FPGA部署的算法定点化原理与基础
当前在无线通信信号处理中,基本都是基于Python或者Matlab做浮点算法仿真设计,然后部署在硬件DSP或者FPGA中。算法部署在浮点DSP中,基本可以平移,但由于算法速率与成本,灵活性等原因,部分算法也会部署在FPGA中进行实现。常见的数字信号处理,图像处理等需要并行计算的场景,往往需要FPGA参与运算。那么浮点算法部署到FPGA上往往需要一个算法定点化的步骤,该步骤决定了算法性能,FPGA资
FPGA部署的算法定点化原理与基础
摘要:当前在无线通信信号处理中,基本都是基于Python或者Matlab做浮点算法仿真设计,然后部署在硬件DSP或者FPGA中。算法部署在浮点DSP中,基本可以平移,但由于算法速率与成本,灵活性等原因,部分算法也会部署在FPGA中进行实现。常见的数字信号处理,图像处理等需要并行计算的场景,往往需要FPGA参与运算。那么浮点算法部署到FPGA上往往需要一个算法定点化的步骤,该步骤决定了算法性能,FPGA资源消耗,甚至决定了算法部署的成功与失败。本文主要讲述了定点化基础以及算法定点化基本流程。
浮点数与定点数
浮点数有以下几个特点:动态范围大, 精度相对较高小数点位置可变;
定点数特点:位宽固定,小数点固定 。具体浮点数,定点数规则详情请查阅我之前的博客《现代计算机中数字的表示与浮点数、定点数》。
对于动态范围大,精度高的浮点数来说,似乎定点数没啥优势,定点数核心:位宽固定,且对于DSP、CPU等浮点处理器而言,位宽往往小于single float 32bit。举个例子:即假设正整数1,定点位宽2bit即可表示正整数1(0’b01),放在单精度浮点机上跑,1的表示也必须是32bit,这在一定程度上造成了硬件资源的浪费,数字的计算与存储,都需要硬件支撑,那么定点机的优势就体现出来了。除了底层资源方面的考虑,FPGA,ASIC等定点机往往具有更快的运行速率,比如我们在浮点机开发的C代码在ARM处理器上采用多级流水线技术,且需要多个机器周期来完成取指令、译码、执行、访存和写回等,在FPGA中我们只需要单纯对这个信号直接操作即可完成我们想要的功能。
通常的来说FPGA等定点机具有以下优势:定点运算相对简单,执行速度通常比浮点运算快;硬件设计相对简单,不需要专门的浮点单元,成本较低;编程模型相对简单,不需要考虑舍入误差,需要手动管理数值的范围和溢出。
本文的规定如下:s(16,10)表示有符号的16bit信号,其中整数为10bit(包含1bit符号位),16-10=6bit小数;u(16,10)表示无符号的16bit信号,整数为10bit(没有符号位),小数6bit。
定点化的目的:
- 浮点仿真简单直接,适合算法功能/性能摸底;
- 实现中大部分器件对字长及位宽有限制,实现方法采用的数据类型是定点数,需要将浮点仿真进行定点化使之成为实现的基础;
- 定点链路模拟实际硬件行为,定点仿真可以为硬件实际性能提供参考;
- 定点化是算法与实现的桥梁,定点化过程需要兼顾算法性能和硬件实现,以求达到性能和实现代价的相对平衡。
浮点数转定点数
以5.739为例:
- step1:乘以小数部分位宽的二次幂(13)
5.739 * 2^13 = 47013.888
- step2:转换为整数,转换方式有:四舍五入round,向下取整floor,向上取整ceil等
round(47013.888) = 47014
floor(47013.888) = 47013
ceil(47013.888) = 47014
定点数的补码运算
- 二进制补码的正数/负数区间不平衡
- 定点位宽为(N,N)和(M,M)的二进制相加,位宽变为max(N,M)+1 bit
- 定点位宽为(N,N)和(M,M)的二进制相乘,位宽变为N+M bit
定点数运算
无论是加法还是乘法运算,如果要保持精度无任何损失,每一次运算位宽都会增加。这在实现中会导致资源或运算速度上无法承受,必须通过适当方法在性能允许的情况下降低位宽。
饱和处理
在定点数的大小超过它整数部分所能表示的最大值的时候,就用这个最大值表示这个定点数。
例如定点位宽s(16,16)的定点数X,饱和处理如下,存在对称饱和与非对称饱和,非对称饱和来源于补码表示的不对称性。
非对称饱和:
If X > 32767 X = 32767
else if X < -32768 X = -32768
else X = X
对称饱和:
If X > 32767 X = 32767
else if X < -32767 X = -32767
