视觉SLAM理论到实践系列(五)——非线性优化(2)
非线性优化
视觉SLAM理论到实践系列文章
下面是《视觉SLAM十四讲》学习笔记的系列记录的总链接,本人发表这个系列的文章链接均收录于此
视觉SLAM理论到实践系列文章链接
下面是专栏地址:
视觉SLAM理论到实践专栏
文章目录
前言
高翔博士的《视觉SLAM14讲》学习笔记的系列记录
视觉SLAM理论到实践系列(五)——非线性优化(2)
机器人状态估计
经典SLAM问题
接着前面几讲的内容,我们回顾第2讲讨论的经典SLAM模型。
它由一个运动方程和一个观测方程构成,如下式所示:
{ x k = f ( x k − 1 , u k ) + w k z k , j = h ( y j , x k ) + v k , j . \begin{cases}\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k\right)+\boldsymbol{w}_k\\ \boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_j,\boldsymbol{x}_k\right)+\boldsymbol{v}_{k,j}\end{cases}. {xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j.
通过第4讲的知识,我们了解到这里的 x k x_k xk 是相机的位姿,可以用 S E ( 3 ) SE(3) SE(3) 来描述。
至于观测方程,第5讲已经说明,即针孔相机模型。为了让读者对它们有更深的印象,我们不妨讨论其具体参数化形式。首先,位姿变量 x x x 可以由 T k ∈ S E ( 3 ) T_k\in SE(3) Tk∈SE(3) 表达。
其次,运动方程与输入的具体形式有关,但在视觉SLAM中没有特殊性(和普通的机器人、车辆的情况一样),我们暂且不谈。观测方程则由针孔模型给定。
假设在 x k x_k xk 处对路标 y j y_j yj ,进行了一次观测,对应到图像上的像素位置 z k , j z_{k,j} zk,j,那么,观测方程可以表示成
s z k , j = K ( R k y j + t k ) . sz_{k,j}=K(R_ky_j+t_k). szk,j=K(Rkyj+tk).
其中 K K K 为相机内参, s s s 为像素点的距离,也是 ( R k y j + t k ) (R_ky_j+t_k) (Rkyj+tk) 的第三个分量。如果使用变换矩阵 T T T 描述位姿,那么路标点 y j y_j yj 必须以齐次坐标来描述,计算完成后要转换为非齐次坐标。
如果你还不熟悉这个过程,请回顾第5讲相机与图像。
现在,考虑数据受噪声影响后会发生什么改变。在运动和观测方程中,我们通常假设两个噪声项 w k , v k w_k,v_k wk,vk,满足零均值的高斯分布,像这样:
w k ∼ N ( 0 , R k ) , v k ∼ N ( 0 , Q k , j ) . \boldsymbol{w}_k\sim\mathcal{N}\left(\boldsymbol{0},\boldsymbol{R}_k\right),\boldsymbol{v}_k\sim\mathcal{N}\left(\boldsymbol{0},\boldsymbol{Q}_{k,j}\right). wk∼N(0,Rk),vk∼N(0,Qk,j).
其中 N \mathcal{N} N 表示高斯分布, 0 \mathbf{0} 0 表示零均值, R k , Q k , j R_k,Q_{k,j} Rk,Qk,j 为协方差矩阵。在这些噪声的影响下,我们希望通过带噪声的数据 z z z 和 u u u 推断位姿 x x x 和地图 y y y (以及它们的概率分布),这构成了一个状态估计问题。
状态估计——处理思路
总的来说:
对于经典SLAM问题
{ x k = f ( x k − 1 , u k ) + w k z k , j = h ( y j , x k ) + v k , j . \begin{cases}\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k\right)+\boldsymbol{w}_k\\ \boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_j,\boldsymbol{x}_k\right)+\boldsymbol{v}_{k,j}\end{cases}. {xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j.
(1)ch3 位姿描述
(2)ch4 位姿求导
(3)ch5 相机观测
(4)运动方程和观测方程中的噪声
w k ∼ N ( 0 , R k ) , v k ∼ N ( 0 , Q k , j ) \boldsymbol{w}_k\sim\mathcal{N}\left(\boldsymbol{0},\boldsymbol{R}_k\right),\boldsymbol{v}_k\sim\mathcal{N}\left(\boldsymbol{0},\boldsymbol{Q}_{k,j}\right) wk∼N(0,Rk),vk∼N(0,Qk,j)
(5)由已知的 z z z 和 u u u,推测 x x x 和 y y y,构成状态估计问题
处理这个状态估计问题的方法大致分成两种。
由于在SLAM过程中,这些数据是随时间逐渐到来的,所以,我们应该持有一个当前时刻的估计状态,然后用新的数据来更新它。这种方式称为增量/渐进(incremental)的方法,或者叫滤波器。在历史上很长一段时间内,研究者们使用滤波器,尤其是扩展卡尔曼滤波器及其衍生方法求解它。
另一种方式,则是把数据“攒”起来一并处理,这种方式称为**批量(batch)**的方法。例如,我们可以把0到k时刻所有的输入和观测数据都放在一起,问,在这样的输入和观测下,如何估计整个0到k时刻的轨迹与地图呢?
这两种不同的处理方式引出了很多不同的估计手段。
大体来说,增量方法仅关心当前时刻的状态估计 x x x,而对之前的状态则不多考虑;相对地,批量方法可以在更大的范围达到最优化,被认为优于传统的滤波器,而成为当前视觉SLAM的主流方法。极端情况下,我们可以让机器人或无人机收集所有时刻的数据,再带回计算中心统一处理,这也正是 SfM(Structure from Motion) 的主流做法。
当然,这种极端情况显然是不实时的,不符合SLAM的运用场景。所以在SLAM中,实用的方法通常是一些折衷的手段。例如,我们固定一些历史轨迹,仅对当前时刻附近的一些轨迹进行优化,这是后面要讲到的滑动窗口估计法。
总的来说:
(1)增量数据 -> 滤波角度
仅考虑当前时刻
缺:累积误差
(2)批量数据 -> 优化角度
更大范围合理性
缺:时间过长
(3)滑动窗口 -> 折衷手段
将一段时间内的数据纳入优化
优:兼顾时间与精度
(4)前端后端 -> 综合手段
-
前端使用轻量级的方法预估路径
滤波/小优化/预积分
-
积累一定的数据后,在后端对轨迹进行优化
上述手段并不是完全独立的,有时会相互借鉴融合
状态估计——问题描述
理论上,批量方法更容易介绍。同时,理解了批量方法也更容易理解增量的方法。
所以,本节我们重点介绍以非线性优化为主的批量优化方法,将卡尔曼滤波器及更深入的知识留到介绍后端的章节再进行讨论。
由于讨论的是批量方法,考虑从1到N的所有时刻,并假设有M个路标点。
定义所有时刻的机器人位姿和路标点坐标为
x = { x 1 , … , x N } , y = { y 1 , … , y M } . \mathbf{x}=\{\mathbf{x}_1,\ldots,\mathbf{x}_N\},\quad\mathbf{y}=\{\mathbf{y}_1,\ldots,\mathbf{y}_M\}. x={x1,…,xN},y={y1,…,yM}.
同样地,用不带下标的 u u u 表示所有时刻的输入, z z z 表示所有时刻的观测数据。那么我们说,对机器人状态的估计,从概率学的观,点来看,就是已知输入数据 u u u 和观测数据 z z z 的条件下,求状态 x , y x,y x,y 的条件概率分布:
P ( x , y ∣ z , u ) . P(x,y|z,u). P(x,y∣z,u).
特别地,当我们不知道控制输入,只有一张张的图像时,即只考虑观测方程带来的数据时,相当于估计 P ( x , y ∣ z ) P(x,y|z) P(x,y∣z) 的条件概率分布,此问题也称为 SfM,即如何从许多图像中重建三维空间结构。
为了估计状态变量的条件分布,利用贝叶斯法则,有
P ( x , y ∣ z , u ) = P ( z , u ∣ x , y ) P ( x , y ) P ( z , u ) ∝ P ( z , u ∣ x , y ) ⏟ 似然 P ( x , y ) ⏟ 先验 . P\left(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u}\right)=\frac{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right) P\left(\boldsymbol{x},\boldsymbol{y}\right)} {P\left(\boldsymbol{z},\boldsymbol{u}\right)} \propto \underbrace{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{似然}}\underbrace{P\left(\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{先验}}. P(x,y∣z,u)=P(z,u)P(z,u∣x,y)P(x,y)∝似然
P(z,u∣x,y)先验
P(x,y).
