扩散策略:通过动作扩散的视觉运动策略学习
本文介绍了扩散策略(Diffusion Policy),这是一种通过将机器人的视觉运动策略表示为条件去噪扩散过程来生成机器人行为的新方法。我们在来自4个不同机器人操作基准的15项不同任务上对扩散策略进行了基准测试,发现它始终优于现有的最先进的机器人学习方法,平均改进幅度达到46.9%。扩散策略学习动作分布得分函数的梯度,并在推理过程中通过一系列随机朗之万动力学步骤,根据该梯度场进行迭代优化。
原文:https://arxiv.org/pdf/2303.04137
Diffusion Policy代码、数据及训练细节:Diffusion Policy
摘要
本文介绍了扩散策略(Diffusion Policy),这是一种通过将机器人的视觉运动策略表示为条件去噪扩散过程来生成机器人行为的新方法。我们在来自4个不同机器人操作基准的15项不同任务上对扩散策略进行了基准测试,发现它始终优于现有的最先进的机器人学习方法,平均改进幅度达到46.9%。扩散策略学习动作分布得分函数的梯度,并在推理过程中通过一系列随机朗之万动力学步骤,根据该梯度场进行迭代优化。我们发现,当用于机器人策略时,扩散公式展现出了强大的优势,包括能够优雅地处理多模态动作分布、适用于高维动作空间,以及表现出令人印象深刻的训练稳定性。为了充分释放扩散模型在实体机器人视觉运动策略学习方面的潜力,本文提出了一系列关键技术贡献,包括融合预测控制、视觉条件设置和时间序列扩散变换器。我们希望这项工作能够激励新一代策略学习技术的发展,这些技术能够利用扩散模型强大的生成建模能力。
关键词:模仿学习,视觉运动策略,操作控制
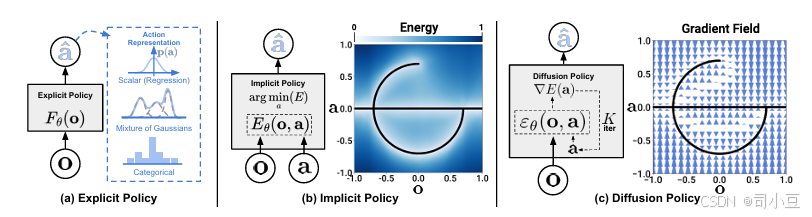
图1. 策略表示。
a) 具有不同类型动作表示的显式策略。
b) 隐式策略学习一个以动作和观察为条件的能量函数,并优化使能量景观最小化的动作。
c) 扩散策略通过学习的梯度场将噪声精炼为动作。这种表述提供了稳定的训练,使得学习到的策略能够准确模拟多模态动作分布,并适应高维动作序列。
1 引言
从示范中进行策略学习,在最简单的形式下,可以被构想为一项监督回归任务,即学习将观察结果映射到动作上。然而,在实际操作中,预测机器人动作所具有的独特性质——例如多模态分布的存在、序列相关性以及对高精度的要求——使得这项任务与其他监督学习问题相比显得与众不同且更具挑战性。先前的工作试图通过探索不同的动作表示(图1a)来解决这一挑战,例如使用高斯混合体Mandlekar等人(2021)或量化动作的分类表示Shafiullah等人(2022),或者通过转换策略表示(图1b),从显式表示转为隐式表示,以更好地捕捉多模态分布Florence等人(2021);Wu等人(2020)。
在这项工作中,我们试图通过引入一种新型的机器人视觉运动策略来解决这一挑战,该策略通过“在机器人动作空间上应用条件去噪扩散过程Ho等人(2020)”来生成行为,我们称之为“扩散策略(Diffusion Policy)”。在这种表述中,策略不是直接输出动作,而是根据视觉观察,在K次去噪迭代中推断出动作得分梯度(Fig. 1 c)。这种表述使得机器人策略能够从扩散模型中继承几个关键属性,从而显著提高性能。
• 表达多模态动作分布。通过学习动作得分函数的梯度(Song and Ermon, 2019),并在这个梯度场上执行随机朗之万动力学采样,扩散策略能够表达任意可归一化的分布(Neal et al., 2011),这包括多模态动作分布,这是策略学习中的一个众所周知的挑战。
• 高维输出空间。扩散模型在图像生成方面取得了令人瞩目的成果,证明了它们在高维输出空间上具有出色的可扩展性。这一特性使得策略能够联合推断一系列未来动作,而不是单步动作,这对于促进动作的时间一致性和避免短视规划至关重要。
• 稳定训练。训练基于能量的策略通常需要通过负采样来估计一个难以处理的归一化常数,这已知会导致训练不稳定(Du et al., 2020; Florence et al., 2021)。扩散策略通过学习能量函数的梯度来绕过这一需求,从而在保持分布表达能力的同时实现了稳定的训练。
我们的主要贡献是将上述优势引入机器人学领域,并在复杂的现实世界机器人操作任务中证明其有效性。为了成功地将扩散模型应用于视觉运动策略学习,我们做出了以下技术贡献,这些贡献提升了扩散策略的性能,并充分发掘了其在实体机器人上的潜力:
• 闭环动作序列。我们将策略预测高维动作序列的能力与滚动时域控制相结合,以实现稳健的执行。这种设计使策略能够以闭环方式持续重新规划其动作,同时保持动作的时间一致性,从而在长期规划与响应性之间取得平衡。
• 视觉条件约束。我们引入了一种视觉条件约束下的扩散策略,其中视觉观察被视为条件约束,而不是联合数据分布的一部分。在这种表述中,策略仅提取一次视觉表征,无论进行多少次去噪迭代,这极大地减少了计算量,并实现了实时动作推断。
• 时间序列扩散Transformer。我们提出了一种新的基于Transformer的扩散网络,该网络最小化了典型基于CNN模型的过度平滑效应,并在需要高频动作变化和速度控制的任务上实现了最先进的性能。
我们在行为克隆框架下,对来自4个不同基准测试集(Florence et al., 2021; Gupta et al., 2019; Mandlekar et al., 2021; Shafiullah et al., 2022)的15项任务上,对扩散策略进行了系统评估。评估涵盖了模拟环境和真实环境、2自由度(DoF)到6自由度的动作、单任务和多任务基准测试、全驱动和欠驱动系统,以及使用单个和多个用户收集的演示数据的刚体和流体对象。
从实证角度看,我们在所有基准测试中均发现了性能的一致提升,平均改进幅度达到46.9%,这为扩散策略的有效性提供了有力证据。我们还进行了详细分析,以仔细考察所提算法的特点和关键设计决策的影响。
本文是会议论文Chi et al. (2023)的扩展版。我们以以下方式扩展了本文的内容:
• 增加了一个新讨论部分,探讨扩散策略与控制理论之间的联系。见第4.5节.
• 在模拟环境中进行了额外的消融研究,探讨了替代网络架构设计以及不同的预训练和微调范式,见第5.4节。
• 在第7节中,通过三项双手操作任务(包括打蛋器操作、铺展垫子和衬衫折叠)扩展了现实世界中的实验结果。
代码、数据和训练细节均可在diffusion-policy.cs.columbia.edu上公开获取,以便重现我们的结果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)