networkx学习(五)无标度网络
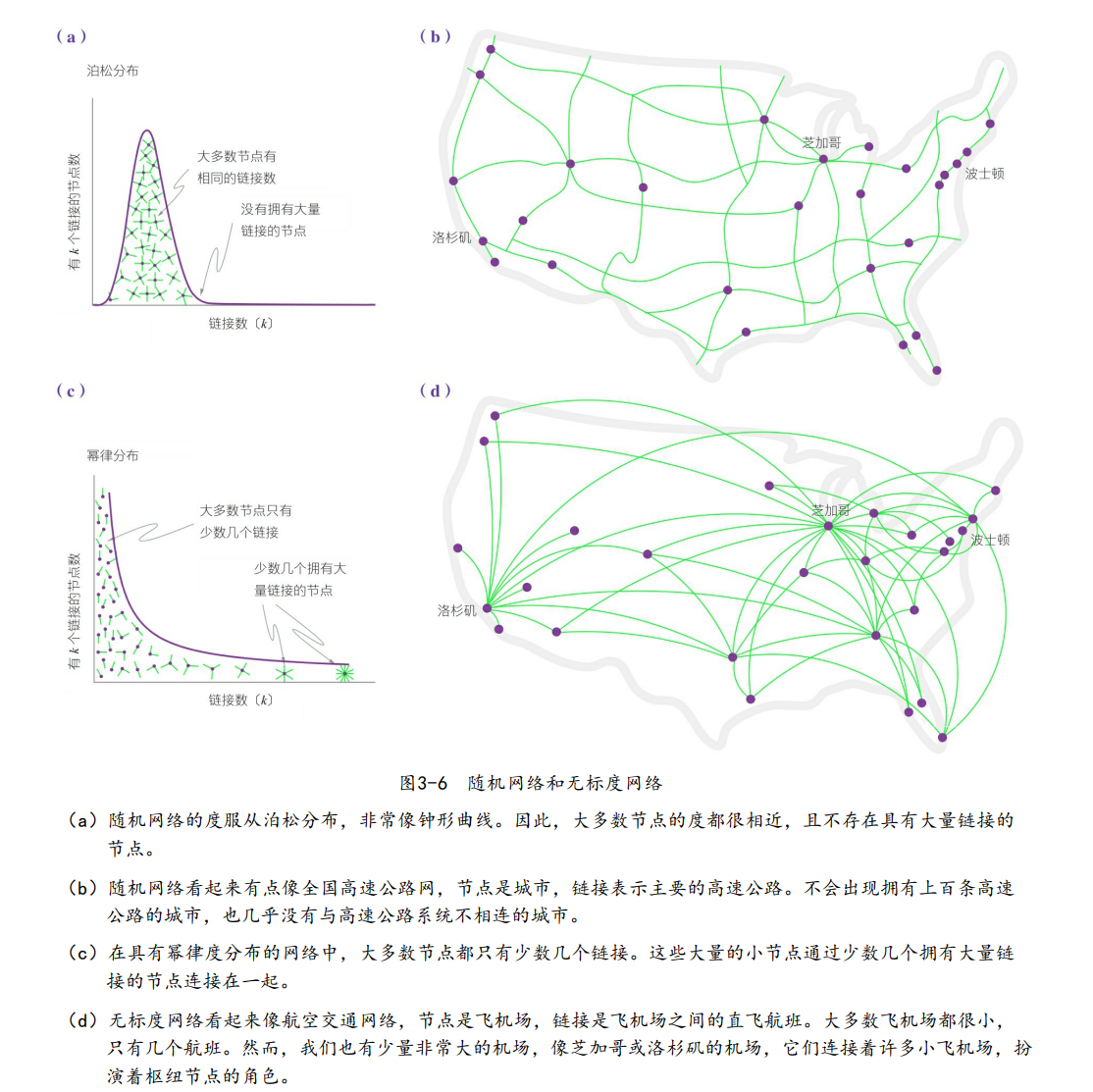
在万维网的连接图背后似乎隐藏着大量的随机性。然而,仔细观察就会发现,万维网地图和随机网络之间存在一些令人费解的差异。实际上,在随机网络中,高度连接的节点——枢纽节点,是几乎不可能出现的。相比之下,万维网中同时存在大量度很小的节点和少数几个枢纽节点——拥有链接数异常多的节点。
networkx学习(五)无标度网络
参考:参考来源,《巴拉巴西网络科学》
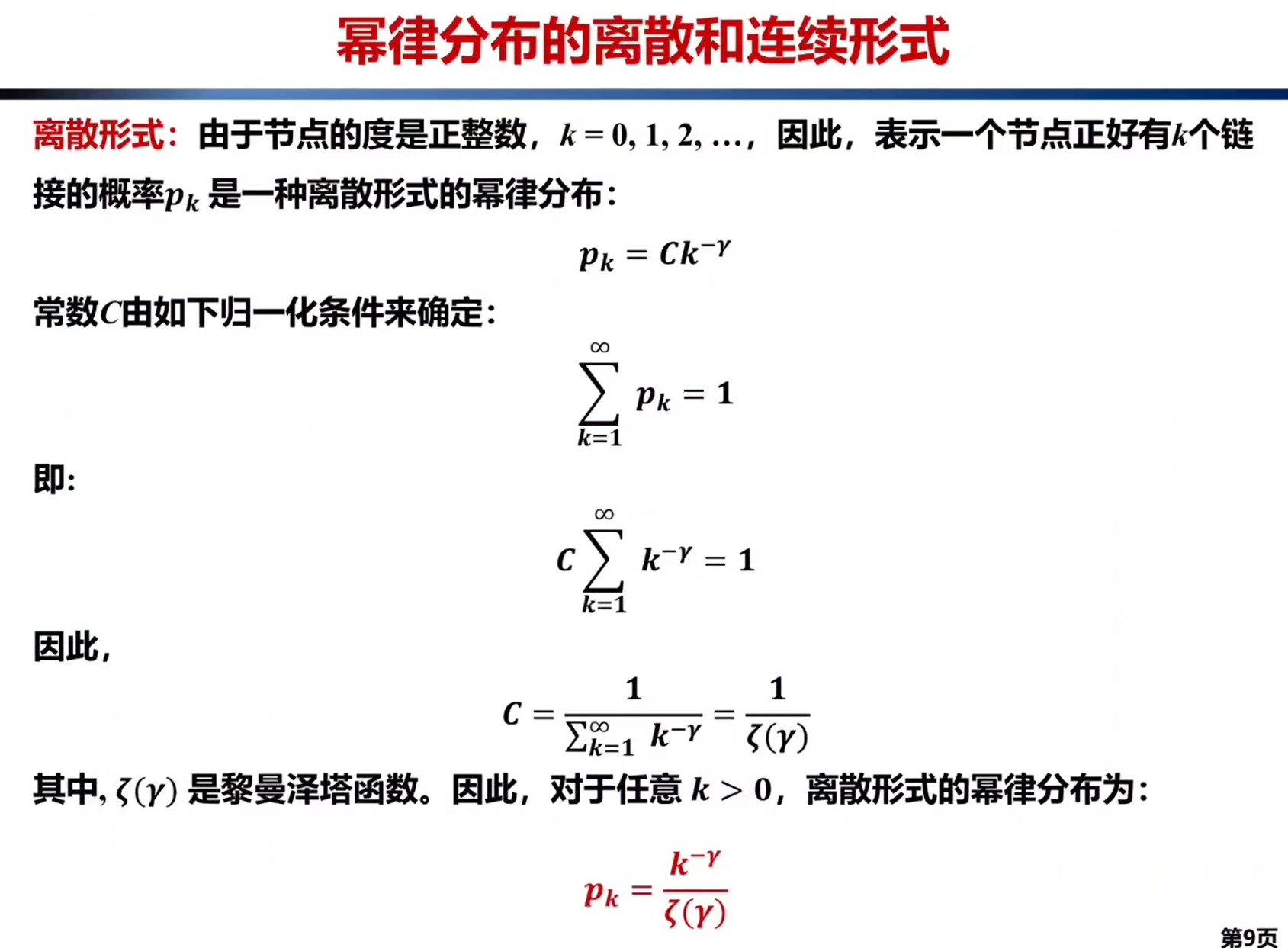
无标度网络:
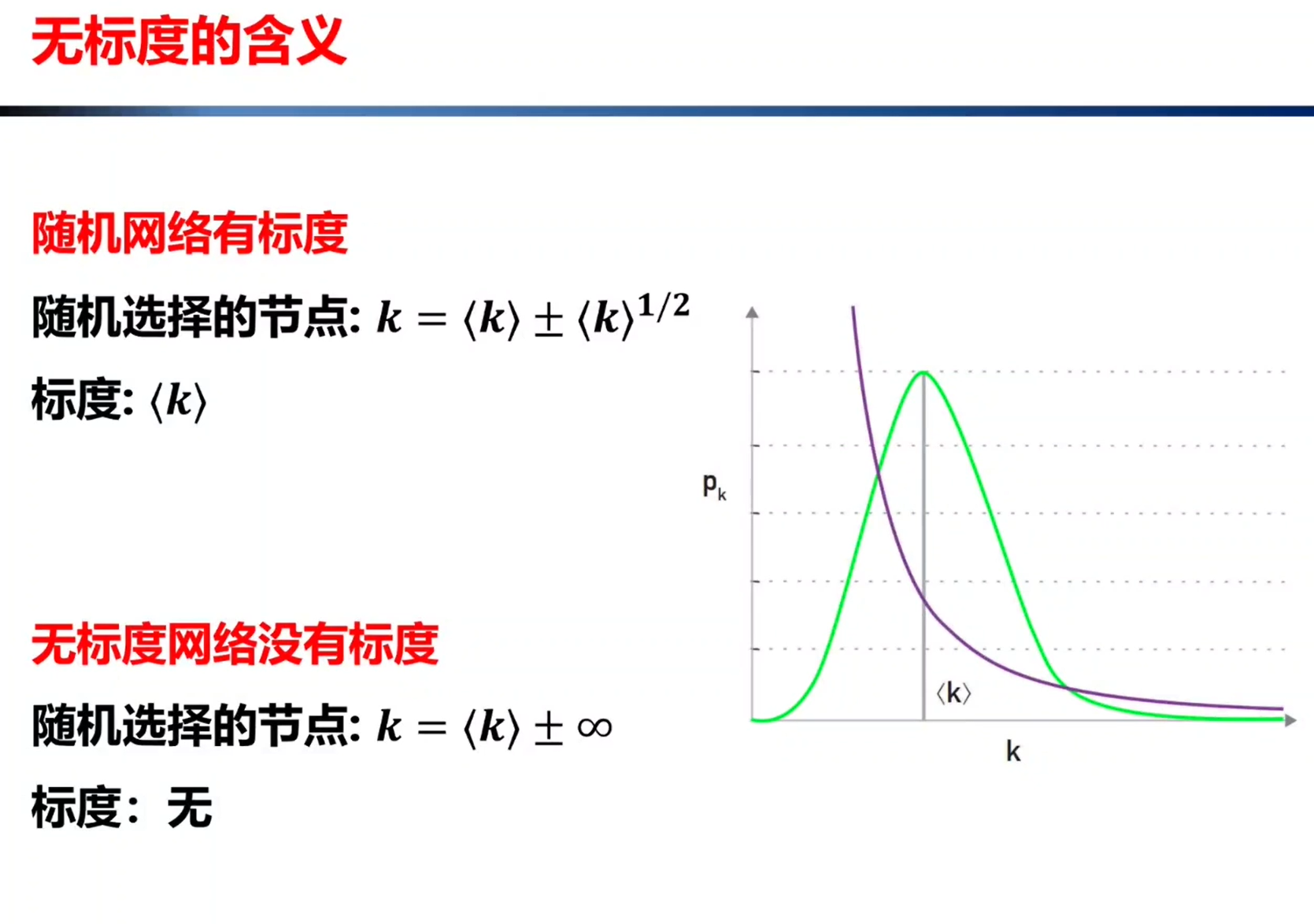
对于随机网络和规则网络,度分布区间非常狭窄,大多数节点都集中在节点度均值< k >的附近,说明节点具有同质性,因此< k >可以被看作是节点度的一个特征标度。而在节点度服从幂律分布的网络中,大多数节点的度都很小,而少数节点的度很大,说明节点具有异质性,这时特征标度消失。这种节点度的幂律分布为网络的无标度特性。
1.无标度性质
在万维网的连接图背后似乎隐藏着大量的随机性。然而,仔细观察就会发现,万维网地图和随机网络之间存在一些令人费解的差异。实际上,在随机网络中,高度连接的节点——枢纽节点,是几乎不可能出现的。相比之下,万维网中同时存在大量度很小的节点和少数几个枢纽节点——拥有链接数异常多的节点。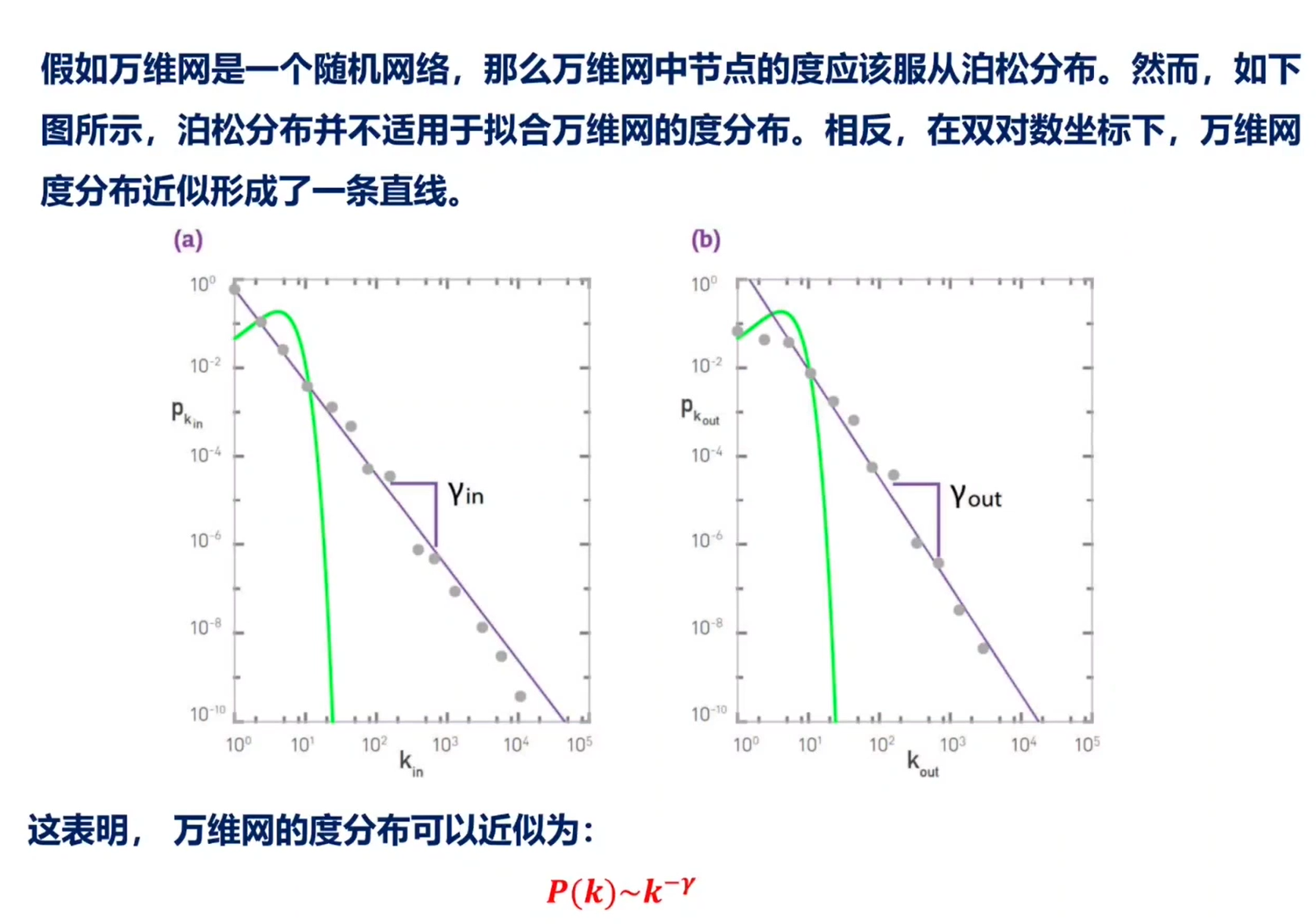


实践一
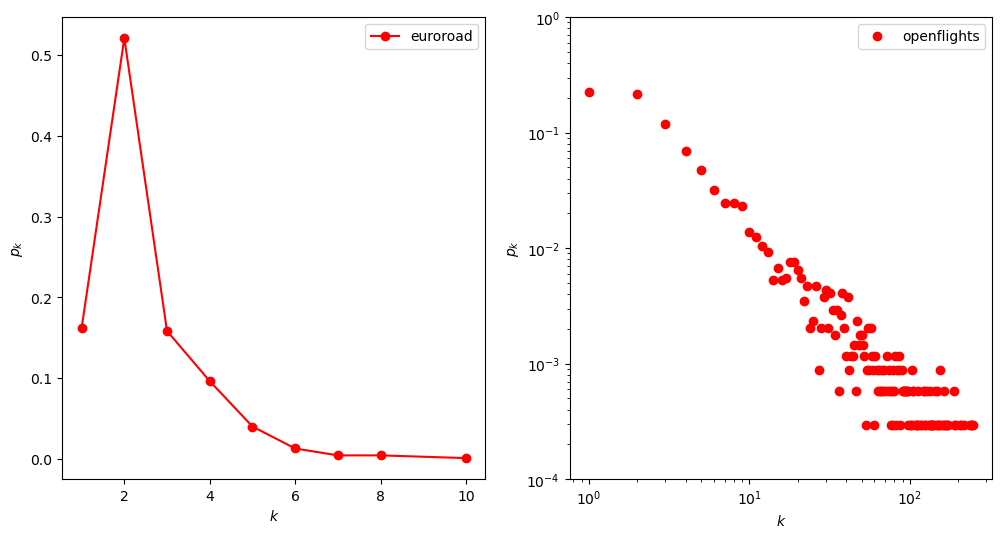
1、道路网络和航空网络的度分布
# 导入库
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 加载euroroad数据集
df1 = pd.read_csv("euroroad.csv")
G1 = nx.from_pandas_edgelist(df1, 'source', 'target', create_using = nx.Graph())
# 加载openflights数据集
df2 = pd.read_csv("openflights.csv")
G2 = nx.from_pandas_edgelist(df2, 'source', 'target', create_using = nx.Graph())
print(len(G1.nodes()), len(G2.nodes()))