贝叶斯法则左侧称为后验概率,右侧的 P ( z ∣ x ) P(z|x) P(z∣x) 称为似然(Likehood),另一部分 P ( x ) P(x) P(x) 称为先验(Prior)。
直接求后验分布是困难的,但是求一个状态最优估计,使得在该状态下后验概率最大化,则是可行的:
( x , y ) M A P ∗ = arg max P ( x , y ∣ z , u ) = arg max P ( z , u ∣ x , y ) P ( x , y ) . (\boldsymbol{x},\boldsymbol{y})^*_{M A P}=\arg\max P(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u})=\arg\max P(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y})P(\boldsymbol{x},\boldsymbol{y}). (x,y)MAP∗=argmaxP(x,y∣z,u)=argmaxP(z,u∣x,y)P(x,y).
请注意贝叶斯法则的分母部分与待估计的状态 x , y x,y x,y 无关,因而可以忽略。
贝叶斯法则告诉我们,求解最大后验概率等价于最大化似然和先验的乘积。
当然,我们也可以说,对不起,我不知道机器人位姿或路标大概在什么地方,此时就没有了先验。那么,可以求解最大似然估计(Maximize Likelihood Estimation,MLE ):
( x , y ) MLE ∗ = arg max P ( z , u ∣ x , y ) . (x,y)^*_{\text{MLE}}=\arg\max P(z,u|x,y). (x,y)MLE∗=argmaxP(z,u∣x,y).
直观地讲,似然是指“在现在的位姿下,可能产生怎样的观测数据”。由于我们知道观测数据,所以最大似然估计可以理解成:“在什么样的状态下,最可能产生现在观测到的数据”。这就是最大似然估计的直观意义。
总的来说
(1)面临的问题:已知运动和观测,求轨迹和地图
P ( x , y ∣ z , u ) . P(x,y|z,u). P(x,y∣z,u).
(2)使用贝叶斯法则对问题变形
P ( x , y ∣ z , u ) = P ( z , u ∣ x , y ) P ( x , y ) P ( z , u ) ∝ P ( z , u ∣ x , y ) ⏟ 似然 P ( x , y ) ⏟ 先验 P\left(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u}\right)=\frac{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right) P\left(\boldsymbol{x},\boldsymbol{y}\right)} {P\left(\boldsymbol{z},\boldsymbol{u}\right)} \propto \underbrace{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{似然}}\underbrace{P\left(\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{先验}} P(x,y∣z,u)=P(z,u)P(z,u∣x,y)P(x,y)∝似然
P(z,u∣x,y)先验
P(x,y)
将 最大化后验概率 转换为 max ( 似然 ∗ 先验) \max( 似然 * 先验) max(似然∗先验)
(3)直接求后验分布是困难的,但是求一个状态最优估计,使得在该状态下后验概率最大化
( x , y ) M A P ∗ = arg max P ( x , y ∣ z , u ) = arg max P ( z , u ∣ x , y ) P ( x , y ) (\boldsymbol{x},\boldsymbol{y})^*_{M A P}=\arg\max P(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u})=\arg\max P(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y})P(\boldsymbol{x},\boldsymbol{y}) (x,y)MAP∗=argmaxP(x,y∣z,u)=argmaxP(z,u∣x,y)P(x,y)
求 最大后验概率
(4)有时候我们没有运动信息,只有一组观测,这时就没有了先验,问题是纯粹的SFM问题
( x , y ) MLE ∗ = arg max P ( z , u ∣ x , y ) (x,y)^*_{\text{MLE}}=\arg\max P(z,u|x,y) (x,y)MLE∗=argmaxP(z,u∣x,y)
求 最大似然估计
“在怎样的位姿和地图下,最可能出现已知观测”
补充
关于似然函数,参考:
似然(likelihood)和概率(probability)的区别与联系
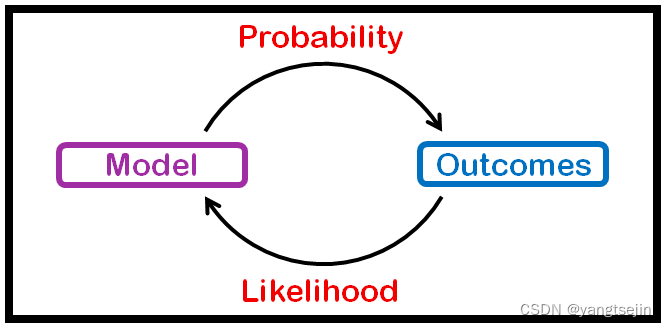
似然(Likelihood)也称"逆概率",是贝叶斯主义的核心概念,它是贝叶斯公式的组成部分自不待言,它在频率主义的极大似然估计(Maximum Likelihood Estimation, MLE)的应用也堪称经典
概率描述的是结果;似然描述的是假设/模型
(1)概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性。 比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的。
(2)而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数)。 还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%,这个过程就是我们运用出现的结果来判断这个事情本身的性质(参数),也就是似然。
**概率函数:**如果 θ 是已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。(相当于机器/深度学习模型的测试过程,此时参数已训练好,是确定的)
**似然函数:**如果x是已知确定的, θ 是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。(相当于机器/深度学习模型的训练过程,此时参数还未确定,x是确定的)
我们可以做一个类比,假设一个函数为 a b a^b ab ,这个函数包含两个变量。
如果你令 b = 2 b=2 b=2,这样你就得到了一个关于 a a a 的二次函数,即 a 2 a^2 a2 :

当你令 a = 2 a=2 a=2 时,你将得到一个关于** b b b 的指数函数**,即 2 b 2^b 2b:

可以看到这两个函数有着不同的名字,却源于同一个函数。
而 p ( x ∣ θ ) p(x|θ) p(x∣θ) 也是一个有着两个变量的函数。
如果,你将 θ \theta θ 设为常量,则你会得到一个概率函数(关于 x x x 的函数);如果,你将 x x x 设为常量你将得到似然函数(关于 θ \theta θ 的函数)。
下面举一个例子:
有一个硬币,它有 θ \theta θ 的概率会正面向上,有 1 − θ 1-\theta 1−θ 的概率反面向上。 θ \theta θ 是存在的,但是你不知道它是多少。为了获得 θ \theta θ 的值,你做了一个实验:将硬币抛10次,得到了一个正反序列: x = H H T T H T H H H H x=HHTTHTHHHH x=HHTTHTHHHH。
无论 θ \theta θ 的值是多少,这个序列的概率值为
f ( x , θ ) = θ ⋅ θ ⋅ ( 1 − θ ) ⋅ ( 1 − θ ) ⋅ θ ⋅ ( 1 − θ ) ⋅ θ ⋅ θ ⋅ θ ⋅ θ = θ 7 ( 1 − θ ) 3 = f ( θ ) f(x,\theta)=\theta \cdot \theta \cdot(1-\theta)⋅(1-\theta)⋅\theta⋅(1-\theta)\cdot\theta\cdot\theta\cdot\theta\cdot\theta = \theta^7 (1-\theta)^3=f({\theta}) f(x,θ)=θ⋅θ⋅(1−θ)⋅(1−θ)⋅θ⋅(1−θ)⋅θ⋅θ⋅θ⋅θ=θ7(1−θ)3=f(θ)
注:这是个只关于 θ \theta θ 的函数。而最大似然估计,顾名思义,就是要最大化这个函数,说得更简单点,就是给你一个函数,求它的极大值点。
比如,如果 θ \theta θ 值为0,则得到这个序列的概率值为 0。如果 θ \theta θ 值为1/2,概率值为1/1024。
但是,我们应该得到一个更大的概率值,所以我们尝试了所有 θ \theta θ 可取的值,画出了下图:

这个曲线就是 θ \theta θ 的似然函数,通过了解在某一假设下,已知数据发生的可能性,来评价哪一个假设更接近 θ \theta θ 的真实值。
如图所示,最有可能的假设是在 θ = 0.7 \theta=0.7 θ=0.7 的时候取到。但是,你无须得出最终的结论 θ = 0.7 \theta=0.7 θ=0.7。
这样,我们已经完成了对 θ \theta θ 的最大似然估计。即抛10次硬币,发现7次硬币正面向上,最大似然估计认为正面向上的概率是0.7。是不是非常直接,非常简单粗暴?没错,就是这样,谁大像谁!
