探索AI系统在视觉软件领域的泛化能力:SWE-Bench Multimodal基准研究
SWE-Bench M的发布为AI系统在视觉软件领域的研究提供了重要的基准,揭示了现有技术的局限性,也为未来的研究提供了清晰的方向。随着AI技术的不断进步,我们有理由相信,未来的AI系统将不仅能够处理文本代码,还能在复杂的视觉软件开发任务中成为工程师的得力助手,推动软件工程领域的创新与发展。该研究的代码、数据和排行榜已公开,感兴趣的研究者可以访问swebench.com/multimodal获取更
探索AI系统在视觉软件领域的泛化能力:SWE-Bench Multimodal基准研究
在当今人工智能与软件工程快速融合的时代,评估AI系统在实际软件开发任务中的表现变得尤为重要。近日,来自斯坦福大学、普林斯顿大学等机构的研究团队发布了一篇名为《SWE-BENCH MULTIMODAL: DO AI SYSTEMS GENERALIZE TO VISUAL SOFTWARE DOMAINS?》的论文,提出了一个全新的基准测试——SWE-Bench Multimodal(SWE-Bench M),旨在评估AI系统在处理包含视觉元素的软件开发任务时的泛化能力。
研究背景:现有基准的局限性
当前主流的软件工程AI系统评估基准SWE-bench虽然在评估AI解决Python代码问题方面发挥了重要作用,但它存在两个显著局限性:一是仅支持Python语言,无法覆盖前端开发、游戏开发等更广泛的软件领域;二是任务描述以文本为主,缺乏视觉元素,而现实中许多软件开发任务(如用户界面设计、数据可视化等)都离不开图像或视频等视觉信息。
数据显示,SWE-bench中仅有5.6%的任务包含图像,这与实际软件开发中视觉内容的重要性严重不符。随着JavaScript等语言在前端开发和交互式应用中的广泛使用,开发一个能够评估AI系统在视觉软件领域能力的基准变得迫切。
SWE-Bench M:多模态视觉软件开发基准
数据收集与特点
SWE-Bench M从17个JavaScript库中收集了617个任务实例,这些库涵盖了网页界面设计、图表绘制、数据可视化、语法高亮和交互式地图等多个领域。每个任务实例的问题描述或单元测试中至少包含一张图片,确保了任务的多模态特性。
研究团队通过GitHub搜索星标数超过5000且拉取请求数超过500的JavaScript库,筛选出具有视觉元素的问题,并经过严格的环境搭建、测试一致性检查和人工验证,最终形成了这个高质量的基准数据集。

多模态挑战与任务多样性
