2025年最新中科院1区最新算法!整体群优化算法(Holistic Swarm Optimization,HSO),附完整MATLAB免费代码
本文介绍了一种称为整体群优化(HSO)的新型无隐喻优化算法,旨在通过利用来自整个种群的数据来增强搜索过程。与依赖部分或局部信息的传统算法不同,HSO采用了一种综合方法,确保每个决策都由种群的整体分布和适应度景观来告知。该算法通过一个自适应框架动态平衡探索和开发,该框架集成了基于均方根(RMS)适应度的位移系数、基于模拟退火的选择和自适应变异。这种结构使HSO能够有效地导航复杂的多模态优化问题,同时
1、简介
本文介绍了一种称为整体群优化(HSO)的新型无隐喻优化算法,旨在通过利用来自整个种群的数据来增强搜索过程。与依赖部分或局部信息的传统算法不同,HSO采用了一种综合方法,确保每个决策都由种群的整体分布和适应度景观来告知。该算法通过一个自适应框架动态平衡探索和开发,该框架集成了基于均方根(RMS)适应度的位移系数、基于模拟退火的选择和自适应变异。这种结构使HSO能够有效地导航复杂的多模态优化问题,同时避免局部最优。2025年最新发表在中科院一区期刊Computer Methods in Applied Mechanics and Engineering。
2. 全息群优化(HSO)
全息群优化(HSO)算法旨在利用整个种群的信息全面更新每个成员的位置。通过利用所有代理的信息,HSO 确保搜索过程被种群整体分布和适应度景观的完整理解所指导。这种方法导致更稳健和全面的搜索,根据实时反馈动态平衡探索和开发。所提出的 HSO 算法的不同阶段在以下小节中介绍和讨论。
2、HSO算法
2.1 种群初始化
算法通过初始化一组搜索代理开始,记为 xix_ixi,对于 i=1,2,…,ni = 1, 2, \ldots, ni=1,2,…,n,其中 nnn 是代理数量。每个代理的位置是在定义的搜索空间内随机生成的。每个搜索代理 xix_ixi 表示优化问题的潜在解决方案,其本身是 mmm 维的。
2.2 适应度评估
每个搜索代理的适应度基于目标函数 f(xi)f(x_i)f(xi) 进行评估。
2.3 系数计算
所有适应度值的均方根(RMS)表示为 RMSfRMS_fRMSf,计算如下:
RMSf=1n∑i=1nf(xi)2(1) RMS_f = \sqrt{\frac{1}{n} \sum_{i=1}^{n} f(x_i)^2} \tag{1} RMSf=n1i=1∑nf(xi)2(1)
其中 f(xi)f(x_i)f(xi) 是代理 iii 的适应度值。然后,基于每个适应度值与 RMS 的差异计算位移向量的系数。代理 iii 的差异由以下公式给出:
di=RMSf−f(xi)(2) d_i = RMS_f - f(x_i) \tag{2} di=RMSf−f(xi)(2)
系数 cic_ici 被分配为低于 RMS 的差异的正值,高于 RMS 的差异的负值,绝对值归一化至 1:
ci=sign(di)⋅∣di∣∑i=1n∣di∣(3) c_i = \frac{\text{sign}(d_i) \cdot |d_i|}{\sum_{i=1}^{n} |d_i|} \tag{3} ci=∑i=1n∣di∣sign(di)⋅∣di∣(3)
其中 sign(di)\text{sign}(d_i)sign(di) 是符号函数,指示每个代理的移动方向。
2.4 位置更新
搜索代理的位置迭代更新。每个代理 xix_ixi 的新位置 xi′x_i'xi′ 受到其当前位置与所有其他代理位置之间差异的加权和的影响。更新如下:
xi′=xi+α∑j=1nrij⋅cj⋅(xj−xi)(4) x_i' = x_i + \alpha \sum_{j=1}^{n} r_{ij} \cdot c_j \cdot (x_j - x_i) \tag{4} xi′=xi+αj=1∑nrij⋅cj⋅(xj−xi)(4)
其中 α\alphaα 是常数参数,rijr_{ij}rij 是确保搜索空间多样性和全面探索的随机值。
2.5 基于自适应模拟退火的选择
基于模拟退火(SA)的选择过程包括每次迭代的动态温度更新。温度 TTT 更新如下:
T=Tinitial×CRiter(5) T = T_{\text{initial}} \times CR^{\text{iter}} \tag{5} T=Tinitial×CRiter(5)
其中 TinitialT_{\text{initial}}Tinitial 是初始温度,CRCRCR(冷却率)是控制温度下降速率的参数,iter\text{iter}iter 是当前迭代次数。
如果新适应度值 fnew(xi)f_{\text{new}}(x_i)fnew(xi) 优于先前的适应度值 f(xi)f(x_i)f(xi),则算法以贪婪方式操作并用新解替换旧解。另一方面,如果新适应度值 fnew(xi)f_{\text{new}}(x_i)fnew(xi) 比先前的适应度值 f(xi)f(x_i)f(xi) 更差,则应用以下标准进行选择:
Δf=fnew(xi)−f(xi)(6) \Delta f = f_{\text{new}}(x_i) - f(x_i) \tag{6} Δf=fnew(xi)−f(xi)(6)
新位置以概率 PPP 被接受,由以下公式给出:
P=exp(−ΔfT)(7) P = \exp \left(-\frac{\Delta f}{T}\right) \tag{7} P=exp(−TΔf)(7)
如果 PPP 大于从均匀分布 UunifU_{\text{unif}}Uunif 中随机抽取的数,则即使适应度降低,新位置也被接受:
if exp(−ΔfT)>Uunif,and \text{if } \exp \left(-\frac{\Delta f}{T}\right) > U_{\text{unif}}, \text{and} if exp(−TΔf)>Uunif,and
总之,根据基于 SA 的选择操作,选择特定解的概率在某一迭代中达到比其先前位置更差的位置与最近迭代中其适应度值的不利变化水平成反比,并且随着迭代的进行,这种概率变得越来越小。这种设置在时间上平衡了探索和开发。