# 定义求度分布的函数
def get_pdf(G):
all_k = [G.degree(i) for i in G.nodes()]
k = list(set(all_k)) # 获取所有可能的度值
N = len(G.nodes())
Pk = []
for ki in sorted(k):
c = 0
for i in G.nodes():
if G.degree(i) == ki:
c += 1
Pk.append(c/N)
return sorted(k), Pk
deg1 = [G1.degree(i) for i in G1.nodes()]
deg2 = [G2.degree(i) for i in G2.nodes()]
k1, Pk1 = get_pdf(G1)
k2, Pk2 = get_pdf(G2)
plt.figure(figsize=(12,6))
plt.subplot(121)
plt.plot(k1, Pk1, 'ro-', label='euroroad')
plt.legend(loc=0)
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.subplot(122)
plt.plot(k2, Pk2, 'ro', label='openflights')
plt.legend(loc=0)
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.ylim([1e-4,1])
plt.xscale("log")
plt.yscale("log")
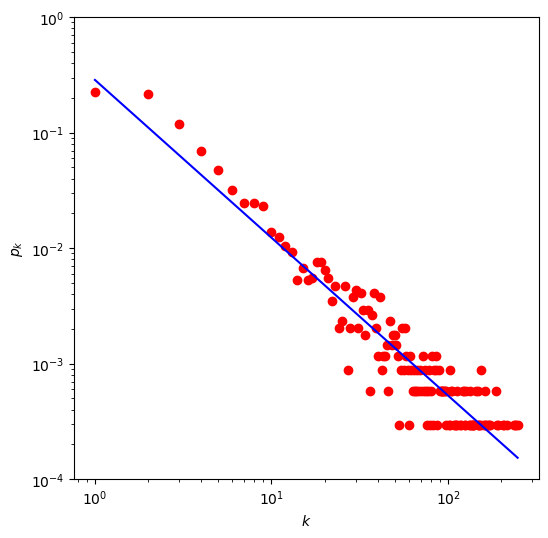
2、对于航空网络,粗略拟合度分布
from scipy import optimize
def fit_line(x, a, b):
return a * x + b
x = np.log10(np.array(k2))
y = np.log10(np.array(Pk2))
kmin2, kmax2 = min(deg2), max(deg2)
# 拟合
a, b = optimize.curve_fit(fit_line, x, y)[0]
print("斜率 a = ", a)
x1 = np.arange(kmin2, kmax2, 0.01)
y1 = (10**b) * (x1 ** a)
plt.figure(figsize=(6,6))