SWE-Bench M中的图像类型丰富多样,主要包括以下几类:
- 网页界面截图(401张):展示前端布局缺陷或可访问性问题
- 代码片段截图(194张):用于定位语法高亮或代码逻辑错误
- 图表与数据可视化(107张):呈现统计图表或地理信息可视化问题
- 错误消息截图(54张):显示程序运行时的异常信息
- 艺术与创意编程图像(38张):反映创意编码中的视觉效果问题
此外,221个任务包含多张图片,70个任务包含视频,69个任务采用像素级视觉测试来验证解决方案的正确性。人工标注显示,83.5%的任务实例中图像是解决问题的关键,无法仅通过文本描述完成任务。
实验结果:现有AI系统的表现与挑战
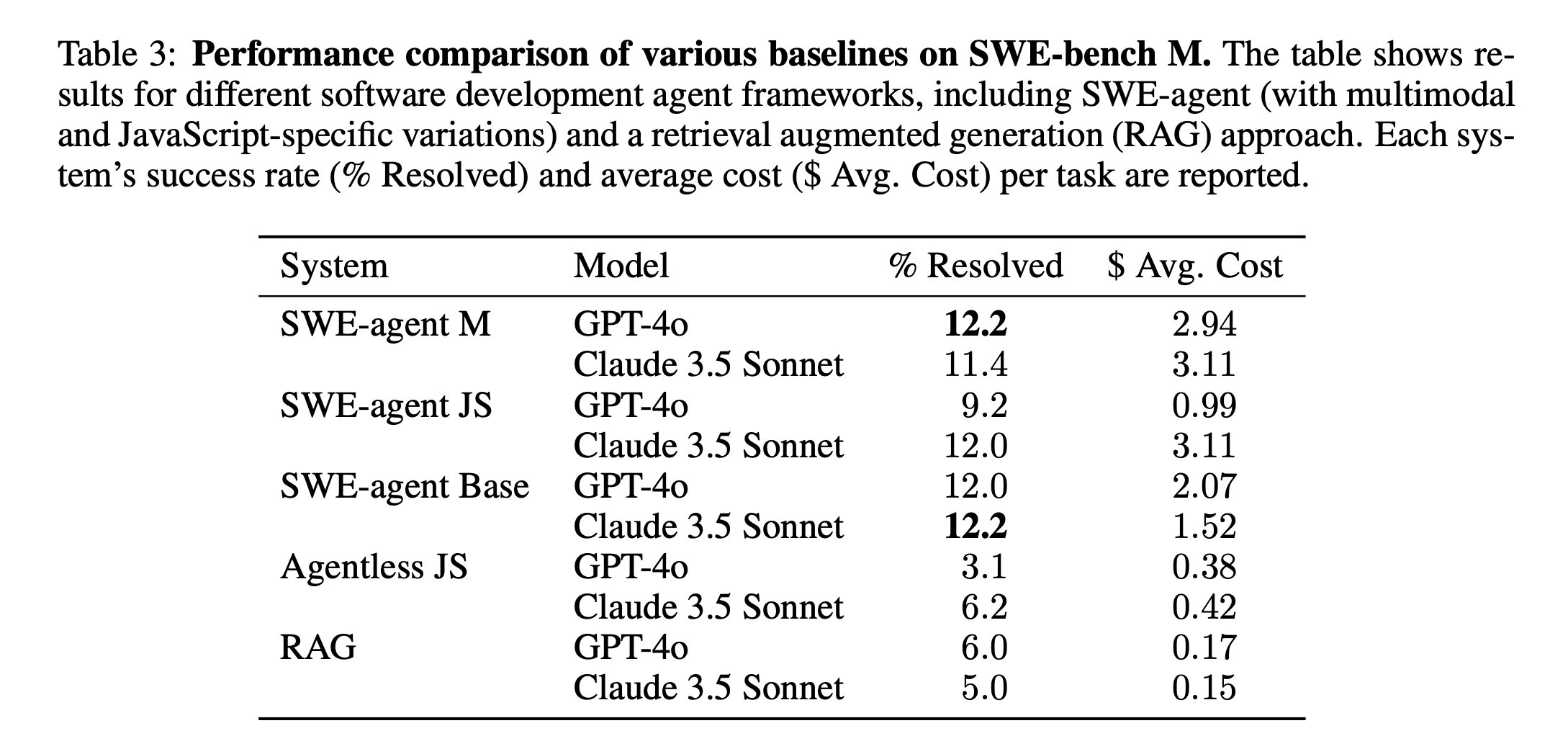
研究团队对多个现有AI系统在SWE-Bench M上的表现进行了评估,主要包括SWE-agent、Agentless、AutoCodeRover、Moatless和RAG等系统。实验结果显示,现有系统在SWE-Bench M上的表现普遍不佳,最高解决率仅为12.2%(SWE-agent M使用GPT-4o模型),而次优系统的解决率仅为6%。
关键发现
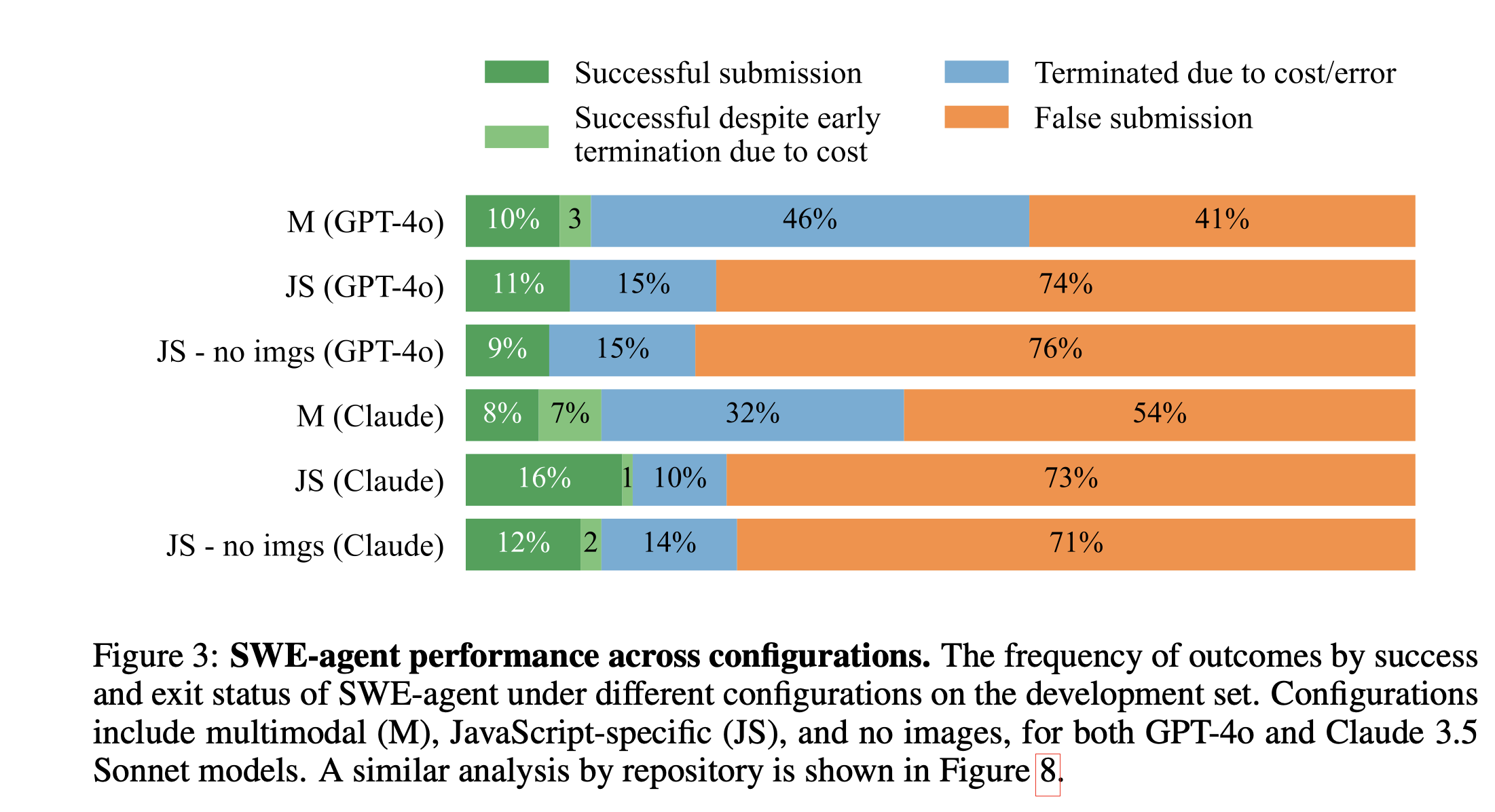
- 视觉理解能力不足:当模型无法访问图像时,解决率显著下降。例如,SWE-agent JS在有图像时解决率为11.0%,无图像时降至8.0%。对于非文本视觉元素,性能下降更为明显。
-
跨语言泛化困难:现有系统大多针对Python设计,缺乏对JavaScript等语言的原生支持。例如,Agentless系统需要从头开发JavaScript解析器,但其解决率仍仅为4.6%。
-
任务复杂性影响:SWE-Bench M任务的平均难度高于SWE-bench,13%的任务需要不到15分钟解决,而6%的任务需要超过4小时,这对AI系统的长期推理能力提出了更高要求。
-
交互方式的重要性:SWE-agent通过灵活的人机交互界面,允许模型与环境进行多轮交互,其表现显著优于非交互式系统(如RAG),表明交互能力是提升AI系统在复杂任务中表现的关键。
SWE-agent:迈向更通用的AI软件开发助手
在所有评估的系统中,SWE-agent表现最为突出。研究团队对SWE-agent进行了三次重要升级:
- SWE-agent Base:原始版本,主要用于Python任务
- SWE-agent JS:增加JavaScript特定的语法检查和错误检测功能
- SWE-agent M:进一步集成网页浏览、截图和图像查看功能,支持多模态交互
