(Note)音频向量化表示
·
音频向量化表示
经典语音特征(MFCC等)语音信号的传统特征提取方法包括MFCC(梅尔倒谱系数)、PLP等,用于描述语音的频谱包络信息。这些特征设计依据生理听觉模型,在ASR、情感识别等任务中长期有效。但它们仍属浅层特征,无法自动学习更高阶的语言和语音信息,对说话人和环境的鲁棒性有限,通常需配合复杂模型来提高性能。
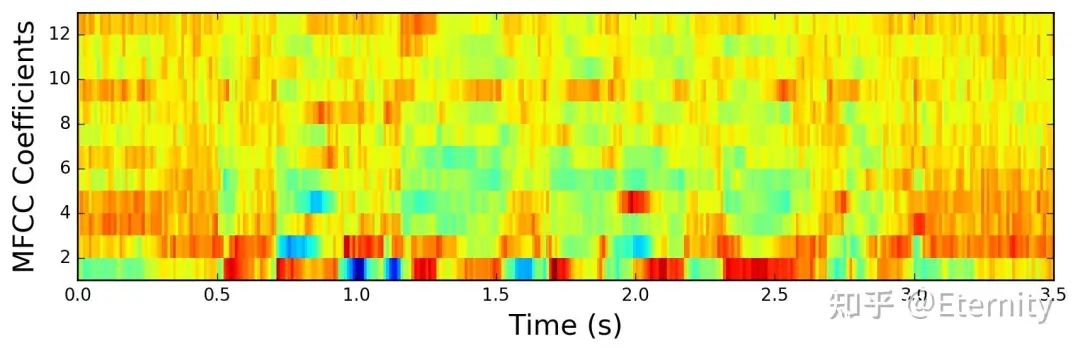
梅尔倒谱系数特征示意图
自监督语音模型(Wav2Vec、HuBERT等) 近年来,语音领域也借鉴了文本与视觉的自监督预训练思想:Wav2Vec(2019):Schneider等提出了第一个Wav2Vec模型。该模型使用双层卷积网络编码原始音频,通过噪声对比学习(NCE)任务来预测未来音频帧。Wav2Vec的优点是无需文本标签即可从大量无标注音频学习特征,但早期模型仍依赖ConvNet结构,有一定的表达局限。Wav2Vec 2.0(2020):Baevski等改进了Wav2Vec,引入了Transformer编码器和向量量化,将输入划分为离散音频单元,并对其进行Masked Prediction预训练。Wav2Vec 2.0在LibriSpeech等标准基准上达到了超越以往方法的性能,进一步推动了无监督语音表征发展。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)