哈希(Hash)算法与查找
哈希算法(Hash),简单来说就是一个“数据粉碎机”。你给它输入任意内容(文字、文件、密码等),它会吐出一串固定长度的乱码(叫“哈希值”)。
本文将尽量说人话,讲清楚哈希算法
参考
概述
哈希算法(Hash),简单来说就是一个“数据粉碎机”。你给它输入任意内容(文字、文件、密码等),它会吐出一串固定长度的乱码(叫“哈希值”)。
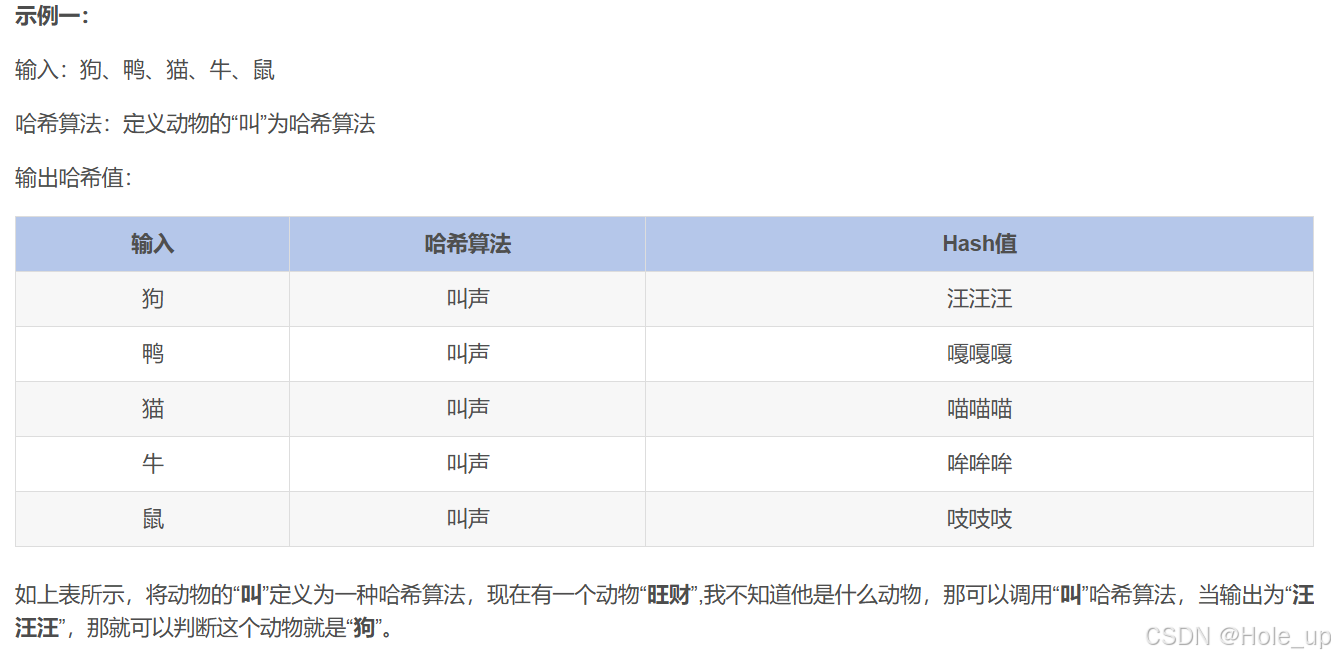
特点
-
唯一性:
- 就像人的指纹,不同数据算出的哈希值几乎不会重复(比如“你好”和“Hello”的哈希完全不同)。
- 例外:极小的概率会重复(叫“哈希碰撞”),但算法会尽量避免。
-
不可逆:
- 只能从数据算哈希值,不能从哈希值反推原始数据(就像榨汁机不能把果汁变回水果)。
- 所以常用它存密码,服务器只存哈希值,即使泄露也无法还原密码。
-
固定长度:
- 无论输入是1个字还是1GB电影,输出的哈希值长度都一样(比如SHA-256算法固定输出256位)。
-
敏感度:
- 输入数据哪怕改1个标点(比如“Hi”→“Hi!”),哈希值会变得妈都不认。
常见用途
- 密码存储:网站不存你的密码,只存密码的哈希值,登录时对比哈希值。
- 文件校验:下载文件后算哈希值,对比官网给的哈希值,一致说明文件没被篡改。
- 区块链:比特币用哈希链接所有交易,确保数据不可篡改。
- 快速查找:哈希表(HashMap)用哈希值快速定位数据,比挨个查快得多。
哈希表
哈希是一种应用极其广泛的算法,其核心功能为:给定任意一个对象 A,能利用哈希表迅速找到以 A 的名义存储的结果。关键点如下:
- 这里的 A 必须是可哈希的;
- 这里的哈希表其实是一个数组;
- 所谓的迅速其实是利用哈希函数计算出这个可哈希对象 A 的哈希码(就是一个数字对应到哈希表数组中的某一个下标索引值),然后 O(1)O(1) 地在哈希表数组中索引出存储的内容。
举个例子。现在需要查询出你这学期翘了几次课,一个最直观的做法就是遍历数据库然后匹配你的学号(假设学号唯一),这样的时间复杂度为 O(n)O(n),空间复杂度为 O(1)O(1)。但如果提前利用哈希算法存储了每一个学号对应的翘课次数,那么在输入你的学号后,就可以通过哈希函数计算出你学号对应的哈希码,然后在哈希表数组中索引出翘课的次数即可,这样的时间复杂度为 O(1)O(1),空间复杂度为 O(n)O(n)。
大多数编程语言都实现了哈希的功能,只要对象是可哈希的,就可以利用该算法完成空间换时间的操作。例如 C++ 中的 unordered_map 类、Python 中的 dict 类、Java 中的 HashMap 类等。
哈希冲突。当然,哈希算法没法保证不同对象的哈希码都是不同的,有小概率会发生不同的对象映射出了相同的哈希码,此时就发生了哈希冲突。为了解决这个问题,要么优化哈希函数从而降低哈希冲突的概率,要么修改哈希表的一维数组结构,彻底解决哈希冲突。我们关注后者,有两种方法:
- 拉链法 (Chaining)。我们仍然沿用一维数组作为哈希表,只不过将数组元素修改为单链表。一旦发生哈希冲突映射到了同一个数组位置,就在对应位置的单链表中往后拉链即可;【当发生冲突时,在冲突位置拉链表来解决】
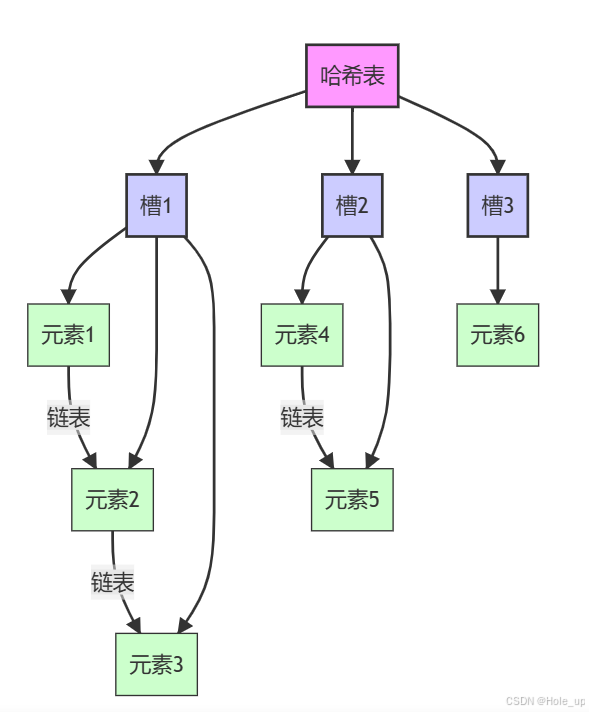
- 开放地址法 (Open Addressing)。该法保持原来的一维数组结构不变,将产生哈希冲突的元素移动到其他还没有被占用的位置(称为空桶)存储。这种方法在频繁产生哈希冲突时性能较差。而为了找到其他空位,开放地址法需要进行「空桶探测」,常见的探测方法有线性探测(从产生冲突的地方开始沿着某个方向枚举)、双重哈希探测(利用第二个哈希函数探测其余位置)。【每个槽直接存储元素,当发生哈希冲突时,会使用探查序列在表中寻找下一个空闲的槽。】

哈希表的数据结构。在 C++ 的 unordered_map 库中,unordered_map 与 unordered_multimap 的基类 _Hashtable 定义了哈希表的具体结构。具体地,其定义的哈希表是一维动态数组,数组元素是前向链表(即单链表)。
哈希查找(快速查找)
快速查找算法
想象你有一堆杂乱的书,现在想找一本《哈利波特》。
- 笨办法:一本一本翻,直到找到(线性查找,慢)。
- 聪明办法:先按书名首字母排序,直接跳到"H"那堆找(快速查找,快)。
快速查找的核心:用某种方式(比如哈希、二分、索引)跳过无关数据,直奔目标。
快速查找 = 跳过无关数据,哈希用字典,二分靠排序,索引像目录。
哈希查找代码实现
class HashTable:
def __init__(self, capacity=8):
self.capacity = capacity # 初始桶数量
self.size = 0 # 当前元素数量
self.threshold = 0.75 # 扩容阈值
self.buckets = [[] for _ in range(capacity)] # 桶数组(链表解决冲突)
def _hash(self, key):
"""哈希函数:将任意key转换为桶索引"""
return hash(key) % self.capacity # Python内置hash() + 取模
def _resize(self):
"""扩容:当元素数量超过阈值时重新分配桶"""
old_buckets = self.buckets
self.capacity *= 2
self.buckets = [[] for _ in range(self.capacity)]
# 将旧数据重新哈希到新桶
for bucket in old_buckets:
for key, value in bucket:
index = self._hash(key)
self.buckets[index].append((key, value))
def put(self, key, value):
"""插入键值对"""