事实上,根据贝叶斯法则,0.7是一个不太可能的取值(如果你知道几乎所有的硬币都是均质的,那么这个实验并没有提供足够的证据来说服你,它是均质的)。但是,0.7却是最大似然估计的取值。
因为这里仅仅试验了一次,得到的样本太少,所以最终求出的最大似然值偏差较大,如果经过多次试验,扩充样本空间,则最终求得的最大似然估计将接近真实值0.5。
似然的数学表达
结果和参数相互对应的时候,似然和概率在数值上是相等的,如果用 $ \boldsymbol{\theta}$ 表示环境对应的参数, X \boldsymbol{X} X 表示结果,那么概率可以表示为:
P ( X ∣ θ ) P(\boldsymbol{X}|\boldsymbol{\theta}) P(X∣θ)
P ( X ∣ θ ) P(\boldsymbol{X}|\boldsymbol{\theta}) P(X∣θ) 是条件概率的表示方法, θ \boldsymbol{\theta} θ 是前置条件,理解为在 θ \boldsymbol{\theta} θ 的前提下,事件 X \boldsymbol{X} X 发生的概率,相对应的似然可以表示为:
L ( θ ∣ X ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X}) L(θ∣X)
可以理解为已知结果为 $ \boldsymbol{X}$ ,参数为 θ \boldsymbol{\theta} θ (似然函数里 θ \boldsymbol{\theta} θ 是变量,这里说的参数和变量是相对与概率而言的)对应的概率,即:
L ( θ ∣ X ) = P ( X ∣ θ ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X})=P(\boldsymbol{X}|\boldsymbol{\theta}) L(θ∣X)=P(X∣θ)
需要说明的是两者在数值上相等,但是意义并不相同, L \mathcal{L} L 是关于 θ \boldsymbol{\theta} θ 的函数,而 P P P 则是关于 X \boldsymbol{X} X 的函数,两者从不同的角度描述一件事情。
从符号上区分似然和概率
似然的符号一般是用 L \mathcal{L} L 来表示,例如 L ( θ ∣ X ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X}) L(θ∣X)。
而概率的符号一般是用 $ P$ 来表示,例如 P ( X ∣ θ ) P(\boldsymbol{X}|\boldsymbol{\theta}) P(X∣θ)。
必须指出的是,虽然似然一般用 L \mathcal{L} L 来表示,但是却能间接使用概率来计算,这也便是上面的公式 L ( θ ∣ X ) = P ( X ∣ θ ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X})=P(\boldsymbol{X}|\boldsymbol{\theta}) L(θ∣X)=P(X∣θ) 了。
最大似然估计(MLE,Maximum Likelihood Estimation)
参考:
最大后验(Maximum a Posteriori,MAP)概率估计详解
最大似然估计就是给定模型,然后通过收集数据,求该模型的参数
最大似然估计是似然函数最初也是最自然的应用。似然函数取得最大值表示相应的参数能够使得统计模型最为合理。
从这样一个想法出发,最大似然估计的做法是:首先选取似然函数(一般是概率密度函数或概率质量函数),整理之后求最大值。
实际应用中一般会取似然函数的对数作为求最大值的函数,这样求出的最大值和直接求最大值得到的结果是相同的。
似然函数的最大值不一定唯一,也不一定存在。
最大似然估计和最大后验估计有一定的相似的地方,对比着学,会有利于学习。
最大似然估计的形式是
arg max θ L ( θ ∣ X ) = arg max θ P ( X ∣ θ ) = arg max θ P ( X 1 ∣ θ ) P ( X 2 ∣ θ ) ⋯ P ( X N ∣ θ ) = arg max θ ∏ i = 1 N P ( X i ∣ θ ) \begin{aligned}\arg\max_{\theta}\mathcal{L}(\theta|X)&=\arg\max_{\theta}{P}\left(X|\theta\right)\\ &=\arg\max_{\theta}{P}(X_1|\theta){P}\left(X_2|\theta\right)\cdots{P}\left(X_N|\theta\right)\\ &=\arg\max_{\theta}\prod\limits_{i=1}^N P\left(X_i|\theta\right)\end{aligned} argθmaxL(θ∣X)=argθmaxP(X∣θ)=argθmaxP(X1∣θ)P(X2∣θ)⋯P(XN∣θ)=argθmaxi=1∏NP(Xi∣θ)
对似然函数取对数,不会影响该函数的单调性,从而不会影响最后的计算的极值,也可以在一定程度上减少因计算而带来的误差,还可以极大的简化计算。 此时求解取对数的似然函数的极大值点,就是似然函数的极大值点。由于似然函数是先单调递增,然后再单调递减的,因此,取对数的似然函数导数为0的点,即是似然函数或取对数的似然函数的极大值点(在这里也是最大值点)
如果未知参数有多个,则需要用取对数的似然函数对每个参数进行求偏导,使得所有偏导均为0的值,即为该函数的极值点,一般也是其最大似然估计值。
最大后验估计(MAP,Maximum A Posteriori Estimation)
最大后验(Maximum A Posteriori,MAP)估计可以利用经验数据获得对未观测量的点态估计。
它与Fisher的最(极)大似然估计(Maximum Likelihood,ML)方法相近,不同的是它扩充了优化的目标函数,其中融合了预估计量的先验分布信息,所以最大后验估计可以看作是正则化(regularized)的最大似然估计。

首先看一下后验概率的公式,根据贝叶斯公式有
P ( θ ∣ X ) = P ( X ∣ θ ) P ( θ ) P ( X ) \mathrm P\left(\theta|X\right)=\frac{\mathrm P\left(X|\theta\right)\mathrm P\left(\theta\right)}{\mathrm P\left(X\right)} P(θ∣X)=P(X)P(X∣θ)P(θ)
其中的 P ( θ ∣ X ) P(\boldsymbol{\theta}|\boldsymbol{X}) P(θ∣X) 表示后验概率,分子上的 P ( X ∣ θ ) P(\boldsymbol{X}|\boldsymbol{\theta}) P(X∣θ) 便是上面的似然,即似然 L ( θ ∣ X ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X}) L(θ∣X),分子上的 P ( θ ) P(\boldsymbol{\theta}) P(θ) 是先验概率,分母则是积分,在进行最大后验估计的时候,会把分母省略,只对分子部分求最大,如下面
arg max θ P ( θ ∣ X ) = arg max θ P ( X ∣ θ ) P ( θ ) \arg\max_{\theta}\operatorname*{P}\left(\theta|\boldsymbol{X}\right)=\arg\max_{\theta}\operatorname*{P}\left(X|\boldsymbol{\theta}\right)\mathrm{P}\left(\theta\right) argθmaxP(θ∣X)=argθmaxP(X∣θ)P(θ)
优化的目标变为了 P ( θ ∣ X ) P(\boldsymbol{\theta}|\boldsymbol{X}) P(θ∣X),即给定了观测值 X \boldsymbol{X} X 以后使模型参数 θ \boldsymbol{\theta} θ 出现的概率最大。
相比最大似然估计方法,最大后验概率考虑了参数 θ \boldsymbol{\theta} θ 的先验概率 P ( θ ) P(\boldsymbol{\theta}) P(θ)。
即就算似然概率 P ( X ∣ θ ) P(\boldsymbol{X}|\boldsymbol{\theta}) P(X∣θ) 很大,但是如果参数 θ \boldsymbol{\theta} θ 出现的概率小,也更倾向于不考虑模型参数为 θ \boldsymbol{\theta} θ。这是二者区别的地方。
理解似然的技巧
似然和后验概率在表示上有类似的地方,似然是用的符号 L \mathcal{L} L,而后验概率使用的是符号 P P P。
把二者放在一起,细品一下。
似然: L ( θ ∣ X ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X}) L(θ∣X)
后验概率: P ( θ ∣ X ) P(\boldsymbol{\theta}|\boldsymbol{X}) P(θ∣X)
但是计算似然的时候,是使用的下面的公式,你再细品一下。
L ( θ ∣ X ) = P ( X ∣ θ ) \mathcal{L}(\boldsymbol{\theta}|\boldsymbol{X})=P(\boldsymbol{X}|\boldsymbol{\theta}) L(θ∣X)=P(X∣θ)
**最大似然估计:**求参数 θ \theta θ , 使似然函数 P ( x ∣ θ ) P(x|\theta) P(x∣θ) 最大。
**最大后验概率估计:**求参数 θ \theta θ ,使 P ( x ∣ θ ) P ( θ ) P(x|\theta)P(\theta) P(x∣θ)P(θ) 最大. 求得的 θ \theta θ 不单单让似然函数大, θ \theta θ 自己出现的先验概率 P ( θ ) P(\theta) P(θ) 也得大。(这有点像正则化里加惩罚项的思想,不过正则化里是利用加法,而MAP里是利用乘法)
MAP其实是在最大化 P ( θ ∣ x ) = P ( x ∣ θ ) P ( θ ) P ( x ) P(\theta|x)=\frac{P(x|\theta)P(\theta)}{P(x)} P(θ∣x)=P(x)P(x∣θ)P(θ),不过因为 x x x 是确定的(即投出的“反正正正正反正正正反”), P ( x ) P(x) P(x) 是一个已知值,所以去掉了分母 P ( x ) P(x) P(x)(假设“投10次硬币”是一次实验,实验做了1000次,“反正正正正反正正正反”出现了n次,则 P ( x ) = n 1000 P(x)=\frac{n}{1000} P(x)=1000n 。总之,这是一个可以由数据集得到的值)。
