机器学习学习
循环神经网络(Recurrent Neural Network):NN 结构只能单独的去处理一个个的输入,前一个输入和后一个输入是完全没有关系的,RNN 允许神经单元包含循环,这样信息可以在不同时刻传输,适合时序数据预测(例如,自然语言处理,语音识别,监控时序数据等)。Transformer模型:摒弃了固有的定式,并没有用任何CNN或者RNN的结构,而是使用了Attention注意力机制,自动捕捉
机器学习类型(按学习方式分):监督学习、半监督学习、无监督学习、强化学习;
通过已知标签训练集训练模型,使用模型及逆行预测、测试;
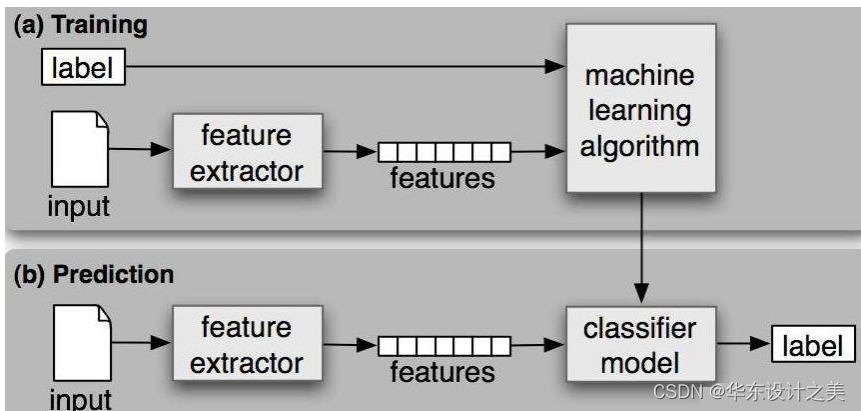
向量表示法,其中每一维对应一个特征(feature)或者称为属性,记为[x1,x2,...,xn]
特征值、特征、标签,共同完成训练集的数据填充,最后辅以训练样例;
不同量纲的数据则需要进行去量纲,分为区间缩放和标准化;


特征值缺失:可以分为删除数据和插补数据;
删除数据:按行、成对删除、删除变量;
插补数据:时间序列问题(无趋势、有趋势、季节性数据/均值、中位数、众数、随机插补、线性插值、季节性调整)、一般性问题(分类数据、连续数据/回归);
构建模型,确定要找的是哪类规律(函数形式)或者说假设空间,比如线性函数;随后确定策略,从众多可能的规律中选出最好的选择标准,比如某个损失函数最小;再进行算法选择,如何快速寻找到最好结果,比如牛顿法;
常见机器学习模型:线性回归,逻辑回归,决策树,支持向量机,神经网络模型;
损失函数的选择:损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
分类评价:评价必须基于测试数据进行,而且该测试数据是与训练数据完全隔离的。指标:正确率、召回率、 F1值、分类精确率(classification accuracy)等等
正确率及召回率:

