爬虫-微博的Cookie登录
在爬虫中,使用通常用于访问需要身份验证的网页或保存用户会话状态的网站。Cookie 是服务器存储在客户端(浏览器)上的一小段数据,主要用于跟踪用户的会话信息。例如,当用户登录一个网站时,服务器会将用户的身份信息(如会话ID)存储在 Cookie 中,以便在后续的请求中确认用户的身份。一些网站对未登录的用户有内容访问限制,只有登录后才能获取特定内容。通过使用登录后的 Cookie,你的爬虫可以模拟已
目录
Cookie登录
在爬虫中,使用 Cookie 登录 通常用于访问需要身份验证的网页或保存用户会话状态的网站。Cookie 是服务器存储在客户端(浏览器)上的一小段数据,主要用于跟踪用户的会话信息。例如,当用户登录一个网站时,服务器会将用户的身份信息(如会话ID)存储在 Cookie 中,以便在后续的请求中确认用户的身份。
在爬虫中,使用 Cookie 登录的主要作用包括以下几点:
1. 模拟用户登录
一些网站对未登录的用户有内容访问限制,只有登录后才能获取特定内容。通过使用登录后的 Cookie,你的爬虫可以模拟已登录的用户,从而访问网站的更多资源。
例如:
- 访问社交媒体的私人内容。
- 获取登录用户的定制化信息。
- 访问需要登录才能查看的数据(如电商平台的订单信息、用户中心、个人收藏等)。
2. 保持会话状态
Cookie 中通常包含会话信息,使用 Cookie 可以保持用户的登录状态。这样,你的爬虫在执行多个请求时,不必每次都重新登录。
例如:
- 爬取用户账户中的连续多页数据(如邮件、历史订单等),你可以通过在每个请求中附带同样的 Cookie,保持会话的连续性。
3. 绕过验证码
很多网站在用户登录时要求输入验证码,而爬虫难以自动识别和输入验证码。如果能够获取登录后的 Cookie,爬虫可以绕过登录时的验证码验证。
例如:
- 在首次手动登录时获取 Cookie,保存下来,然后通过爬虫重复使用这些 Cookie,避免每次登录都需要输入验证码。
直接访问登陆后的页面
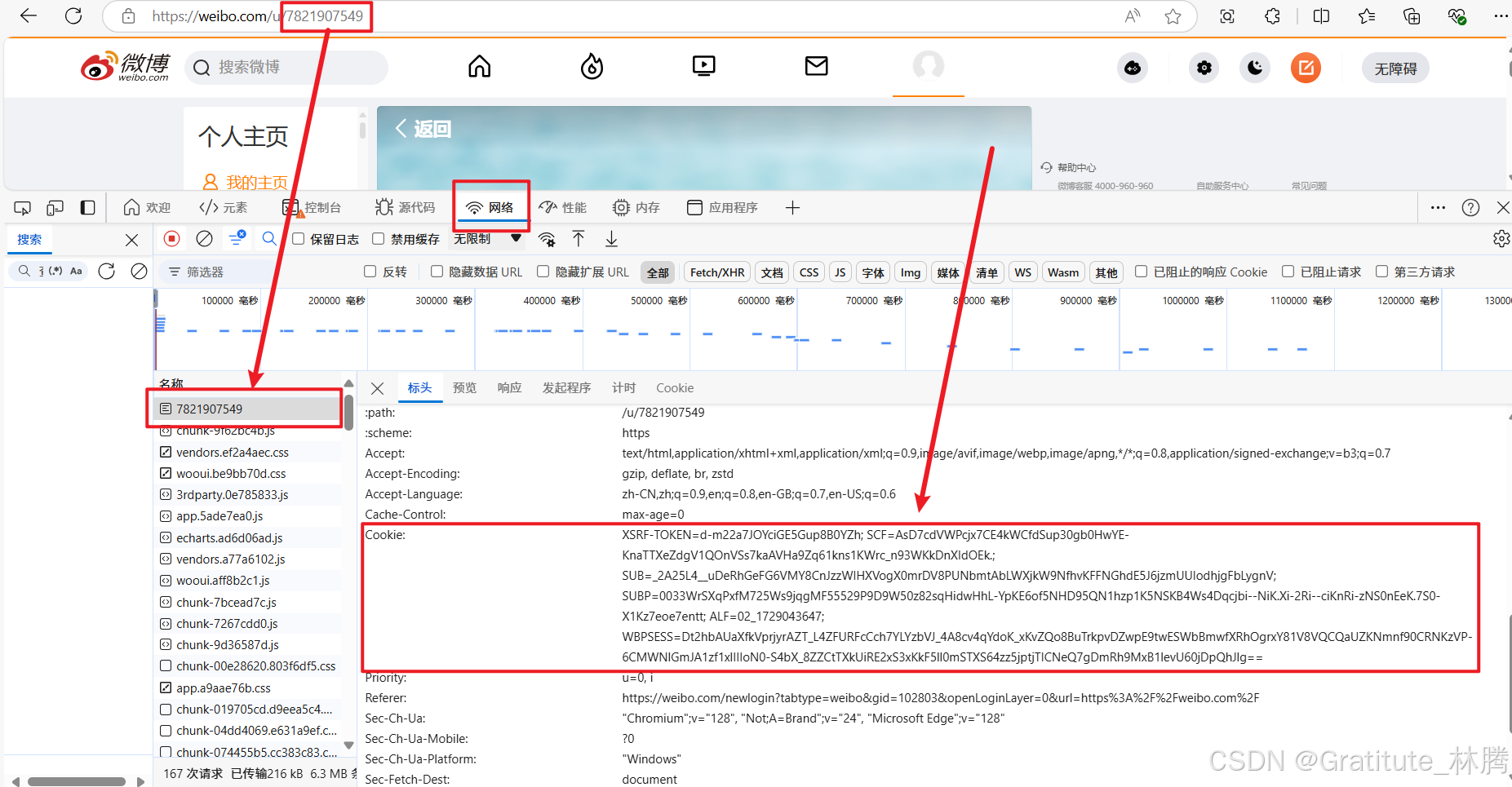
下图是登录微博后的网址