plt.plot(k2, Pk2, 'ro')
plt.plot(x1, y1, 'b-')
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.ylim([1e-4,1])
plt.xscale("log")
plt.yscale("log")
import powerlaw
# 安装:pip install powerlaw
data = [G2.degree(i) for i in G2.nodes()]
print(max(data))
fit = powerlaw.Fit(data)
print(fit)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)
plt.figure(figsize=[6, 4.8])
fig = fit.plot_pdf(marker = 'o', color='b', linewidth=1)
fit.power_law.plot_pdf(color='b', linestyle='-', ax=fig)
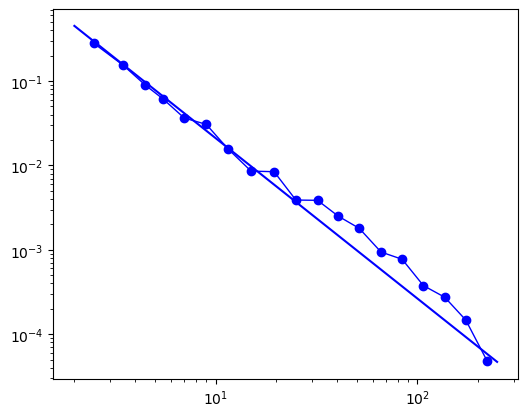
fig = fit.plot_ccdf(marker = 'o', color='b', linewidth=1)
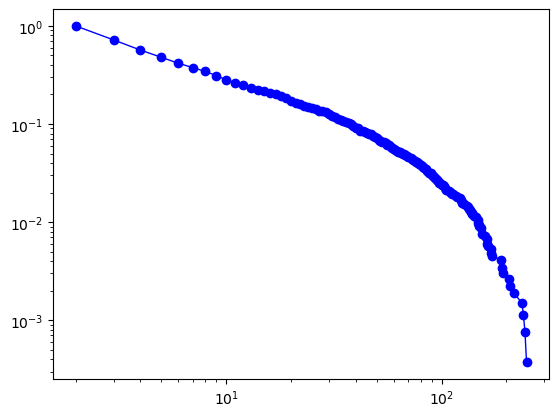
3、生成符合幂律分布的度序列
from networkx.utils import powerlaw_sequence
degree_seq = powerlaw_sequence(10000, exponent=2.5)
int_deg = [int(di) for di in degree_seq]
# print(int_deg)
fit = powerlaw.Fit(int_deg)
print(fit)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)
plt.figure(figsize=[6, 4.8])
fig = fit.plot_pdf(marker = 'o', color='b', linewidth=1)
fit.power_law.plot_pdf(color='b', linestyle='-', ax=fig)
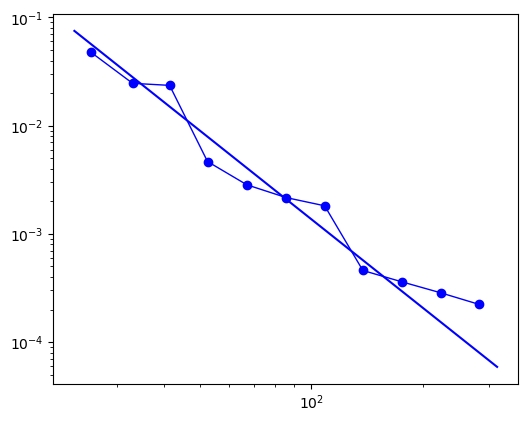
2.枢纽节点
