grafana免费连接Oracle/MongoDB——simpod-json-datasource
grafana官方提供的Oracle、MongoDB插件都需要付费使用。在需求促使下,我发现了一个官方提供的可以白嫖的simpod-json-datasource。这款插件允许自定义数据源,我们只需要提供接口,并按数据库数据按规定格式响应,即可将数据传给grafana。只要插件版本适配,这套方案理论上支持任何版本的grafana。这套方案的扩展性很好,后续可以加入其他grafana付费数据源。
一、简介
grafana官方提供的Oracle、MongoDB插件都需要付费使用。
在需求促使下,我发现了一个官方提供的可白嫖的插件:simpod-json-datasource。
JSON plugin for Grafana | Grafana Labs
简单来说,数据流向从
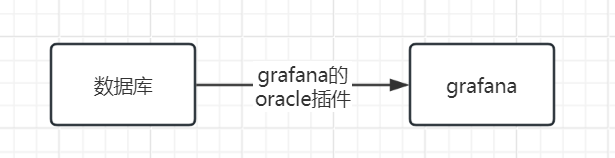
转变为

服务器API的规范如下(详见上面的官方文档),

实际可在请求触发时,用浏览器开发者工具捕获后核对,比如请求路径、参数格式等等
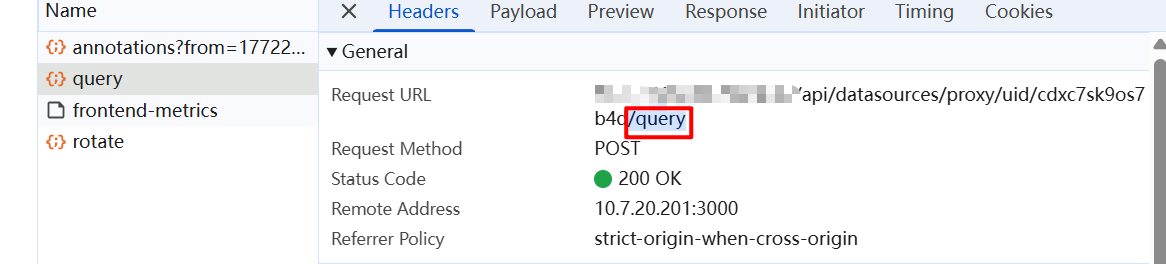
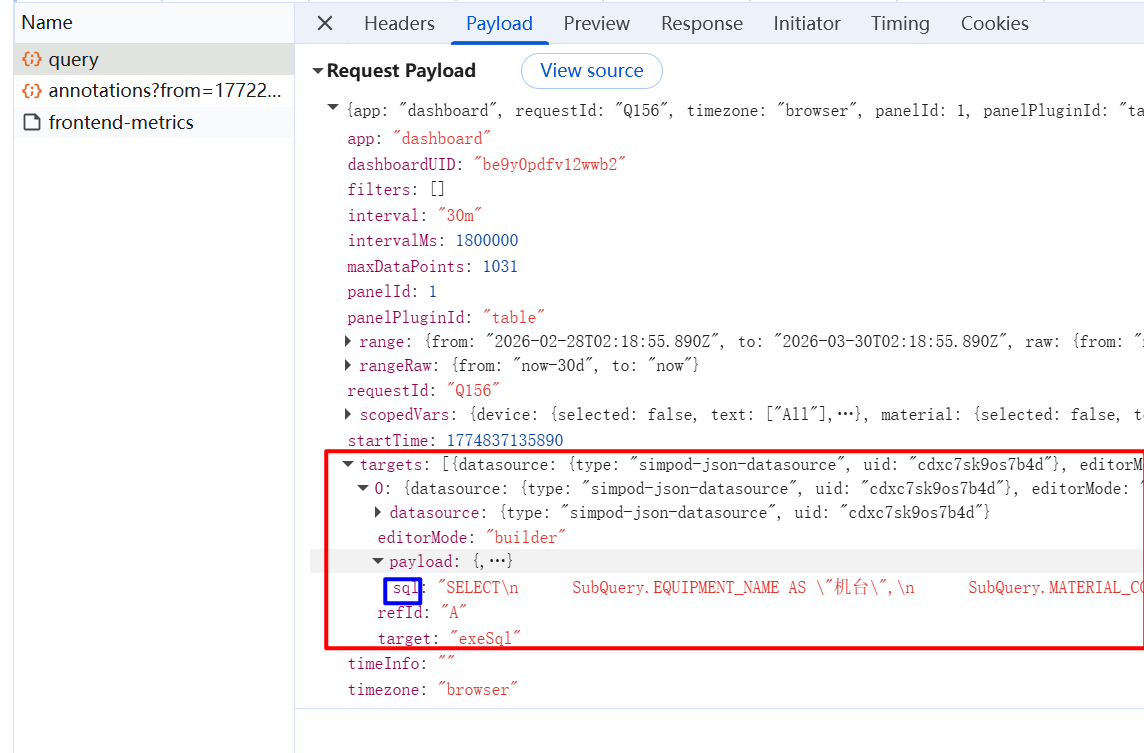
服务器响应数据的格式必须应插件文档要求,不同的图表类型有不同的格式
二、实现
1、下载grafana

