俄亥俄州立大学:GUI代理的通用视觉定位
我们展示了一个简单的方案,包括基于网络的合成数据和对LLaVA架构的轻微调整,对于训练此类视觉定位模型出奇地有效。我们收集了迄今为止最大的GUI视觉定位数据集,包含1000万个GUI元素及其在130万个屏幕截图上的指称表达,并用它来训练UGround,这是一个用于GUI代理的强大的通用视觉定位模型。
《Navigating the Digital World as Humans Do: UNIVERSAL VISUAL GROUNDING FOR GUI AGENTS》
我们展示了一个简单的方案,包括基于网络的合成数据和对LLaVA架构的轻微调整,对于训练此类视觉定位模型出奇地有效。我们收集了迄今为止最大的GUI视觉定位数据集,包含1000万个GUI元素及其在130万个屏幕截图上的指称表达,并用它来训练UGround,这是一个用于GUI代理的强大的通用视觉定位模型。

数据收集过程
我们合成了一组大型、高质量和多样的⟨屏幕截图,参照表达,坐标⟩三元组作为视觉定位的训练数据,其中我们使用元素的中心点坐标作为预期输出。我们的数据合成将以网页为基础。网页是生成定位数据的理想选择,因为它们具有双重表示形式——我们可以轻松获取完整的HTML、视觉渲染以及两者之间的精细对应(例如,HTML元素到精确的边界框)。HTML元素还包含丰富的元数据,如CSS或可访问性属性,为生成多样化的参照表达(REs)开辟了多种可能性。最后,由于GUI设计在不同平台之间有许多相似之处,我们假设仅在网页数据上训练的视觉定位模型可能仍然可以推广到桌面和移动UI等其他平台。
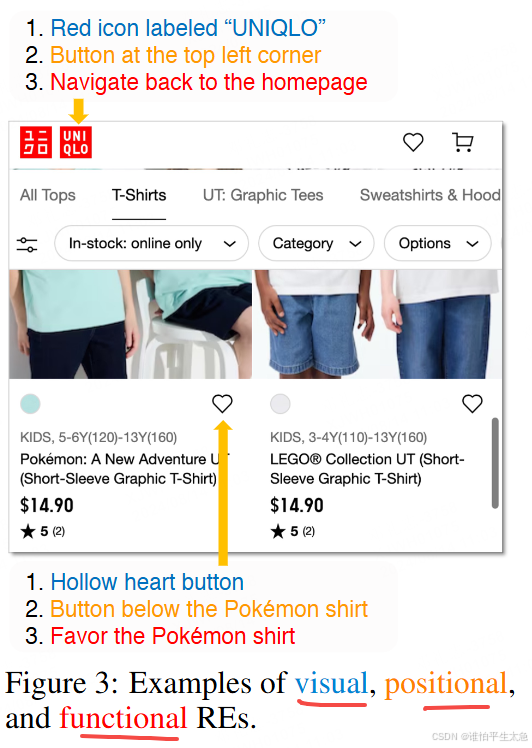
三类RE(指称表达式)数据[⭐]
(1)visual:显著的视觉特征,如文本或图像内容,元素类型。
(2)positional:包括绝对位置(如,“页面左上角”)和相对位置(如,“元素X的右侧”)到其他元素。除了直接的位置信息,上下文引用(如,“针对项目A”,“X部分下方”)对定位更具挑战性,因为它们需要理解元素之间的位置关系和语义关系(例如,点赞按钮与产品相关联)。
(3)functional REs:通过其主要功能来指代元素(例如,“导航到主页”,“去我的购物车”)。组合类型也很常见,它们结合了两种或多种上述类型,特别是在需要更强的消歧义时,例如,“点击宝可梦T恤下的心形按钮以添加到收藏夹。”
来自网络的混合式RE合成【⭐】
我们提出了一种新颖的混合生成流程,该流程协调了精心策划的规则以及LLMs,以生成HTML元素的多样化REs:
(1)主要描述符:我们从HTML元素的属性中提取丰富的视觉和功能信息。
例如,inner-text和alt这样的HTML属性提供了视觉线索(包括文本内容),
