Python 爬虫项目实战(四):爬取当当网好评榜 Top 500
·
前言
网络爬虫(Web Crawler),也称为网页蜘蛛(Web Spider)或网页机器人(Web Bot),是一种按照既定规则自动浏览网络并提取信息的程序。爬虫的主要用途包括数据采集、网络索引、内容抓取等。
爬虫的基本原理
- 种子 URL:爬虫从一个或多个种子 URL 开始,这些 URL 是起点。
- 发送请求:爬虫向这些种子 URL 发送 HTTP 请求,通常是 GET 请求。
- 获取响应:服务器返回网页的 HTML 内容作为响应。
- 解析内容:爬虫解析 HTML 内容,提取所需的数据(如文本、链接、图片等)。
- 提取链接:从网页中提取出所有链接,并将这些链接加入待访问队列。
- 重复过程:爬虫重复上述步骤,直到达到某个停止条件,如爬取了一定数量的页面,或所有页面都被爬取完毕。
爬虫的分类
-
通用爬虫
- 设计用于抓取整个互联网的大量网页。搜索引擎(如 Google、Bing)的爬虫就是通用爬虫。
-
聚焦爬虫
- 专注于特定主题或领域,抓取相关网页。比如,一个新闻爬虫只抓取新闻网站的内容。
-
增量爬虫
- 仅抓取自上次爬取以来发生变化或更新的网页,适用于动态内容更新频繁的网站。
爬虫的合法性和道德
在编写和运行爬虫时,必须遵循以下原则:
-
遵守网站的
robots.txt:-
大多数网站都有一个
robots.txt文件,规定了哪些页面允许被爬取,哪些不允许。爬虫应当尊重这些规则。
-
-
避免过度抓取:
- 设置适当的抓取频率,避免对服务器造成过大负担。
