目标跟踪综述 算法分类介绍
多目标跟踪旨在将视频序列中感兴趣的目标检测出来,并赋予每个目标单独的编号,在整个序列中形成目标的轨迹。Online形式的MOT算法按照是否同时单次进行检测与轨迹处理可分为检测后跟踪(tracking-by-detection,TBD)与联合检测跟踪(joint detection and tracking,JDT)两种结构。强约束:同一帧的目标之间不可以相互匹配弱约束:两帧里有很多重复目标,因此一
多目标跟踪任务介绍:
定义:
多目标跟踪旨在将视频序列中感兴趣的目标检测出来,并赋予每个目标单独的编号,在整个序列中形成目标的轨迹。
分类:
Online:算法在推理目标身份过程中,只能看到当前帧以及之前的帧,解决方法一般为关联
Offline:算法在推理目标身份过程中,可以看到整个视频序列,通过最优化解决,把offline转换为网络最大流,将整个视频的身份匹配作为一个网络流;也称batch
多目标跟踪VS检测
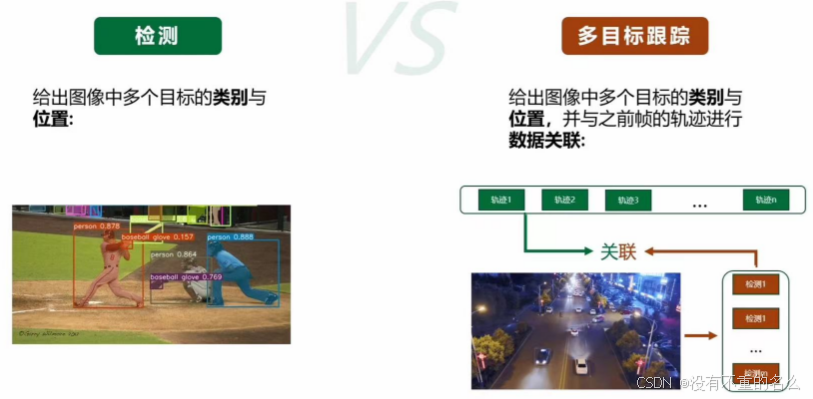
难点:
- 目标模糊、遮挡造成目标外观特征不稳定
- 相机运动造成的外观特征(模糊、尺寸变化)与运动特征变化
- 各类样本数量不均衡(长尾分布),分类器难以训练
- 目标尺寸小容易漏检
- 实时性要求
数据集发展历程:
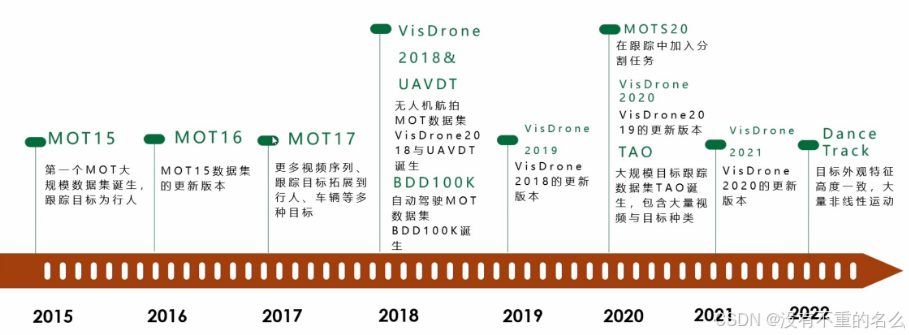
评价指标发展历程:
经典度量方式:
- 多数被跟踪轨迹(Mostly Tracked trajectories,MT):真实轨迹中大于等于80%的帧中被正确跟踪的数目。有时也用百分比表示,越大越好。