实验表明,SWE-agent M在处理需要视觉验证的任务时表现最佳,其成功解决的任务中,38.3%需要生成和查看网页截图,平均每个任务需要7.5次截图操作。这表明,赋予AI系统与视觉环境交互的能力可以显著提升其解决复杂问题的能力。
未来展望:构建更通用的AI软件开发系统
SWE-Bench M的提出揭示了当前AI系统在视觉软件领域的不足,也为未来的研究指明了方向:
-
多模态模型的发展:需要开发能够同时理解文本和视觉信息的AI模型,特别是在代码上下文与视觉元素之间建立关联的能力。
-
语言无关的架构设计:现有系统过度依赖特定语言的解析工具,未来需要构建更通用的、与语言无关的AI架构。
-
增强交互与环境感知:AI系统应具备更强的环境交互能力,能够主动探索和验证解决方案,尤其是在视觉界面的上下文中。
-
扩展基准范围:未来的基准可以进一步扩展到更多编程语言、更多模态(如音频、3D模型)和更多软件开发场景。
分析:图像在任务中扮演的重要的角色,
1、提供关键视觉信息,辅助问题理解与定位
-
直观呈现软件缺陷
图像(如网页截图、界面布局图)能直接展示前端组件的视觉异常(如元素错位、颜色错误),或代码语法高亮错误(如关键字颜色显示异常)。例如:- 在UI设计相关任务中,图像可明确显示按钮尺寸不符、文本溢出等布局问题。
- 在语法高亮库任务中,代码截图能直观呈现引号、注释等语法元素的错误着色。
-
定位代码问题上下文
代码截图或错误信息截图可帮助定位代码库中的具体问题区域。例如:- 错误消息截图能显示运行时异常的堆栈跟踪或错误提示,辅助快速定位bug位置。
- 代码片段截图可标注出需要修改的函数或变量,减少代码搜索成本。
2、作为任务解决的必要条件,无法被文本替代
-
视觉信息的不可替代性
研究通过人工标注发现,83.5%的任务实例中,图像是解决问题的必要条件。例如:- 数据可视化任务中,图表截图能展示坐标轴标签缺失、数据点错误等问题,而文本描述难以准确传达空间关系和视觉偏差。
- 交互式地图任务中,图像可显示标记点位置错误或图层叠加异常,这些信息无法仅通过文本描述复现。
-
多模态信息互补性
图像与文本结合能更完整地描述任务需求。例如:- 问题描述中,文本可能说明“图表渲染异常”,而图像则具体展示柱状图宽度不一致、颜色分配错误等细节。
- 测试用例中的“预期-实际”图像对比(如Carbon库任务),可明确视觉验收标准,避免文本描述的歧义。
3、支持视觉测试与结果验证
-
像素级视觉验证
