毫米波雷达如何实现目标分类——神经网络基础
NN二、算法理论三、激活函数四、基本实现(matlab)五、特征选取
目录
一、前言
毫米波雷达以高适应性低识别力著称,但选择适合的分类算法依然可以达到85%甚至95%以上的准确率。一般工程做选择距离信噪比经验公式来做类型判断;置信度通过信噪比(反射强度)、跟踪命中次数及丢失次数来计算。
之前工程中看到SVM与NN相关分类准确度比较,NN超平面学习效果比SVM提高的多。NN在分类上仍少不了传统特征分析与选取,神经元个数,层数,激活函数、损失函数设计,学习率等参数的调整。本篇基于西瓜书matlab实现最基本的NN,特征的选择。
二、算法理论
BP网络及算法如下所示:
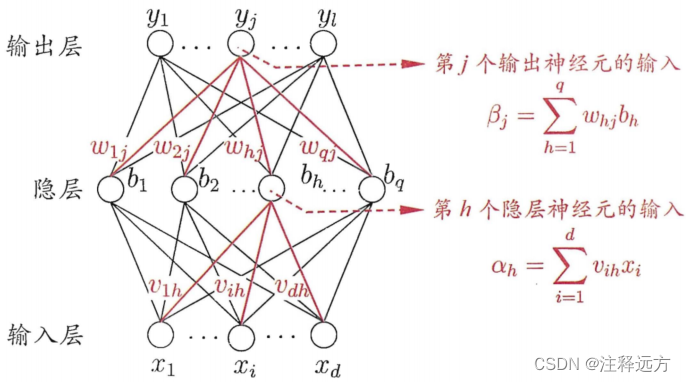
5.3到5.17的公式可以根据南瓜书看具体推导,这里我们可以先只关注结论即可,误差逆传播算法如下:

三、激活函数
激活函数就是在原来的线性组合的基础上加上非线性函数,让模型的表达能力更强。
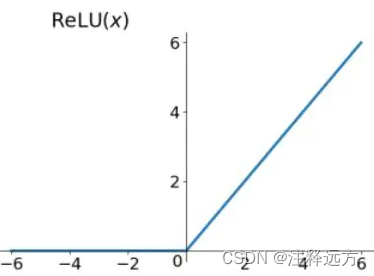
ReLU(Rectified Linear Unit) - 用于隐层神经元输出,Relu实质就是个取最大值的函数
f(x) = max(0,x)。
优点:
输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,进而对计算来说是非常有效率的。
缺点:神经元很容易“死亡”,因此需要设置较小的学习率
Sigmoid - 用于隐层神经元输出,对于二分类的神经网络来说,最后一层的激活函数一般都是sigmoid函数。
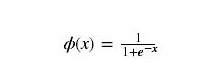

x是输入量,w是权重,b是偏移量(bias),权重w使得sigmoid函数可以调整其倾斜程度(上下),偏移量b不会改变曲线大体形状(左右)
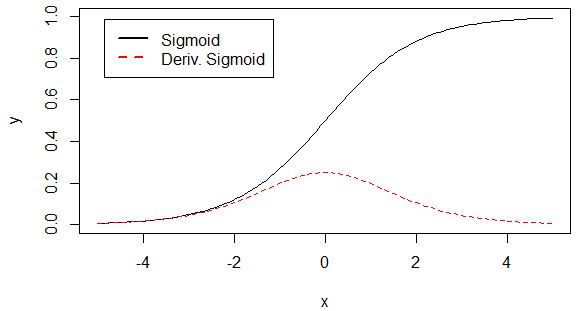
小结:对比sigmoid类函数主要变化是:单侧抑制;相对宽阔的兴奋边界 ;稀疏激活性。
Softmax - 用于多分类神经网络输出。softmax函数,又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。1)预测的概率为非负数;2)各种预测结果概率之和等于1
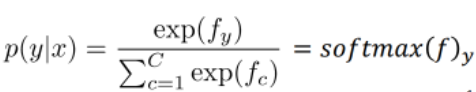
小结:softmax一般用于多分类的结果,一般和one-hot的真实标签值配合使用,大多数用于网络的最后一层;而sigmoid是原本一种隐层之间的激活函数,但是因为效果比其他激活函数差,目前一般也只会出现在二分类的输出层中,与0 1真实标签配合使用 。

Linear - 用于回归神经网络输出(或二分类问题)y= ax+b
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
交叉熵损失函数
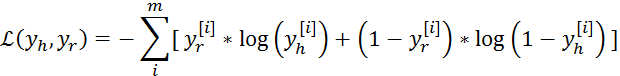
随机梯度下降:
L表示最后一层,从最后一层开始,由损失函数逐步向后求导
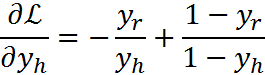
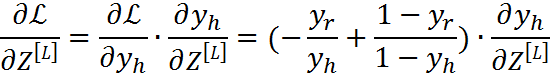
四、参数初始化
- 基于固定方差的参数初始化
- 高斯分布初始化:使用高斯分布
对每个参数随机初始化;
- 均匀分布初始化:在[-r, r] 内采用均匀分布初始化,其方差为
,得到:
固定方差参数初始化的关键是:如何设置方差,如果太小,一是导致神经元输出过小,经过多层则信号消失了;二是sigmoid激活丢失非线性(0附近基本是近似线性的)。如果太大,sigmoid激活梯度接近0,导致梯度消失。一般需要配合逐层归一化一起使用。