- 多数丢失轨迹(Mostly Lost trajectories,ML):真实轨迹中小于等于20%的帧中被正确跟踪的数目。有时也用百分比表示,越小越好。
- ID切换数(ID Switches,IDS):ID错误切换的次数。越小越好。维持一个目标的稳定,目标还是原来的目标,但算法认为它是一个新目标,这就是ID Switches。
“CLEAR”度量方式:
- MOTA:同时考虑检测效果(虚警、漏检)和ID错误切换次数指标
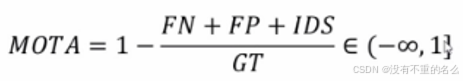
- MOTP:考虑回归的边界框的质量,以与真值边界框的欧式距离度量
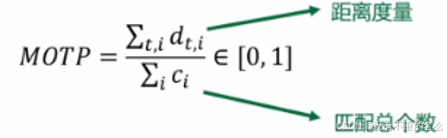
ID度量方式:
- IDP(ID精度):利用二部图匹配计算出预测ID与真值ID的映射关系,以下式求解
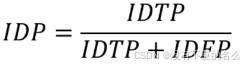
- IDR(ID召回率):
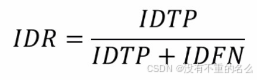
- IDF1(ID F1 score):精度和召回率的调和平均
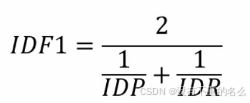
HOTA度量方式:
高阶度量精度将检测性能与关联性能进行了统一与平衡
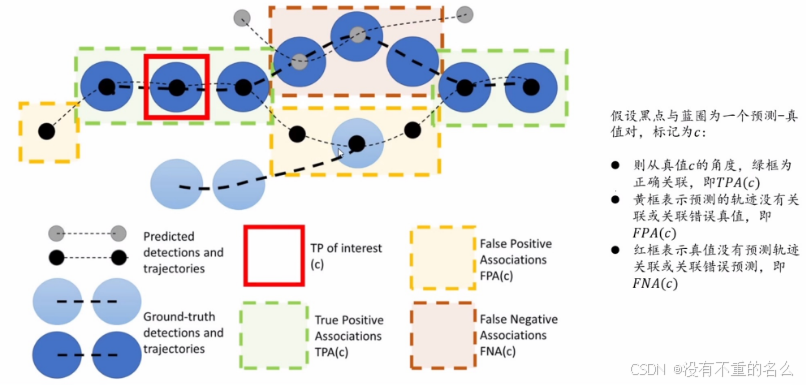
False Positive(黄框):无轨迹或其他轨迹的预测出轨迹
False Negative(棕框):有轨迹没预测出来或预测成其他轨迹
True Positive(绿框):重合部分