我们尝试在pycharm中直接通过这个网址来访问该页面
import urllib.request
url = 'https://weibo.com/u/7821907549'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read().decode("utf-8")
# 打印响应数据
print(content)
# 下载到本地
with open('weibo.html','w',encoding='utf-8') as fp:
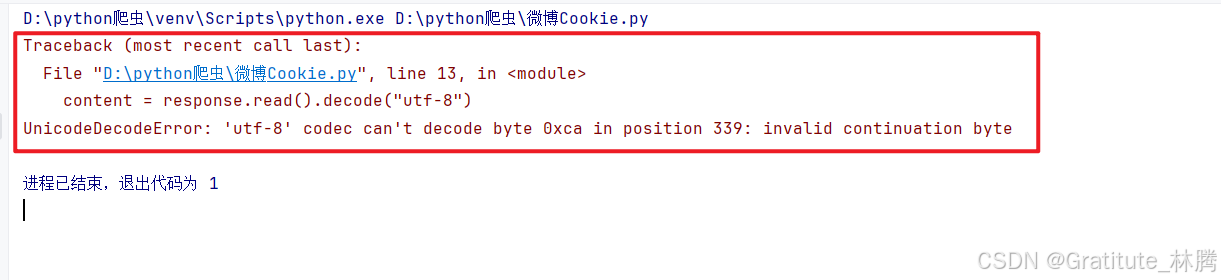
fp.write(content)运行程序,却报了编码错误,表示该页面不是utf-8的编码格式
此时,我们回到微博个人信息页面,按f12查看编码格式。
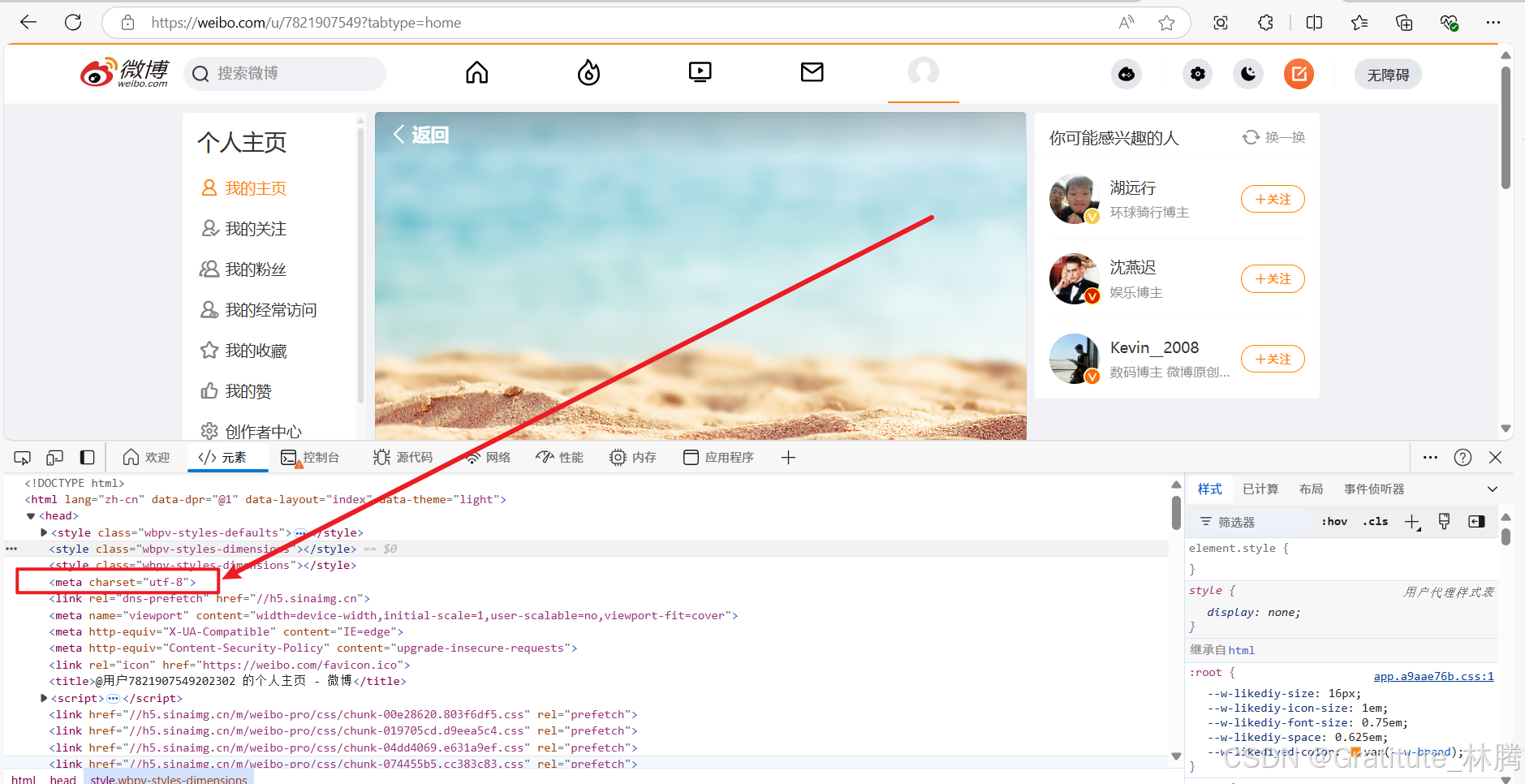
可以看到,该页面的编码格式就是utf-8,那为什么控制台会报编码格式错误呢?是不是感觉很诡异。