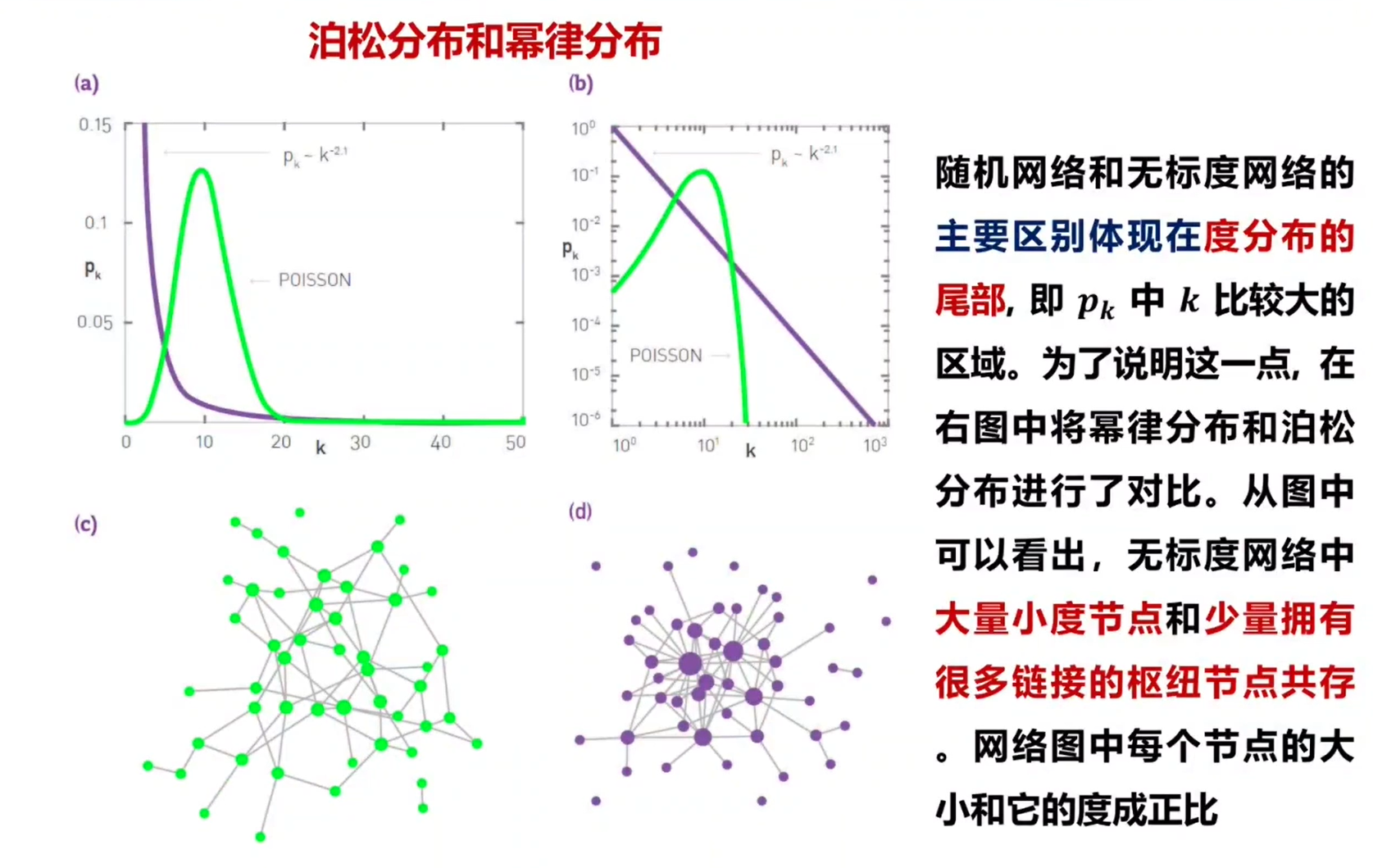
(1)当k比较小时,幂律分布在泊松分布之上。这表明,无标度网络中有大量度比较小的节点,而随机网络中这样的节点很少出现。
(2)当k处于< k > 附近时,泊松分布在幂律分布之上。这表明,随机网络中大多数节点的度在 < k >附近。
(3)当k比较大时,幂律分布再次位于泊松分布之上。如果将pk画在双对数坐标下,这种差异会格外明显。这一现象表明,在无标度网络中观察到一个大度节点——枢纽节点的概率,要比在随机网络中观察到这样一个节点的概率大好几个数量级。
最大的枢纽节点


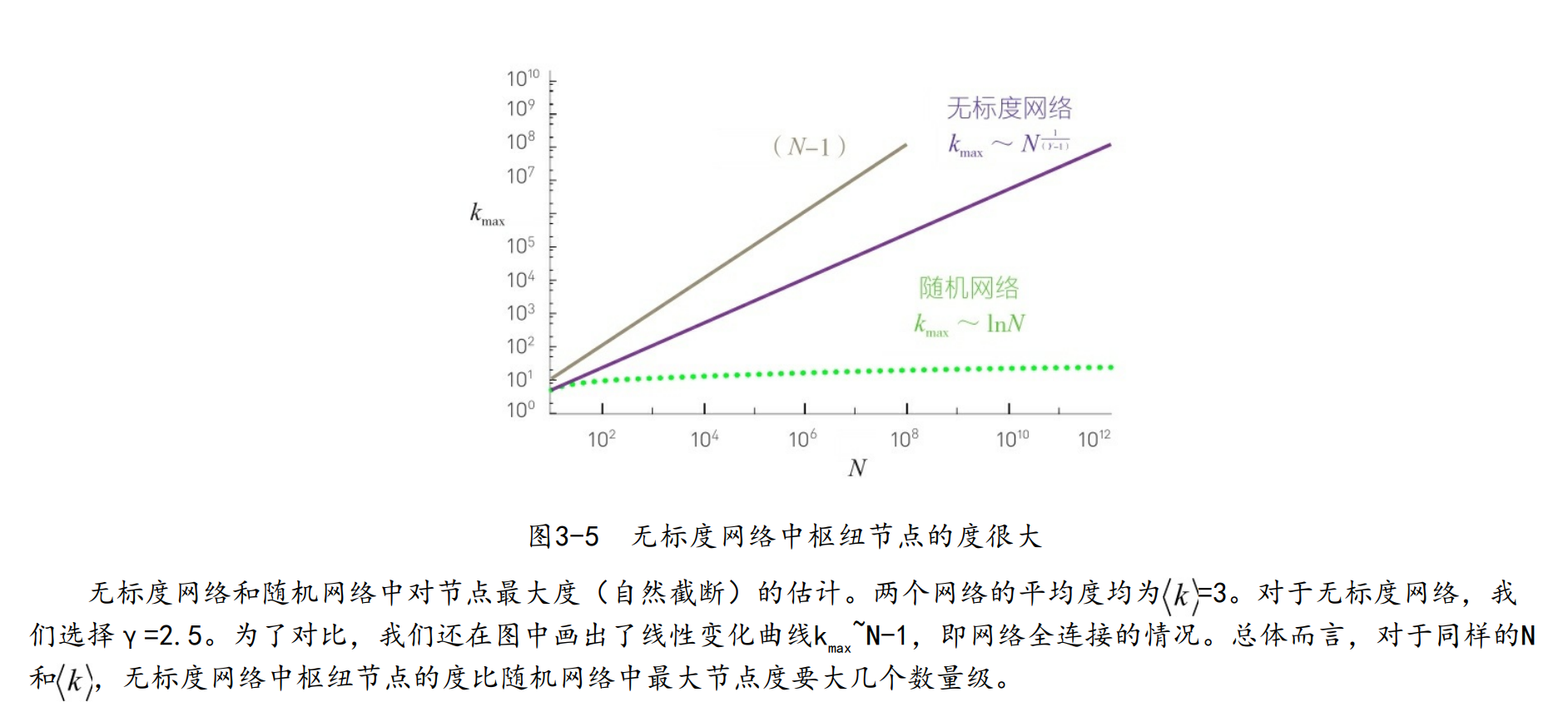
3.无标度的含义


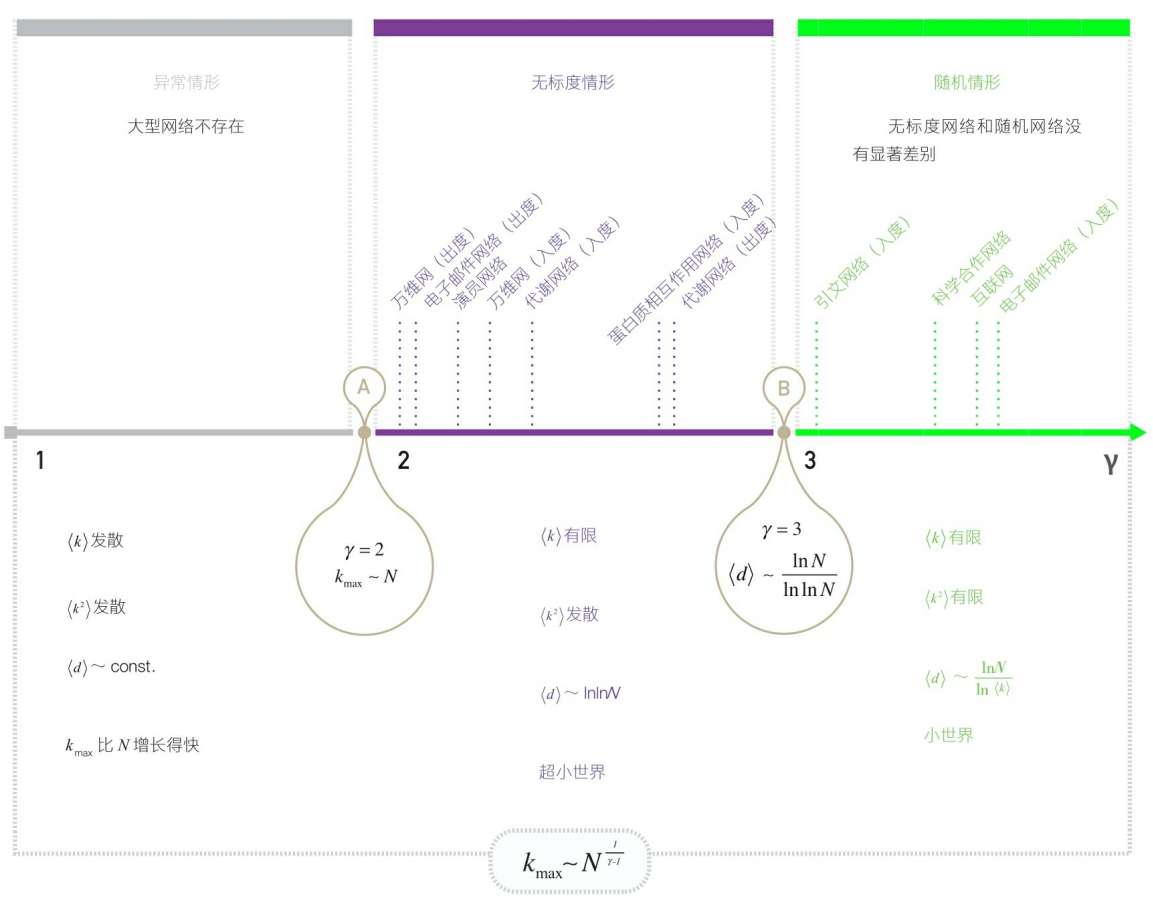


4.超小世界性质
无标度网络中枢纽节点的出现,引发了一个有趣的问题:枢纽节点会影响小世界性质吗?枢纽节点的确会影响小世界性质:航空公司正是通过建造枢纽节点来减少机场间转机次数的。计算结果也支持上述预期:同等条件下,无标度网络中节点间的平均距离比随机网络中节点间的平均距离要小。
实践二
给定度分布生成网络
配置模型、度保持的网络随机化,以及隐参数模型都能生成具有预定义好的度分布的网络,从而可以帮助我们对网络的关键特性进行解析计算。每当要研究“某个特定网络性质是不是网络度分布的结果”或者“该网络性质是不是度分布之外网络中涌现出的一种新性质”时,我们都会使用这几种算法来生成网络。在使用这些算法时,我们必须清楚它们的局限性:
● 这些算法并不能告诉我们,为什么网络具有某种特定的度分布。理解某个观
测到的度分布pk的形成原因,是第5章和第6章的主题。
● 一些重要的网络特性,包括聚集特性(第8章)和度相关性(第6章),在随机化过程中将会消失。
因此,这些算法生成的网络有点像一幅画的照片:乍一看和原画似乎是一样的,但仔细观察就会发现,包括画布质感和笔触在内的很多细节都丢失了。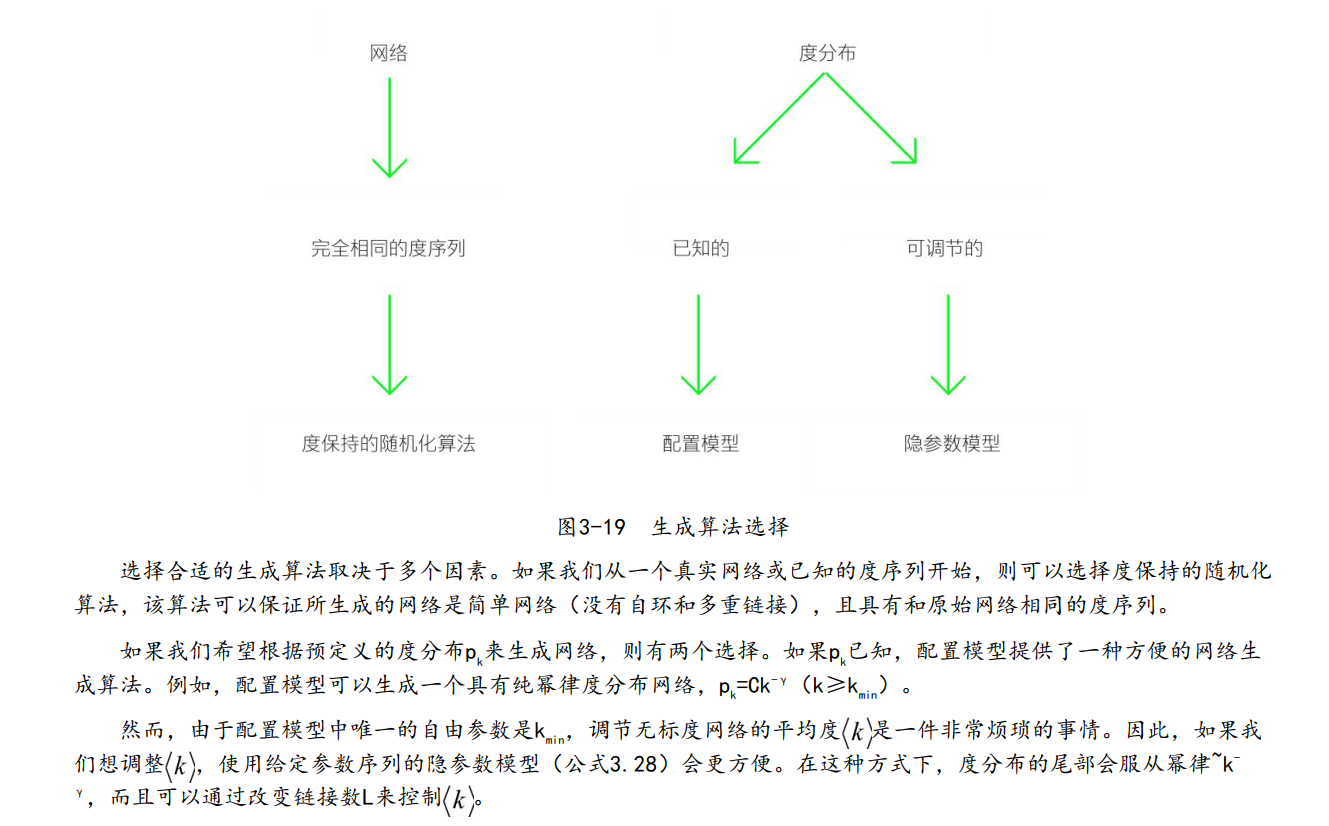
1、配置模型生成给定度序列的网络
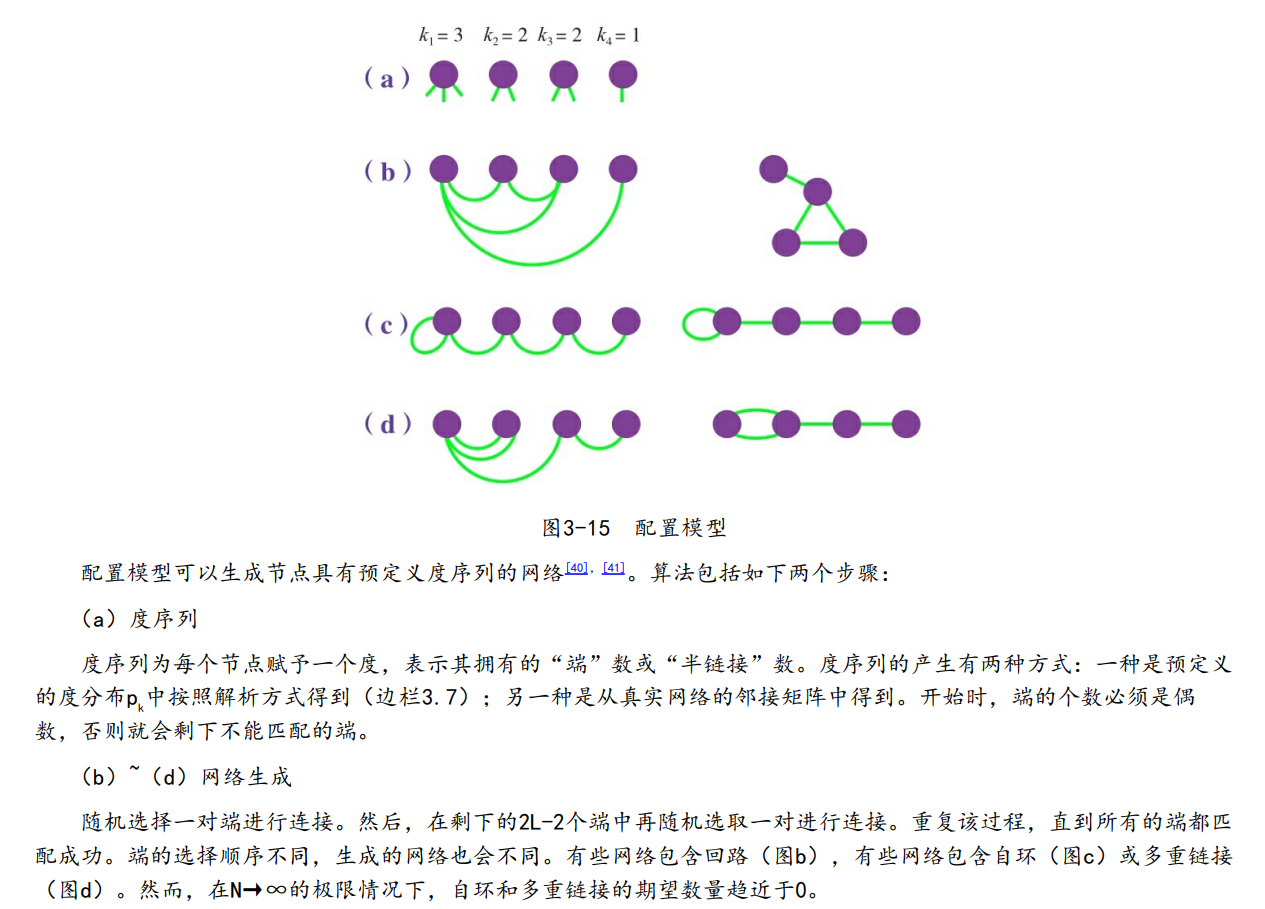
# 导入库
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from networkx.utils import powerlaw_sequence
from my_utils import *
n, gamma = 5000, 2.1