- DetA(Detection Acc,检测精度分数):
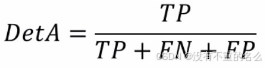
- AssA(Association Acc,关联精度分数):
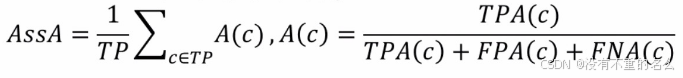
- HOTA(High-Order Tracking Acc,高阶关联精度):
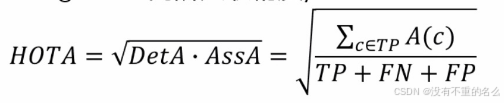
开根号:精度分数为0~1之间的数,让数字差异更大一点
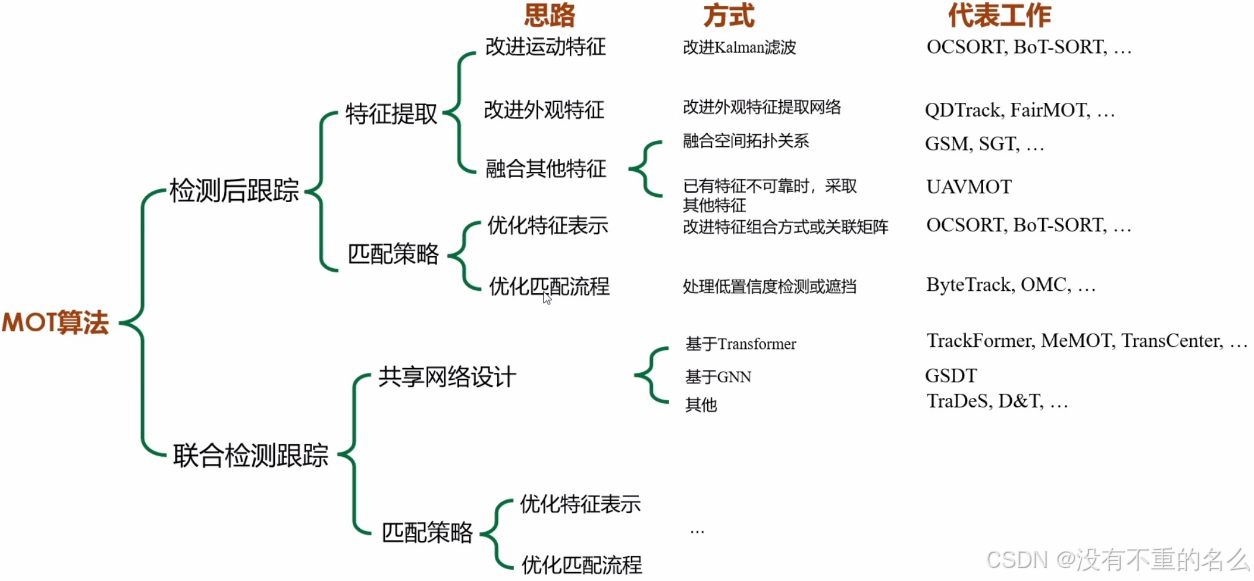
主要流派介绍:
分类依据:
Online形式的MOT算法按照是否同时单次进行检测与轨迹处理可分为检测后跟踪(tracking-by-detection,TBD)与联合检测跟踪(joint detection and tracking,JDT)两种结构。
-
检测后跟踪(TBD):
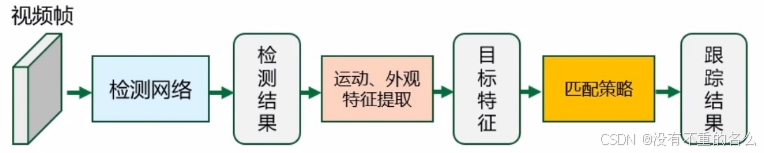
研究重点:特征提取方式、匹配策略
-
联合检测跟踪(JDT):
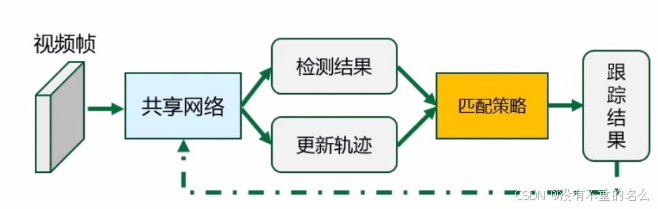
研究重点:共享网络设计、匹配策略
改进卡尔曼滤波:
算法[1] OCSORT:
inactive(不再活跃或未能持续跟踪)的轨迹要恢复时,为这个轨迹建立一个虚拟轨迹,修正Kalman的误差;从目标丢失时到目标发现时,自己创建了一个线性运动模型,修正后代入Kalman更新步
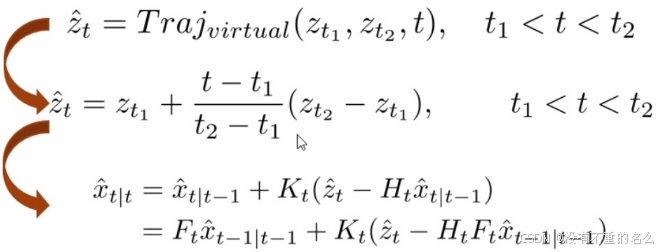
