用python爬虫带你爬取4399小游戏
·
使用python爬虫爬取4399小游戏
准备环境:
python环境,pycharm,requests库,csv库,lxml库
公众号回复 4399 获取源代码
教程:
打开4399网站,打开开发者模式,搜索关键字,
观察发现所有的东西都在页面源代码中
每一个游戏对应着每一个ul标签下的li下
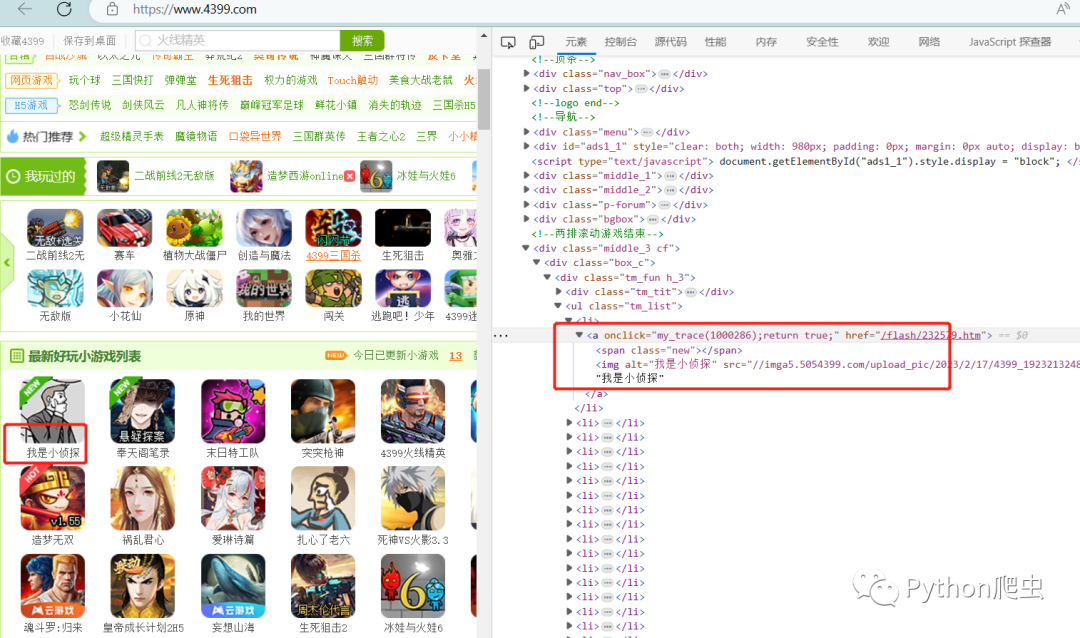
思路:
拿到页面源码,提取出li标签的数据,再二次提取
上代码:
访问网站
url = 'https://www.4399.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63'
}
response = requests.get(url\=url,headers\=headers)
可以看到这个页面使用的是gb2312编码格式

所以我们也改成gb2312
然后用xpath来提取出每一个li标签
response = requests.get(url\=url,headers\=headers)
response.encoding='gb2312'
page = response.text
html = etree.HTML(page)
lis = html.xpath('//\*\[@id="skinbody"\]/div\[10\]/div\[1\]/div\[1\]/ul/li')
for循环每一个li标签,二次提取出游戏名字和游戏地址
for li in lis:
href = ''.join(li.xpath('./a/@href'))
dit\['游戏地址'\] = 'https://www.4399.com/'+href
dit\['游戏名'\] = ''.join(li.xpath('./a/text()'))
w\_header.writerow(dit)
print(dit,'已保存!')
并且保存到csv
看效果:
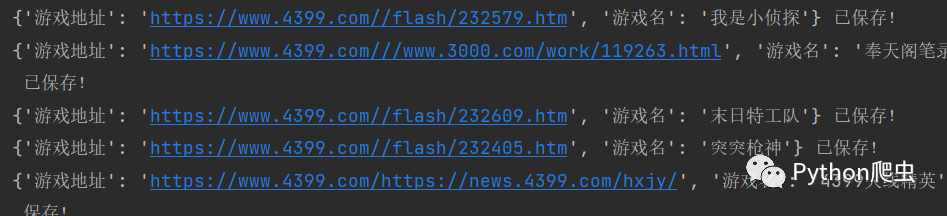
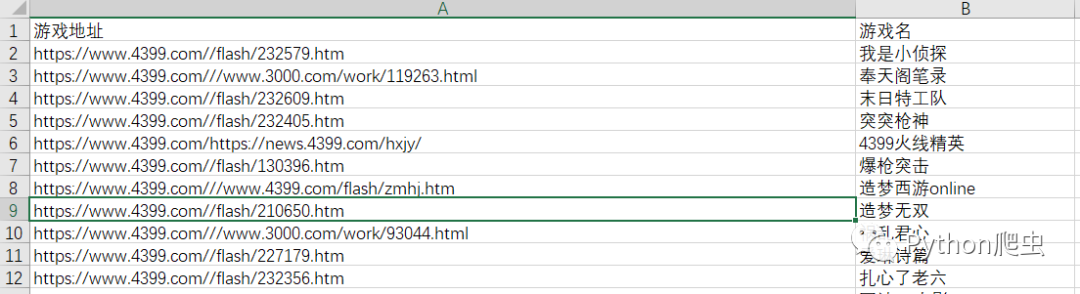
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
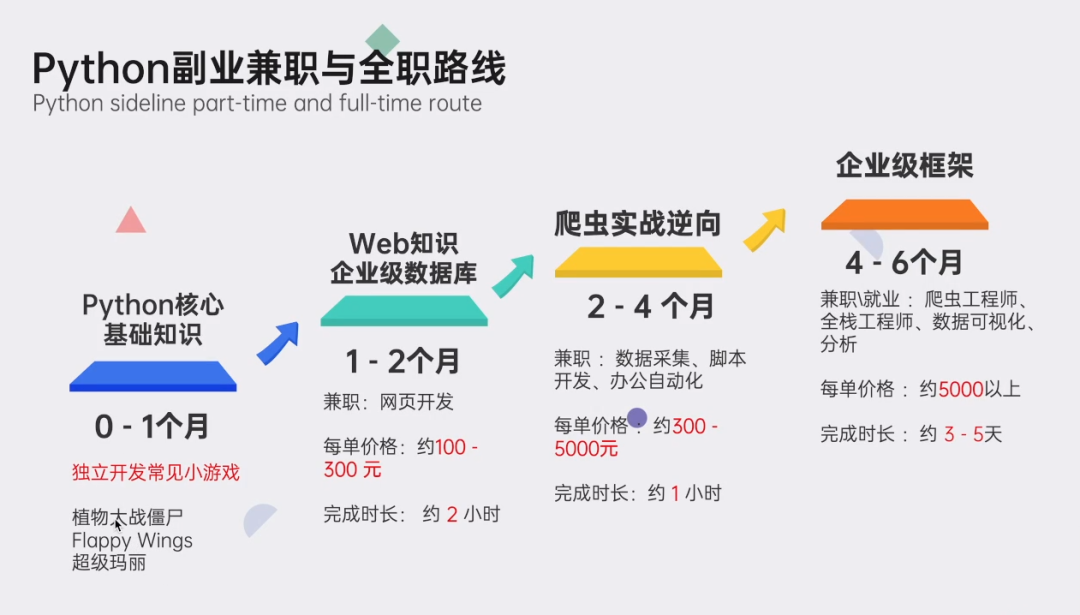
👉Python副业创收路线👈
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)