若依框架-源码阅读_后端代码分析
通过使用 Map 来接收参数,开发者可以灵活地处理变化的请求参数,避免频繁修改已有的实体类,减少代码改动的风险,提升开发效率。注:实体类一旦修改,前端接收的数据就会发生变化,可能就会有风险。
目录
在之前已通过代码生成器生成了课程表的后端相关文件,接下来以这些文件为例,分析后端代码。

CourseController


用于接收前端的请求,调用service处理业务逻辑,并返回结果。Controller中的方法遵循了Restfor风格,get是查询,post是新增,put是修改,delete是删除。这是目前主流的一种开发风格
ICourseService及其实现类
这些都是方法签名,声明了方法定义的规范,其实现类会完成具体的业务操作

实现类重写了接口的所有抽象方法,并调用mapper完成数据库的相关操作。

CourseMapper及其映射文件
mapper中的方法签名,跟service接口及其实现类的命名是一样的。

mapper中,每个方法对应的SQL语句都映射在了xml文件中

Course
课程管理实体类,该实体类继承了BaseEntity基类

实体类的属性跟数据库的表字段做到了对应,完成了xml的自动映射封装。

@Log和@PreAuthorize
在Controller中的每个方法,都有两个注解

@Log用于记录用户操作日志
@PreAuthorize是SpringSecurity安全框架提供的一个注解,用于权限校验控制
BaseController
我们来观察CourseController中的查询课程管理列表的方法
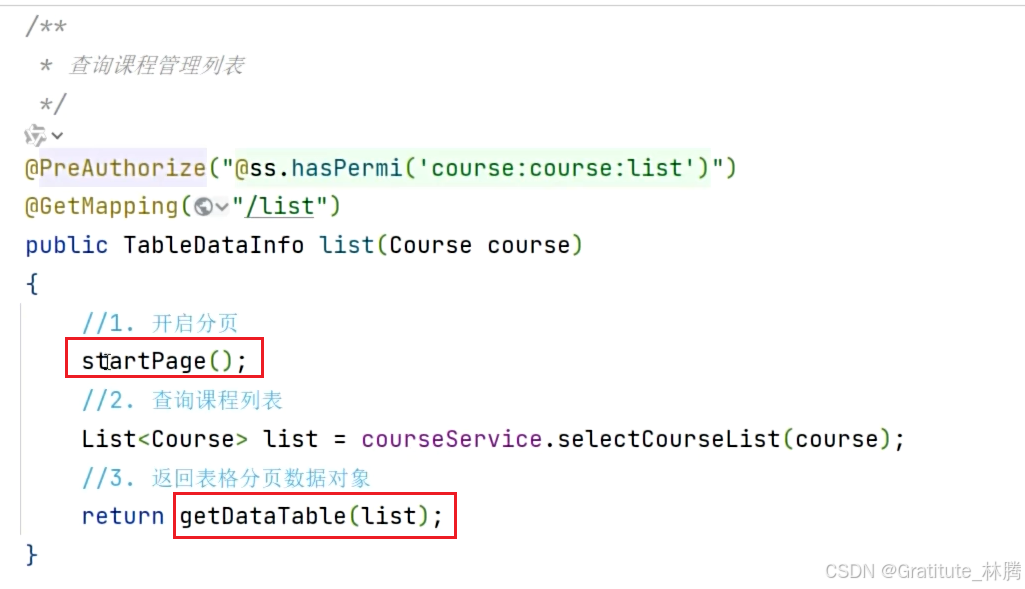
这里我们可以发现,startPage()和getDataTable()这两个方法并不存在于CourseController中,我们按ctrl并点击startPage,可以进入该方法的所属类:

可以看到,startPage和getDataTable的所属类是BaseController,它是web层通用的数据处理类,我们所有的业务Controller类都默认继承了BaseController:
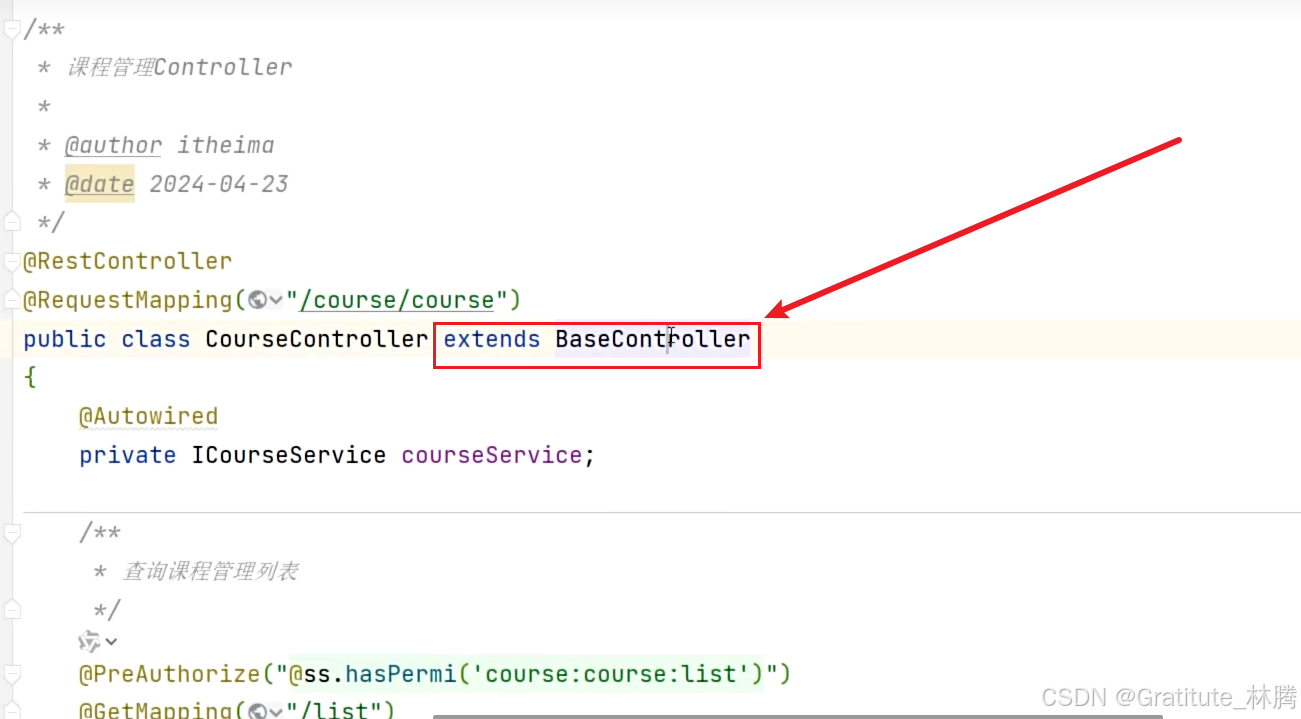