degree_seq = powerlaw_sequence(n, gamma)
int_deg = [int(di) for di in degree_seq]
while sum(int_deg)%2 != 0:
degree_seq = powerlaw_sequence(n, gamma)
int_deg = [int(di) for di in degree_seq]
G = nx.configuration_model(int_deg)
# 该模型会生成自环和多重链接,而这些在真实网络中通常是不会出现的
for e in G.edges():
if e[0]==e[1]:
print(e)
k, Pk = get_pdf(G)
plt.figure(figsize=(6,4.8))
plt.plot(k, Pk, 'ro')
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.xscale("log")
plt.yscale("log")
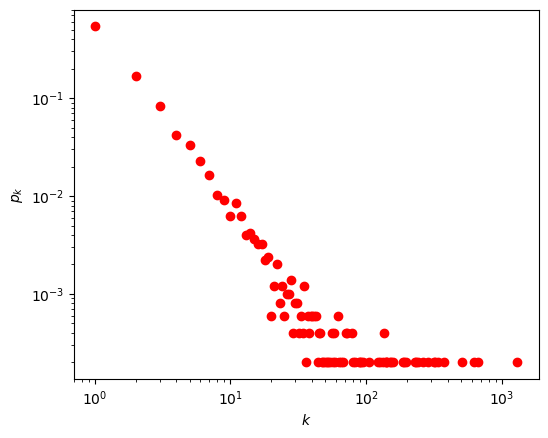
2、隐参数模型生成给定度分布指数的无标度网络
N = 5000
gamma = 2.1
avk = 6.0
L = int(avk*N/2)
G = generate_SF_network(N, gamma, L)
k, Pk = get_pdf(G)
plt.figure(figsize=(6, 4.8))
plt.plot(k, Pk, 'ro')
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.xscale("log")
plt.yscale("log")
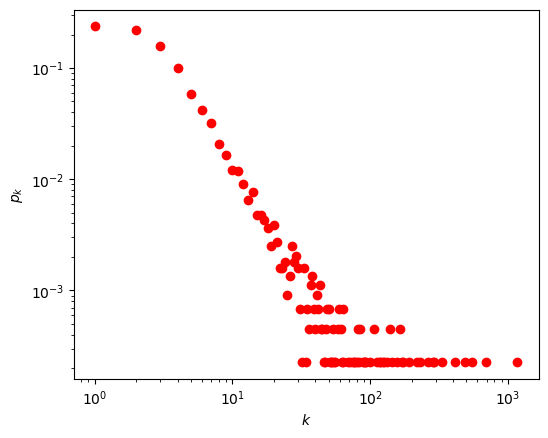
3、度保持的网络随机化
# 加载蛋白质网络数据集
df = pd.read_csv("protein_interaction.csv")
G = nx.from_pandas_edgelist(df, 'source', 'target', create_using = nx.Graph())
print(len(G.nodes()), len(G.edges()))
# 删除self-loops
self_edges = []
for e in G.edges():
if e[0]==e[1]:
self_edges.append(e)
