XGBoot算法---介绍、说明、python代码
提示:这些是自己整理 可以借鉴 也可能存在错误 欢迎指正XGBoot一、是什么?集成算法思想XGBoost基本思想二、使用步骤算法流程小结一、是什么?xgboot的全称为eXtreme Gradient Boosting集成算法思想引出:在使用决策树时,一颗树的效果不太好,用两棵树呢?同理,在做分类或者回归任务的时候,需要想一想一旦选择用一个分类器可能表达效果并不是很好,那么就要考虑用这样一个集成
·
提示:这些是自己整理 可以借鉴 也可能存在错误 欢迎指正
XGBoot
一、是什么?
xgboot的全称为eXtreme Gradient Boosting
集成算法思想
引出:在使用决策树时,一颗树的效果不太好,用两棵树呢?
同理,在做分类或者回归任务的时候,需要想一想一旦选择用一个分类器可能表达效果并不是很好,那么就要考虑用这样一个集成的思想。上面的图例只是举了两个分类器,其实还可以有更多更复杂的弱分类器,一起组合成一个强分类器。
XGBoost基本思想
提问:
- XGBoost的集成表示是什么?
- 怎么预测?
- 求最优解的目标是什么?
优点:
- 简单易用。相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。
- 高效可扩展。在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。
- 鲁棒性强。相对于深度学习模型不需要精细调参便能取得接近的效果。
- XGBoost内部实现提升树模型,可以自动处理缺失值。
缺点:
- 相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
- 在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。
优势
剪枝
- 当分裂时遇到一个负损失时,GBM会停止分裂。因此GBM实际上是一个贪心算法。
