c# 结构体 4字节对齐_「底层原理」高级开发必须懂的"字节对齐
认识字节对齐之前,假定int(4Byte),char(1Byte),short(2Byte)认识字节对齐先看段代码:struct Data1{char a;int b;short c;};struct Data2 {int a;char b;short c;};int main(){cout << sizeof(Data1) << endl;cout << si
·
认识字节对齐之前,假定int(4Byte),char(1Byte),short(2Byte)
认识字节对齐
先看段代码:
struct Data1{char a;int b;short c;};struct Data2 {int a;char b;short c;};int main(){cout << sizeof(Data1) << endl;cout << sizeof(Data2) << endl;getchar();return 1;}输出结果:128sizeof(Data1)和sizeof(Data2)分别表示Data1和Data2内存占用字节数,输出结果不一样是因为编译时对Data1和Data2做了不同的字节对齐。Data1的对齐为4Byte,Data2的对齐是2Byte。
假定存储起始地址为0x00,存储模型如下:
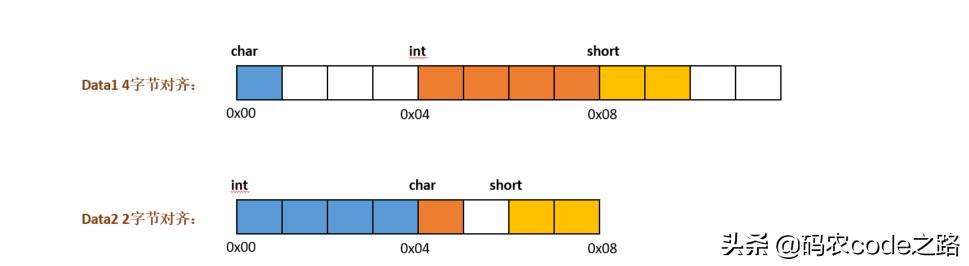
结构体或类中的每个成员都是内存对齐的。
编码时可以使用#pragma pack(x)来指定字节对齐大小,x必须为2的n次方,否则设定的字节对齐大小不生效。如上段代码开头加上#pragma pack(4),输出结果均为12。
为什么要字节对齐
首先明确:CPU从内存中读取数据的起始地址是对齐的。如下内存存储,cpu一次读取8个字节,对于int型数据则需要两次读取。如不对齐会降低执行效率。
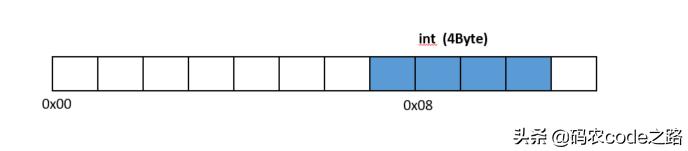
内存对齐目的:为了让CPU一次性获得基本类型的数据,从而提升程序执行效率。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)