2. 基于方差缩放的参数初始化
如果一个神经元输入很多,则每个输入连接上的权重就应该小一些,以免输出过大,导致梯度爆炸(ReLU)或梯度消失(sigmoid)。因此,需要尽量保持每个神经元输入和输出方差一直,可以根据神经元连接数量自适应调整初始化分布的方差,称为“方差缩放”。
- 2.1 Xavier初始化(也称为Glorot初始化,因为发明人为Xavier Glorot)
- 2.2 He初始化(也称为Kaiming初始化)
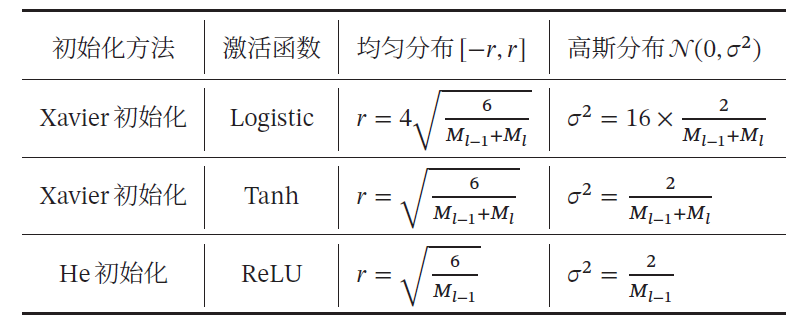
表1 Xavier初始化和He初始化的具体设置情况
五、基本实现(matlab)
clc
clear
close all
%load data and init
data = csvread('watermelon3.csv',1,1);
x_in=[data(:,1:2),data(:,4:end)];
y_in = data(:,3);
learning = 0.1;
costs=[];
%layer: w1=3x19 b1=1x3; 1layer: w2=1x3 b2=1x1
layer_dims = [size(x_in,2);3;1];
%Xavier init:used for update
para.w1 = unifrnd(-sqrt(6)/sqrt(layer_dims(1)+layer_dims(2)),sqrt(6)/sqrt(layer_dims(1)+layer_dims(2)),layer_dims(1),layer_dims(2));
para.b1 = zeros(1,layer_dims(2));
para.w2 = unifrnd(-sqrt(6)/sqrt(layer_dims(2)),sqrt(6)/sqrt(layer_dims(2)),layer_dims(2),layer_dims(3));
para.b2 = zeros(1,layer_dims(3));
%learn
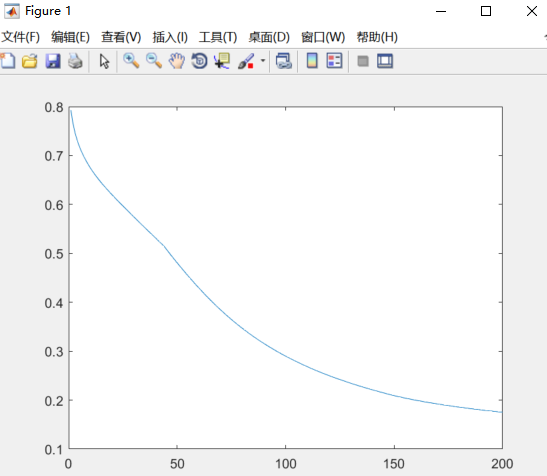
for i = 1:200
%% Forward
%1.forward first layer
layer1.in = x_in;
layer1.w = para.w1;
layer1.b = para.b1;
layer1.z = layer1.in*layer1.w+repmat(layer1.b,size(layer1.in,1),1);
% 'relu' activate function
layer1.out = max(0,layer1.z);
%2.forward second layer
layer2.in = layer1.out;
layer2.w = para.w2;
layer2.b = para.b2;
layer2.z = layer2.in*layer2.w+repmat(layer2.b,size(layer2.in,1),1);
% 'sigmoid' activate function
layer2.out = 1./(1+exp(-layer2.z));
%% Backward
%二分类交叉熵损失函数,反向传播,求导=-yr/yh + (1-yr)/(1-yh),公式(5-10)求gi
%参考:https://www.cnblogs.com/nullzx/p/9234058.html
back1.gi = -y_in./layer2.out + (1-y_in)./(1-layer2.out);
m = length(back1.gi);
%sigmoid 求导 5.9
exp_z = 1./(1+exp(-layer2.z));
back1.dz = back1.gi .* exp_z .* (1-exp_z);