- XGBoost会一直分裂到指定的最大深度(max_depth),然后回过头来剪枝。如果某个节点之后不再有正值,它会去除这个分裂。
二、XGBoost
2.1 boosting
2.1.1. 建立映射
“GBDT”—梯度提升树
2.1.2. 计算参数


举例: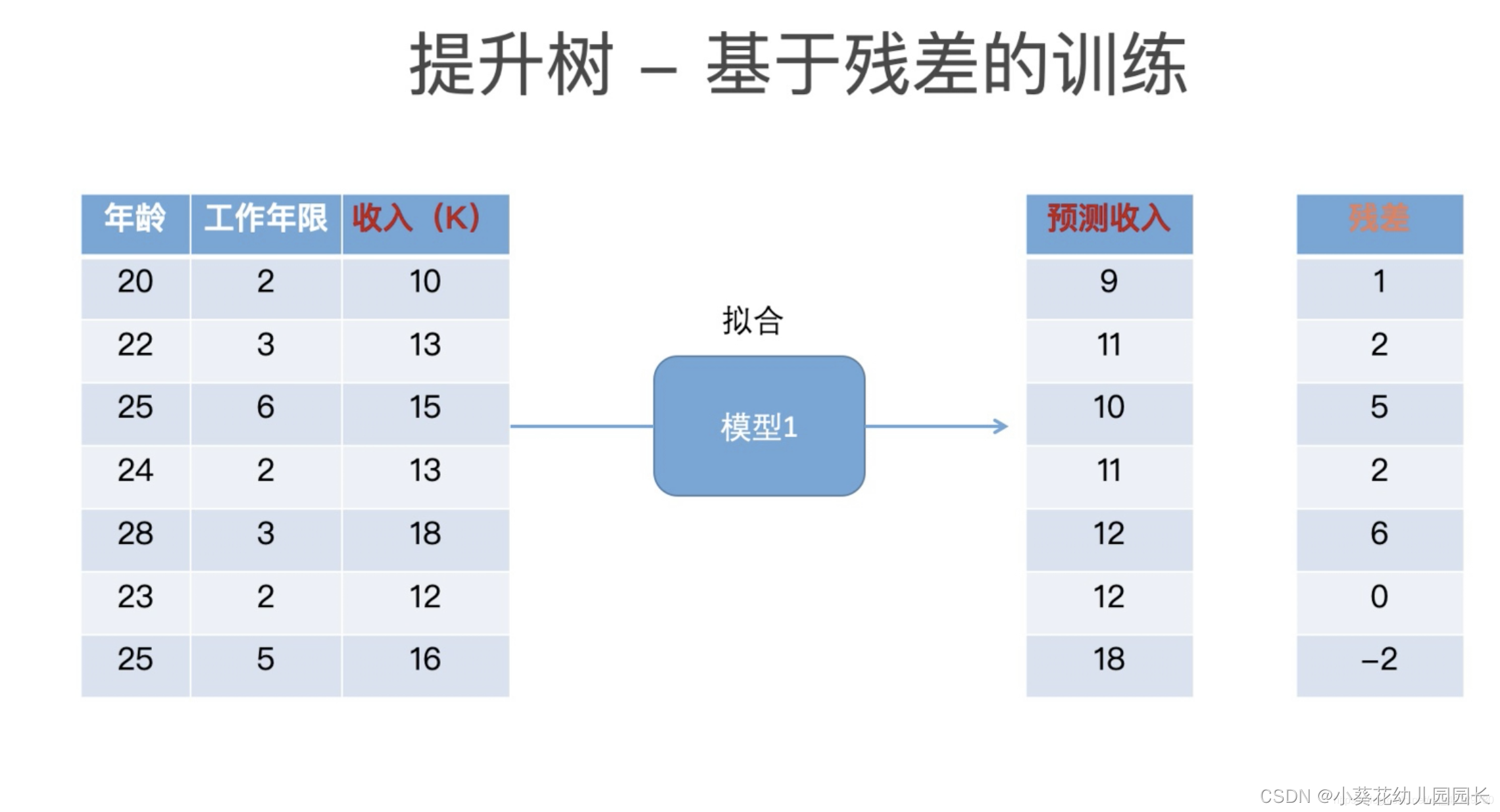
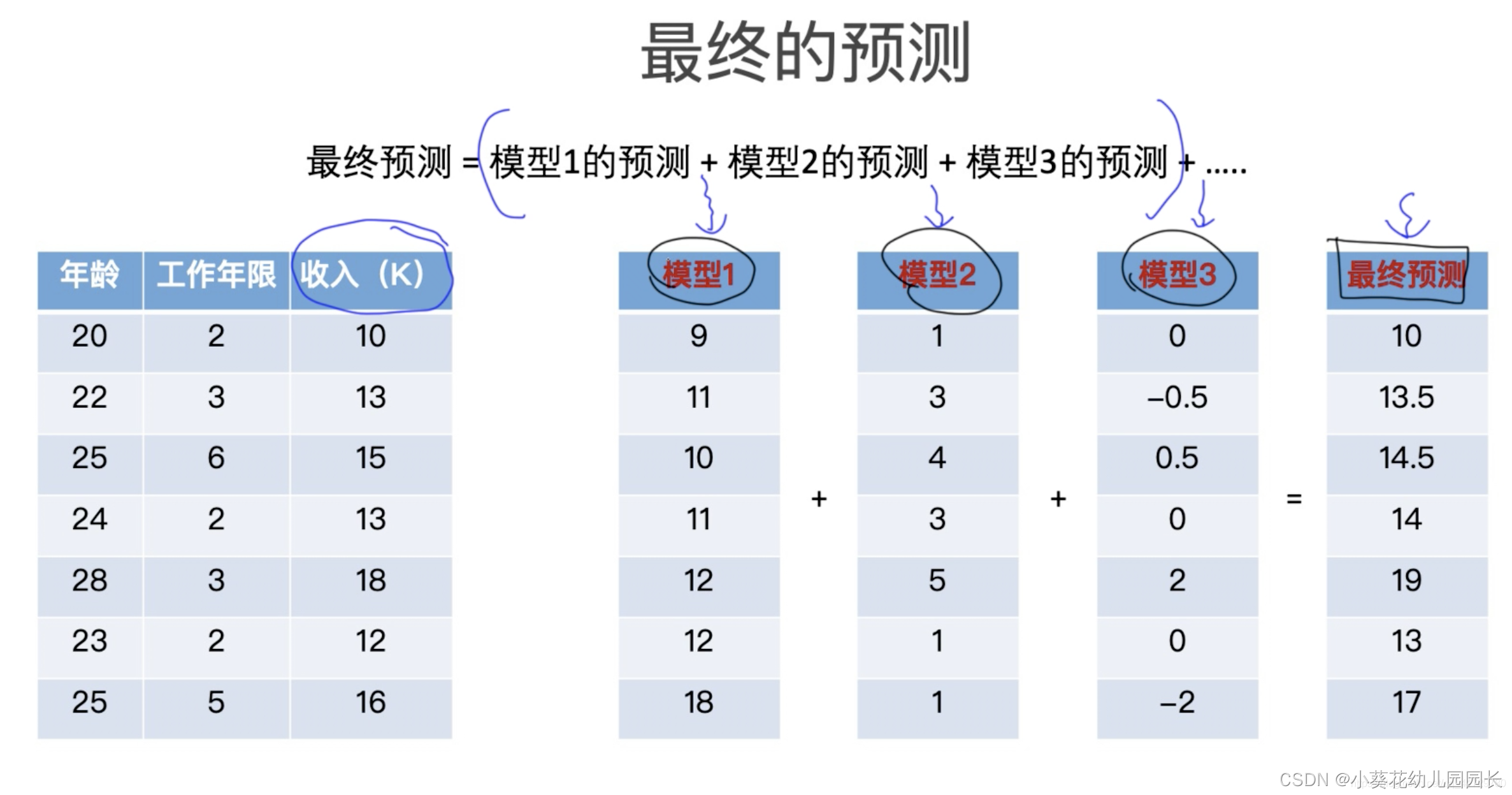
2.2 XGBoost目标函数
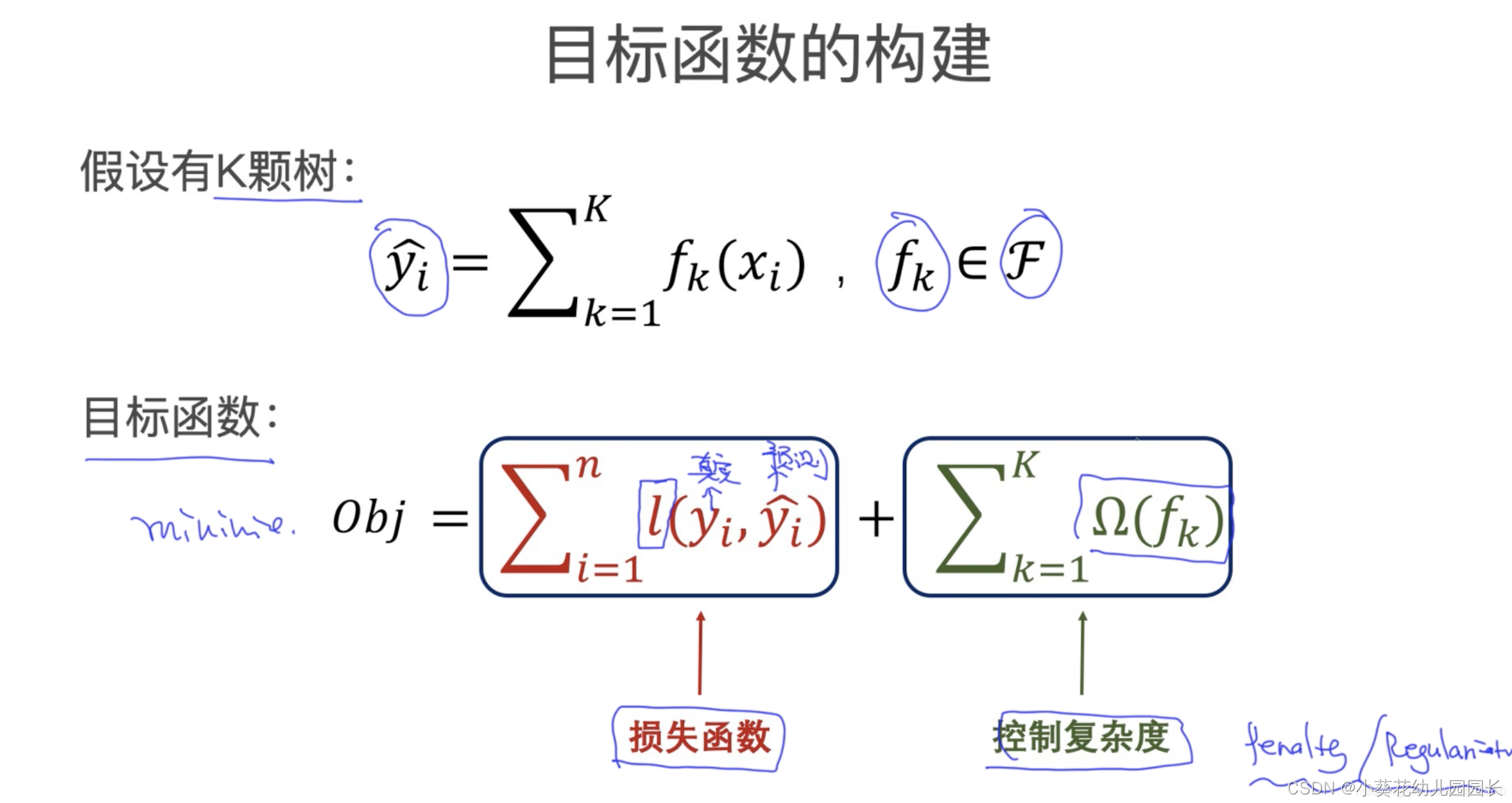


2.3 简化目标函数

2.4 泰勒展开
尽管我们对目标函数进行了化简,但直接对目标函数进行求解,运算的复杂度会非常高,所以我们选择对目标函数进行二级泰勒展开,提高模型的训练速度。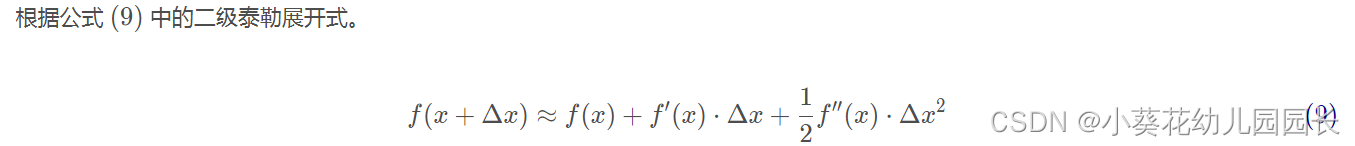

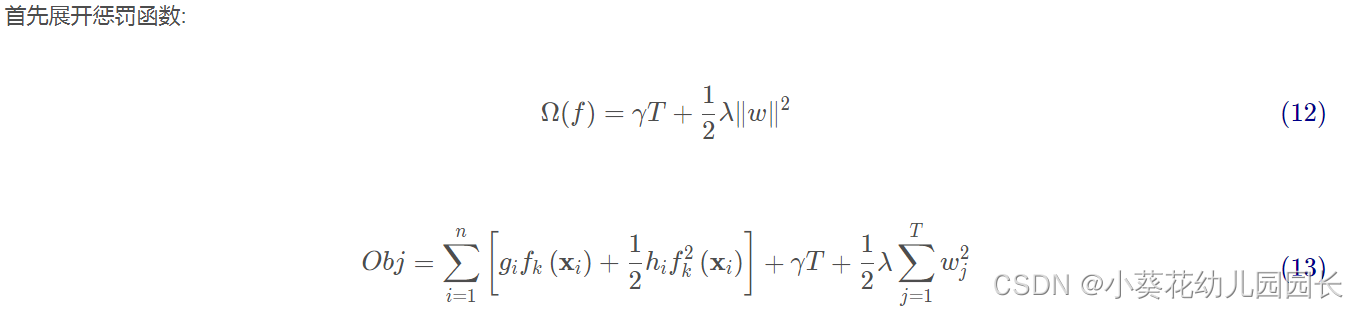


三、使用
xgboost安装
推荐: 安装
注意:文件名不要定义为:【xgboost】 会出错!!!
python代码
直接使用xgboost库自己的建模流程:
一些参数定义:
params = {
'booster': 'gbtree', # 可选gbtree(树模型)(默认)和gblinear(线性模型)
'objective': 'multi:softmax',
# 目标函数
# 可选:'reg:linear'(线性回归);'reg:logistic'(逻辑回归);'binary:logistic'(二分类的逻辑回归问题,输出为概率);
# 'binary:logitraw'(二分类的逻辑回归问题,输出的结果为wTx);'count:poisson'(计数问题的poisson回归,输出结果为poisson分布。