最大化 P ( θ ∣ x ) P(\theta|x) P(θ∣x) 的意义也很明确, x x x 已经出现了,要求 θ \theta θ 取什么值使 P ( θ ∣ x ) P(\theta|x) P(θ∣x) 最大。顺带一提, P ( θ ∣ x ) P(\theta|x) P(θ∣x) 即后验概率,这就是“最大后验概率估计”名字的由来。
考研笔记节选
下面摘自考研概率论笔记 参数估计 一章


例题
已知某个硬币抛掷落地后正面朝上的概率服从伯努利分布
p ( x = 1 ∣ μ ) ∼ B e r n ( x ∣ μ ) = μ x ( 1 − μ ) ( 1 − x ) p(x=1|\mu)\sim Bern(x|\mu)=\mu^x(1-\mu)^(1-x) p(x=1∣μ)∼Bern(x∣μ)=μx(1−μ)(1−x)
分布参数 μ \mu μ 的先验服从 Beta分布,即
μ ∼ B e t a ( μ ∣ a , b ) = Γ ( a + b ) Γ ( a ) Γ ( b ) μ a − 1 ( 1 − μ ) b − 1 \mu \sim Beta(\mu|a,b)=\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\mu^{a-1}(1-\mu)^{b-1} μ∼Beta(μ∣a,b)=Γ(a)Γ(b)Γ(a+b)μa−1(1−μ)b−1
(1)若观测到一组相互独立硬币抛掷的结果, D = x 1 , ⋯ , x N , x i ∈ { 0 , 1 } , i = 1 , ⋯ , N D={x_1,\cdots,x_N},x_i\in\{0,1\},i=1, \cdots,N D=x1,⋯,xN,xi∈{0,1},i=1,⋯,N。试求参数的极大似然估计 μ M L E \mu_{MLE} μMLE。
(2)若观测 D D D 中有 m m m 个硬币正面朝上,试求参数的最大后验估计 μ M A P \mu_{MAP} μMAP。
解:
概率与似然的关系如下

(1)由最大似然估计可得,关于 μ \mu μ 的似然函数如下
L ( μ ) = p ( D ∣ μ ) = ∏ i = 1 N μ x i ( 1 − μ ) 1 − x i ln ( L ( μ ) ) = ∑ i = 1 N ( ln μ x i + ln ( 1 − μ ) 1 − x i ) = ∑ i = 1 N ( x i ln μ + ( 1 − x i ) ln ( 1 − μ ) ) = ∑ i = 1 N x i ln μ + ( N − ∑ i = 1 N x i ) ln ( 1 − μ ) ∂ ln L ( μ ) ∂ μ = ∑ i = 1 N x i 1 μ − ( N − ∑ i = 1 N x i ) 1 1 − μ = 0 ∑ i = 1 N x i ( 1 − μ ) = ( N − ∑ i = 1 N x i ) μ \begin{aligned} L(\mu)&=p(D|\mu)=\prod_{i=1}^{N}\mu^{x_i}(1-\mu)^{1-x_i} \\\\ \ln(L(\mu))& =\sum_{i=1}^{N}\big(\ln\mu^{x_i}+\ln(1-\mu)^{1-x_i} \big) \\ &=\sum_{i=1}^{N}\big(x_i\ln\mu+(1-x_i)\ln(1-\mu)\big) \\ &=\sum_{i=1}^{N}x_i\ln\mu+(N-\sum_{i=1}^{N}x_i)\ln(1-\mu) \\\\ \frac{\partial \ln L(\mu)}{\partial \mu} &=\sum_{i=1}^{N}x_i\frac{1}{\mu}-(N-\sum_{i=1}^{N}x_i)\frac{1}{1-\mu} =0 \\\\ &\sum_{i=1}^{N}x_i(1-\mu)=(N-\sum_{i=1}^{N}x_i)\mu \end{aligned} L(μ)ln(L(μ))∂μ∂lnL(μ)=p(D∣μ)=i=1∏Nμxi(1−μ)1−xi=i=1∑N(lnμxi+ln(1−μ)1−xi)=i=1∑N(xilnμ+(1−xi)ln(1−μ))=i=1∑Nxilnμ+(N−i=1∑Nxi)ln(1−μ)=i=1∑Nxiμ1−(N−i=1∑Nxi)1−μ1=0i=1∑Nxi(1−μ)=(N−i=1∑Nxi)μ
则可得
∴ μ = 1 N ∑ i = 1 N x i = x ˉ ∴ μ M L E = x ˉ \therefore \mu =\frac{1}{N}\sum_{i=1}^{N}x_i=\bar{x} \\ \therefore \mu_{MLE}=\bar{x} ∴μ=N1i=1∑Nxi=xˉ∴μMLE=xˉ
(2)求MAP
由贝叶斯公式
p ( μ ∣ D ) = p ( μ , D ) p ( D ) = p ( D ∣ μ ) p ( μ ) p ( D ) ∝ p ( D ∣ μ ) p ( μ ) p(\mu|D)=\frac{p(\mu,D)}{p(D)}=\frac{p(D|\mu)p(\mu)}{p(D)}\propto p(D|\mu)p(\mu) p(μ∣D)=p(D)p(μ,D)=p(D)p(D∣μ)p(μ)∝p(D∣μ)p(μ)
令
L ( μ ) = p ( D ∣ μ ) p ( μ ) L(\mu)=p(D|\mu)p(\mu) L(μ)=p(D∣μ)p(μ)
则
μ M A P = arg max μ p ( μ ∣ D ) = arg max μ p ( D ∣ μ ) p ( μ ) = arg max ∏ i = 1 N μ x i ( 1 − μ ) 1 − x i p ( μ ) ln L ( μ ) = ∑ i = 1 N ( ln μ x i ( 1 − μ ) 1 − x i ) ⏟ L 1 ( μ ) + ln p ( μ ) ⏟ L 2 ( μ ) \begin{aligned} \mu_{MAP} &=\arg\max_{\mu}p(\mu|D)=\arg \max_{\mu} p(D|\mu)p(\mu) \\ &=\arg \max \prod_{i=1}^{N}\mu^{x_i}(1-\mu)^{1-x_i}p(\mu) \\\\ \ln L(\mu) &=\underbrace{\sum_{i=1}^{N}\big(\ln \mu^{x_i}(1-\mu)^{1-x_i}\big)}_{L_1(\mu)}+\underbrace{\ln p(\mu)}_{L_2(\mu)} \end{aligned} μMAPlnL(μ)=argμmaxp(μ∣D)=argμmaxp(D∣μ)p(μ)=argmaxi=1∏Nμxi(1−μ)1−xip(μ)=L1(μ)
i=1∑N(lnμxi(1−μ)1−xi)+L2(μ)
lnp(μ)
则
∂ ln ( μ ) ∂ μ = 0 ⇒ μ M A P \frac{\partial\ln(\mu)}{\partial \mu}=0 \quad \Rightarrow \quad \mu_{MAP} ∂μ∂ln(μ)=0⇒μMAP
分别求解
∂ ∂ μ L 1 ( μ ) = ∂ ∂ μ ∑ i = 1 N ( ln μ x i ( 1 − μ ) 1 − x i ) = ∂ ∂ μ ∑ i = 1 N ( x i ln μ + ( 1 − x i ) ln ( 1 − μ ) ) = ∑ i = 1 N x i 1 μ − ∑ i = 1 N ( 1 − x i ) 1 1 − μ = m μ − N − m 1 − μ \begin{aligned} \frac{\partial}{\partial \mu}L_1(\mu) &=\frac{\partial}{\partial \mu}\sum_{i=1}^{N}\big(\ln \mu^{x_i}(1-\mu)^{1-x_i}\big) \\ &=\frac{\partial}{\partial \mu}\sum_{i=1}^{N}\big({x_i}\ln \mu+ ({1-x_i})\ln(1-\mu)\big) \\ &=\sum_{i=1}^{N}{x_i}\frac{1}{\mu}-\sum_{i=1}^{N}{(1-x_i)}\frac{1}{1-\mu} \\ &=\frac{m}{\mu}-\frac{N-m}{1-\mu} \end{aligned} ∂μ∂L1(μ)=∂μ∂i=1∑N(lnμxi(1−μ)1−xi)=∂μ∂i=1∑N(xilnμ+(1−xi)ln(1−μ))=i=1∑Nxiμ1−i=1∑N(1−xi)1−μ1=μm−1−μN−m
其中 m = ∑ i = 1 N x i m=\sum_{i=1}^{N}{x_i} m=∑i=1Nxi
∂ ∂ μ L 2 ( μ ) = ∂ ∂ μ p ( μ ) = ∂ ∂ μ ln ( Γ ( a + b ) Γ ( a ) Γ ( b ) μ a − 1 ( 1 − μ ) b − 1 ) = ∂ ∂ μ ln ( Γ ( a + b ) Γ ( a ) Γ ( b ) ) + ( a − 1 ) ∂ ∂ μ ln μ + ( b − 1 ) ∂ ∂ μ ln ( 1 − μ ) = 0 + a − 1 μ − b − 1 1 − μ \begin{aligned} \frac{\partial}{\partial \mu}L_2(\mu) &=\frac{\partial}{\partial \mu}p(\mu) \\ &=\frac{\partial}{\partial \mu}\ln\big(\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\mu^{a-1}(1-\mu)^{b-1} \big) \\ &=\frac{\partial}{\partial \mu}\ln\big(\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\big)+(a-1)\frac{\partial}{\partial \mu}\ln\mu+(b-1)\frac{\partial}{\partial \mu}\ln(1-\mu) \\ &=0+\frac{a-1}{\mu}-\frac{b-1}{1-\mu} \end{aligned} ∂μ∂L2(μ)=∂μ∂p(μ)=∂μ∂ln(Γ(a)Γ(b)Γ(a+b)μa−1(1−μ)b−1)=∂μ∂ln(Γ(a)Γ(b)Γ(a+b))+(a−1)∂μ∂lnμ+(b−1)∂μ∂ln(1−μ)=0+μa−1−1−μb−1