69个任务实例采用像素级视觉测试(如使用Puppeteer、Pixelmatch库),通过对比截图验证解决方案的正确性。例如:- 网页渲染任务中,系统需确保修改后的界面截图与预期图像一致,细微的像素差异(如抗锯齿效果)都可能导致测试失败。
- 图表库任务中,生成的图表截图需与设计稿完全匹配,确保数据可视化效果正确。
-
动态效果复现与验证
视频或GIF格式的图像(如70个任务包含的动态演示)可展示交互行为异常(如拖拽元素卡顿、动画过渡错误),帮助AI系统理解动态场景下的问题。例如:- 在bpmn-js图表工具任务中,GIF可记录流程图交互时的节点连接错误,辅助复现动态bug。
4、反映真实软件开发场景的多样性
-
覆盖多领域视觉挑战
图像类型覆盖7大类别(网页界面、代码片段、地图、图表、艺术作品、错误消息、其他),对应不同开发场景:- 前端开发:UI布局、响应式设计问题(如Next库的虚拟滚动背景异常)。
- 数据可视化:图表渲染、地理信息展示(如OpenLayers的地图标记点错位)。
- 创意编程:艺术效果错误(如p5.js的图形渲染异常)。
-
多语言与跨模态需求
55个任务包含非英文文本(如中文),部分图像中的文字需结合上下文理解。例如:- 中文界面截图中的按钮文本错误,需同时处理视觉信息和语言语义。
5、对AI系统的挑战与能力验证
-
视觉理解与跨模态推理
AI系统需将图像信息与代码逻辑关联,例如:- 根据界面截图中的按钮样式异常,推断出CSS样式表或JavaScript渲染逻辑的问题。
- 通过代码截图的语法高亮错误,定位到语法解析器的配置错误。
-
环境交互与视觉验证能力
SWE-agent M等系统需通过浏览器工具生成截图、对比视觉结果,例如:- 修改代码后,使用
screenshot命令获取界面截图,验证修改是否解决视觉问题。 - 针对动态任务,通过多轮截图迭代调整代码(如调整图表尺寸时需多次截图验证)。
- 修改代码后,使用
结语
SWE-Bench M的发布为AI系统在视觉软件领域的研究提供了重要的基准,揭示了现有技术的局限性,也为未来的研究提供了清晰的方向。随着AI技术的不断进步,我们有理由相信,未来的AI系统将不仅能够处理文本代码,还能在复杂的视觉软件开发任务中成为工程师的得力助手,推动软件工程领域的创新与发展。
该研究的代码、数据和排行榜已公开,感兴趣的研究者可以访问swebench.com/multimodal获取更多信息,共同推动AI在软件工程领域的前沿研究。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)