Java,八股,cv,算法——双非研0四修之路day27
redis实践总结,JVM底层原理学习,快速回顾了一下mysql的基础篇,算法:二叉树的最大深度,二叉树的最小深度,完全二叉树节点的数量,平衡二叉树
目录
昨日总结
- redis实践总结,JVM底层原理学习,快速回顾了一下mysql的基础篇
- cv(停滞中)
- 背诵小林coding--Java虚拟机面试篇(4/5)
- 代码随想录——二叉树的最大深度,二叉树的最小深度,完全二叉树节点的数量,平衡二叉树
今日计划
- redis实践总结,JVM底层原理学习,学习mysql的进阶篇
- cv(停滞中)
- 背诵小林coding--Java虚拟机面试篇(5/5)
- 代码随想录——二叉树的所有路径,左叶子之和,找左下下角的值,路径总和
算法——二叉树的最大深度
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 :
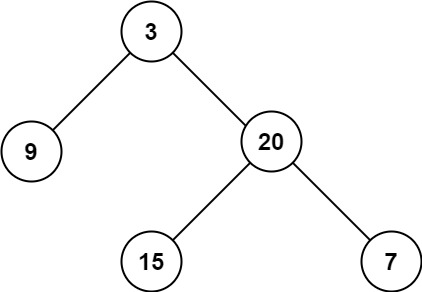
输入:root = [3,9,20,null,null,15,7] 输出:3
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null)
return 0;
int leftHigh = maxDepth(root.left);
int rightHigh = maxDepth(root.right);
int High = 1 + Math.max(leftHigh,rightHigh);
return High;
}
}算法——二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
示例 :
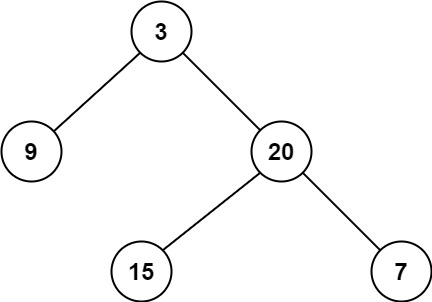
输入:root = [3,9,20,null,null,15,7] 输出:2
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int minDepth(TreeNode root) {
if(root == null)
return 0;
int leftHitg = minDepth(root.left);
int rightHitg = minDepth(root.right);
//注意是求叶子结点,要抛去为null的节点
if(root.left == null && root.right != null)
return 1 + rightHitg;
else if(root.left != null && root.right == null)
return 1 + leftHitg;
else
return 1 + Math.min(leftHitg,rightHitg);
}
}算法——完全二叉树节点的数量
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(从第 0 层开始),则该层包含 1~ 2h 个节点。
示例 :
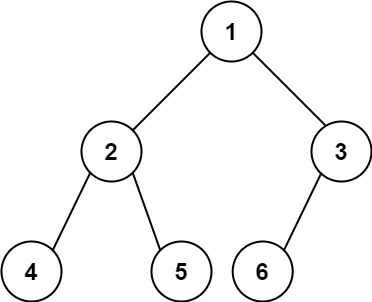
输入:root = [1,2,3,4,5,6] 输出:6
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
if(root == null) {
return 0;
}
int lcount = countNodes(root.left);
int rcount = countNodes(root.right);