则
∂ ln L ( μ ) ∂ μ = ∂ ln L 1 ( μ ) ∂ μ + ∂ ln L 2 ( μ ) ∂ μ = ∂ ∑ i = 1 N ( ln μ x i ( 1 − μ ) 1 − x i ) ∂ μ + ∂ ln p ( μ ) ∂ μ = m μ − N − m 1 − μ + a − 1 μ − b − 1 1 − μ = 0 μ M A P = m − a + 1 N + b + a − 2 \begin{aligned} \frac{\partial \ln L(\mu)}{\partial \mu} &=\frac{\partial \ln L_1(\mu)}{\partial \mu}+\frac{\partial \ln L_2(\mu)}{\partial \mu} \\ &=\frac{\partial \sum_{i=1}^{N}\big(\ln \mu^{x_i}(1-\mu)^{1-x_i}\big)}{\partial \mu}+\frac{\partial \ln p(\mu)}{\partial \mu} \\ &=\frac{m}{\mu}-\frac{N-m}{1-\mu}+\frac{a-1}{\mu}-\frac{b-1}{1-\mu} \\ &=0 \\\\ \mu_{MAP} &= \frac{m-a+1}{N+b+a-2} \end{aligned} ∂μ∂lnL(μ)μMAP=∂μ∂lnL1(μ)+∂μ∂lnL2(μ)=∂μ∂∑i=1N(lnμxi(1−μ)1−xi)+∂μ∂lnp(μ)=μm−1−μN−m+μa−1−1−μb−1=0=N+b+a−2m−a+1
比较如下:
μ M L E = x ˉ = m N μ M A P = m − a + 1 N + b + a − 2 \begin{aligned} \mu_{MLE}&=\bar{x}=\frac{m}{N} \\\\ \mu_{MAP} &= \frac{m-a+1}{N+b+a-2} \end{aligned} μMLEμMAP=xˉ=Nm=N+b+a−2m−a+1
其中 m = ∑ i = 1 N x i m=\sum_{i=1}^{N}{x_i} m=∑i=1Nxi
后验估计就是在似然估计的基础上加上了一些由先验模型产生的偏置项
状态估计——观测误差
回顾观测模型,对于某一次观测:
z k , j = h ( y j , x k ) + v k , j \boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_{j},\boldsymbol{x}_{k}\right)+\boldsymbol{v}_{k,j} zk,j=h(yj,xk)+vk,j
由于我们假设了噪声项 v k ∼ N ( 0 , Q k , j ) v_{k}\sim\mathcal{N}\left(\mathbf{0},\boldsymbol{Q}_{k,j}\right) vk∼N(0,Qk,j) ,所以观测数据的条件概率为
P ( z j , k ∣ x k , y j ) = N ( h ( y j , x k ) , Q k , j ) P(\boldsymbol{z}_{j,k}|\boldsymbol{x}_{k},\boldsymbol{y}_{j})=N\left(h(\boldsymbol{y}_{j},\boldsymbol{x}_{k}),\boldsymbol{Q}_{k,j}\right) P(zj,k∣xk,yj)=N(h(yj,xk),Qk,j)
它依然是一个高斯分布。考虑单次观测的最大似然估计,可以使用最小化负对数来求一个高斯分布的最大似然。
我们知道高斯分布在负对数下有较好的数学形式。
考虑任意高维高斯分布 x ∼ N ( μ , Σ ) x\sim\mathcal{N}(\mu,\Sigma) x∼N(μ,Σ),它的概率密度函数展开形式为
P ( x ) = 1 ( 2 π ) N det ( Σ ) exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) . P\left(\boldsymbol{x}\right)=\frac{1}{\sqrt{\left(2\pi\right)^{N}\det\left(\boldsymbol{\Sigma}\right)}}\exp\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}}\boldsymbol{\Sigma}^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}\right)\right). P(x)=(2π)Ndet(Σ)1exp(−21(x−μ)TΣ−1(x−μ)).
对其取负对数,则变为
− ln ( P ( x ) ) = 1 2 ln ( ( 2 π ) N det ( Σ ) ) + 1 2 ( x − μ ) T Σ − 1 ( x − μ ) -\ln\left(P\left(\boldsymbol{x}\right)\right)=\frac{1}{2}\ln\left(\left(2\pi\right)^{N}\det\left(\boldsymbol{\Sigma}\right)\right)+\frac{1}{2}(x-\boldsymbol{\mu})^{T}\boldsymbol{\Sigma}^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}\right) −ln(P(x))=21ln((2π)Ndet(Σ))+21(x−μ)TΣ−1(x−μ)
因为对数函数是单调递增的,所以对原函数求最大化相当于对负对数求最小化。
在最小化上式的 x x x 时,第一项与 x x x 无关,可以略去。
于是,只要最小化右侧的二次型项,就得到了对状态的最大似然估计。代入SLAM的观测模型,相当于在求:
( x k , y j ) ∗ = arg max N ( h ( y j , x k ) , Q k , j ) = arg min ( ( z k , j − h ( x k , y j ) ) T Q k , j − 1 ( z k , j − h ( x k , y j ) ) ) \begin{aligned} (\boldsymbol{x}_k,\boldsymbol{y}_j)^*& =\arg\max\mathcal{N}(h(\boldsymbol{y}_j,\boldsymbol{x}_k),\boldsymbol{Q}_{k,j}) \\ &=\arg\min\left(\left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right)^{\mathrm{T}}\boldsymbol{Q}_{k,j}^{-1}\left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right)\right) \end{aligned} (xk,yj)∗=argmaxN(h(yj,xk),Qk,j)=argmin((zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj)))
我们发现,该式等价于最小化噪声项(即误差)的一个二次型。这个二次型称为马哈拉诺比斯距离(Mahalanobis distance),又叫马氏距离。它也可以看成由 Q k , j − 1 Q^{-1}_{k,j} Qk,j−1 加权之后的欧氏距离(二范数),这里 Q k , j − 1 Q^{-1}_{k,j} Qk,j−1 也叫作信息矩阵,即高斯分布协方差矩阵之逆。
总的来说
(1)先看某次观测:
z k , j = h ( y j , x k ) + v k , j \boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_{j},\boldsymbol{x}_{k}\right)+\boldsymbol{v}_{k,j} zk,j=h(yj,xk)+vk,j
(2)噪声项服从分布:
v k ∼ N ( 0 , Q k , j ) v_{k}\sim\mathcal{N}\left(\mathbf{0},\boldsymbol{Q}_{k,j}\right) vk∼N(0,Qk,j)
(3)观测的概率分布可算:
P ( z j , k ∣ x k , y j ) = N ( h ( y j , x k ) , Q k , j ) P(\boldsymbol{z}_{j,k}|\boldsymbol{x}_{k},\boldsymbol{y}_{j})=N\left(h(\boldsymbol{y}_{j},\boldsymbol{x}_{k}),\boldsymbol{Q}_{k,j}\right) P(zj,k∣xk,yj)=N(h(yj,xk),Qk,j)
(4)多元高斯分布(基础知识)
一元高斯分布, x ∼ N ( μ , σ 2 ) x\sim N(\mu,\sigma^2) x∼N(μ,σ2)
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu)^{2}}{2\sigma^{2}}\right) f(x)=2πσ1exp(−2σ2(x−μ)2)
多元高斯分布 x ∼ N ( μ , Σ ) \boldsymbol{x}\sim\mathcal{N}(\boldsymbol{\mu},\boldsymbol{\Sigma}) x∼N(μ,Σ),均值为 μ \boldsymbol{\mu} μ,协方差矩阵 Σ \Sigma Σ, N N N 为变量维度