继承了BaseController后,BaseController类中所有公开的属性和方法都可以直接使用。这就是CourseController可以使用startPage和getDataTable的原因。
进入BaseController,按住alt+7,就可以展示该类所有公用的方法

分页方法解析
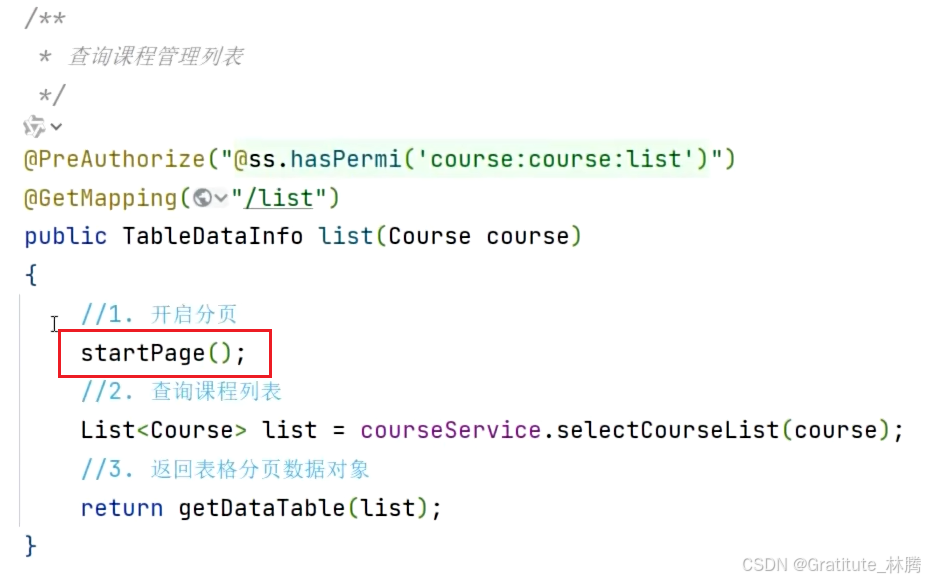
按住ctrl并点击startPage,进入:
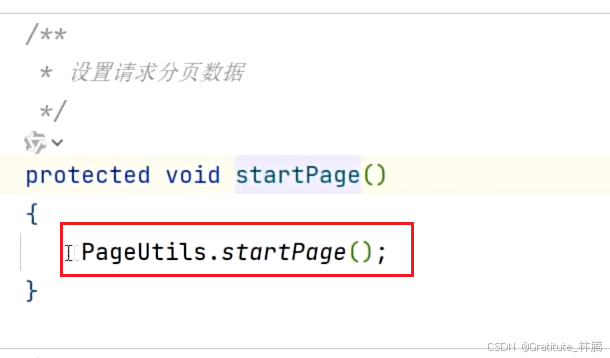
可以看到BaseController中的startPage方法只有一行,调用了分页工具类,开启了分页。我们来看看分页工具类的startPage的具体内容,按住ctrl并点击startPage,进入:
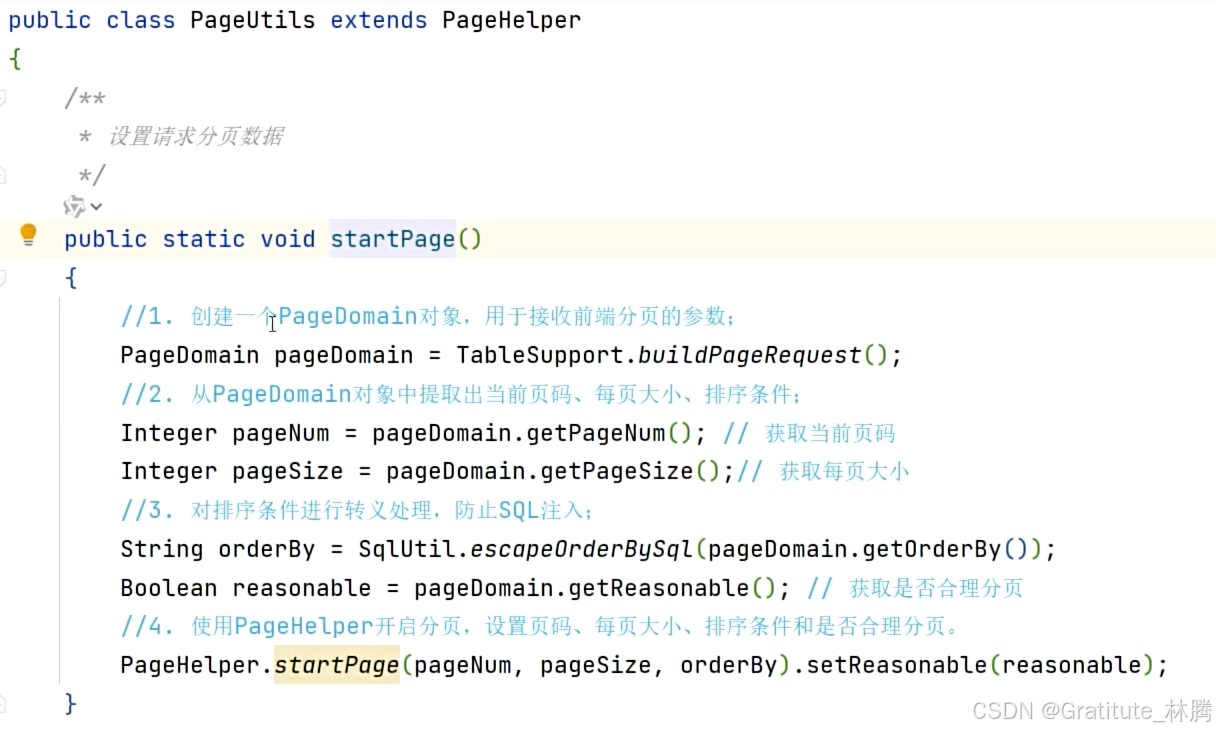
分页的工作原理
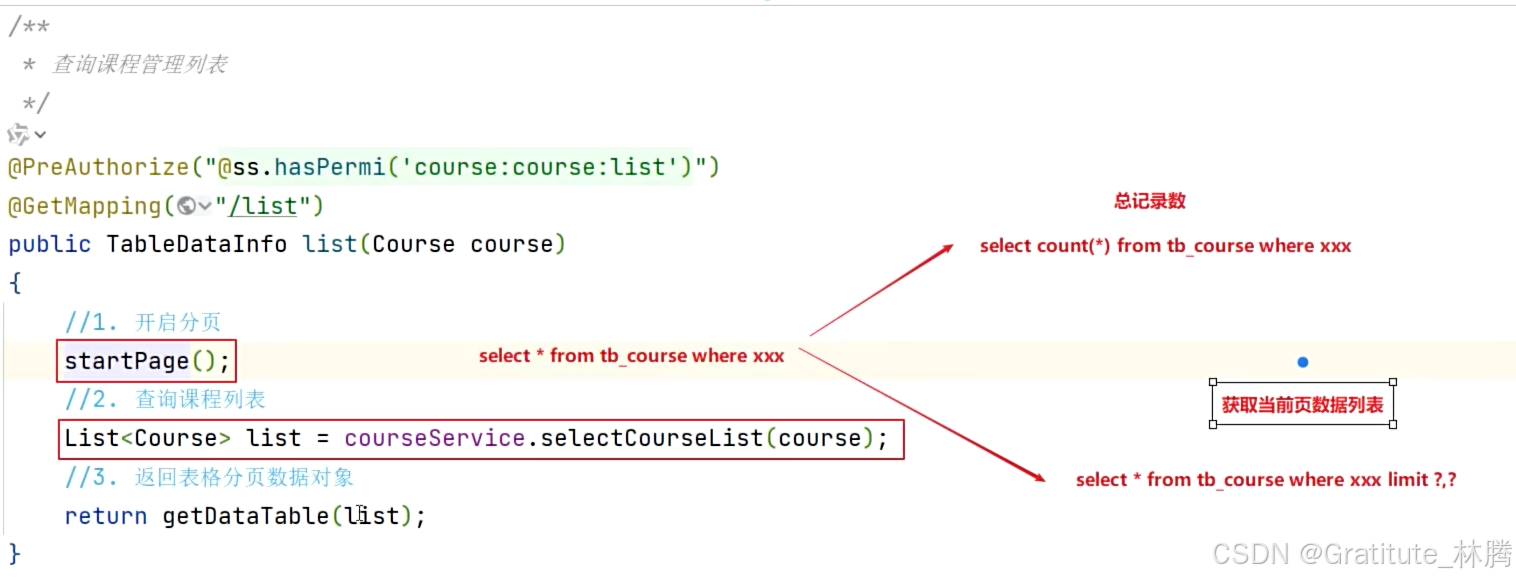
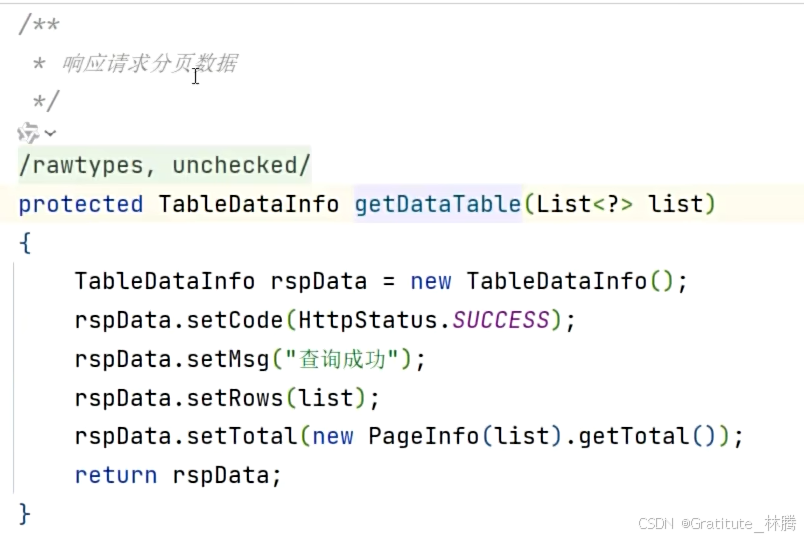
getDataTable解析
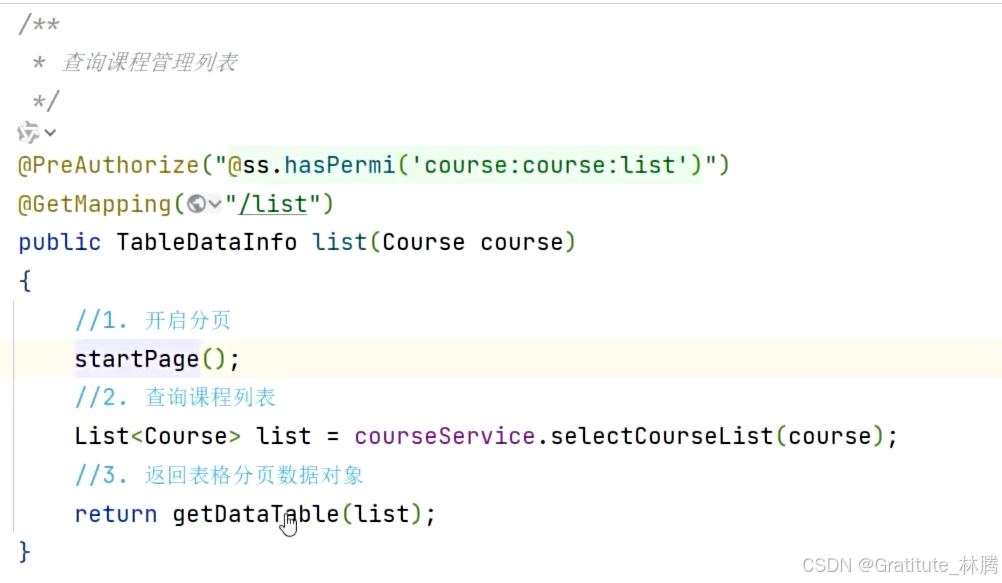
