用自己网络添加注意力机制后画出热力图_注意力机制热力图
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
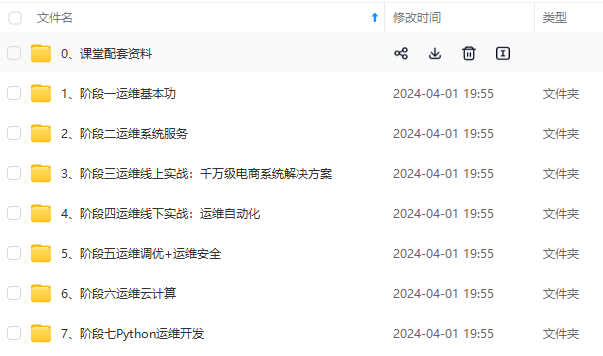
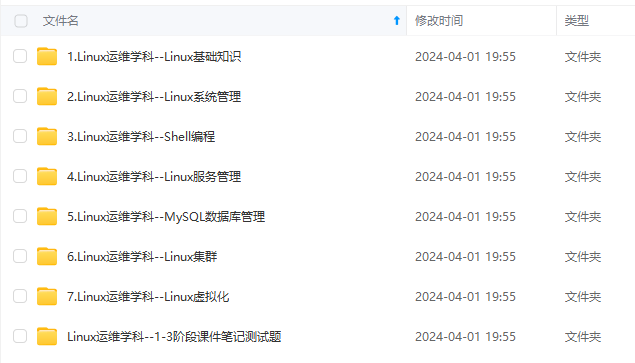
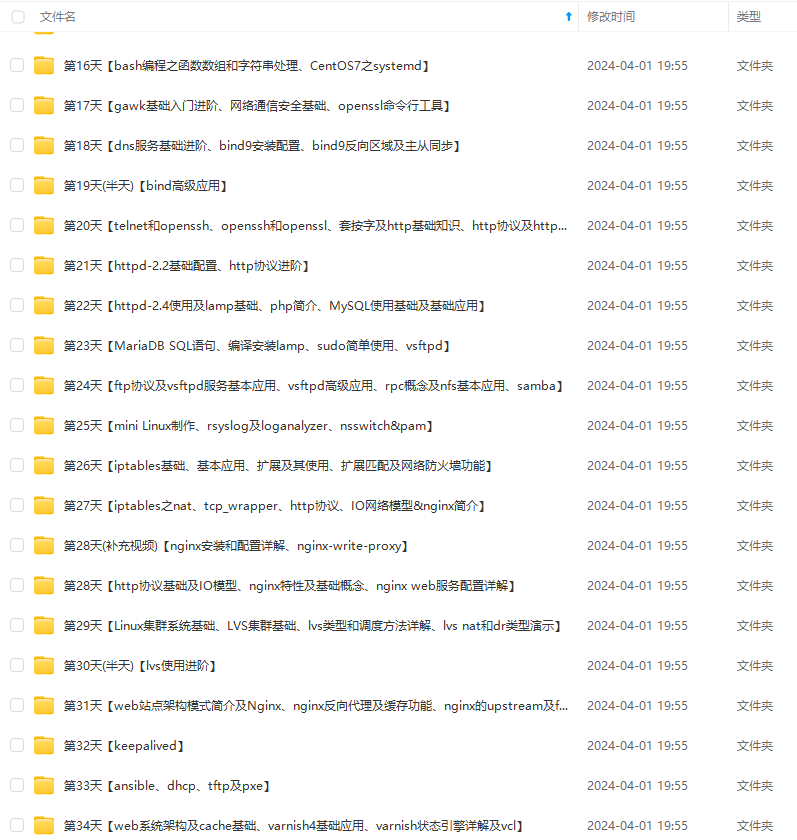
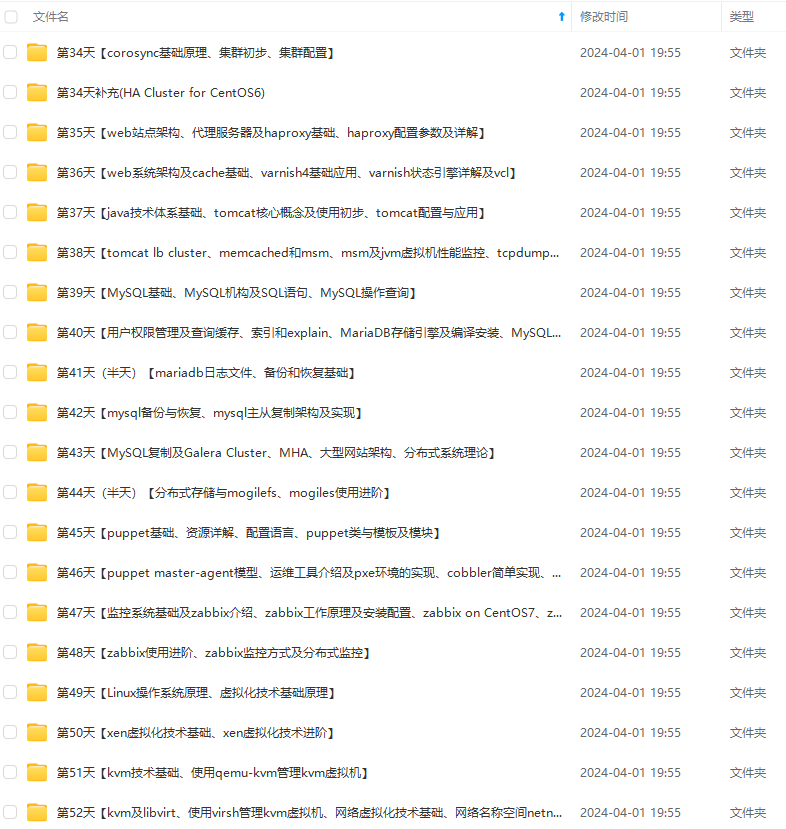
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)
正文
]))
def forward(self, x):
avg_result = self.avgpool(x)
output = self.layers(x)
return output
if name == ‘__main__’:
net = MDNet()
其次将该模型保存下来,即在代码中添加:
def save_model(model):
torch.save(obj=model, f=‘B.pth’)
具体代码如下:
from PIL import Image
import torchvision
import cv2
import numpy as np
from collections import OrderedDict
import torch
import torch.nn as nn
class MDNet(nn.Module):
def __init__(self, model_path=None, K=1):
super(MDNet, self).init()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.layers=nn.Sequential(OrderedDict([
(‘conv1’, nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(2),
nn.MaxPool2d(kernel_size=3, stride=2))),
(‘conv2’, nn.Sequential(nn.Conv2d(96, 256, kernel_size=5, stride=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(2),
nn.MaxPool2d(kernel_size=3, stride=2))),
(‘features’, nn.Sequential(nn.Conv2d(3, 512, kernel_size=3, stride=1),
nn.ReLU(inplace=True))),
(‘fc4’, nn.Sequential(nn.Linear(500, 512),
nn.ReLU(inplace=True))),
(‘fc5’, nn.Sequential(nn.Dropout(0.5),
nn.Linear(500, 512),
nn.ReLU(inplace=True)))
]))
def forward(self, x):
avg_result = self.avgpool(x)
output = self.layers(x)
return output
def save_model(model):
torch.save(obj=model, f=‘B.pth’)
if name == ‘__main__’:
net = MDNet()
save_model(net)
# model = torch.load(f=“A.pth”)
运行Python后可以看见生成了一个B.pth文件
## 2.使用热红外图生成图片:
#图片路径
img_path = r’C:/Users/HP/Desktop/w/1.jpg’
#给图片进行标准化操作
img = Image.open(img_path).convert(‘RGB’)
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, ], [0.5, ])])
data = transforms(img).unsqueeze(0)
#用于加载Pycharm中封装好的网络框架
model = torchvision.models.vgg11_bn(pretrained=True)
#用于加载1中生成的.pth文件
model = torch.load(f=“B.pth”)