而aria-label等可访问性属性揭示了HTML元素的更多功能方面。
然而,HTML属性通常不完整。为了获取HTML属性之外的视觉和功能信号,我们使用了开放的多语言语言模型(MLLM),LLaVA-NeXT-13B(Liu et al., 2024b)。
我们将HTML元素的视觉渲染与其可用属性输入到MLLM中,并提示它生成多种不同的关系表达(REs)。
这个过程常常会产生结合了一些HTML属性与视觉特征(例如,“空心心形”)或MLLM的新知识(例如,蓝色鸟的图标代表Twitter)的组合REs。
类似于Lai et al. (2023),我们也使用LLM(Llama-3-8B-Instruct; AI@Meta, 2024)来使这些生成的REs更加简洁。
我们随机选择以下之一作为元素的主要描述符:一个视觉HTML属性、一个功能HTML属性或LLMs合成的描述。
(2)位置表达式:我们编纂规则,根据元素在屏幕截图中的绝对位置以及与相邻元素的空间关系(例如,“在页面顶部”,“在元素A和B之间”)来生成位置相关的正则表达式。
我们还创建了多个规则来生成上下文引用。例如,我们识别屏幕快照中的某些类型元素(如单选按钮、复选框、输入字段),并根据它们与其他元素(如DOM树的层次结构)的空间和结构关系来生成正则表达式(例如,“标记为‘生日’的输入字段”)。
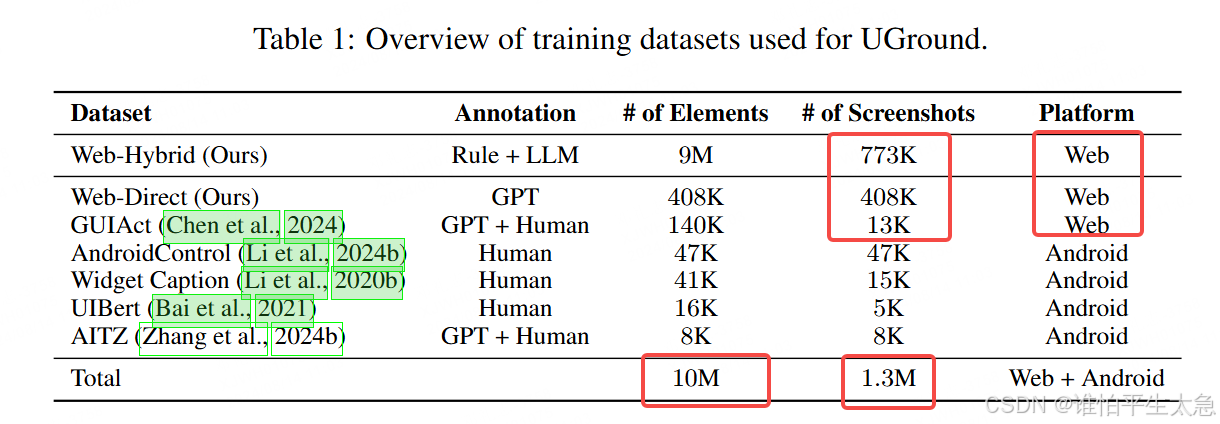
我们收集网页元素的截图(包括各种分辨率的纵向和横向视图)和元数据(显著的HTML属性,边界框坐标)来自Common Crawl。将我们的数据合成管道应用于构建主要的训练数据集(Web-Hybird)。更多细节见附录1。
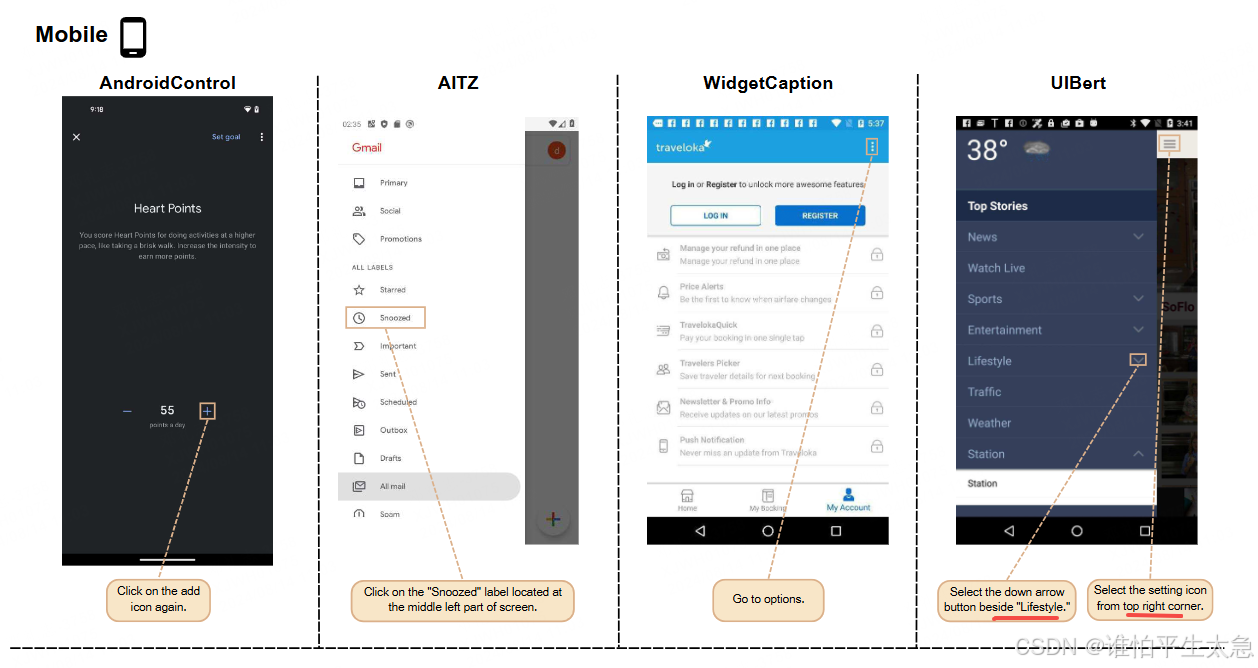
(3)补充数据。之前已经有多个针对Android构建定位数据的尝试,所以我们也整合了现有的数据集。
我们还使用GPT-4o直接合成一小部分针对网页元素的RE(关系表达式),重点是更开放、无类型限制的RE和功能性RE(Web-Direct)。这些补充有助于提供更多样化的RE,覆盖Android中的元素,尤其是那些在网页上不常见的元素(如切换按钮)。
总计,我们编译了一个包含1000万个UI元素的数据库,其中大部分(90%)来自我们的混合合成管道(表1)。相同截图上的元素被批量处理以加速训练。
数据示例
遵循先前的研究(Hong et al., 2024; Cheng et al., 2024),我们下载并从最新的Common Crawl1中随机采样。我们应用了少量过滤方法,根据URL排除非网页文件,并根据Common Crawl提供的语言标签删除非英文页面。