按住ctrl并点击getDataTable,进入:
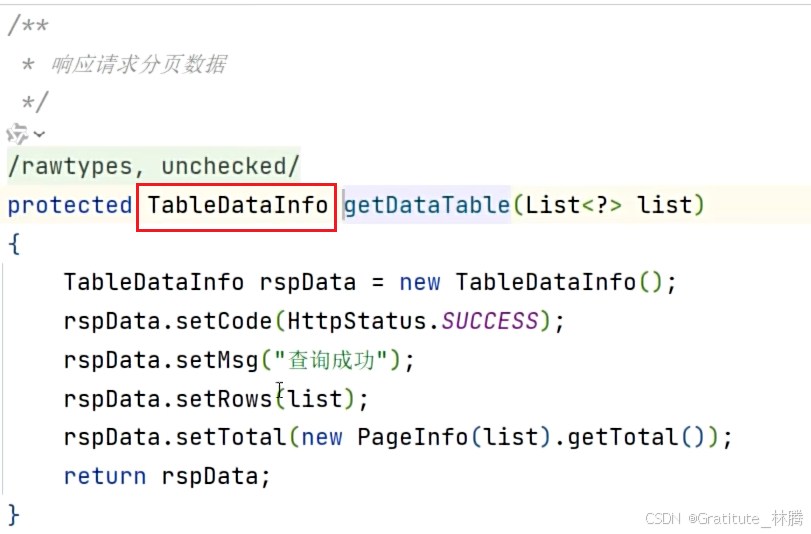
该方法在BaseController中,按住ctrl并点击TableDataInfo,进入:
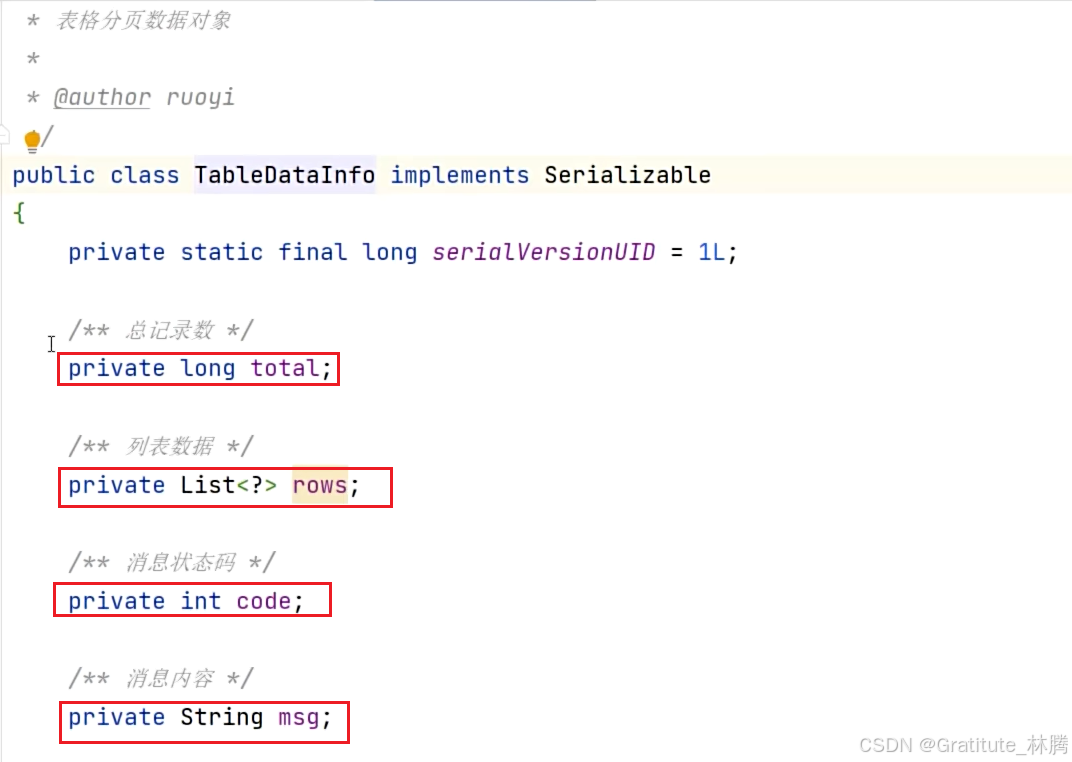
该对象有如图四个属性,这四个属性是与前端共同协商返回的分页对象的标准数据格式,将其转换成json,前端就可以进行数据分页的展示了。具体json格式如图:
这样,getDataTable的方法内容就能看懂了:
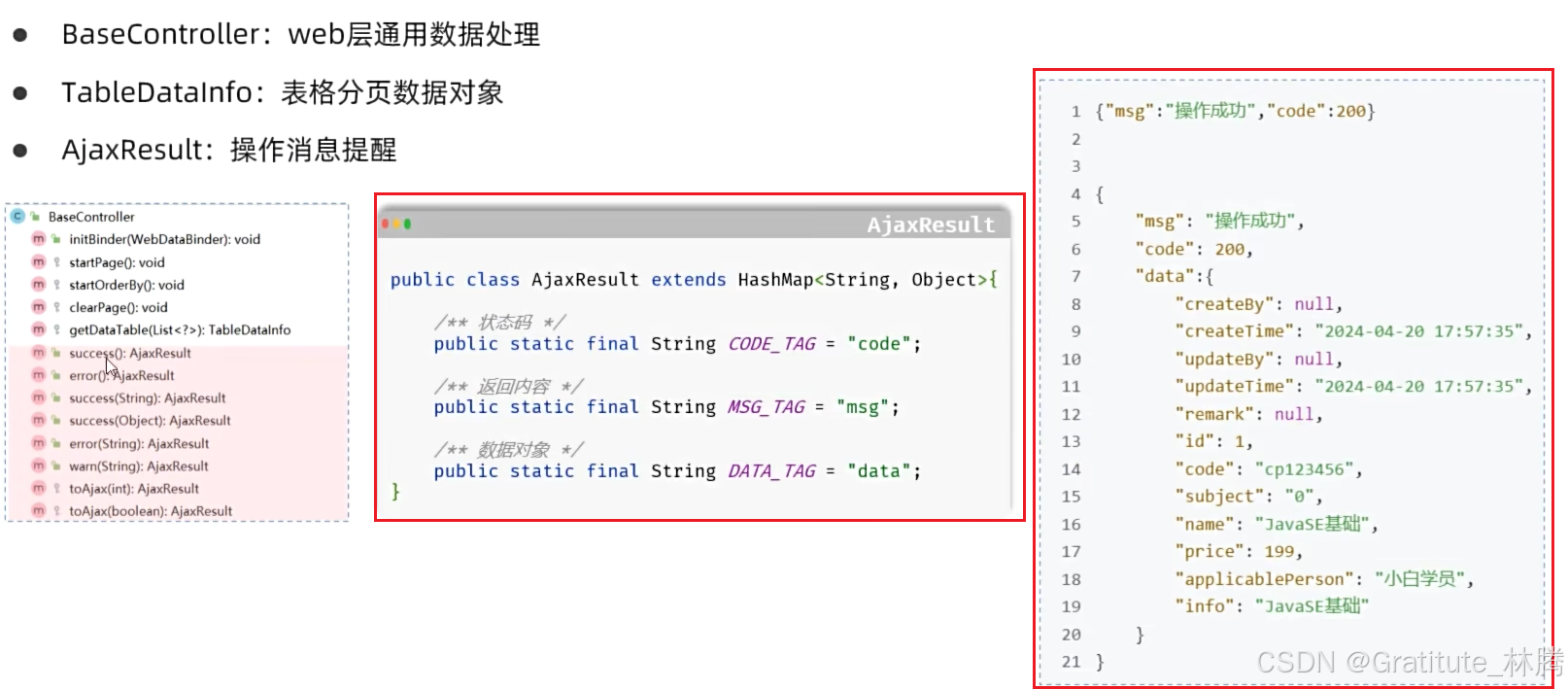
AjaxResult解析
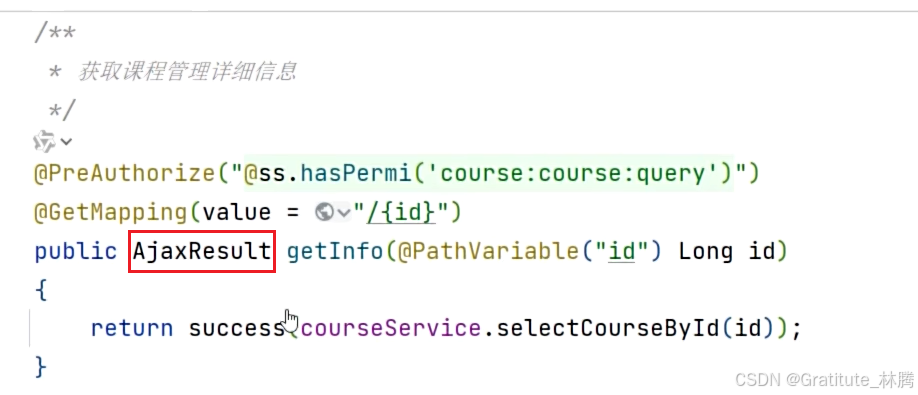
根据id查询课程详情,返回的是非分页的结果-AjaxResult,按住ctrl并点击success,进入:
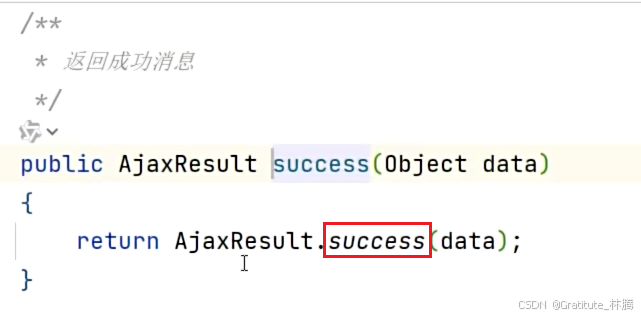
这是BaseController提供的success方法,该方法调用了AjaxResult的静态success方法。按住ctrl并点击AjaxResult,进入:
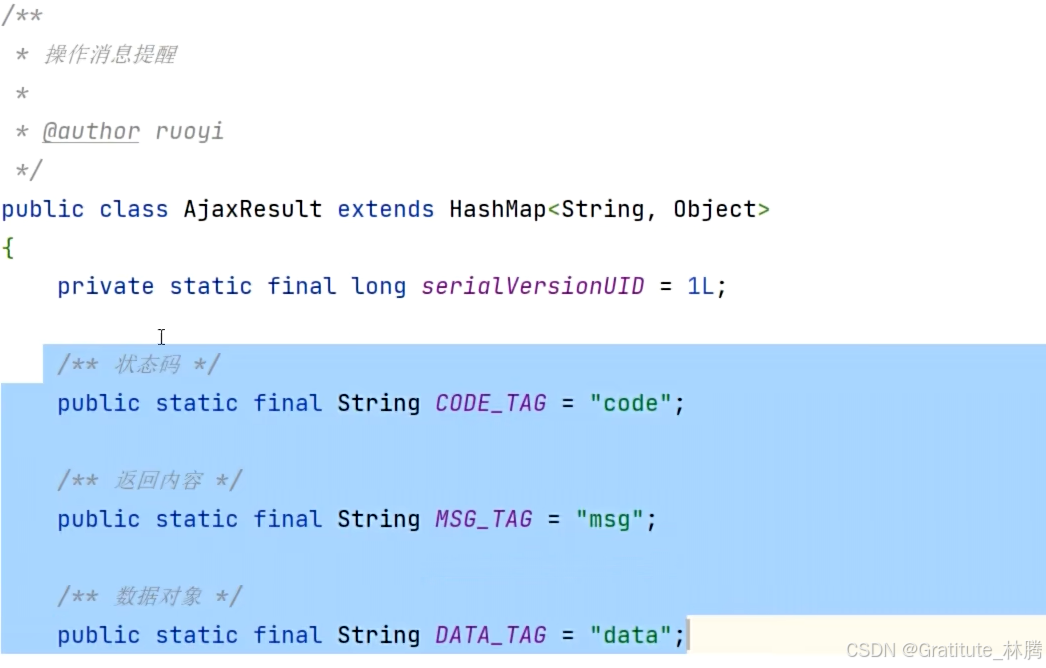
里面包含了三个属性,这三部分也是跟前端共同协商,提供的非分页的统一返回结果,具体json格式如下图:
对于一些不需要返回数据对象的业务操作:
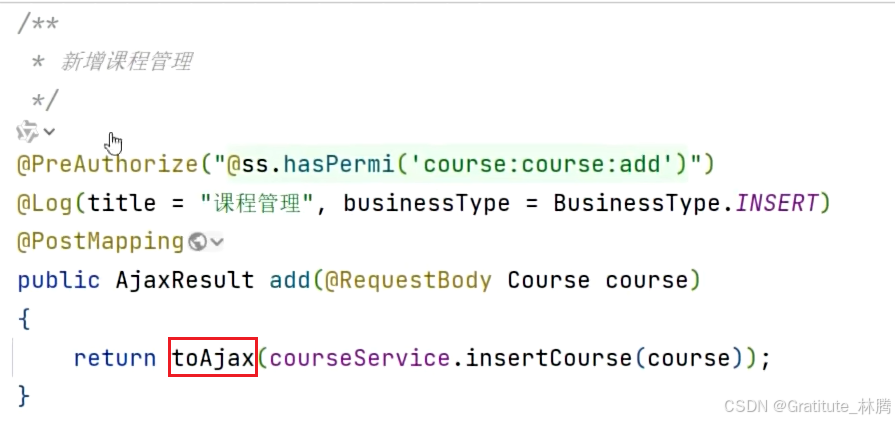
该方法同样返回的是AjaxResult,而返回的方法不再是success,而是toAjax,按住ctrl并点击toAjax,进入:
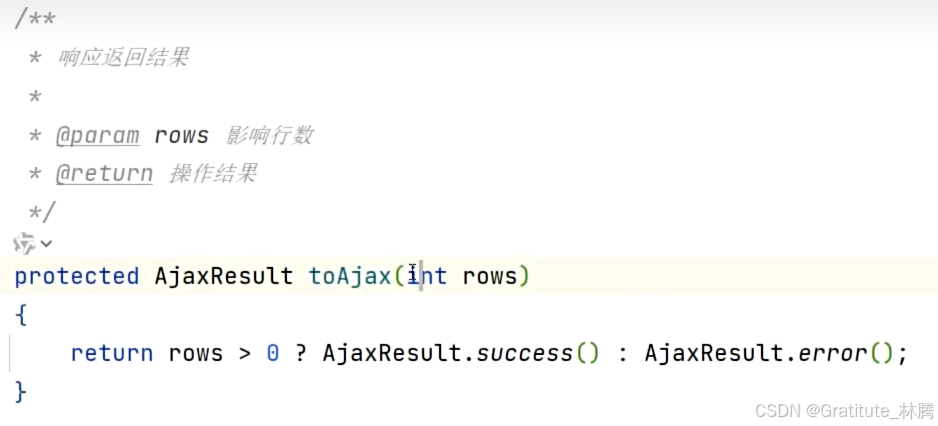
该方法接收的是业务操作返回的影响行数,对于数据库操作,如果影响行数大于0,表示成功,否则表示失败,所以这里使用了三元运算符,如果rows>0,则返回的是没有参数的success(),因为不需要返回数据对象,只需要告诉前端成功了;如果rows<=0,则返回error()。具体的json格式:

BaseEntity解析
Course类继承BaseEntity类,按住ctrl并点击BaseEntity,进入:
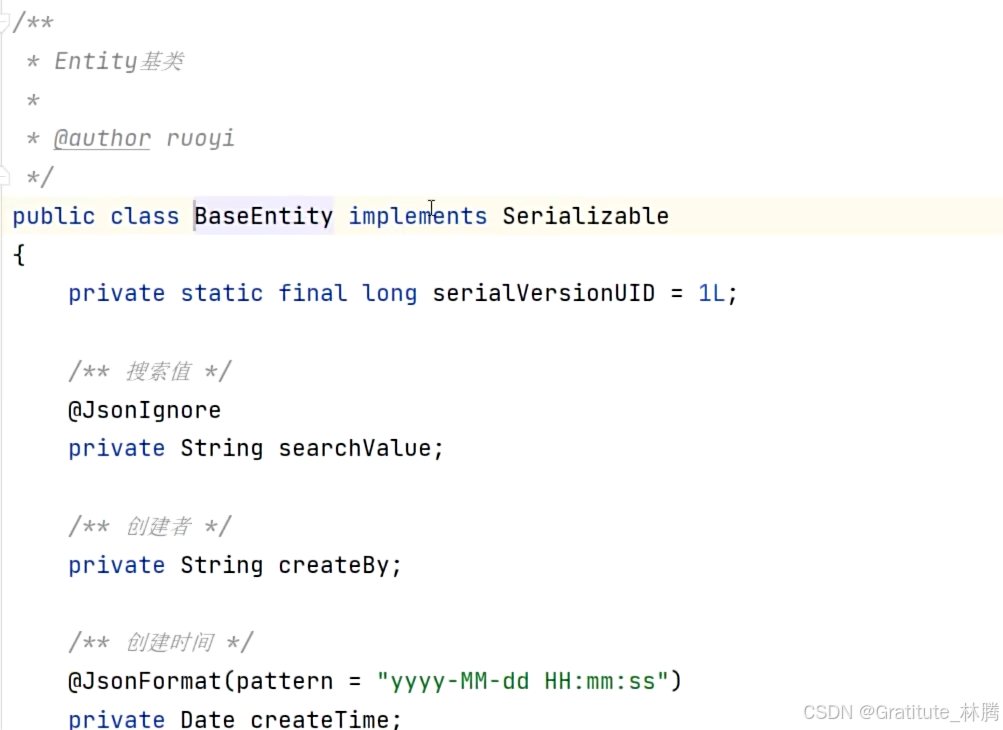