2.6 自适应变异
为了进一步增强探索能力,以自适应方式定义了变异算子,因此其变异率和变异步长根据当前迭代动态调整。变异率 λiteralter\lambda_{\text{iter}}^{\text{alter}}λiteralter 和变异步长 δiteralter\delta_{\text{iter}}^{\text{alter}}δiteralter 计算如下:
λiteralter=λinit−iter×(λinit−λfinalitermax)(9) \lambda_{\text{iter}}^{\text{alter}} = \lambda_{\text{init}} - \text{iter} \times \left(\frac{\lambda_{\text{init}} - \lambda_{\text{final}}}{\text{iter}_{\text{max}}}\right) \tag{9} λiteralter=λinit−iter×(itermaxλinit−λfinal)(9)
其中 λalteriter\lambda_{\text{alter}}^{\text{iter}}λalteriter 是迭代 iter\text{iter}iter 处的变异率,λinit\lambda_{\text{init}}λinit 是初始变异率,λfinal\lambda_{\text{final}}λfinal 是最终变异率,iter\text{iter}iter 是当前迭代次数,itermax\text{iter}_{\text{max}}itermax 是最大迭代次数。
δiteralter=δinit−iter×(δinit−δfinalitermax)(10) \delta_{\text{iter}}^{\text{alter}} = \delta_{\text{init}} - \text{iter} \times \left(\frac{\delta_{\text{init}} - \delta_{\text{final}}}{\text{iter}_{\text{max}}}\right) \tag{10} δiteralter=δinit−iter×(itermaxδinit−δfinal)(10)
其中 δiteralter\delta_{\text{iter}}^{\text{alter}}δiteralter 是迭代 iter\text{iter}iter 处的变异步长,δinit\delta_{\text{init}}δinit 是初始变异步长,δfinal\delta_{\text{final}}δfinal 是最终变异步长。
变异率 λiteralter\lambda_{\text{iter}}^{\text{alter}}λiteralter 决定了在迭代过程中发生变异的概率。随着迭代次数的增加,λiteralter\lambda_{\text{iter}}^{\text{alter}}λiteralter 从其初始值 λinit\lambda_{\text{init}}λinit 线性减少到其最终值 λfinal\lambda_{\text{final}}λfinal。同样,变异步长 δiteralter\delta_{\text{iter}}^{\text{alter}}δiteralter 控制应用于搜索代理位置的扰动幅度。它也从其初始值 δinit\delta_{\text{init}}δinit 线性减少到其最终值 δfinal\delta_{\text{final}}δfinal,随着算法的进展。这种配置允许 HSO 在初始迭代中更广泛地探索搜索空间,同时随着接近最大迭代次数而逐渐专注于开发当前解决方案。
如果发生变异(以等于 λiteralter\lambda_{\text{iter}}^{\text{alter}}λiteralter 的概率),则向代理的位置添加随机扰动 Δxi\Delta x_iΔxi:
Δxi=δmutalter⋅N(0,1)(11) \Delta x_i = \delta_{\text{mut}}^{\text{alter}} \cdot \mathcal{N}(0, 1) \tag{11} Δxi=δmutalter⋅N(0,1)(11)
其中 N(0,1)\mathcal{N}(0, 1)N(0,1) 是标准正态分布,Δxi\Delta x_iΔxi 是修改代理 xix_ixi 当前位置的变异向量。
更新后代理 iii 的位置 xi′x_i'xi′ 计算如下:
xi′=xi+Δxi(12) x_i' = x_i + \Delta x_i \tag{12} xi′=xi+Δxi(12)
其中 xi′x_i'xi′ 是代理经过变异后的新位置。
通过遵循这些步骤,HSO 算法有效地平衡了全局和局部搜索策略,确保在各种问题领域中实现稳健的优化性能。所提出的算法的伪代码在算法 1 中呈现,并在图 1 和图 2 中展示。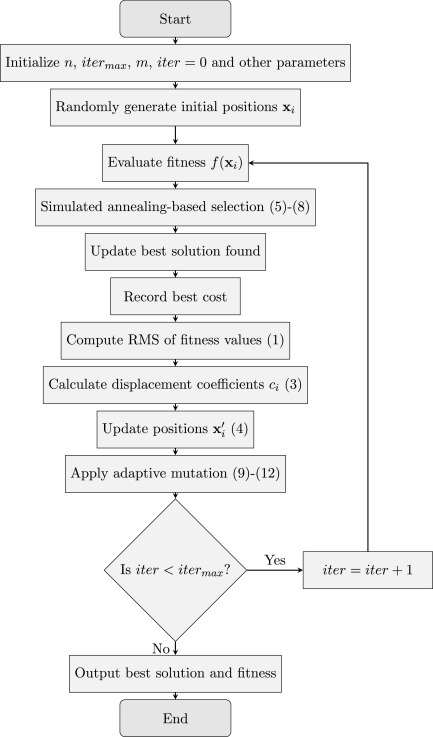
3、完整代码
%% Holistic Swarm Optimization (HSO)
% "Holistic Swarm Optimization: A Novel Metaphor-less Algorithm Guided by Whole Population Information
% for Addressing Exploration-Exploitation Dilemma"
% DOI: https://doi.org/10.1016/j.cma.2025.118208
function [Best_fitness, Xbest, bestCosts] = HSO(pop, maxIter, lb, ub, dim, fobj)
nPop = pop; % Population size
maxIt = maxIter; % Maximum number of iterations