算法[2] BoT-SORT:
提取两帧之间关键点建立仿射矩阵,将Kalman滤波预测结果映射到新坐标下;把图像之间的变化等价于坐标系之间的变化;当发生相机运动时,认为Kalman滤波预测不准,而需要在一个新的坐标系下进行更正
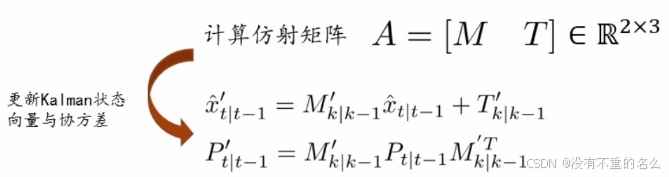
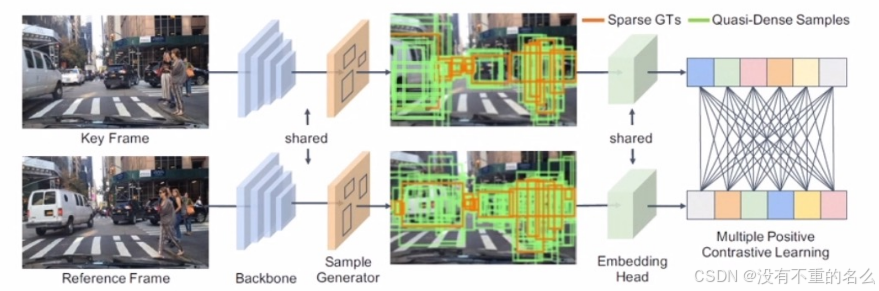
算法[3] QDTrack:
产生大量的region-proposal,利用对比学习的方式在关键帧和相邻帧之前来学习实例之间的相似性,更好区分不同目标之间的差异
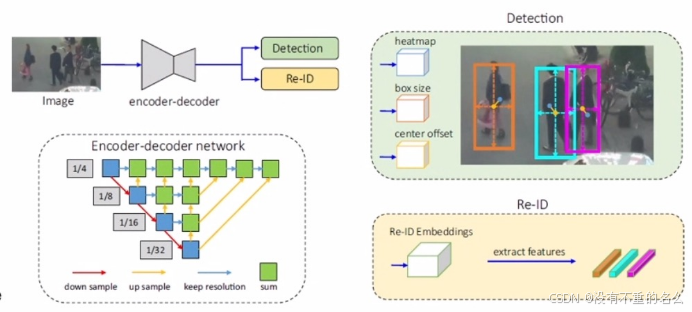
算法[4] FairMOT:
将外观特征学习与目标检测合为一体,通过使用anchor-free的方式缓解两任务不平衡的问题
算法[5] UTrack:
采用无监督学习的方式训练特征提取网络,避免了标签分类很多问题的推理
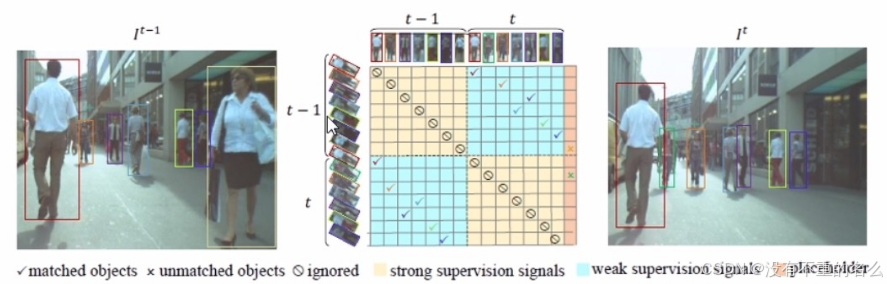
定义两种约束条件:
- 强约束:同一帧的目标之间不可以相互匹配
- 弱约束:两帧里有很多重复目标,因此一帧里的目标大概率要在另一帧中找到匹配
融合其他特征:
-
融合空间拓扑关系
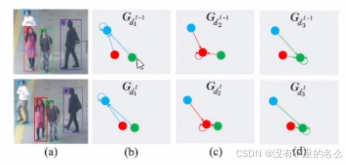
算法[6] GSM:
采用GNN加入拓扑关系,对每个顶点建立一个有向图,顶点表示外观特征,边表示位置关系特征,随后计算两帧间每个目标的图相似度进而进行匹配;每一个目标都建一个图,该目标周围的外观和位置差异建模,两帧之间进行图匹配做关联