-
尊重版权和隐私:
- 不应抓取或使用受版权保护的内容,或涉及用户隐私的数据。
-
获取许可:
- 在某些情况下,最好获得网站管理员的许可,特别是当你打算频繁地抓取大量数据时。
通过以上方法和原则,可以编写高效、可靠且合规的网络爬虫来满足数据采集的需求。
侦察
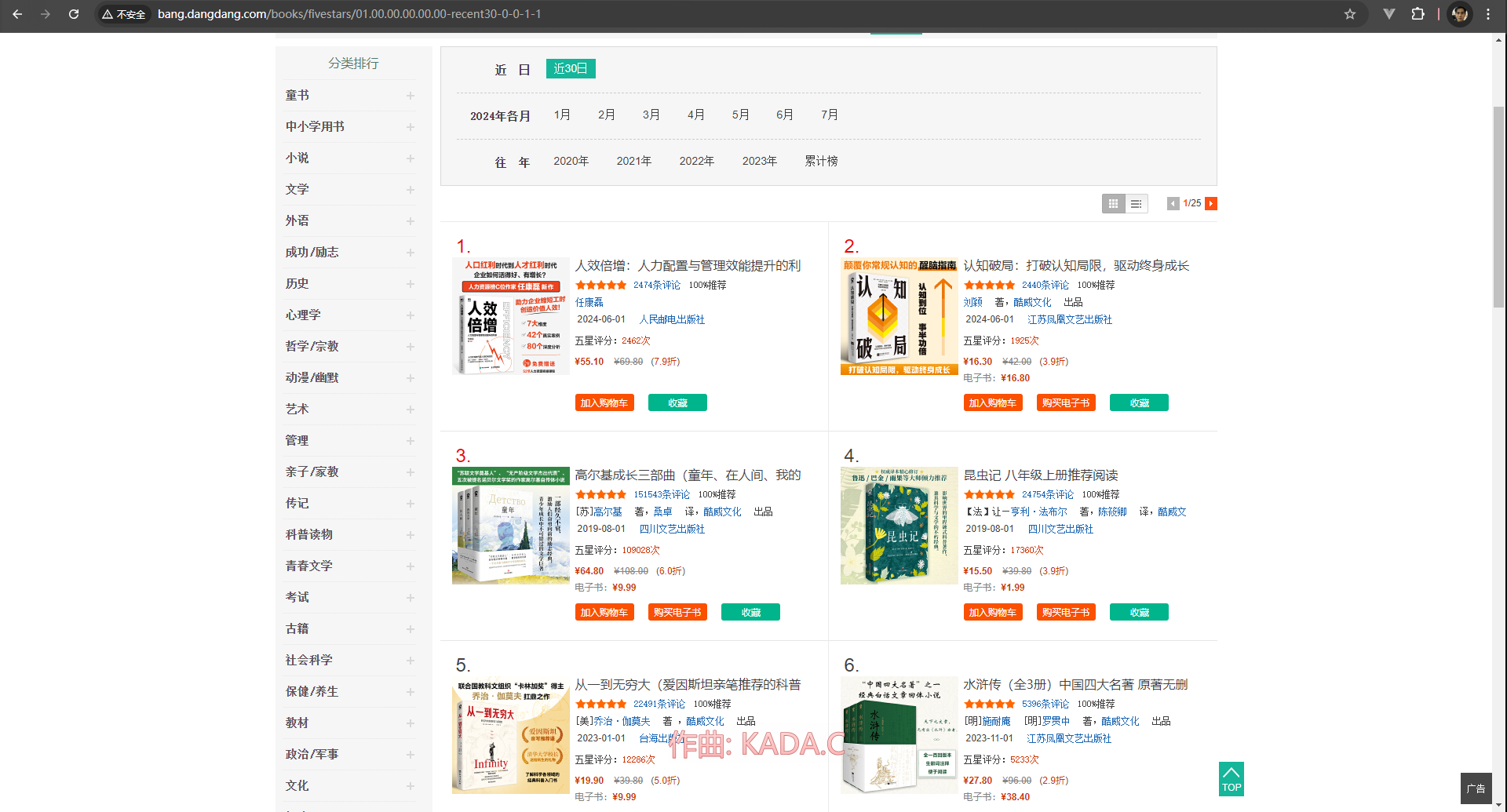
本次爬取网站如下
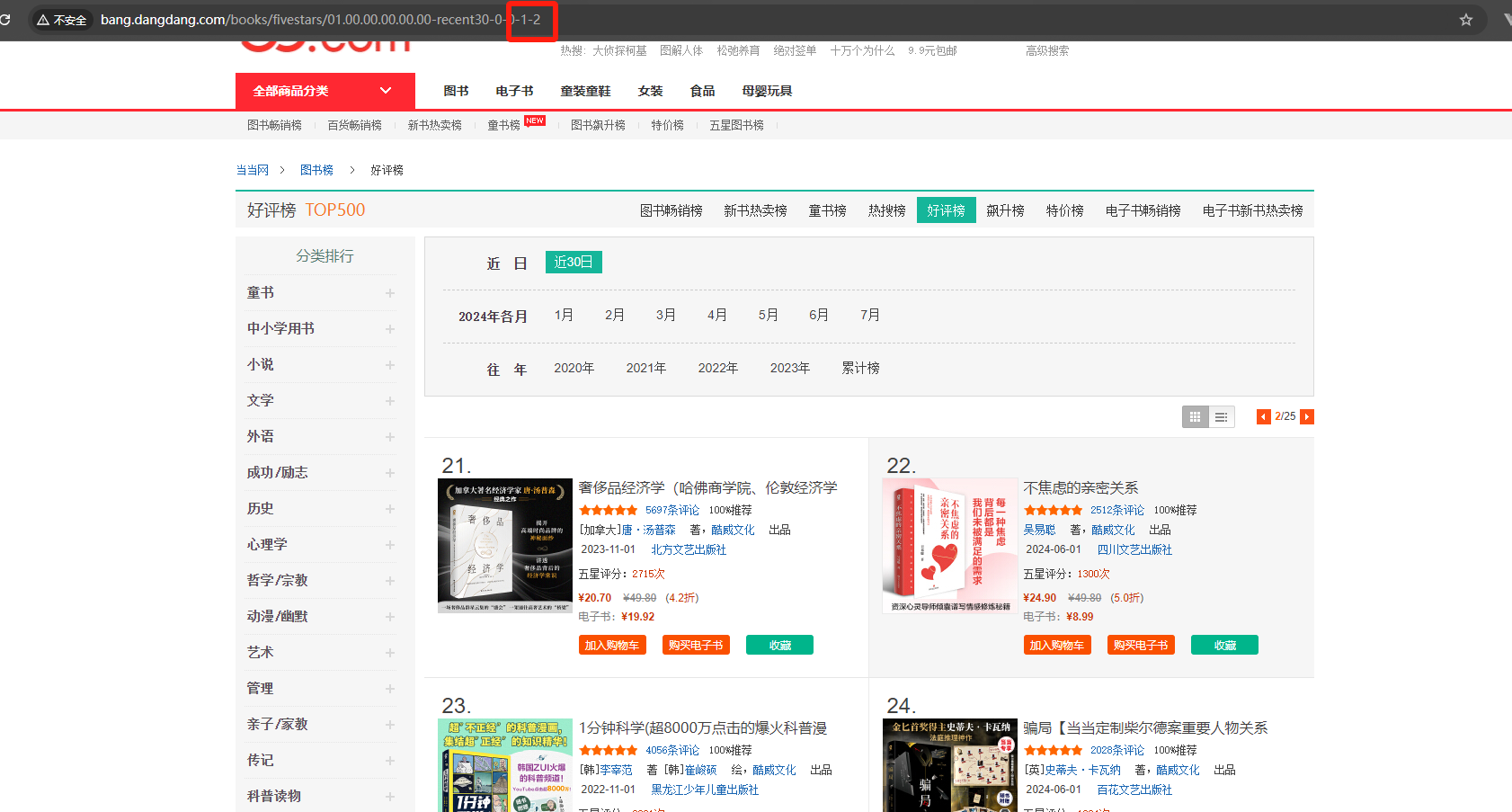
点击下一页发现 url 最后一个参数 +1
请求头
cookie

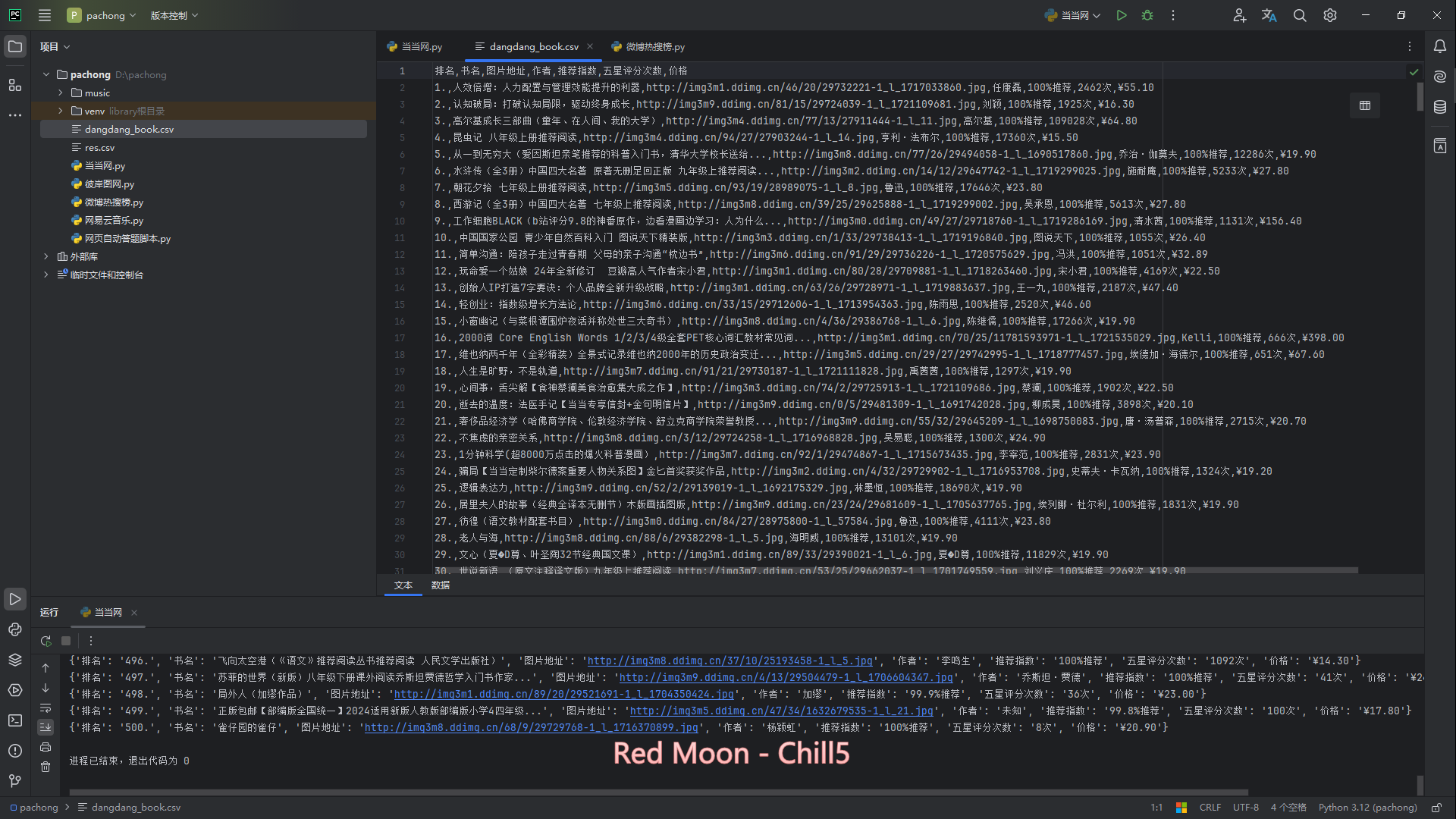
我们需要的是排名、书名、图片地址、作者、推荐指数、五星评分次数、价格
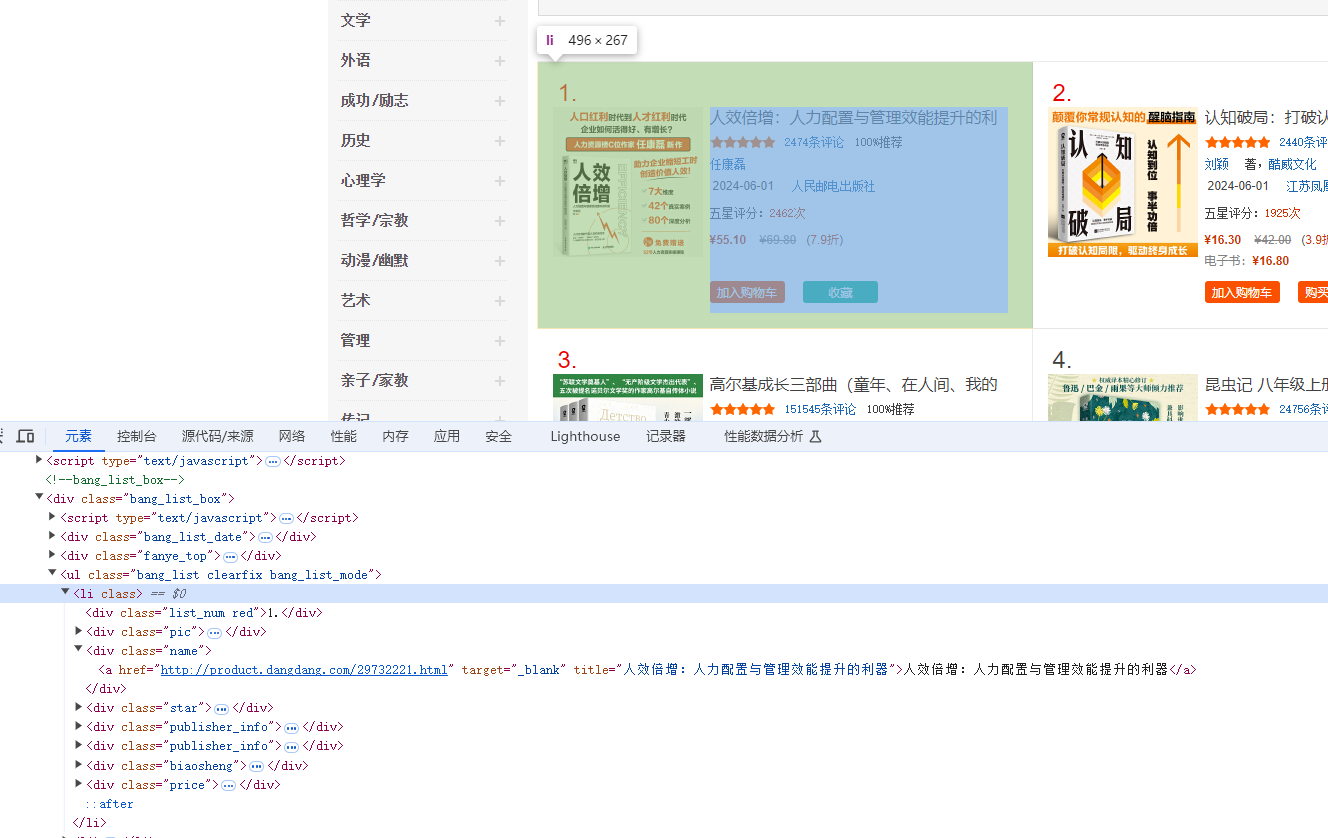
源代码
import csv
import requests
from bs4 import BeautifulSoup
# 创建 csv 文件
# 'a' 表示以追加模式(append mode)打开文件
# newline=''的作用是确保在写入文件时,所有的换行符都使用'\n'
f = open('dangdang_book.csv', 'a', encoding='utf-8', newline='')
# csv.DictWriter 类用于将字典格式的数据写入 CSV 文件
# 每个字典表示一行,字典的键对应 CSV 文件的列名
csv_writer = csv.DictWriter(f, fieldnames=['排名', '书名', '图片地址', '作者', '推荐指数', '五星评分次数', '价格'])