这是因为代码中并没有携带Cookie信息,所有其实并没有进入到个人信息页面,而是跳转到了其他页面,而其他页面的编码格式并不是utf-8,于是就报了编码格式错误。
我们来看看跳转到的其他页面的编码格式,修改为如下代码
import urllib.request
url = 'https://weibo.com/u/7821907549'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read()
# 打印响应数据
print(content)
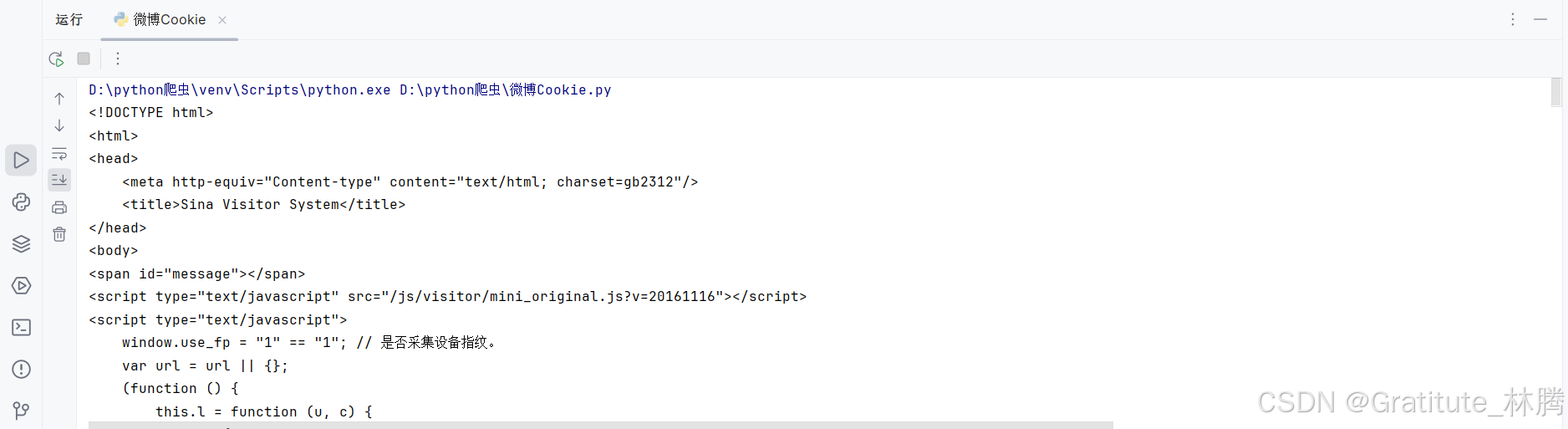
该代码没有对响应数据进行解码,而是直接打印,这样我们能从打印结果中得到当前页面的编码格式,打印结果

可以看到,跳转到的其他页面的编码格式为gb2312
此时,我们将utf-8换成gb2312
import urllib.request
url = 'https://weibo.com/u/7821907549'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read().decode("gb2312")
