of the teacher model and the student model at layer li, respectively.
逐层蒸馏
此外,为了确保学生模型中的每个Mamba层与教师模型中的对应层对齐,本文采用了一种逐层蒸馏策略。具体来说,这种方法在提供相同输入时,最小化学生模型中Mamba层与教师模型中对应Transformer层输出之间的L2范数。这些输入由教师模型的上一层生成,确保上下文的一致性和连续性。通过对齐中间特征表示,学生模型可以更有效地复制教师模型的分层特征提取过程,从而提升其整体性能。假设学生模型中Mamba层的位置为l = [l_1, l_2, . . . , l_m],对齐的损失函数定义如下:
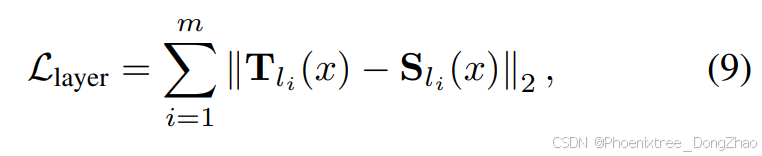
其中,Tli (x)和Sli (x)分别表示教师模型和学生模型在层li的输出。
Sequence Prediction Loss
Finally, except for the distillation losses mentioned above, we also calculate the cross-entropy loss between the output sequence prediction of the student model and the ground truth. This loss is used to guide the student model to learn the correct sequence prediction, which is crucial for the model to perform well on downstream tasks. The loss function is defined as:
where y is the ground truth sequence, and yˆs is the predicted sequence from the student model.
序列预测损失
最后,除了上述蒸馏损失,本文还计算了学生模型的输出序列预测与真实标签之间的交叉熵损失。该损失用于指导学生模型学习正确的序列预测,这对于模型在下游任务中表现良好至关重要。损失函数定义如下:
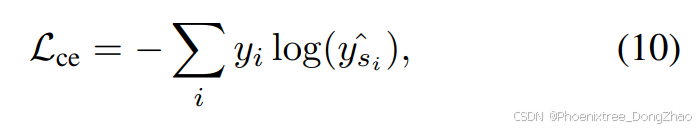
其中,y是真实标签序列,yˆs是学生模型的预测序列。
Single Stage Distillation Training
To fully harness the complementary strengths of the proposed distillation methods, we integrate the probability distribution loss, layer-wise distillation loss, and the sequence prediction loss into a unified framework for the single stage distillation training. During training, we set their respective weights as follows:
where α, β, γ are hyperparameters that control the relative importance of each loss component.
We will conduct a series of experiments to thoroughly investigate the individual contributions and interactions of these three loss functions. By analyzing their effects in isolation and in combination, we aim to gain deeper insights into how each loss function influences the student model’s learning process, the quality of intermediate representations, and the accuracy of final predictions. This will help us understand the specific role of each loss in enhancing the overall performance of the model and ensure that the chosen loss functions are effectively contributing to the optimization process.
This single-stage framework efficiently combines two distillation objectives and one prediction task, allowing gradients from different loss components to flow seamlessly through the student model. The unified loss function not only accelerates convergence during training but also ensures that the student model benefits from both hierarchical feature distillation and global prediction alignment. Furthermore, the proposed method is flexible and can be easily adapted to various neural architectures and tasks by adjusting the weights of the loss components based on task-specific requirements. By integrating these two distillation objectives and the prediction task into a single framework, the student model, MaTVLM, achieves significant performance improvements while maintaining computational efficiency, making this approach highly applicable in real-world scenarios.
单阶段蒸馏训练
为了充分发挥所提出的蒸馏方法的互补优势,将概率分布损失、逐层蒸馏损失和序列预测损失整合到一个统一框架中,用于单阶段蒸馏训练。在训练过程中,本文设置它们各自的权重如下:
![]()
其中,α、β、γ是控制每个损失组件相对重要性的超参数。
本文将进行一系列实验,以彻底研究这三个损失函数的个体贡献和相互作用。通过分析它们单独和组合的效果,旨在更深入地了解每个损失函数如何影响学生模型的学习过程、中间表示的质量以及最终预测的准确性。这将帮助理解每个损失在提升模型整体性能中的具体作用,并确保所选的损失函数有效地贡献于优化过程。
这种单阶段框架高效地结合了两个蒸馏目标和一个预测任务,使来自不同损失组件的梯度能够无缝地通过学生模型流动。统一损失函数不仅加速了训练期间的收敛,还确保学生模型从分层特征蒸馏和全局预测对齐中受益。此外,所提出的方法具有灵活性,可以通过根据任务特定需求调整损失组件的权重,轻松适应各种神经网络架构和任务。通过将这两个蒸馏目标和预测任务整合到一个单一框架中,学生模型——MaTVLM,在保持计算效率的同时实现了显著的性能提升,使该方法在实际场景中具有高度适用性。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)