P ( x ) = 1 ( 2 π ) N det ( Σ ) exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) P\left(\boldsymbol{x}\right)=\frac{1}{\sqrt{\left(2\pi\right)^{N}\det\left(\boldsymbol{\Sigma}\right)}}\exp\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}}\boldsymbol{\Sigma}^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}\right)\right) P(x)=(2π)Ndet(Σ)1exp(−21(x−μ)TΣ−1(x−μ))
注意:虽然这里协方差矩阵 Σ \Sigma Σ 没有带平方,但是其中的元素都是二阶的,其主对角线上的元素为方差,其他位置为协方差,且 Σ \Sigma Σ 为对称阵
-
方差、协方差、协方差矩阵基本知识:
-
《机器人学中的状态估计》
-
《概率机器人》
关于多元高斯分布,可见:
对概率密度函数取负对数(仅第二项与 P ( x ) P(x) P(x) 直接相关)
− ln ( P ( x ) ) = 1 2 ln ( ( 2 π ) N det ( Σ ) ) + 1 2 ( x − μ ) T Σ − 1 ( x − μ ) -\ln\left(P\left(\boldsymbol{x}\right)\right)=\frac{1}{2}\ln\left(\left(2\pi\right)^{N}\det\left(\boldsymbol{\Sigma}\right)\right)+\frac{1}{2}(x-\boldsymbol{\mu})^{T}\boldsymbol{\Sigma}^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}\right) −ln(P(x))=21ln((2π)Ndet(Σ))+21(x−μ)TΣ−1(x−μ)
(5)这里的 Q Q Q 就是协方差矩阵, Q − 1 Q^{-1} Q−1 也叫信息矩阵
( x k , y j ) ∗ = arg max N ( h ( y j , x k ) , Q k , j ) = arg min ( ( z k , j − h ( x k , y j ) ) T Q k , j − 1 ( z k , j − h ( x k , y j ) ) ) \begin{aligned} (\boldsymbol{x}_k,\boldsymbol{y}_j)^*& =\arg\max\mathcal{N}(h(\boldsymbol{y}_j,\boldsymbol{x}_k),\boldsymbol{Q}_{k,j}) \\ &=\arg\min\left(\left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right)^{\mathrm{T}}\boldsymbol{Q}_{k,j}^{-1}\left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right)\right) \end{aligned} (xk,yj)∗=argmaxN(h(yj,xk),Qk,j)=argmin((zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj)))
其中 z k , j \boldsymbol{z}_{k,j} zk,j 为实际观测量, h ( x k , y j ) h(\boldsymbol{x}_k,\boldsymbol{y}_j) h(xk,yj) 为估计观测量,它们的差值为误差
这个二次型可以看成信息矩阵加权之后的二范数
考虑噪声加权的误差二次型
( z k , j − h ( x k , y j ) ) T Q k , j − 1 ( z k , j − h ( x k , y j ) ) \left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right)^{\mathrm{T}}\boldsymbol{Q}_{k,j}^{-1}\left(\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_k,\boldsymbol{y}_j\right)\right) (zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj))
例如:
Q = [ σ 11 σ 12 σ 21 σ 22 ] , Q − 1 = [ k 11 k 12 k 21 k 22 ] Q= \left[ \begin{matrix} \sigma_{11}&\sigma_{12}\\ \sigma_{21}&\sigma_{22} \end{matrix} \right] , Q^{-1}= \left[ \begin{matrix} k_{11}&k_{12}\\ k_{21}&k_{22} \end{matrix} \right] Q=[σ11σ21σ12σ22],Q−1=[k11k21k12k22]
( z − μ ) T Q − 1 ( z − μ ) = [ x 1 , x 2 ] [ k 11 k 12 k 21 k 22 ] [ x 1 x 2 ] = [ k 11 x 1 + k 21 x 2 , k 12 x 1 + k 22 x 2 ] [ x 1 x 2 ] = k 11 x 1 2 + k 21 x 1 x 2 + k 12 x 1 x 2 + k 22 x 2 2 \begin{aligned} &(z-\mu)^TQ^{-1}(z-\mu) \\ &= [x_1,x_2] \left[ \begin{matrix} k_{11}&k_{12}\\ k_{21}&k_{22} \end{matrix} \right] \left[ \begin{matrix} x_1\\x_2 \end{matrix} \right] \\ &= [k_{11}x_1+k_{21}x_2,k_{12}x_1+k_{22}x_2] \left[ \begin{matrix} x_1\\x_2 \end{matrix} \right] \\ &= k_{11}x_1^2+k_{21}x_1x_2+k_{12}x_1x_2+k_{22}x_2^2 \end{aligned} (z−μ)TQ−1(z−μ)=[x1,x2][k11k21k12k22][x1x2]=[k11x1+k21x2,k12x1+k22x2][x1x2]=k11x12+k21x1x2+k12x1x2+k22x22
可以令
c o s t = k 11 x 1 2 + k 21 x 1 x 2 + k 12 x 1 x 2 + k 22 x 2 2 cost=k_{11}x_1^2+k_{21}x_1x_2+k_{12}x_1x_2+k_{22}x_2^2 cost=k11x12+k21x1x2+k12x1x2+k22x22
可以把 x 1 2 x_1^2 x12 看成 c o s t 1 cost_1 cost1, x 1 x 2 x_1x_2 x1x2 看成 c o s t 2 cost_2 cost2,他们前面的系数可以看成可信度,或者噪声的倒数。简单来讲就是如果这个数据约可信,那么就要把它前面的数据放大些
矩阵 Q Q Q 中的元素越大, Q − 1 Q^{-1} Q−1 中的元素越小
(6)概率估计状态,重点把握 均值和方差 的传递
状态估计——批量数据
现在我们考虑批量时刻的数据。通常假设各个时刻的输入和观测是相互独立的,这意味着各个输入之间是独立的,各个观测之间是独立的,并且输入和观测也是独立的。于是我们可以对联合分布进行因式分解:
P ( z , u ∣ x , y ) = ∏ k P ( u k ∣ x k − 1 , x k ) ∏ k , j P ( z k , j ∣ x k , y j ) , P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right)=\prod_{k}P\left(\boldsymbol{u}_{k}|\boldsymbol{x}_{k-1},\boldsymbol{x}_{k}\right)\prod_{k,j}P\left(\boldsymbol{z}_{k,j}|\boldsymbol{x}_{k},\boldsymbol{y}_{j}\right), P(z,u∣x,y)=k∏P(uk∣xk−1,xk)k,j∏P(zk,j∣xk,yj),
这说明我们可以独立地处理各时刻的运动和观测。定义各次输入和观测数据与模型之间的误差:
e u , k = x k − f ( x k − 1 , u k ) e z , j , k = z k , j − h ( x k , y j ) , \begin{gathered} e_{\boldsymbol{u},k} =\boldsymbol{x}_k-f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k\right) \\\\ e_{z,j,k} =\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_{k},\boldsymbol{y}_{j}\right), \end{gathered} eu,k=xk−f(xk−1,uk)ez,j,k=zk,j−h(xk,yj),
那么,最小化所有时刻估计值与真实读数之间的马氏距离,等价于求最大似然估计。负对数允许我们把乘积变成求和:
min J ( x , y ) = ∑ k e u , k T R k − 1 e u , k + ∑ k ∑ j e z , k , j T Q k , j − 1 e z , k , j . \min J(\boldsymbol{x},\boldsymbol{y})=\sum_k\boldsymbol{e}_{\boldsymbol{u},k}^T\boldsymbol{R}_k^{-1}\boldsymbol{e}_{\boldsymbol{u},k}+\sum_k\sum_j\boldsymbol{e}_{\boldsymbol{z},k,j}^T\boldsymbol{Q}_{k,j}^{-1}\boldsymbol{e}_{\boldsymbol{z},k,j}. minJ(x,y)=k∑eu,kTRk−1eu,k+k∑j∑ez,k,jTQk,j−1ez,k,j.