# 打印响应数据
print(content)
# 下载到本地
with open('weibo.html','w',encoding='gb2312') as fp:
fp.write(content)此时就成功运行了,并且也下载到了本地
不过很容易能看出,这并不是微博的个人信息页面。这也再一次证明了如果代码中并没有携带Cookie信息,则并不会进入到个人信息页面,而是跳转到了其他页面。
添加Cookie信息
将Cookie放在请求头中,并换回utf-8
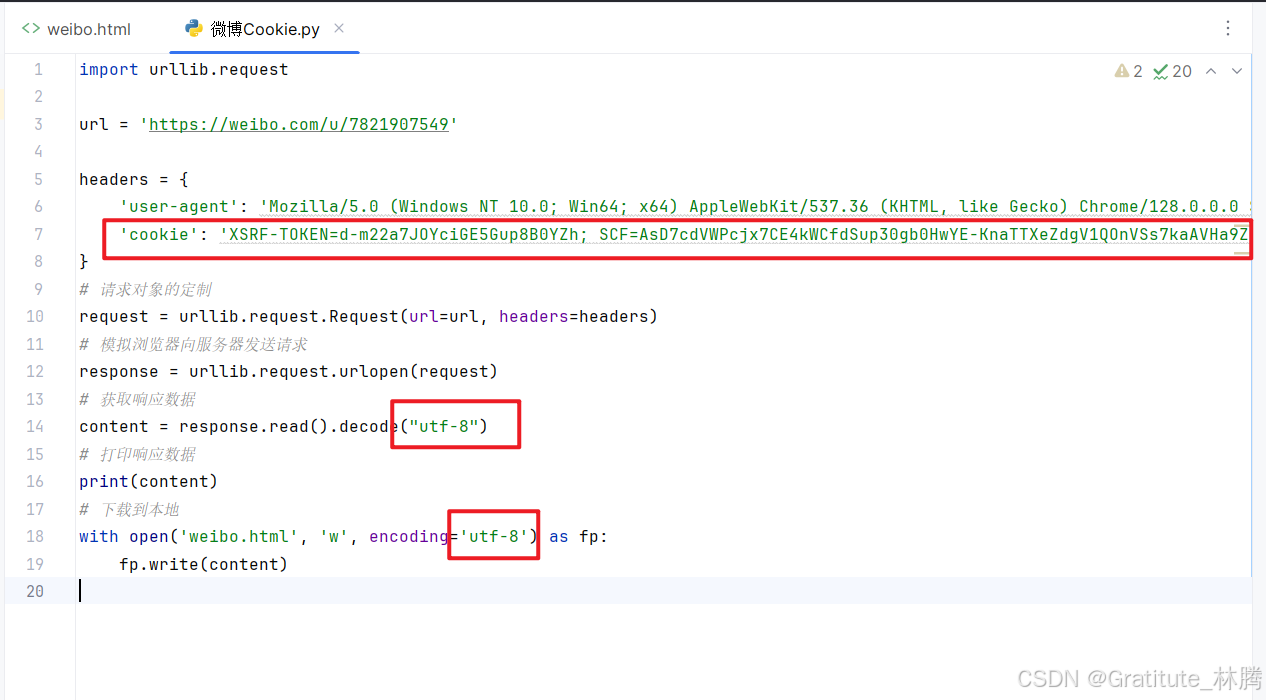
代码
import urllib.request
url = 'https://weibo.com/u/7821907549'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'cookie': '换成你自己的cookie',