alpha = 3; % Scaling factor for position updates
% Simulated Annealing parameters
initialTemp = 10000;
coolingRate = 0.995;
% Adaptive Mutation parameters
initialMutationRate = 0.5;
finalMutationRate = 0.1;
initialMutationStep = 0.3;
finalMutationStep = 0.1;
%% Problem Definition
nVar = dim; % Number of decision variables
varMin = lb; % Lower bound
varMax = ub; % Upper bound
%% Initialization
bestSol.position = zeros(1, nVar);
bestSol.cost = inf;
positions = rand(nPop, nVar) .* (varMax - varMin) + varMin;
positionsNew = positions;
fitness = inf(1, nPop);
fitnessNew = fitness;
bestCosts = zeros(1, maxIt);
iter = 0;
%% Main Loop
while iter < maxIt
temp = initialTemp * (coolingRate ^ iter);
% Update adaptive mutation parameters
mutationRate = initialMutationRate - iter * ((initialMutationRate - finalMutationRate) / maxIt);
mutationStep = initialMutationStep - iter * ((initialMutationStep - finalMutationStep) / maxIt);
for i = 1:nPop
% Ensure positions remain within bounds
positionsNew = max(min(positionsNew, varMax), varMin);
% Evaluate fitness of each agent
fitnessNew(i) = fobj(positionsNew(i, :));
% Selection using greedy and SA-based criteria
if fitnessNew(i) < fitness(i)
positions(i, :) = positionsNew(i, :);
fitness(i) = fitnessNew(i);
else
delta = fitnessNew(i) - fitness(i);
if exp(-delta / temp) > rand
positions(i, :) = positionsNew(i, :);
fitness(i) = fitnessNew(i);
end
end
end
% Sort and archive best solution
[fitness, idx] = sort(fitness);
positions = positions(idx, :);
if fitness(1) < bestSol.cost
bestSol.cost = fitness(1);
bestSol.position = positions(1, :);
end
%% Coefficient Calculation (simplified, without sign)
fitnessVector = fitness(:);
differences = rms(fitnessVector) - fitnessVector;
updateCoef = differences / sum(abs(differences));
%% Position Update
for i = 1:nPop
for j = 1:nVar
randWeights = rand(nPop, 1);
displacement = alpha * sum(randWeights .* updateCoef .* (positions(:, j) - positions(i, j)));
positionsNew(i, j) = positions(i, j) + displacement;
end
end
%% Adaptive Mutation
for i = 1:nPop
if rand < mutationRate
mutationVector = mutationStep * randn(1, nVar);
positionsNew(i, :) = positionsNew(i, :) + mutationVector;
end
end
iter = iter + 1;
bestCosts(iter) = bestSol.cost;
end
Best_fitness = bestSol.cost;
Xbest = bestSol.position;
end
Akbari E, Rahimnejad A, Gadsden S A. Holistic swarm optimization: A novel metaphor-less algorithm guided by whole population information for addressing exploration-exploitation dilemma[J]. Computer Methods in Applied Mechanics and Engineering, 2025, 445: 118208.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)