BaseEntity是所有实体类的基类,子类可以使用里面提供的所有属性,具体细节如图:

若依的设计者认为:每张表都应该有创建人、创建时间、更新者、更新时间、备注等字段,我们没有必要为每个实体类定义这些共有的属性了,将其放入父类,这样子类都可以把它们继承过来,所以在返回的数据中,就有这5个属性字段了,如果表存在这些字段,就返回对应的值,否则就返回null。
searchValue字段用于做全文检索时,接收前端传递的参数。
params用于做到灵活定义,比如产品已经上线,但客户想在前端加上一个新的请求参数,但我们有不太想去修改实体类的代码,那我们就可以把这个参数放到map中,做到灵活接收。这样可以减少代码的改造,实现更复杂的业务场景。做到代码的灵活性,提高开发效率。
假设我们有一个产品已经上线了,用户表 (users) 中包含 id、name、email 等字段。我们使用一个 User 实体类来接收前端传来的请求参数。
public class User {
private Long id;
private String name;
private String email;
// Getters and Setters
}
业务场景:
产品已经上线,但客户现在希望在前端添加一个新的查询参数 age,用于过滤年龄。我们不希望修改现有的 User 实体类,因为这可能导致对其他代码的影响或需要重新测试。
使用 Map 灵活接收参数:
我们可以使用 Map<String, Object> 来代替固定的实体类接收参数。这样,无论前端传递什么参数,后端都可以灵活处理。
public interface UserMapper {
List<User> findUsersByParams(Map<String, Object> params);
}
在对应的 Mapper XML 中可以这样写:
<select id="findUsersByParams" parameterType="map" resultType="User">
SELECT * FROM users
<where>
<if test="name != null">
AND name = #{name}
</if>
<if test="email != null">
AND email = #{email}
</if>
<if test="age != null">
AND age = #{age}
</if>
</where>
</select>
解释:
- 前端 可以发送一个请求,比如:
/users?name=John&age=30,后端会接收到name和age两个参数。 - 后端 使用
Map<String, Object>作为params参数来接收这些请求数据。你不需要修改现有的User实体类,因为新添加的age参数会放入Map中。 - SQL 查询 会根据
params中是否包含这些字段来动态生成查询语句。例如,如果params中有name和age,则会在WHERE条件中加入name和age的筛选。
这样做的好处是:
- 不必修改
User类。 - 可根据需要动态添加或忽略查询参数,灵活处理各种情况。
- 提高了代码的扩展性和开发效率。
总结:
通过使用 Map 来接收参数,开发者可以灵活地处理变化的请求参数,避免频繁修改已有的实体类,减少代码改动的风险,提升开发效率。注:实体类一旦修改,前端接收的数据就会发生变化,可能就会有风险。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)