算法设计基础——减治法
分治法是将一个大问题划分为多个子问题,接着对所有子问题求解,再将子问题的解进行合并得出原问题的解。减治法与分治法类似,也是将原问题分解为多个子问题,但却并不需要对所有子问题进行求解,它只需要求解其中一个子问题,因此不需要对子问题的解进行合并,只需通过这个子问题的解来得到原问题的解。减治法可以看做是一种特殊的分治法,但它在分解子问题的同时会不断地减少问题的规模,通常情况下其时间复杂度会比分治法低。作
分治法是将一个大问题划分为多个子问题,接着对所有子问题求解,再将子问题的解进行合并得出原问题的解。
减治法与分治法类似,也是将原问题分解为多个子问题,但却并不需要对所有子问题进行求解,它只需要求解其中一个子问题,因此不需要对子问题的解进行合并,只需通过这个子问题的解来得到原问题的解。
减治法可以看做是一种特殊的分治法,但它在分解子问题的同时会不断地减少问题的规模,通常情况下其时间复杂度会比分治法低。
作为入门,我们先从减一治、减半治开始来逐步了解和掌握减治法。
一、减一治
减一治即每次分解问题时使问题的规模减一,一直分解到减治的终止条件为止。
其基本步骤与分治法类似,也是对问题进行分解,不过减治法的分解比较特殊,它将问题分解成多个子问题后,只需求解一个子问题就能得到原问题的解。
如求解一维数组的和,使用减治法的步骤就是将一维数组分解为前n-1项和第n项,原问题的求解就变成了求解前n-1项的和加第n项的和,分解的终止条件为数组长度为1,此时数组的和即为数组中唯一一个元素的值。
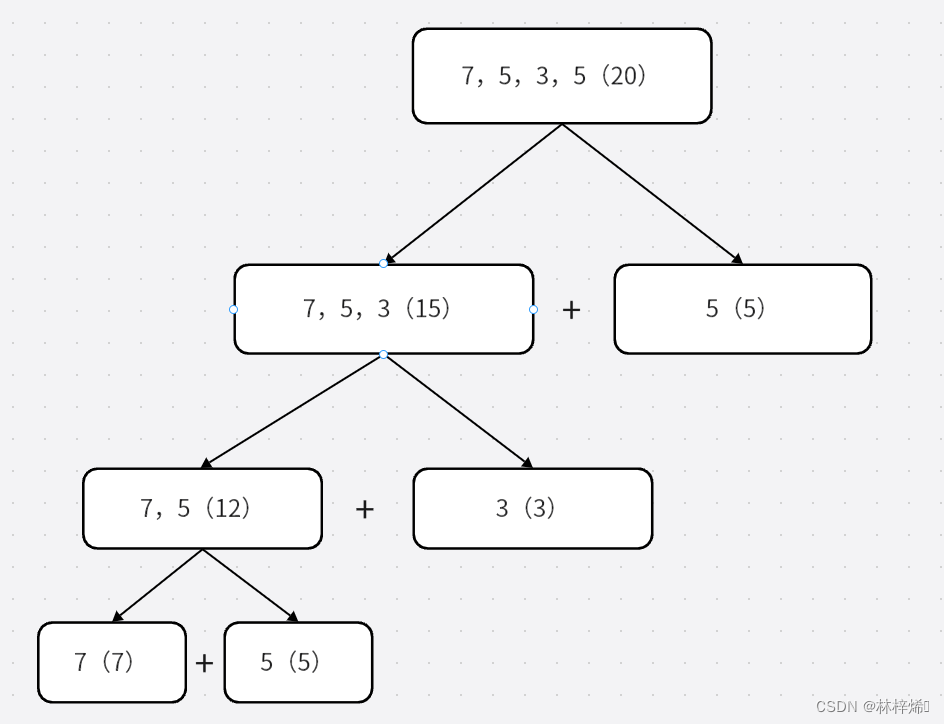
如下图计算一个一维数组[7,5,3,5]的和的步骤
括号内为该子问题的解,从最底层不断向上求解原问题的解
下面通过一道简单的例题来了解掌握减一治的算法设计流程。
问题:
求一个数的n次方
解决办法:把问题分解为求a的n-1次方,原问题结果为a的n-1次方的结果与a的乘积。
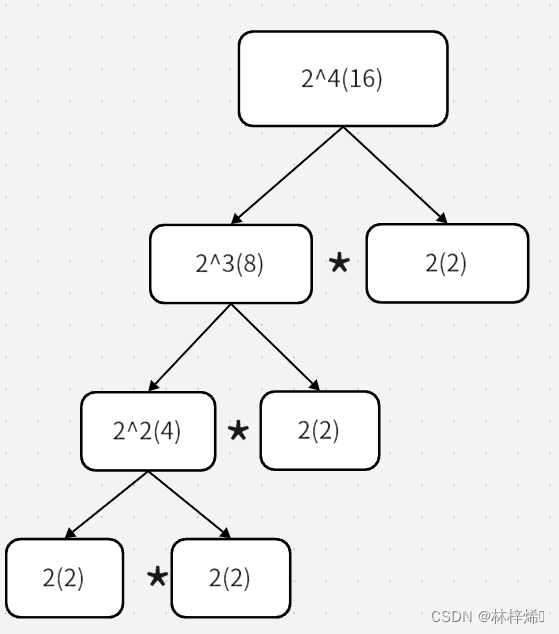
下面是使用减治法求2的4次方的求解步骤
递归求解,至下而上得到原问题的解,括号内为该子问题的解
算法描述与分析:
算法:求a的n次方getPowerByDecrease
输入:待求乘方元素a,待求次方n
输出:a的n次方
过程:
- 如果n=1,只需求a的1次方,返回a,算法结束;
- 调用getPowerByDecrease(a,n-1)计算a的n-1次方;
- 返回a与a的n-1次方的乘积;
算法实现:
public static int getPowerByDecrease(int a, int n){
if(n == 1)
return a;
return a * getPowerByDecrease(a, n - 1);
}时间复杂度计算:
T(n)=1,n=1;
T(n)=T(n-1)+1,n>1;
