目标检测算法之DETR
从上图可以发现DETR的模型结构比较简单,首先通过CNN层获取图像的特征图,然后与位置向量相加作为Transformer encoder的输入,然后固定object queries作为decoder的query,transformer encoder的输出作为key,value,最后输出。同时在原本的分类结果的基础上添加一个no object的类别,对于一些框分类为no object的,直接去除。
DETR
- Background
- 模型结构
-
- Backbone
- Transformer Encoder
- Transformer Decoder
- Prediction feed-forward networks(FFN)
- Loss Function
- 匈牙利算法
Background
随着transformer在NLP的兴起,CV领域也逐渐关注transformer,并尝试将其引入CV任务中。DETR是一种基于transformer的目标检测算法,它不需要先验知识如先验anchor,先验anchor point等,也移除了NMS的后操作。从思想上,DETR引入了匈牙利算法进行二分匹配,使每个预测框和真实框有唯一的匹配。同时DETR的思想比较简单,相较于FastCNN具备较快的推理速度和更高的准确率。但是从现在看DETR,DETR的二分匹配使得模型十分难收敛,也是后来许多基于transformer模型的改进方向。
论文地址:https://arxiv.org/pdf/2005.12872
论文代码:https://github.com/facebookresearch/detr
模型结构
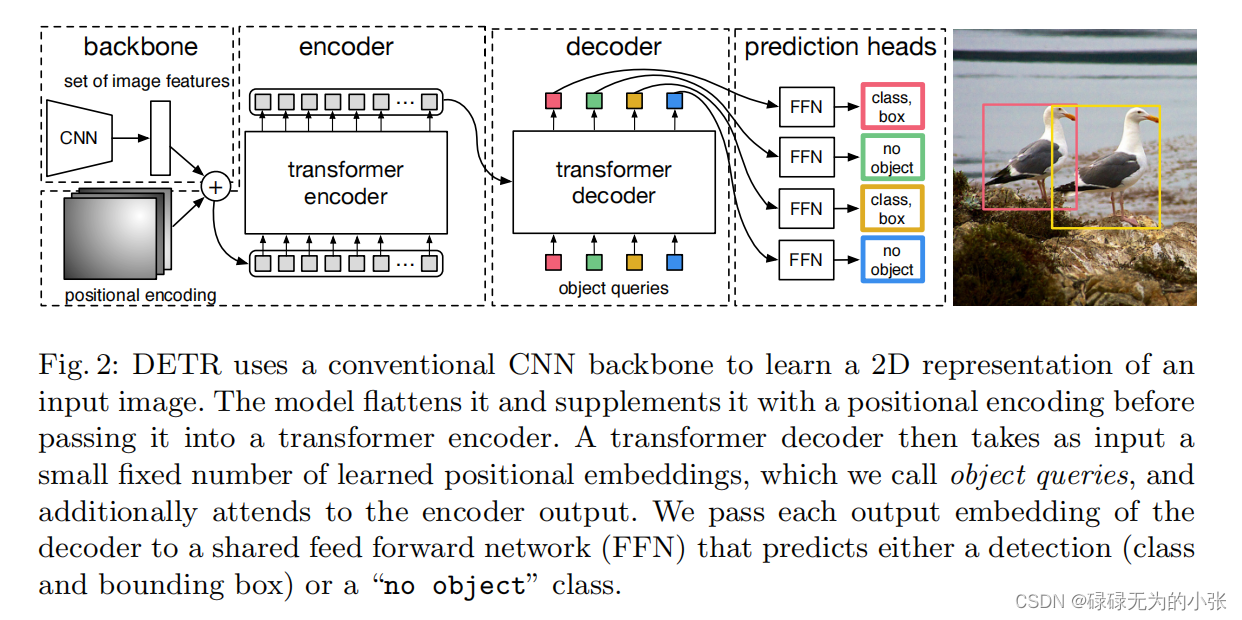
从上图可以发现DETR的模型结构比较简单,首先通过CNN层获取图像的特征图,然后与位置向量相加作为Transformer encoder的输入,然后固定object queries作为decoder的query,transformer encoder的输出作为key,value,最后输出 n n n个特征数数据,这里相当于yolo中的neck。最后每个特征通过FFN层输出分类结果和bbox。同时在原本的分类结果的基础上添加一个no object的类别,对于一些框分类为no object的,直接去除。接下来具体分析一下它的整个结构。
Backbone
DETR中,作者是采用了ResNet50作为Backbone完成了对图像的32倍下采样,将channel扩大到2048,即 f f e a t u r e = R e s n e t ( x i n p u t ) f_{feature}=Resnet(x_{input}) ffeature=Resnet(xinput)其中 x i n p u t ∈ R C × H × W x_{input}\in R^{C\times H\times W} xinput∈RC×H×W, f f e a t u r e ∈ R 2048 × H 32 × W 32 f_{feature}\in R^{2048\times \frac{H}{32}\times \frac{W}{32}} ffeature∈R2048×32H×32W
当然Backbone可以替换成其他的CNN模型
Transformer Encoder
Transformer Encoder是用了 1 × 1 1\times 1 1×1的卷积核,将channel从 C = 2048 C=2048 C=2048转换至维度 d = 256 d=256 d=256(维度大小可以自己指定)。获得新的特征图 z 0 ∈ R d × H × W z_0\in R^{d\times H\times W} z0∈Rd×H×W,将空间从二维降至一维,即 z 1 ∈ R d × H W z_1\in R^{d\times HW} z1∈Rd×HW,这里 d d d可以看成向量的维度, H W HW HW为句子的长度。这样就可以直接输入Transformer Encoder中,这里还需要将position embedding加入。通过论文的代码看出,作者是用的可学习的位置变量,不是用三角函数的绝对位置向量。