G.remove_edges_from(self_edges)
Gcc = sorted(nx.connected_components(G), key=len, reverse=True)
# 得到图G的最大连通组件
LCC = G.subgraph(Gcc[0])
# 获取原始网络的最大连通子图节点数和连边数
N, M = len(LCC.nodes), len(LCC.edges())
print(N, M)
# nx.draw(LCC, pos=nx.kamada_kawai_layout(LCC), node_size=30, node_color="red")
print(nx.average_clustering(LCC))
# 生成度保持的随机化网络:调用double_edge_swap函数
newG = LCC.copy()
G_d = nx.double_edge_swap(newG, nswap=M, max_tries=5*M)
print(nx.average_clustering(G_d))
# nx.draw(G_d, pos=nx.kamada_kawai_layout(G_d), node_size=30, node_color="red")
# 生成完全随机化的网络
G_r = nx.gnm_random_graph(N, M)
测试小世界性质
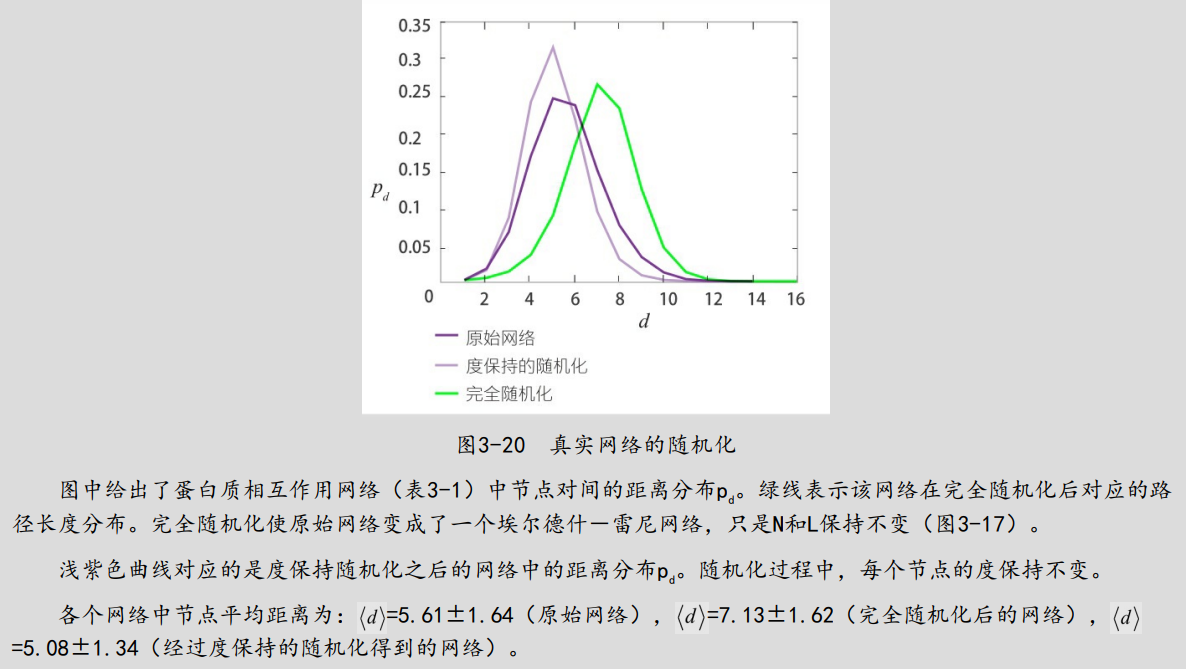
all_sp1, Pl = get_pdf_spl(newG)
all_sp1_d, Pl_d = get_pdf_spl(G_d)
all_sp1_r, Pl_r = get_pdf_spl(G_r)
plt.figure(figsize=(6,6))
plt.plot(all_sp1, Pl, 'ro-', label='original network')
plt.plot(all_sp1_d, Pl_d, 'bs-', label='degree-preserving random network')
plt.plot(all_sp1_r, Pl_r, 'gv-', label='random network')
plt.legend(loc=0)
plt.xlabel("$d$")
plt.ylabel("$p_d$")
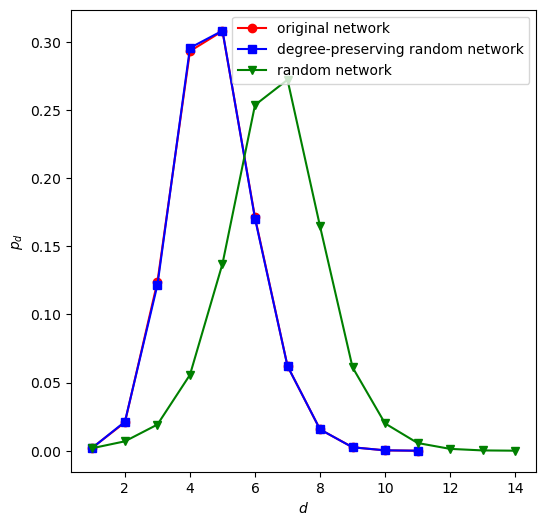
print(nx.is_connected(LCC))