#打印一下刚刚生成的.pth文件看看他的网络结构
print(model)
model.eval()
#读取他fc4层图片特征
features = net.layers.Conv1(data)
features.retain_grad()
t = model.avgpool(features)
t = t.reshape(1, -1)
output = model.classifier(t)[0]
pred = torch.argmax(output).item()
pred_class = output[pred]
pred_class.backward()
grads = features.grad
features = features[0]
avg_grads = torch.mean(grads[0], dim=(1, 2))
avg_grads = avg_grads.expand(features.shape[1], features.shape[2], features.shape[0]).permute(2, 0, 1)
features *= avg_grads
heatmap = features.detach().cpu().numpy()
heatmap = np.mean(heatmap, axis=0)
heatmap = np.maximum(heatmap, 0)
heatmap /= (np.max(heatmap) + 1e-8)
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = np.uint8(heatmap * 0.5 + img * 0.5)
cv2.imshow(‘1’, superimposed_img)
cv2.waitKey(0)
## 3.总代码:
from PIL import Image
import torchvision
import cv2
import numpy as np
from collections import OrderedDict
import torch
import torch.nn as nn
class MDNet(nn.Module):
def __init__(self, model_path=None, K=1):
super(MDNet, self).init()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.layers=nn.Sequential(OrderedDict([
(‘conv1’, nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(2),
nn.MaxPool2d(kernel_size=3, stride=2))),
(‘conv2’, nn.Sequential(nn.Conv2d(96, 256, kernel_size=5, stride=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(2),
nn.MaxPool2d(kernel_size=3, stride=2))),
(‘features’, nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=1),
nn.ReLU(inplace=True))),
# (‘fc4’, nn.Sequential(nn.Linear(500, 512),
# nn.ReLU(inplace=True))),
# (‘fc5’, nn.Sequential(nn.Dropout(0.5),
# nn.Linear(500, 512),
# nn.ReLU(inplace=True)))
]))
def forward(self, x):
avg_result = self.avgpool(x)
output = self.layers(x)
return output
def save_model(model):
torch.save(obj=model, f=‘B.pth’)
if name == ‘__main__’:
# 图片路径
img_path = r’I:/2.jpg’
最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-43PwFzTq-1713259050024)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)