T(n)=T(n-1)+1=T(n-2)+2=T(n-k)+k;
令n-k=1,k=n-1,T(n)=T(1)+n-1=T(n);时间复杂度为O(n)
一般来说,减一治并不能降低时间复杂度(与蛮力法相比),与分治法求解的时间复杂度相同。
测试数据:
![]()
测试结果:
二、减半治
掌握减一治后我们再来看看减半治算法的实现。
问题:
有序数组查找问题
解决办法:
每次通过把元素与区间中值进行比较来将搜索区间缩小到左半区间或右半区间,递归直到区间只剩一个元素或中值即为所找元素;
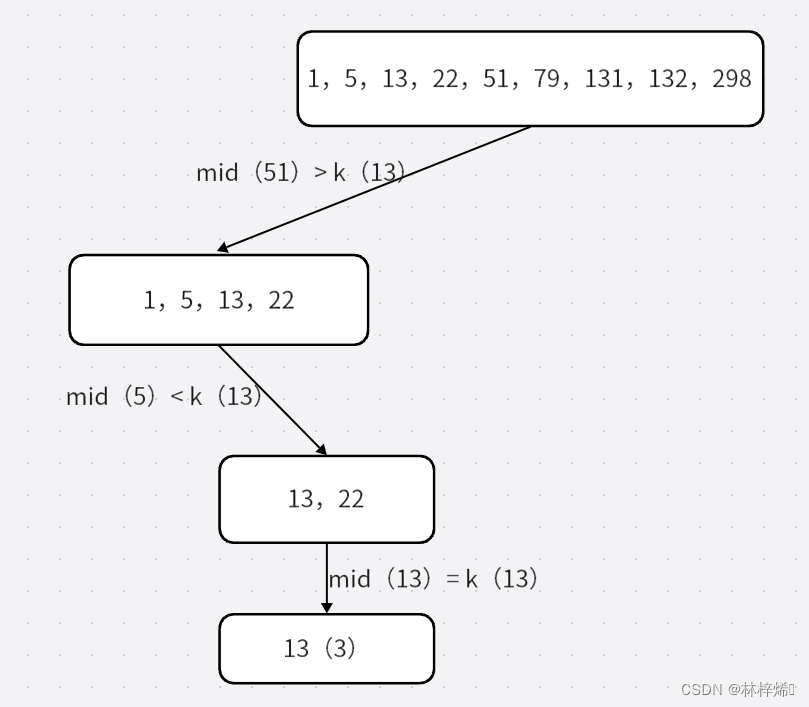
算法流程:
数组:[1,5,13,22,51,79,131,132]
k:13
算法描述与分析:
算法:有序数组查找问题findXByDecrease
输入:一维数组a[],搜索区间最小下标l,最大下标r,待查找元素k;
输出:所查找元素的位置(未找到为0)
过程:
1. 如果l==r,区间只有一个元素,判断该元素是否为k,是则返回l+1,否则返回0,算法结束;
2. 计算区间中点mid=(l+r)/2;
3. 如果k==a[mid],则返回mid+1;
4. 如果k<a[mid],则递归调用findXByDecrease(a,l,mid-1,k)继续搜索 左区间;
5. 如果k>a[mid],则递归调用findXByDecrease(a,mid+1,r,k)继续搜索 左区间;
算法实现:
public static int findXByDecrease(int[] a, int l, int r, int k){
if(l == r){
if(a[l] == k)
return l + 1;
else
return 0;
}
int mid = (l + r) / 2;
if(k < a[mid])
return findXByDecrease(a, l, mid - 1, k);
else if (k == a[mid]) {
return mid + 1;
}
else
return findXByDecrease(a, mid + 1, r, k);
}时间复杂度计算:
T(n)=1,n=1;
T(n)=T(n/2)+1,n>1;
T(n)=T(n/2)+1=T(n/4)+2=T(n/2^k)+k;
令n/2^k=1,k=log2n,T(n)=T(1)+log2n;
时间复杂度为O(log2n);
可以看出时间复杂度相比蛮力法有很大的提升,尤其是当数据规模非常大的时候,此算法的运行的时间会比蛮力法少非常多。
测试数据:
![]()
![]()
运行结果(这里的结果不是该元素的下标,而是该元素的位置(下标+1)):
![]()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)