print(nx.is_connected(G_d))
k1, Pk1 = get_pdf(LCC)
k2, Pk2 = get_pdf(G_d)
k3, Pk3 = get_pdf(G_r)
plt.figure(figsize=(6, 4.8))
plt.plot(k1, Pk1, 'ro')
plt.plot(k2, Pk2, 'b*')
plt.plot(k3, Pk3, 'gv')
plt.xlabel("$k$")
plt.ylabel("$p_k$")
plt.xscale("log")
plt.yscale("log")
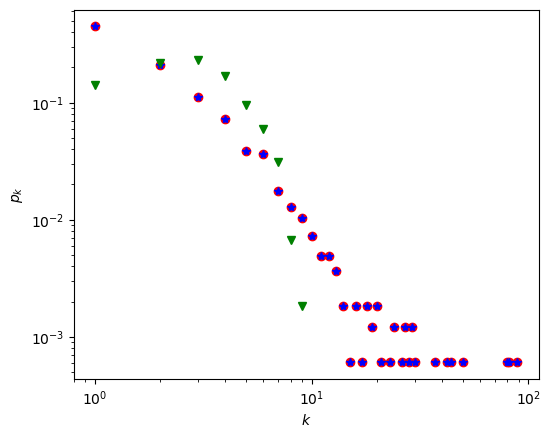
实践三
绘制度分布

1、精确地绘制幂律分布(见书籍进阶阅读3.B)
# 导入库
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
import powerlaw
# internet网络
edges = [tuple(line) for line in np.loadtxt("internet.txt")]
G1 = nx.Graph()
G1.add_edges_from(edges)
degree_seq1 = [G1.degree(i) for i in G1.nodes()]
# 对数坐标,线性分箱
powerlaw.plot_pdf(degree_seq1, linear_bins = True, color = 'r', marker='o')
# 对数坐标,对数分箱
powerlaw.plot_pdf(degree_seq1, linear_bins = False, color = 'b', marker='s')
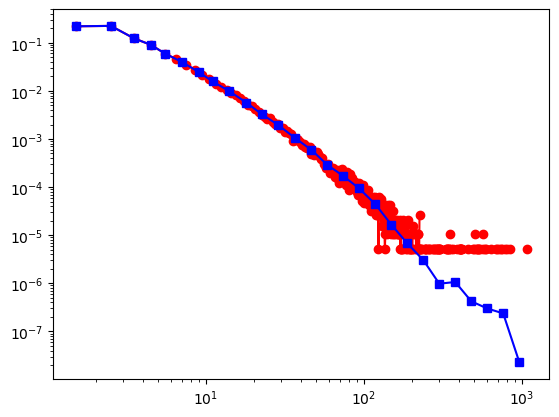
# 对数坐标,累积度分布
powerlaw.plot_ccdf(degree_seq1, color = 'b', marker='o')
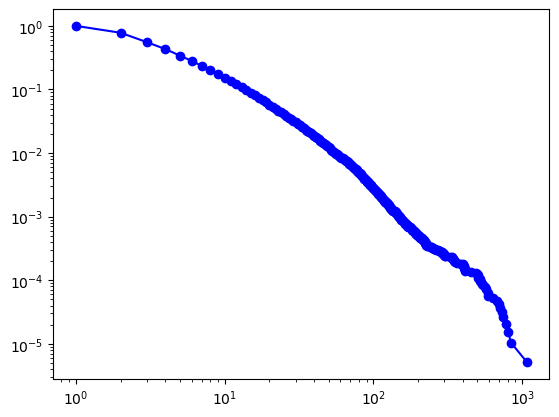
# BA无标度网络
G2 = nx.barabasi_albert_graph(100000,2)
degree_seq2 = [G2.degree(i) for i in G2.nodes()]
# 对数坐标,线性分箱
powerlaw.plot_pdf(degree_seq2, linear_bins = True, color = 'r', marker='o')