back1.dw = back1.dz'*layer2.in/m;
back1.db = sum(back1.dz)/m;
back1.dy = back1.dz*layer2.w';
%back2
%relu 求导:输出为负值,求导为<0 = 0 ; >0 = 1
m = length(back1.dy);
back2.dz = back1.dy;
back2.dz(find(layer1.z<=0)) = 0;
back2.dw = back2.dz'*layer1.in/m;
back2.db = sum(back2.dz)/m;
back2.dy = back2.dz*layer1.w';
%% update
para.w1 = para.w1 - learning*back2.dw';
para.b1 = para.b1 - learning*back2.db;
para.w2 = para.w2 - learning*back1.dw';
para.b2 = para.b2 - learning*back1.db;
%% Cost
%sigmod二分类交叉熵
cost = -(y_in'*log(layer2.out) + ((1-y_in')*log(1-layer2.out)) )/length(y_in);
costs = [costs;cost];
end
plot(costs);
%% predict
%使用梯度迭代的参数进行一次前向即可
%% Forward
%1.forward first layer
layer1.in = x_in;
layer1.w = para.w1;
layer1.b = para.b1;
layer1.z = layer1.in*layer1.w+repmat(layer1.b,size(layer1.in,1),1);
% 'relu' activate function
layer1.out = max(0,layer1.z);
%2.forward second layer
layer2.in = layer1.out;
layer2.w = para.w2;
layer2.b = para.b2;
layer2.z = layer2.in*layer2.w+repmat(layer2.b,size(layer2.in,1),1);
% 'sigmoid' activate function
layer2.out = 1./(1+exp(-layer2.z));
y_pre = layer2.out;
y_pre(find(layer2.out>=0.5))=1;
y_pre(find(layer2.out<0.5))=0;
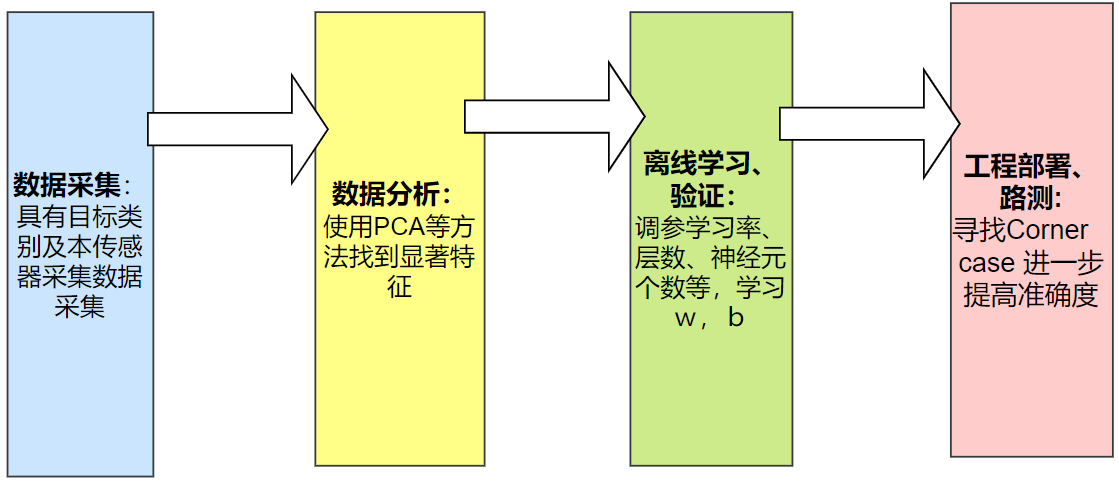
六、处理流程
(1)首先要获取目标数据集,采集数据一般使用GPS定位法、速腾有Reference、摄像头和毫米波雷达融合,使用摄像头识别目标及毫米波获取的目标信息等方法获取数据集。
(2)选取特征信息包括目标相对距离、速度、方位角,RCS,距离RCS,速度RCS,方位角RCS,本车yawRate(本车运动姿态)
(3)选择合适NN参数,学习、预测
(4)雷达板子工程部署NN,上位机显示处理可视化
参考:
机器学习西瓜书——神经网络中的误差逆传播算法(BP算法) | TriaL (bjtu-hxs.github.io)
深度学习常用激活函数之— Sigmoid & ReLU & Softmax_Leo_Xu06的博客-CSDN博客_relu与sigmoid
激活函数:sigmoid、softmax、Relu_thisissally的博客-CSDN博客_激活函数softmax

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)