if self.size / self.capacity > self.threshold:
self._resize()
index = self._hash(key)
bucket = self.buckets[index]
# 检查是否已存在该key
for i, (k, v) in enumerate(bucket):
if k == key:
bucket[i] = (key, value) # 更新值
return
# 新key则追加到链表
bucket.append((key, value))
self.size += 1
def get(self, key):
"""查找key对应的value"""
index = self._hash(key)
bucket = self.buckets[index]
for k, v in bucket:
if k == key:
return v
raise KeyError(f"Key not found: {key}")
def delete(self, key):
"""删除键值对"""
index = self._hash(key)
bucket = self.buckets[index]
for i, (k, v) in enumerate(bucket):
if k == key:
del bucket[i]
self.size -= 1
return
raise KeyError(f"Key not found: {key}")
def __str__(self):
"""可视化哈希表结构"""
result = []
for i, bucket in enumerate(self.buckets):
if bucket:
result.append(f"桶[{i}]: {bucket}")
return "\n".join(result)
# 测试用例
if __name__ == "__main__":
ht = HashTable(capacity=4)
# 插入数据
ht.put("apple", 3.5)
ht.put("banana", 2.8)
ht.put("orange", 4.2)
ht.put("pear", 3.0)
ht.put("kiwi", 7.1) # 触发扩容
print("--- 哈希表结构 ---")
print(ht)
print("\n--- 查找测试 ---")
print("banana的价格:", ht.get("banana")) # 2.8
try:
print(ht.get("watermelon"))
except KeyError as e:
print(e) # Key not found: watermelon
print("\n--- 删除测试 ---")
ht.delete("orange")
print(ht)
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)