Transformer Decoder
Decoder中的object queries给定为 N N N个,然后通过self-attention和encoder-decoder attention输出。这里的decoder不使用mask,同时直接将其输出作为特征变量。注意这里输出的长度为 N N N,假设 q q q为 ( N × d ) (N\times d) (N×d), k k k和 v v v为 ( L × d ) (L\times d) (L×d)经过attention后,变为 N × d N\times d N×d。因为 q k T qk^T qkT为 N × L N\times L N×L,然后在与 v v v相乘得 N × d N\times d N×d。通过这个方式可以固定输出object对的个数。
Prediction feed-forward networks(FFN)
FFN层有俩个,一个将维度 d d d投影到 n u m ( c l a s s e s ) + 1 num(classes)+1 num(classes)+1上,输出分类的类别;另一个 d d d投影到 4 4 4上,输出目标的中心位置 ( x , y ) (x,y) (x,y)和目标的长和宽。输出的框的个数取决于 N N N(object queries)。同时所有每个框的FNN层共享参数。
Loss Function
DETR使用了匈牙利算法进行二分匹配,每个预测框都有与一个真实框进行匹配。所以这里真实框一般是小于预测框的,需要添加一个空框。由于匹配算法中需要计算俩个框之间的距离,所以有KaTeX parse error: No such environment: align* at position 7: \begin{̲a̲l̲i̲g̲n̲*̲}̲\mathcal L_{mat…匹配损失越小说明越接近,上述式子中第一项是指对应真实分类的概率,此时概率越大则整体越小,损失越小。第二项是指俩个box之间的差距,这里采用了L1距离和iou来计算。由于它们越小则损失则越小所以用正号。
定义了距离,接下来可以通过计算最佳匹配序列,即
σ ^ = arg min σ ∈ P N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) \hat{\sigma} = \argmin_{\sigma\in P_N}\sum_{i}^{N}L_{match}(y_i,\hat{y}_{\sigma(i)}) σ^=σ∈PNargmini∑NLmatch(yi,y^σ(i))其中 P N P_N PN是指所有可能的匹配序列。这里直接列举所有的可能的话时间复杂度较大,这里使用匈牙利算法来进行匹配,就可以降低时间复杂度
得到最佳匹配序列后,就可以直接计算模型的loss,即 L H u n g a r i a n ( y i , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 { c ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) ] L_{Hungarian}(y_i,\hat{y}) =\sum^{N}_{i=1}\left[-\log \hat{p}_{\hat{\sigma}(i)}(c_i)+1_{\{c\neq\empty\}}\mathcal L_{box}(b_i,\hat{b}_{\sigma(i)})\right] LHungarian(yi,y^)=i=1∑N[−logp^σ^(i)(ci)+1{c=∅}Lbox(bi,b^σ(i))]
匈牙利算法
匈牙利算法的计算方式:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)