官网网址:
Download Grafana | Grafana Labs
国内镜像:
2、安装插件
下载zip后解压
在bin目录下cmd

运行
grafana-cli plugins install simpod-json-datasource3、运行grafana

双击grafana-server.exe
没有报错一般就是成功
从网页进入grafana,端口默认是3000,用户名密码默认admin/admin

4、运行服务器
从本文中下载我写的Springboot项目(如果被自动升级为需要积分,可联系我)
修改数据库连接信息

启动我的Springboot项目
5、创建DataSource



URL是Springboot项目的控制器请求地址,配置下面几项后,点击save & test

保存成功,oracle同理

6、使用dashboard

创建


6.1先说明相对简单的oracle


在这里输入sql

不同的图表对sql有不同的要求,以time series(时间折线图)为例,第一个字段应该是y轴的数字值,第二个字段是X轴时间值,数据线别名则需要另穿一个metric字段
$__to和$__from变量是grafana的自带的全局变量,会在查询的时候,自动将右上角的开始时间和结束时间替换的符号里(替换为时间戳)。

6.2MongoDb
mongodb界面和oracle一样。

我写的服务器暂时只支持aggregate查询。
查询sql如下例,
db.coll1.aggregate([
{
"$match": {
"create_time": {
"$gte": "$__from",
"$lt": "$__to"
}
}
},
{
"$project": {
"_id": 0,
"value": { "$toDouble": "$count" },
"time": "$create_time",
"metric": "去世次数"
}
}
], { "allowDiskUse": true })tip: aggregate每个阶段默认只能处理100M内存数据,也就是查询数据量有限制。allowDiskUse允许临时写入磁盘,能突破这个数据量限制
7、查看报错
在控制台或者Query inspector中可以查看报错信息


8、注意
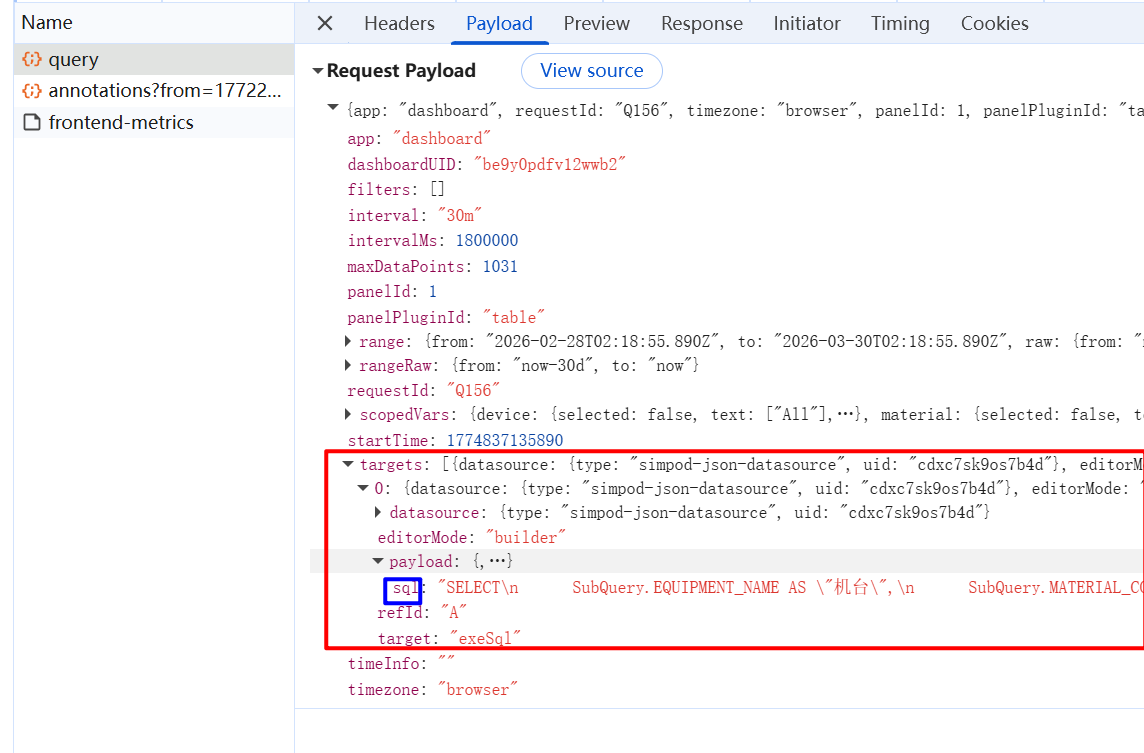
不同版本的grafana发起请求时的参数格式不尽相同,实际需要用浏览器开发者工具中的网络捕获后核对。比如10版本的请求格式如下:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)