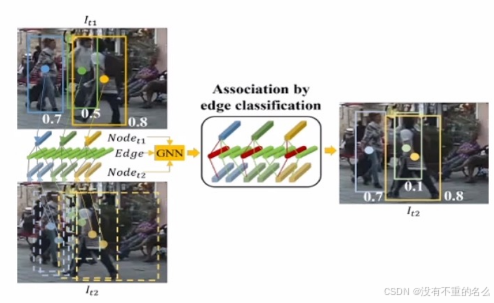
算法[7] SGT:
采用GNN加入拓扑关系,顶点代表检测,边代表两个检测之间的相似度(IoU、拓扑关系、外观三个维度衡量)。把两个检测是否属于同一目标,转换成边分类的问题。将位置信息融合到边里,用边分类把两个检测事物属于同一目标转化为二分类问题。
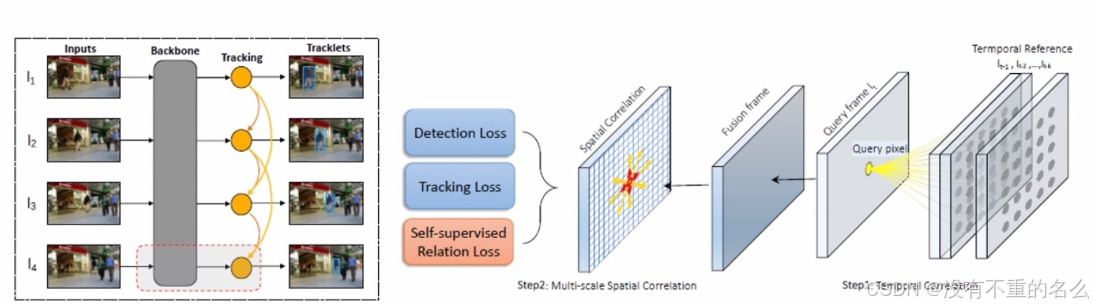
算法[8] STLC:
科用局部相关模块对目标和周围的环境进行拓扑关系的建模,这样在拥挤场景有效。具体地,建立每个空间位置和其上下文的密集联系,然后通过自监督学习显式地约束。
-
已有特征不可靠时,采取其他特征
算法[9] UAVMOT:
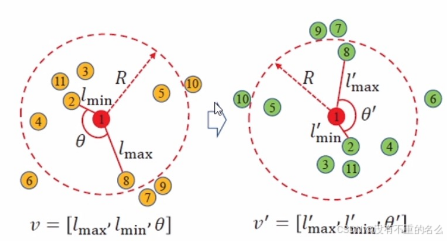
由于摄像机(无人机)的非线性运动造成Kalman预测失效时,采取目标与周围的位置(拓扑)关系作为位置特征。
优化特征表示:
-
优化特征组合方式
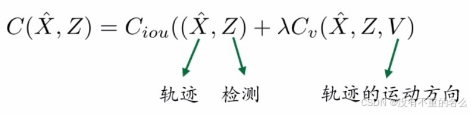
算法[1] OCSORT:
将IoU与目标的运动方向组合作为关联矩阵
算法[2] BoT-SORT:
采取指数滑动平均更新外观特征。在运动与外观特征中选择更接近的特征作为关联矩阵中的元素。
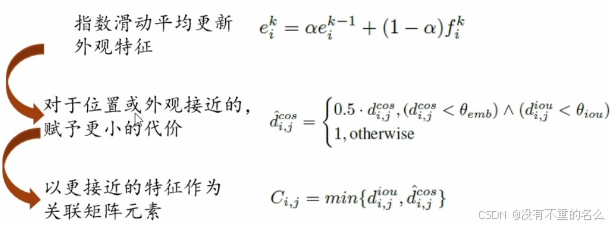
-
采取额外网络计算关联矩阵
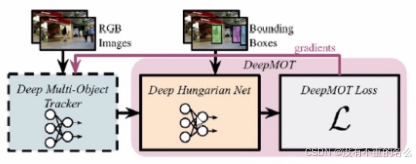
算法[10] DeepMOT:
将MOTA,IDF1指标等价为可微形式,采用双向RNN对原始关联矩阵进行更新以转为优化问题。