# 'multi:softmax'(让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数));
# 'multi:softprob'(和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。没行数据表示样本所属于每个类别的概率。);
# 'rank:pairwise'(set XGBoost to do ranking task by minimizing the pairwise loss)
'num_class': 3,
'gamma': 0.1, # Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。
'max_depth': 6, #树的深度,深度越大,复杂度越高越容易拟合
'lambda': 2, # L2 正则的惩罚系数
'subsample': 0.7, # 训练每一颗新树的采样率;用于训练模型的子样本占整个样本集合的比例
'colsample_bytree': 0.7, # 在建立树时对特征采样的比例。缺省值为1 。取值范围为:(0,1]
'min_child_weight': 3, # 孩子节点中最小的样本权重和。
'silent': 1, # 可选0(默认)和1;0--打印出运行时信息,1--不打印
'eta': 0.1, # 为了防止过拟合,更新过程中用到的收缩步长。缺省值为0.3 ,取值范围为:[0,1]。
'seed': 1000, # 随机数的种子。缺省值为0
'nthread': 4, # 线程数,默认当前系统最大线程数
}
xgboost.train (
params,
dtrain, # 训练数据
num_boost_round=10, # 提升迭代的个数
evals=(), # 列表,用于对训练过程中进行评估列表中的元素
obj=None, # 自定义目标函数
feval=None, # 自定义评估函数
maximize=False, # 是否对评估函数进行最大化
early_stopping_rounds=None, # 早期停止次数
evals_result=None, # 字典,存储在watchlist 中的元素的评估结果。
verbose_eval=True, # 如果为True, 则对evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
xgb_model=None, # 在训练之前用于加载的xgb model。
callbacks=None,
learning_rates=None # 每一次提升的学习率的列表,
)
完整代码:
# 基于XGBoost原生接口的分类
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
iris = load_iris() # 加载样本数据集
x_data, y_data = iris.data, iris.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
plst = params.items()
dtrain = xgb.DMatrix(x_train, y_train) # 生成数据集格式
model = xgb.train(params,
dtrain, # 训练的数据
num_boost_round=500 # 提升迭代的个数
) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(x_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("accuarcy: %.2f%%" % (accuracy * 100.0))
# 显示重要特征
plot_importance(model)
plt.show()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)