我们使用Playwright加载并渲染网页,捕获屏幕快照并收集网页元素的元数据。这些元数据包括边界框坐标以及可能有用的HTML属性,如元素的标签、文本(内部文本)和备用文本(例如,alt属性)。
在使用Playwright进行渲染过程中,我们随机应用不同的图像尺寸,以涵盖广泛的分辨率和宽高比。具体来说,大约三分之一的数据使用对移动设备友好的宽高比,其中网页以移动网络模式渲染。这样做使得一些网站会自动切换到它们的移动版本,有助于提高对移动UI环境的覆盖率。对于每个长网页,我们在视口大小的区域内随机采样一块内容,以确保捕获内容的多样性。
如第2.2节所述,我们采用混合策略为网页元素生成指称表达(REs)。首先,我们描述如何利用MLLMs(LLaVA-NeXT-13B)和LLMs(Llama-3-8B)生成不包含位置或上下文信息的简洁的元素级描述。
我们从网页截图中提取对应元素的边界框区域,并将这些裁剪后的较小元素图像以及它们的主要HTML属性输入到LLaVA。
使用以下提示,我们提示LLaVA基于其内部知识、元素图像和相关HTML属性生成元素描述:
prompt示例[⭐]
根据附图中的网页元素,请提供该网页元素的简短描述。目标是捕捉元素直观和视觉上的表现。可以使用随附的HTML信息作为上下文,但主要关注描述视觉上可观察到的内容。不要直接引用HTML属性,而是推断如果可以从图像中推断,它们可能的视觉影响。要小心HTML属性中的潜在不准确性,只有当它们与视觉推断相吻合时,才利用它们来增强理解。
HTML:{显著的HTML属性列表}
这是一个网页元素的描述:使用提供的详细描述,创建一个简洁的短语,概括该网页元素的主要视觉和功能特征。改写后的描述应简洁、简单且精确,让人们能快速在网页截图中认出这个元素。重点关注最显著的视觉特征和文本中提到的任何关键功能。
翻译结果:
请仅留下最终的描述,不需任何解释。
我们首先根据网页元素的标签将其分为两类:交互式元素(如a,input,select等)和纯文本元素(如p,h1,h2等)。
仅针对交互式元素生成指代表达,而将纯文本元素用作生成指代表达的潜在来源。
主要原因是交互式元素是GUI定位任务的主要目标。此外,某些爬取的纯文本元素的边界框往往存在不匹配,这可能会为数据集引入噪声。
对于每个交互元素,我们首先应用OCR模型(EasyOCR2)来从元素的边界框中提取文本。如果OCR提取的文本和元素的内文之间的相似度超过0.7的阈值,我们把该元素视为文本元素,并跳过基于MLLM的合成流程。这有助于我们避免生成诸如“由文本标注的灰色链接”之类的简单数据。此外,对于文本元素,我们过滤掉那些与其他同页元素具有相同文本的,以避免接地歧义,即当单个截图中有多个元素具有相同标签时可能出现的问题。