# 对数坐标,对数分箱
powerlaw.plot_pdf(degree_seq2, linear_bins = False, color = 'b', marker='s')
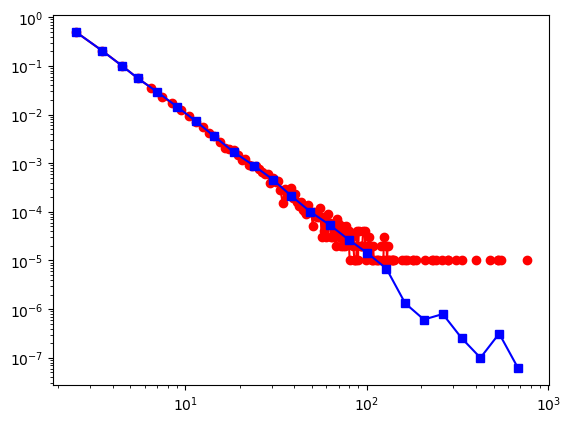
# 对数坐标,累积度分布
powerlaw.plot_ccdf(degree_seq2, color = 'b', marker='o')
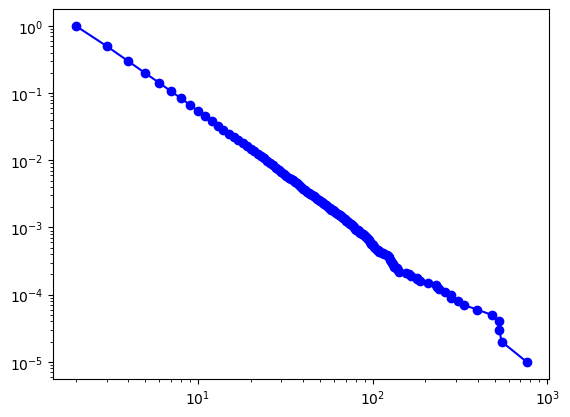
2、估计度指数(见书籍进阶阅读3.C)
fit = powerlaw.Fit(degree_seq1)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)
fit = powerlaw.Fit(degree_seq2)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)
fit = powerlaw.Fit(degree_seq2, xmin = 1.0)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)
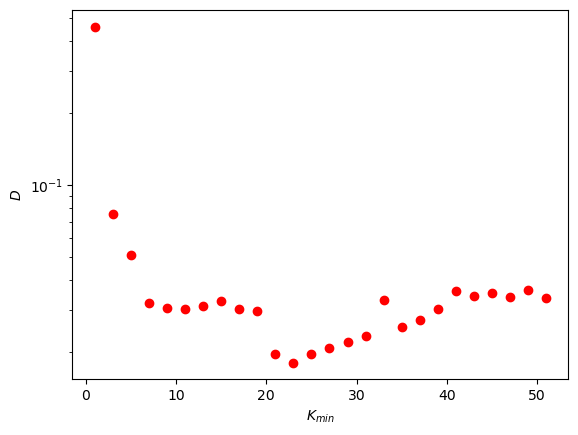
D_list = []
for x in np.linspace(1,51,26):
fit = powerlaw.Fit(degree_seq2, xmin = x)
D_list.append(fit.power_law.D)
plt.plot(np.linspace(1,51,26), D_list, "ro")
plt.xlabel("$K_{min}$")
plt.ylabel("$D$")
plt.yscale("log")
5.BA无标度网络
总之,随机网络和真实网络之间有两个重要的不同之处:
1.生长
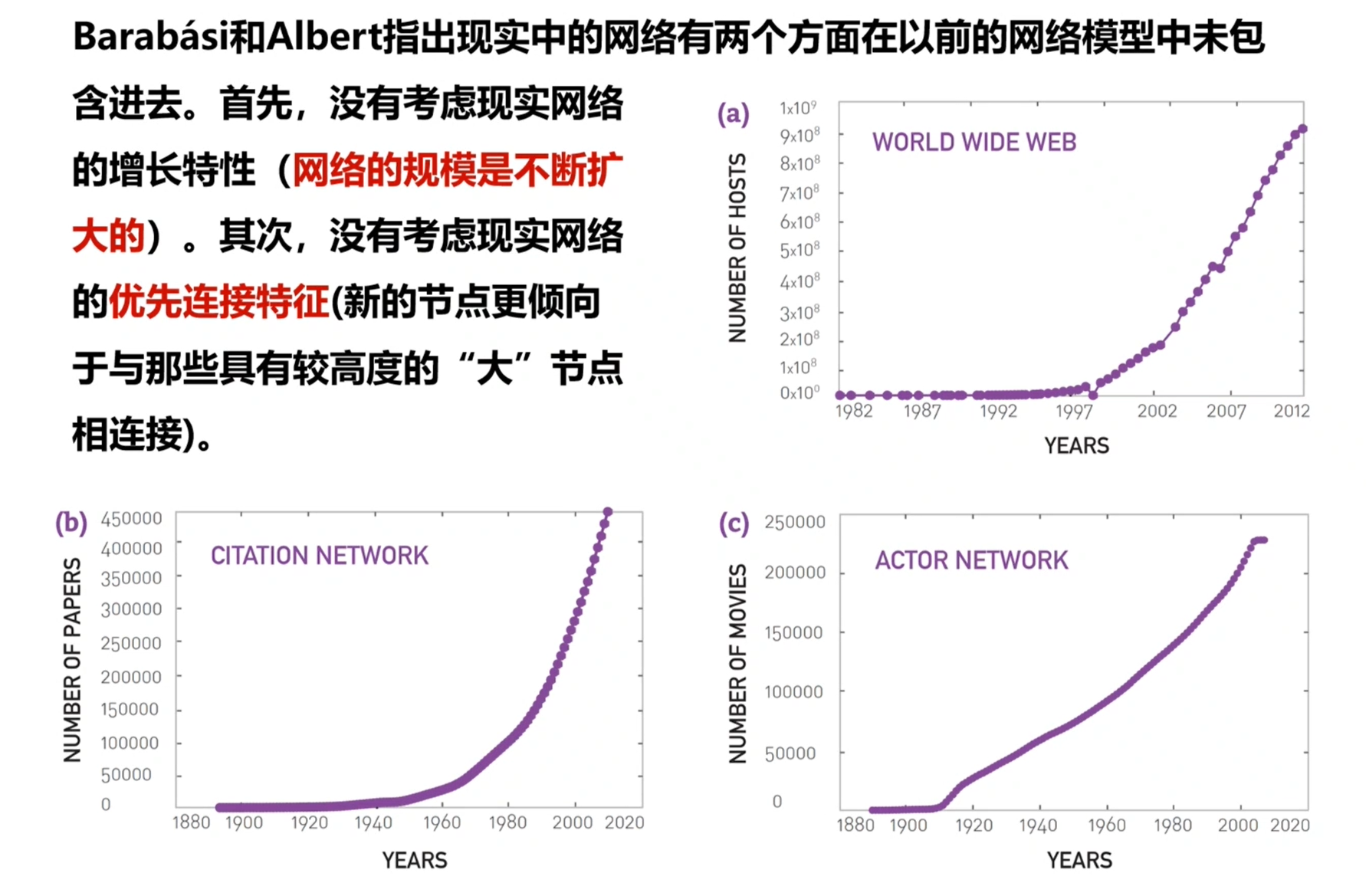
真实网络是一个生长过程的结果,因此其节点数N会持续增加。相反,随机网络模型假设节点数N是固定的。
2.偏好连接
真实网络中,新节点倾向于和链接数高的节点相连。相反,随机网络中的节点随机地选择节点进行连接。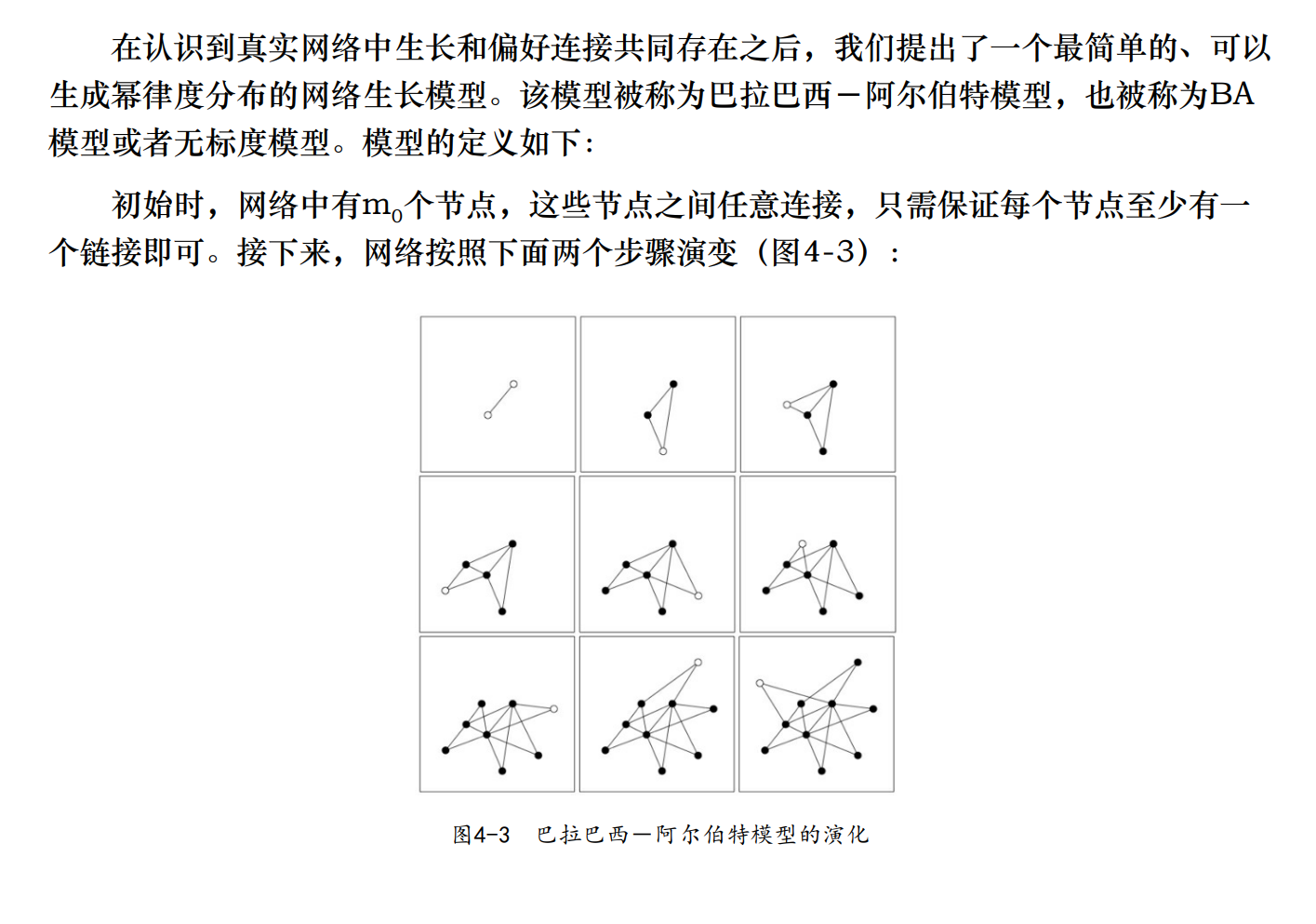


巴拉巴西-阿尔伯特模型总结:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)