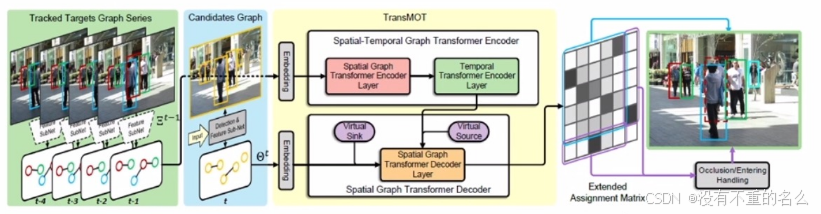
算法[11] TransMOT:
采取Graph Transformer结构对过去帧轨迹时空关系进行建模,输出扩展关联矩阵。第一轮匹配不了的按照TransMOT来计算
算法[12] ByteTrack:
对于舍弃低置信度可能造成的FN,采取将低置信度与未与高置信度匹配的轨迹再次匹配的方式;对于置信度低的匹配再给一次机会

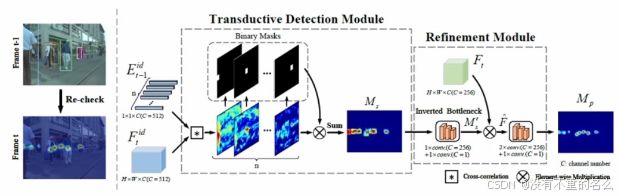
算法[13] OMC:
采取额外分支融合过去帧的目标外观特征,并在本帧做出预测,与检测器的结果共同考虑如果分支预测的结果没有出现在检测器的结果中且置信度充分大,则恢复检测。
共享网络设计:
-
基于Transformer结构:
算法[14] TrackFormer:
根据DETR改进,同时将过去帧的轨迹(表示为跟踪查询向量)和该帧潜在的检测(表示为空向量)与图像特征做注意力机制,并同时输出更新的轨迹与新检测。
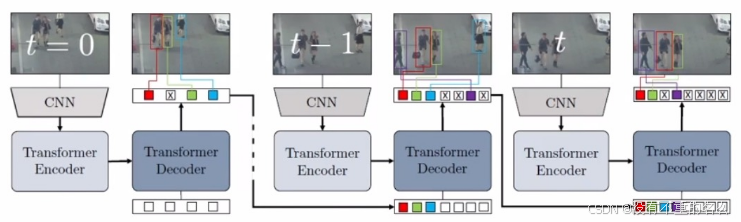
算法[15] TransCenter:
孪生Transformer结构,结合相邻两帧信息,采用anchor-free的方式预测轨迹。
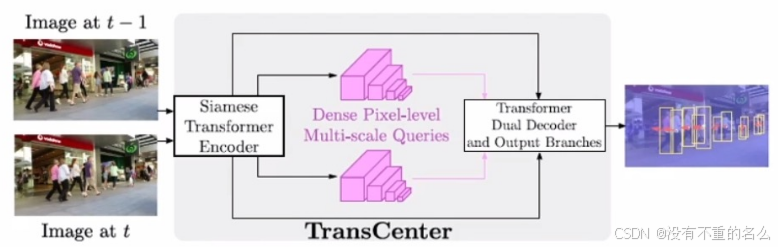
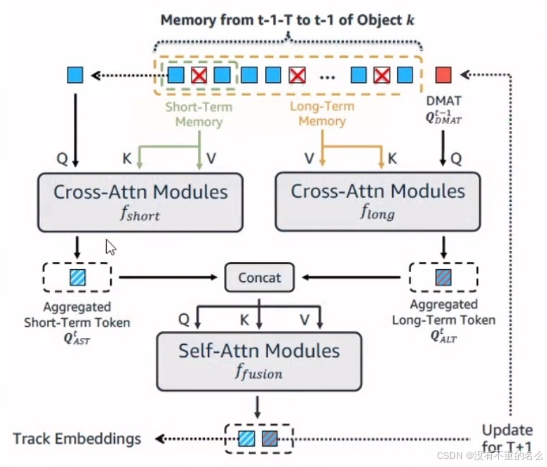
算法[16] MeMOT:
记忆多帧的轨迹特征,并分为短时记忆模块与长时记忆模块联合计算,将输出结果更新轨迹特征。
-
基于GNN结构