# 写入表头行,包含指定的字段名
csv_writer.writeheader()
# 请求页数
num = 1
# 伪造请求头
headers = {
'cookie': 'ddscreen=2; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20240802220700804382492227248503587; __rpm=%7C...1722668179327; __visit_id=20240803145620069300007553500913382; __out_refer=; __trace_id=20240803145703426425192102475401412',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 创建字典保存数据
dic = {}
# 循环请求每一页数据
while num < 26:
# 请求地址
url = 'http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-' + str(num)
# 发送请求
response = requests.get(url, headers=headers)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'lxml')
# 找到页面上的第一个<ul>标签
ul_tag = soup.find('ul', class_='bang_list clearfix bang_list_mode')
# 提取<ul>标签下的所有<li>元素
li_elements = ul_tag.find_all('li')
# 循环保存<li>元素中的数据
for li in li_elements:
# .get_text() 方法有几个参数,其中 strip 是一个常用的参数,它接受一个布尔值(True 或 False)
# 当 strip 参数设置为 True 时,.get_text() 方法会去除从标签中提取的文本的首尾空白字符
# 当 strip 参数设置为 False 或者不提供该参数时,.get_text() 方法会保留文本的首尾空白字符
# 排名
list_num = li.find('div', class_='list_num').get_text(strip=True)
# 书名
name = li.find('div', class_='name').find('a').get_text(strip=True)
# 图片地址
pic = li.find('div', class_='pic').find('a').find('img').get('src')
# 作者信息可能不存在,所以需要检查
publisher_info_div = li.find('div', class_='publisher_info')
publisher_info_a = publisher_info_div.find('a') if publisher_info_div else None
publisher_info = publisher_info_a.get_text(strip=True) if publisher_info_a else '未知'
# 推荐指数
star = li.find('div', class_='star').find('span', class_='tuijian').get_text(strip=True)
# 五星评分次数
biaosheng = li.find('div', class_='biaosheng').find('span').get_text(strip=True)
# 价格
price = li.find('div', class_='price').find('p').find('span', class_='price_n').get_text(strip=True)
# 保存数据
dic = {
'排名': list_num,
'书名': name,
'图片地址': pic,
'作者': publisher_info,
'推荐指数': star,
'五星评分次数': biaosheng,
'价格': price
}
print(dic)
# writerow 写入数据
csv_writer.writerow(dic)
num += 1
项目效果

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)