根据手写规则,我们为每个元素的各个方向上的相邻元素打标签(允许有多个相邻元素),标记最近的上级h1、h2或h3元素(标题),
并确定其绝对位置(例如,屏幕截图的中心、顶部、左上角)以生成基于绝对位置的引用表达式。
我们随机选择0-2个不同方向上的相对元素,并随机选取距离目标元素500像素内的元素(实践中,总是选择最近的元素并不总能获得最佳性能)。
这些用于生成相对位置描述。一些相对描述会进一步随机修改为常见的术语,如“旁边”或“之间”。
对于上下文引用,我们制定了以下规则:如果根据其HTML属性检测到一个元素为复选框或单选按钮,我们假设它有一个相应的标签(例如,“用于’是’的单选按钮”)。
如果这些标签在HTML属性中提供,我们直接使用它们;否则,我们选择与标签在同一行的最近元素(如果同一行上没有,选择同一列的最近元素)。同样,我们为输入字段和下拉框添加潜在的标签。
然后,我们根据标题(主要是h1、h2和h3)的层次结构生成“在下方”、“在内”或“在A节下方”等表达式。如果元素具有title、alt或aria-label属性,它们总是被用作潜在的描述符,通常涵盖了视觉和功能性的引用表达式,其中大多数是功能性的引用表达式。
最后,对于每个元素,我们随机组合任何描述符(来自可访问性标签、元素自身的文本或MLLM基描述)与绝对位置描述(随机包含,不总是)和0-2个相对或上下文描述(对于单选按钮或类似元素,始终包含标签;在其他情况下,随机添加0-2个描述符)。
这生成最终的引用表达式。对于每个网页,我们最多使用100个元素。在随机选择元素时,我们优先考虑具有可访问性标签或被MLLM标记的元素。
我们将纯文本元素的总数限制为最多是具有可访问性标签和MLLM注释元素总和的三倍(最低为10,或者实际可用元素的数量,以较低者为准),以减少纯文本元素的数量。
我们还计算所有唯一可访问性标签及其相应频率的出现次数。我们的训练集中总共有大约190万个唯一的可访问性标签。
对于出现次数超过1000次的标签,我们在训练集中将其下采样为只出现1000次。例如,“Next”标签出现了13K次,但在我们的训练数据中被下采样为1K次出现。
我们还面临的另一个挑战是训练和推理之间正确性和清晰度的不匹配。
由于受限于具体理解,即使是像GPT-4o这样最先进的MLLMs也往往会在位置描述上产生幻觉。因此,教模型如何处理次优或模糊但可接受的描述至关重要。
否则,我们实验发现,模型往往会依赖位置信息走捷径,而忽略其他描述,这使得模型很难对MLLMs提供的稍微模糊的描述进行泛化。我们随机添加一小部分次优或错误的位置描述来模拟这种情况(例如,将远处的元素用作邻居,或者随机更改位置描述)。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)