这样就得到了一个最小二乘问题(Least Square Problem),它的解等价于状态的最大似然估计。
直观上看,由于噪声的存在,当我们把估计的轨迹与地图代入SLAM的运动、观测方程中时,它们并不会完美地成立。这时怎么办呢?我们对状态的估计值进行微调,使得整体的误差下降一些。当然,这个下降也有限度,它一般会到达一个极小值。这就是一个典型的非线性优化的过程。
总的来说
经典SLAM模型由一个运动方程和一个观测方程构成
{ x k = f ( x k − 1 , u k ) + w k z k , j = h ( y j , x k ) + v k , j \begin{cases}\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k\right)+\boldsymbol{w}_k\\ \boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_j,\boldsymbol{x}_k\right)+\boldsymbol{v}_{k,j}\end{cases} {xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j
在已知观测量 z z z 和控制量 u u u 的情况下,去估计最大情况下可能出现的机器人的位姿 x x x 和其看到的路标点坐标 y y y,即求
( x , y ) M A P ∗ = arg max P ( x , y ∣ z , u ) (\boldsymbol{x},\boldsymbol{y})^*_{M A P}=\arg\max P(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u}) (x,y)MAP∗=argmaxP(x,y∣z,u)
问题在于这个问题不好求解
但是可以转化为
P ( x , y ∣ z , u ) = P ( z , u ∣ x , y ) P ( x , y ) P ( z , u ) ∝ P ( z , u ∣ x , y ) ⏟ 似然 P ( x , y ) ⏟ 先验 P\left(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z},\boldsymbol{u}\right)=\frac{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right) P\left(\boldsymbol{x},\boldsymbol{y}\right)} {P\left(\boldsymbol{z},\boldsymbol{u}\right)} \propto \underbrace{P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{似然}}\underbrace{P\left(\boldsymbol{x},\boldsymbol{y}\right)}_{\mathfrak{先验}} P(x,y∣z,u)=P(z,u)P(z,u∣x,y)P(x,y)∝似然
P(z,u∣x,y)先验
P(x,y)
即可以转化为求
( x , y ) MLE ∗ = arg max P ( z , u ∣ x , y ) (x,y)^*_{\text{MLE}}=\arg\max P(z,u|x,y) (x,y)MLE∗=argmaxP(z,u∣x,y)
我们引入一个假设,机器人在各个时刻的观测是相互独立的,各个时刻的输入量也是独立的,且 z z z 和 u u u 也是独立的, z 1 , z 2 , ⋯ , z n z_1,z_2,\cdots,z_n z1,z2,⋯,zn 之间也是独立的
这时
P ( z ⃗ , u ⃗ ∣ x ⃗ , y ⃗ ) = P ( z ⃗ ∣ x ⃗ , y ⃗ ) ⋅ P ( u ⃗ ∣ x ⃗ , y ⃗ ) = ∏ k , j P ( z k , j ∣ x k , y j ) ∏ k P ( u k ∣ x k − 1 , x k ) \begin{aligned} &P(\vec{z},\vec{u}|\vec{x},\vec{y}) \\\\ &=P(\vec{z}|\vec{x},\vec{y})\cdot P(\vec{u}|\vec{x},\vec{y}) \\\\ &=\prod_{k,j}P\left(\boldsymbol{z}_{k,j}|\boldsymbol{x}_{k},\boldsymbol{y}_{j}\right)\prod_{k}P\left(\boldsymbol{u}_{k}|\boldsymbol{x}_{k-1},\boldsymbol{x}_{k}\right) \end{aligned} P(z,u∣x,y)=P(z∣x,y)⋅P(u∣x,y)=k,j∏P(zk,j∣xk,yj)k∏P(uk∣xk−1,xk)
(1)假设各个时刻的输入和观测是独立的,可以分解成多个概率的乘积
P ( z , u ∣ x , y ) = ∏ k P ( u k ∣ x k − 1 , x k ) ∏ k , j P ( z k , j ∣ x k , y j ) P\left(\boldsymbol{z},\boldsymbol{u}|\boldsymbol{x},\boldsymbol{y}\right)=\prod_{k}P\left(\boldsymbol{u}_{k}|\boldsymbol{x}_{k-1},\boldsymbol{x}_{k}\right)\prod_{k,j}P\left(\boldsymbol{z}_{k,j}|\boldsymbol{x}_{k},\boldsymbol{y}_{j}\right) P(z,u∣x,y)=k∏P(uk∣xk−1,xk)k,j∏P(zk,j∣xk,yj)
(2)定义运动和观测误差
e u , k = x k − f ( x k − 1 , u k ) e z , j , k = z k , j − h ( x k , y j ) , \begin{gathered} e_{\boldsymbol{u},k} =\boldsymbol{x}_k-f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k\right) \\\\ e_{z,j,k} =\boldsymbol{z}_{k,j}-h\left(\boldsymbol{x}_{k},\boldsymbol{y}_{j}\right), \end{gathered} eu,k=xk−f(xk−1,uk)ez,j,k=zk,j−h(xk,yj),
(3)将 x , y x,y x,y 作为优化变量,将输入误差 和 观测误差之和 作为目标函数,求当误差最小时的 x , y x,y x,y
min J ( x , y ) = ∑ k e u , k T R k − 1 e u , k + ∑ k ∑ j e z , k , j T Q k , j − 1 e z , k , j . \min J(\boldsymbol{x},\boldsymbol{y})=\sum_k\boldsymbol{e}_{\boldsymbol{u},k}^T\boldsymbol{R}_k^{-1}\boldsymbol{e}_{\boldsymbol{u},k}+\sum_k\sum_j\boldsymbol{e}_{\boldsymbol{z},k,j}^T\boldsymbol{Q}_{k,j}^{-1}\boldsymbol{e}_{\boldsymbol{z},k,j}. minJ(x,y)=k∑eu,kTRk−1eu,k+k∑j∑ez,k,jTQk,j−1ez,k,j.
- 这个就是最小二乘问题
- 它的解就等价于 x , y x,y x,y 的最大似然估计,即求 ( x , y ) M L E (x,y)_{MLE} (x,y)MLE
这个问题的特点
仔细观察式
min J ( x , y ) = ∑ k e u , k T R k − 1 e u , k + ∑ k ∑ j e z , k , j T Q k , j − 1 e z , k , j \min J(\boldsymbol{x},\boldsymbol{y})=\sum_k\boldsymbol{e}_{\boldsymbol{u},k}^T\boldsymbol{R}_k^{-1}\boldsymbol{e}_{\boldsymbol{u},k}+\sum_k\sum_j\boldsymbol{e}_{\boldsymbol{z},k,j}^T\boldsymbol{Q}_{k,j}^{-1}\boldsymbol{e}_{\boldsymbol{z},k,j} minJ(x,y)=k∑eu,kTRk−1eu,k+k∑j∑ez,k,jTQk,j−1ez,k,j
我们发现SLAM中的最小二乘问题具有一些特定的结构:
-
首先,整个问题的目标函数由许多个误差的(加权的)二次型组成。虽然总体的状态变量维数很高,但每个误差项都是简单的,仅与一两个状态变量有关。例如,运动误差只与 x k − 1 , x k x_{k-1},x_{k} xk−1,xk 有关,观测误差只与 x k , y j x_k,y_j xk,yj 有关。这种关系会让整个问题有一种稀疏的形式,我们将在介绍后端的章节中看到。
-
其次,如果使用李代数表示增量,则该问题是无约束的最小二乘问题。但如果用旋转矩阵/变换矩阵描述位姿,则会引入旋转矩阵自身的约束,即需在问题中加入 s . t . R T R = I s.t. R^TR=I s.t.RTR=I 且 det ( R ) = 1 \det(R)=1 det(R)=1 这样令人头大的条件。额外的约束会使优化变得更困难。这体现了李代数的优势。
-
最后,我们使用了二次型度量误差。误差的分布将影响此项在整个问题中的权重。例如,某次的观测非常准确,那么协方差矩阵就会“小”,而信息矩阵就会“大”,所以这个误差项会在整个问题中占有较高的权重。我们之后也会看到它存在一些问题,但是目前先不讨论。
一个例子
考虑一个非常简单的离散时间系统:
x k = x k − 1 + u k + w k , w k ∼ N ( 0 , Q k ) z k = x k + n k , n k ∼ N ( 0 , R k ) \begin{aligned}x_k&=x_{k-1}+u_k+\boldsymbol{w}_k,\quad&\boldsymbol{w}_k\sim\mathcal{N}\left(0,\boldsymbol{Q}_k\right)\\\boldsymbol{z}_k&=\boldsymbol{x}_k+\boldsymbol{n}_k,\quad&\boldsymbol{n}_k\sim\mathcal{N}\left(0,\boldsymbol{R}_k\right)\end{aligned} xkzk=xk−1+uk+wk,=xk+nk,wk∼N(0,Qk)nk∼N(0,Rk)
这可以表达一辆沿 x x x 轴前进或后退的汽车。第一个公式为运动方程, u k u_k uk 为输入, w k w_k wk 为噪声;第二个公式为观测方程, z k z_k zk 为对汽车位置的测量。取时间 k = 1 , ⋯ , 3 k=1,\cdots,3 k=1,⋯,3,现希望根据已有的 v , y v,y v,y 进行状态估计。设初始状态 x 0 x_0 x0 已知。
下面来推导批量状态的最大似然估计。
首先,令批量状态变量为 x = [ x 0 , x 1 , x 2 , x 3 ] T x=[x_0,x_1,x_2,x_3]^T x=[x0,x1,x2,x3]T ,令批量观测为 z = [ z 1 , z 2 , z 3 ] T z=[z_1,z_2,z_3]^T z=[z1,z2,z3]T,按同样方式定义 u = [ u 1 , u 2 , u 3 ] T u=[u_1,u_2,u_3]^T u=[u1,u2,u3]T。按照先前的推导,我们知道最大似然估计为
x m a p ∗ = arg max P ( x ∣ u , z ) = arg max P ( u , z ∣ x ) = ∏ k = 1 3 P ( u k ∣ x k − 1 , x k ) ∏ k = 1 3 P ( z k ∣ x k ) , \begin{gathered} x_{\mathrm{map}}^* =\arg\max P(\boldsymbol{x}|\boldsymbol{u},\boldsymbol{z})=\arg\max P(\boldsymbol{u},\boldsymbol{z}|\boldsymbol{x}) \\ =\prod_{k=1}^3P(\boldsymbol{u}_k|\boldsymbol{x}_{k-1},\boldsymbol{x}_k)\prod_{k=1}^3P\left(\boldsymbol{z}_k|\boldsymbol{x}_k\right), \end{gathered} xmap∗=argmaxP(x∣u,z)=argmaxP(u,z∣x)=k=1∏3P(uk∣xk−1,xk)k=1∏3P(zk∣xk),
注意:
一般情况下
arg max P ( x ∣ u , z ) ≈ arg max P ( u , z ∣ x ) \arg\max P(\boldsymbol{x}|\boldsymbol{u},\boldsymbol{z}) \approx \arg\max P(\boldsymbol{u},\boldsymbol{z}|\boldsymbol{x}) argmaxP(x∣u,z)≈argmaxP(u,z∣x)
但是这里由于系统的状态方程比较简单,这里确实是等价的,所以用等于号
对于具体的每一项,比如运动方程,我们知道:
P ( u k ∣ x k − 1 , x k ) = N ( x k − x k − 1 , Q k ) , P(\boldsymbol{u}_k|\boldsymbol{x}_{k-1},\boldsymbol{x}_k)=\mathcal{N}(\boldsymbol{x}_k-\boldsymbol{x}_{k-1},\boldsymbol{Q}_k), P(uk∣xk−1,xk)=N(xk−xk−1,Qk),
观测方程也是类似的:
P ( z k ∣ x k ) = N ( x k , R k ) . P\left(\boldsymbol{z}_{k}|\boldsymbol{x}_{k}\right)=\mathcal{N}\left(\boldsymbol{x}_{k},\boldsymbol{R}_{k}\right). P(zk∣xk)=N(xk,Rk).