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read().decode("utf-8")
# 打印响应数据
print(content)
# 下载到本地
with open('weibo.html', 'w', encoding='utf-8') as fp:
fp.write(content)
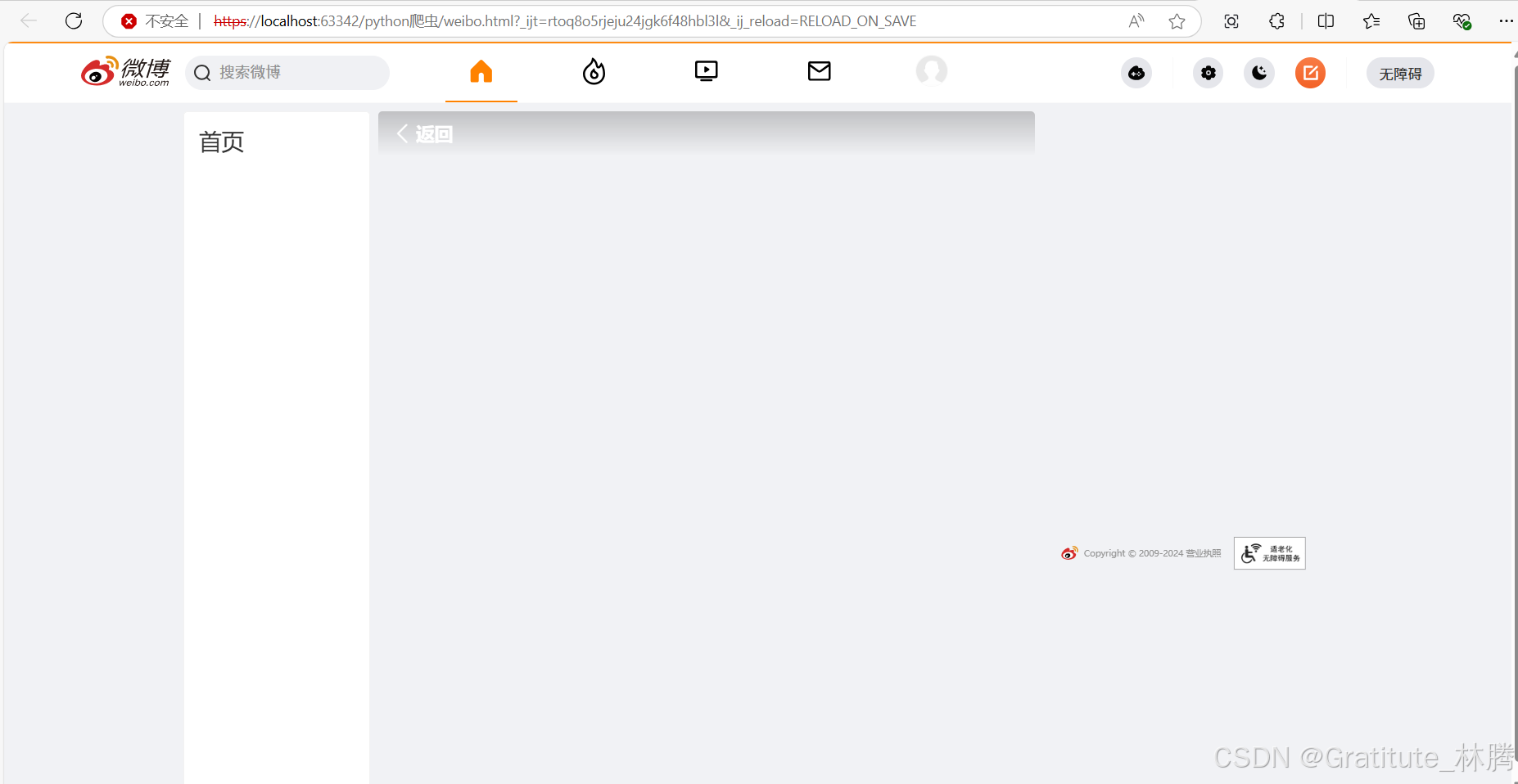
运行程序后,得到的页面代码
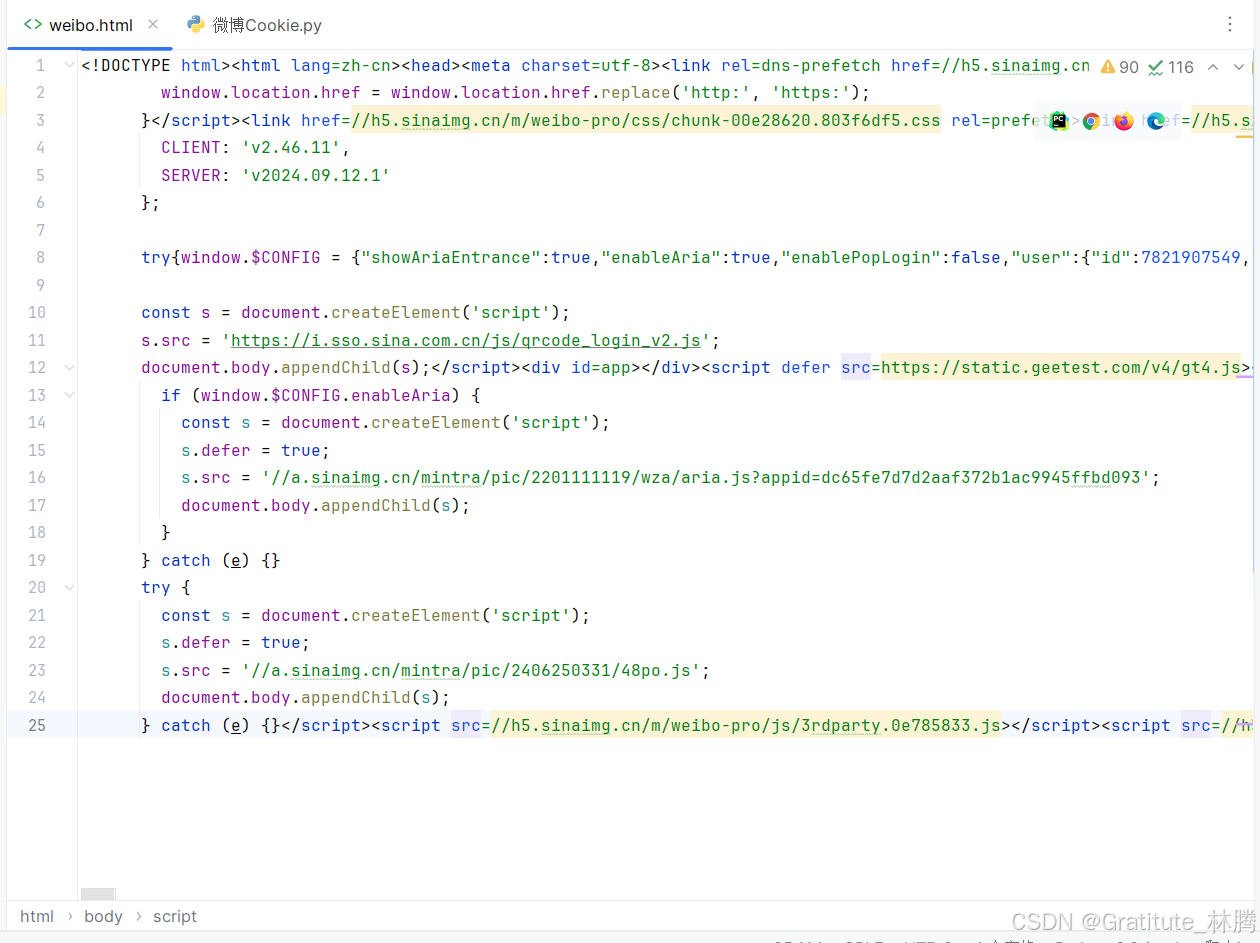
可以看到,得到的是个人信息页面,但内容并不完整,可以说是完全没有实际的内容,可能微博这几年不断更新,优化了反爬手段,只添加Cookie还不足以成功爬取个人页面的完整内容。不过,能到这一步就可以了。这里主要讲解Cookie的作用。
打开该页面,只呈现出页面框架,没有具体信息,并且显示不安全。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)