度量的方法:
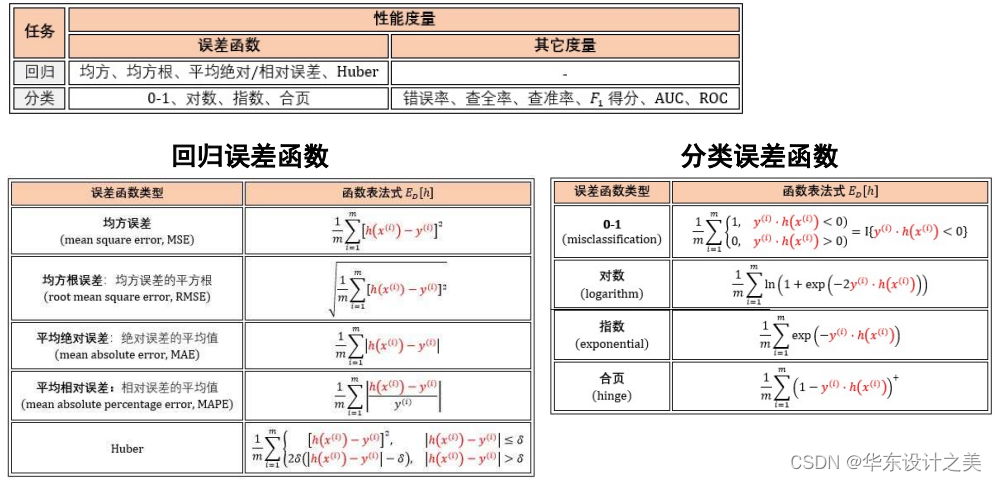
训练集、验证集(开发集)、测试集:
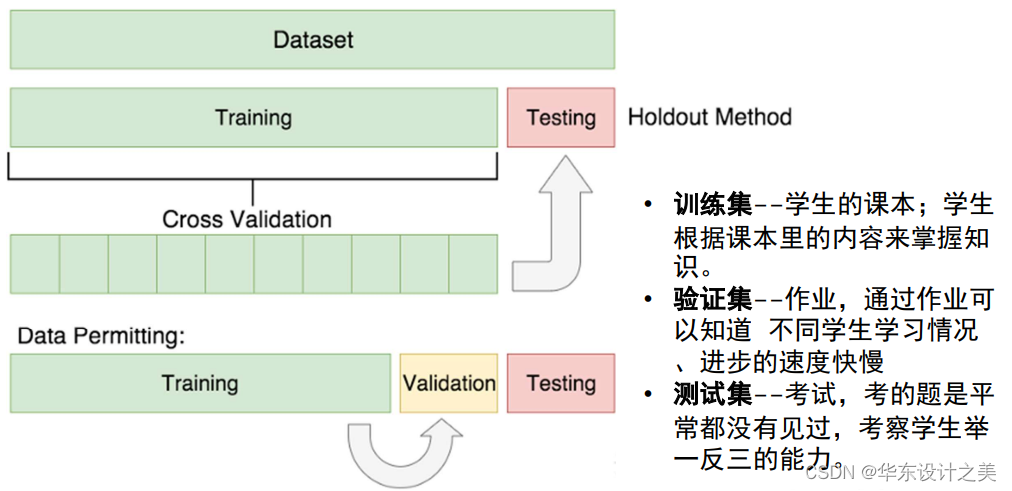
系统栈:
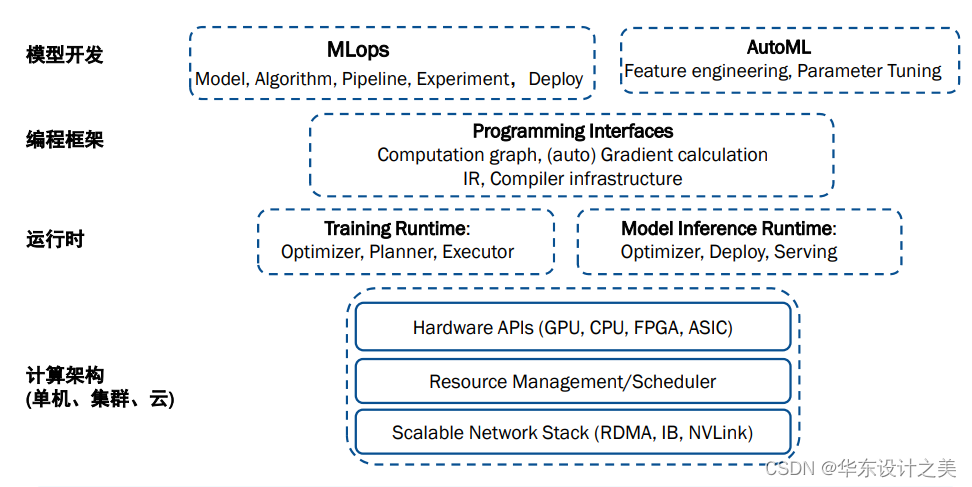
损失函数,评价模型好坏,机器学习的目标就是让损失函数值尽量小;
2个参数的损失函数:通过二维面来描述;
采用矩阵计算的表示方式:矩阵计算可以使用GPU加速、GPU是深度神经网络训练的基础,一个神经网络的计算过程可以表示为一个具体的函数;

Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
并行模式:计算并行、数据并行、模型并行;墙上时钟时间wall clock time,cpu总时间是所有不同线程或进程cpu时间之和,利用多个CPU/GPU同时计算,加快速度,减少wall clock time,并不能减少CPU/GPU的运行总时长;
神经网络-随机并行:神经网络具有一定的冗余性,可以找到一个规模小很多的子网络(称为骨架网络),其效果与原网络差不多;骨架网络,作为公用子网络存储于每个工作节点;每个工作节点随机选取一些其他节点存储,以探索(exploration)骨架网络之外的信息;骨架网络周期性的依据新的网络重新选取,而用于探索的节点也会每次随机选取;
通信机制:通信内容、网络拓扑、任务同步机制(时延=通信的内容* 通信的次数/带宽)
通信的拓扑结构:基于参数服务器的通信(master-slave)
Parameter Server模式是一种基于reduce和broadcast算法的经典架构;其中一个/一组机器作为PS架构的中心节点,用来存储参数和梯度。在更新梯度的时候,先全局reduce接受其他worker节点的数据,经过本地计算后(比如参数平均法),再broadcast回所有其他worker。
任务同步机制:并行化算法通信类别
同步并行BSP:采用具有同步障的通信协调并行 收敛性AAA
异步并行ASP:采用不含同步障的通信协调并行 收敛性A
半同步并行SSP:采用具有限定的宽松同步障的通信协调并行 收敛性AA
分布式机器学习系统
什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
深度学习基本模型:
卷积神经网络(Convolutional Neural Network):人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。
循环神经网络(Recurrent Neural Network):NN 结构只能单独的去处理一个个的输入,前一个输入和后一个输入是完全没有关系的,RNN 允许神经单元包含循环,这样信息可以在不同时刻传输,适合时序数据预测(例如,自然语言处理,语音识别,监控时序数据等)。
Transformer模型:摒弃了固有的定式,并没有用任何CNN或者RNN的结构,而是使用了Attention注意力机制,自动捕捉输入序列不同位置处的相对关联,善于处理较长文本,并且该模型可以高度并行地工作,训练速度很快。
深度学习计算框架的目的:提供灵活的编程模型和编程接口。简洁的神经网络计算原语编程语言,用高层次语义描述出各类主流深度学习模型的计算过程和训练算法;提供直观地模型构建方式;较好的支持与现有生态环境融合;
提供高效和可扩展的计算能力:自动推导计算图;自动编译优化算法,包括不限于:公共子表达式消除,内核融合,内存布局优化等;根据不同体系结构和硬件设备自动并行化,为可复用的处理单元提供高效实现;自动分布式化,并扩展到多个计算节点;支持多设备、分布式计算;降低新模型的开发成本,在添加新硬件支持时,降低增加计算原语和进行计算优化的开发成本。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)