根据这些方法,我们就能够实际地解决上面的批量状态估计问题。根据之前的叙述,可以构建误差变量:
e u , k = x k − x k − 1 − u k , e z , k = z k − x k , e_{\boldsymbol{u},k}=\boldsymbol{x}_k-\boldsymbol{x}_{k-1}-\boldsymbol{u}_k,\quad\boldsymbol{e}_{z,k}=\boldsymbol{z}_k-\boldsymbol{x}_k, eu,k=xk−xk−1−uk,ez,k=zk−xk,
于是最小二乘的目标函数为
min ∑ k = 1 3 e u , k ⊺ Q k − 1 e u , k + ∑ k = 1 3 e z , k ⊺ R k − 1 e z , k . \min\sum_{k=1}^3e_{\boldsymbol{u},k}^\intercal Q_{k}^{-1}e_{\boldsymbol{u},k}+\sum_{k=1}^3e_{\boldsymbol{z},k}^\intercal R_{k}^{-1}e_{z,k}. mink=1∑3eu,k⊺Qk−1eu,k+k=1∑3ez,k⊺Rk−1ez,k.
此外,这个系统是线性系统,我们可以很容易地将它写成向量形式。定义向量 y = [ u , z ] T y=[u,z]^T y=[u,z]T,那么可以写出矩阵 H H H,使得
y − H x = e ∼ N ( 0 , Σ ) y-Hx=e\sim\mathcal{N}(\mathbf{0},\mathbf{\Sigma}) y−Hx=e∼N(0,Σ)
即
[ u 1 u 2 u 3 z 1 z 2 z 3 ] − H [ x 0 x 1 x 2 x 3 ] = [ e u 1 e u 2 e u 3 e z 1 e z 2 e z 3 ] \left[ \begin{matrix} u_1\\u_2\\u_3\\z_1\\z_2\\z_3 \end{matrix}\right]- H \left[ \begin{matrix} x_0\\x_1\\x_2\\x_3 \end{matrix}\right]= \left[ \begin{matrix} e_{u_1}\\e_{u_2}\\e_{u_3}\\e_{z_1}\\e_{z_2}\\e_{z_3} \end{matrix} \right]
u1u2u3z1z2z3
−H
x0x1x2x3
=
eu1eu2eu3ez1ez2ez3
那么:
H = [ 1 − 1 0 0 0 1 − 1 0 0 0 1 − 1 0 1 0 0 0 0 1 0 0 0 0 1 ] , H=\begin{bmatrix}1&-1&0&0\\0&1&-1&0\\0&0&1&-1\\\hline0&1&0&0\\0&0&1&0\\0&0&0&1\end{bmatrix}, H=
100000−1101000−1101000−1001
,
且 Σ = d i a g ( Q 1 , Q 2 , Q 3 , R 1 , R 2 , R 3 ) \mathbf{\Sigma}=\mathrm{diag}(\mathbf{Q}_{1},\mathbf{Q}_{2},\mathbf{Q}_{3},\mathbf{R}_{1},\mathbf{R}_{2},\mathbf{R}_{3}) Σ=diag(Q1,Q2,Q3,R1,R2,R3)。整个问题可以写成
x m a p ∗ = arg min e T Σ − 1 e , x_{\mathrm{map}}^*=\arg\min e^T\Sigma^{-1}e, xmap∗=argmineTΣ−1e,
之后我们将看到,这个问题有唯一的解:
x m a p ∗ = ( H T Σ − 1 H ) − 1 H T Σ − 1 y . x_{\mathrm{map}}^{*}=(H^{\mathrm{T}}\Sigma^{-1}H)^{-1}H^{\mathrm{T}}\Sigma^{-1}y. xmap∗=(HTΣ−1H)−1HTΣ−1y.
求解这样的导数,规律+查表,可以解决大部分的问题
规律+查表求导:https://en.wikipedia.org/wiki/Matrix_calculus
一般情况下使用分母布局(Denominator Layout)

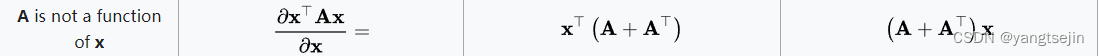
f = ( y − H x ) T Σ − 1 ( y − H x ) ∂ f ∂ x = ∂ ( y − H x ) ∂ x ⋅ ∂ f ∂ ( y − H x ) = − ∂ ( H x ) ∂ x ⋅ ∂ f ∂ ( y − H x ) = − H T ⋅ 2 ⋅ Σ − 1 ( y − H x ) = 0 \begin{aligned} f&=(y-Hx)^T\Sigma^{-1}(y-Hx) \\\\ \frac{\partial f}{\partial x}&= \frac{\partial (y-Hx)}{\partial x}\cdot \frac{\partial f}{\partial (y-Hx)} \\\\ &= -\frac{\partial (Hx)}{\partial x}\cdot \frac{\partial f}{\partial (y-Hx)} \\\\ &=-H^T \cdot 2\cdot \Sigma^{-1}(y-Hx) \\\\ &=0 \end{aligned} f∂x∂f=(y−Hx)TΣ−1(y−Hx)=∂x∂(y−Hx)⋅∂(y−Hx)∂f=−∂x∂(Hx)⋅∂(y−Hx)∂f=−HT⋅2⋅Σ−1(y−Hx)=0
即求解
H T ⋅ Σ − 1 ( y − H x ) = 0 H^T \cdot \Sigma^{-1}(y-Hx)=0 HT⋅Σ−1(y−Hx)=0
则
H T ⋅ Σ − 1 ⋅ y = H T ⋅ Σ − 1 H x ( H T ⋅ Σ − 1 ⋅ H ) − 1 H T ⋅ Σ − 1 ⋅ y = x M A P ∗ x M A P ∗ = ( H T Σ − 1 H ) − 1 H T Σ − 1 y \begin{aligned} &H^T \cdot \Sigma^{-1} \cdot y=H^T \cdot \Sigma^{-1} Hx \\\\ &(H^T \cdot \Sigma^{-1} \cdot H)^{-1}H^T \cdot \Sigma^{-1} \cdot y=x^*_{MAP} \\\\ &x_{\mathrm{MAP}}^{*}=(H^{\mathrm{T}}\Sigma^{-1}H)^{-1}H^{\mathrm{T}}\Sigma^{-1}y \end{aligned} HT⋅Σ−1⋅y=HT⋅Σ−1Hx(HT⋅Σ−1⋅H)−1HT⋅Σ−1⋅y=xMAP∗xMAP∗=(HTΣ−1H)−1HTΣ−1y

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)