else X = X
截位处理
- floor:向负无穷方向取整
例:floor(-1.3) = -2; floor(1.8) = 1; floor(1.3) = 1; floor(-1.8) = -2
- ceil:向正无穷方向取整
例:ceil(-1.3) = -1; ceil(1.8) = 2; ceil(1.3) = 2; ceil(-1.8) = -1
- fix:向零方向取整,即正数和负数都向0方向靠拢
例:fix(-1.3) = -1; fix (1.8) = 1; fix(1.3) = 1; fix(-1.8) = -1
- round:四舍五入到最近的整数,0.5进位,0.49舍去
例:round(-1.3) = -1; round (1.5) = 2; round(1.3) = 1; round(-1.5) = -2
- nearest:将负数的0.5舍去,其他与round相同
例:nearest(-1.3) = -1; nearest (1.5) = 2; nearest(1.3) = 1; nearest(-1.5) = -1
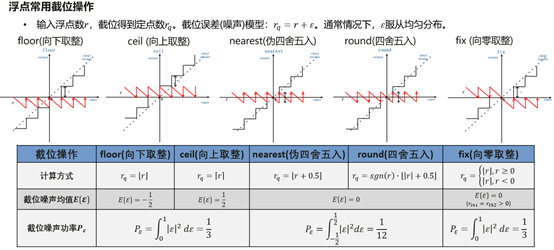
定点到浮点,浮点到定点的位宽变换通过截位和饱和操作完成;通常先截位再饱和;nearest相比round操作,实现更简单,但可能引入固定偏差带来直流问题,需要仔细分析与仿真其直流影响。
算法定点化流程
- 确认关键算法实现、定义和简化算法结构
- 系统设计的开始阶段(浮点)一般都是算法研究和选择,不会考虑太多算法的实现,因此系统中会包含许多理想化的算法,或者调用一些函数调用,建议按照最终实现的结构来创建浮点函数
- 定义和简化算法结构:
- 例如用sin(x) 或者 cos(x) 函数来计算变量x的正弦或余弦值。此时可直接用cordic算法、泰勒级数或者查找表来表示正弦浮点函数。
- 注意:在做定点设计时需要特别注意查找表的大小。因为查找表本身已经是输出的量化结果了。如果输出的量化步骤不同,也就是低比特位和查找表的低比特位不相符,那么查找表就会引起错误。因此开始阶段应该尽可能选择大的查找表,逐步尝试
- 确定需要量化的函数中的关键变量
- 常见的关键变量包括状态变量或数组、滤波器的系数、累加值、以及输入和输出接口的值(输入/输出端口及其浮点参数)
- 如何定义这些关键变量的定点格式关系到量化的误差,或者说是相比浮点函数的性能损失,它们的定点格式不像某些临时变量或者中间结果,无法由其他变量推导而来。
- 收集关键变量的统计信息,如范围、分布等
- 通过浮点变量的范围可以确定所需的整数部分字长(iwl),也就是定点格式中小数点左边的比特数。
- 为了得到合理的统计值,需要运行足够多的仿真,激励信号也应该尽量合理选择。
- 确定关键变量的精确表示
- 在获得所有关键变量的iwl后,需要确定其字长(wl)。字长的确定只能通过采用某些指标评估算法的整体性能来实现,例如BER、MSE、SNR等。此时算法评估的参考标准是浮点模型。
- 将关键遍历转化成定点格式,其中定点格式的iwl在步骤3中确定,通过选择不同的wl做多次仿真,将仿真结果和相应的wl做成表格,作为确定关键变量字长的依据。最后根据项目要求选择满足特定指标的最优字长(BER、MSE等)
- 在多数设计流程中,这一步骤最为繁琐。
- 对关键变量的量化顺序推荐从全局到局部,先从顶层的信号和接口开始。各个模块之间的接口确定以后,对模块本身的定点化可以并行进行。
- 确定其余变量的定点格式:
- 当所有的关键变量量化完成以后,系统基本上已经是比特精确了。但还会有一些其他变量,例如局部或者临时变量,依然是浮点格式。这些变量的定点格式由关键变量决定,多数情况可以通过计算获得。如果计算不能实现,则还需要额外的仿真,重复步骤3和步骤4,来确定所需的iwl和wl。
- 加入逻辑处理延时仿真确认性能
- 逻辑处理延时主要由逻辑开发人员给出,这与设计风格和设计需求(资源、功耗、时序)密切相关
- 对于特殊情况,如环路延时,需要综合算法性能而定
- 该步骤需要根据项目进度来定,越早确认越好,如性能未达标需要重新执行步骤3\4\5
定点计算位宽变化一张表
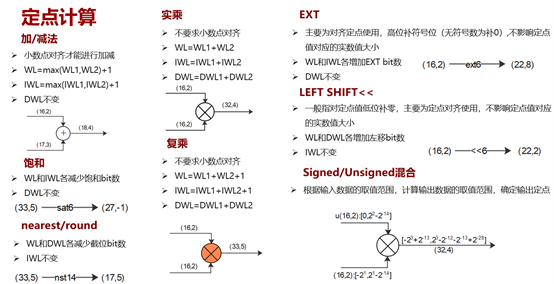
其中WL为总位宽,IWL为整数位宽,DWL为小数位宽。图中的(16,2)等,均表示为s(16,2)。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)