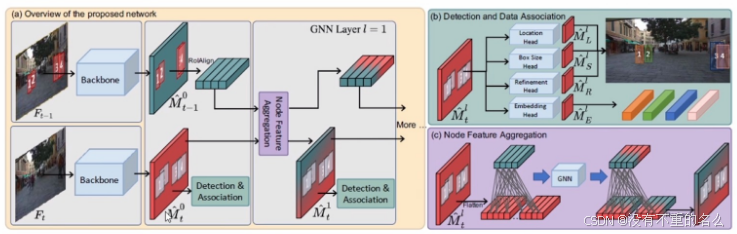
算法[17] GSDT:
将过去轨迹特征与当前特征图进行GNN传播并同时得到外观特征与位置信息。将每一个像素都看作为目标的潜在位置,做节点的特种融合,预测,计算量大。
-
其他结构
算法[18] TraDeS:
利用相邻帧的特征相似度计算跟踪偏移,并采用DCN对当前帧特征进行增强。运动预测根据特征预测得来。
数据关联:
首先根据得到的轨迹和检测的中心点位置关联,对于该步无法关联的采取外观特征再次关联。
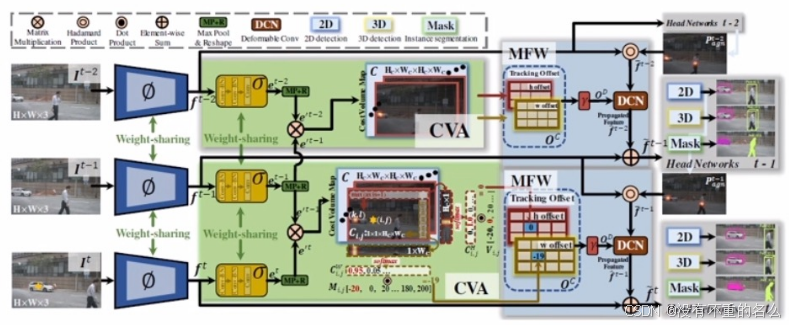
算法[19] D&T:
输入为两帧特征(包括卷积中间层和position-sensitive score map)的相关操作后的结果,经过RoI Tracking输出坐标变换关系。根据关联直接预测目标偏移,偏移小的直接关联,预测为一个轨迹

算法[20] CenterTrack:
将上一帧图像与上一帧轨迹作为该帧检测的辅助,网络输出轨迹的偏移
数据关联:
根据预测的偏移关联轨迹与检测

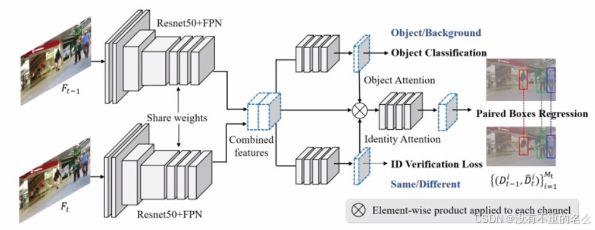
算法[21] Chained-Tracker:
相邻两帧为输入,将特征融合后采取注意力机制直接输出边界框对。
数据关联:
通过IoU值进行跨帧连接,滑动窗口
未来的发展趋势:


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 36
36 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)