int sum = 1 + lcount + rcount;
return sum;
}
}算法——平衡二叉树
给定一个二叉树,判断它是否是 平衡二叉树
示例 :
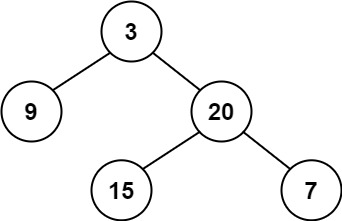
输入:root = [3,9,20,null,null,15,7] 输出:true
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int dg(TreeNode node) {
if(node == null) {
return 0;
}
int lh = dg(node.left);
int rh = dg(node.right);
return 1 + Math.max(lh,rh);
}
public boolean isBalanced(TreeNode root) {
if(root == null)
return true;
int lh = dg(root.left);
int rh = dg(root.right);
if(Math.abs(lh - rh) > 1)
return false;
boolean t = isBalanced(root.left);
boolean y = isBalanced(root.right);
return t && y;
}
}Jvm笔记
- 本地方法主要指的是由C或C++语言实现的相关库,用java语言来进行一个调用,实现功能的扩展
- 本地方法栈主要是和本地方法接口来打交道的
- 一个JVM实例只存在一个堆内存,堆也是java内存管理的核心代码区域
- java堆区在jvm启动的时候就被创建,其空间大小也就确定了。
- 堆内存的大小是可以调节的
- 堆在物理上可以不连续,但在逻辑上要连续
- 所有的线程共享java堆,但不是java堆所有都被共享,它可以划分出线程私有的缓冲区,给各个线程单独使用
- 数组和对象可能永远不会存储在栈上,因为栈帧中保存引用, 这个引用指向对象或者数组在堆中的位置
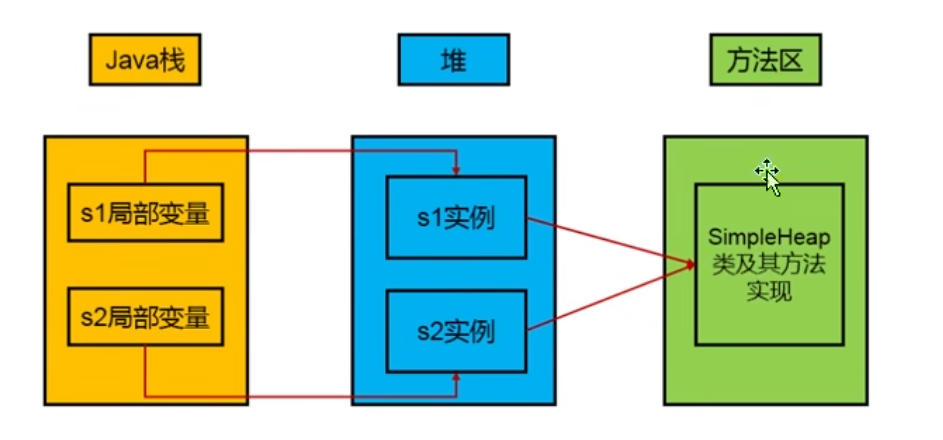
- 方法结束后,堆中存储的对象不会被立马被释放,当GC时才会被回收
- 现代垃圾收集器大部分都基于分代收集理论设 计,如下

Redis实践总结
优雅的key结构
- 【业务名称】:【数据名】:【id】
- 长度不超过44字节
- 这样做的优点:可读性强,避免key冲突,方便管理,更节省空间
合理的value结构
- 合理的拆分数据,拒绝BigKey
- 选择合适的数据结构(String类型,hash类型,字段打散:采用string和hash结合)
- hash结构的entry数量不要超过1000
- 设置合理的超时时间
BigKey的危害
- 网络阻塞:对bigkey执行请求时,少量的QPS就会导致带宽使用率被占满
- 数据倾斜:如果该key的使用率远超其他实例,因为redis的key是按插槽结构的,所以无法使数据分片的内存资源达到平衡
- redis堵塞
- cpu压力:对bigkey的数据序列化和反序列化导致CPU的使用飙升,影响redis实体
批处理优化
- 命令的响应时间主要耗费在了网络传输上,redis执行命令的耗时很短,因此在执行命令时,对于长距离,应采用批量执行操作
- 不能再一次批处理中传输太多命令,否则单词命令占用太多带宽,导致网络堵塞
- redis命令中存在批处理命令(一是原生的M操作,一种是Pipeline批处理操作),原生的M操作如下,注意Pipeline的操作不是原子操作。用的时候查询使用

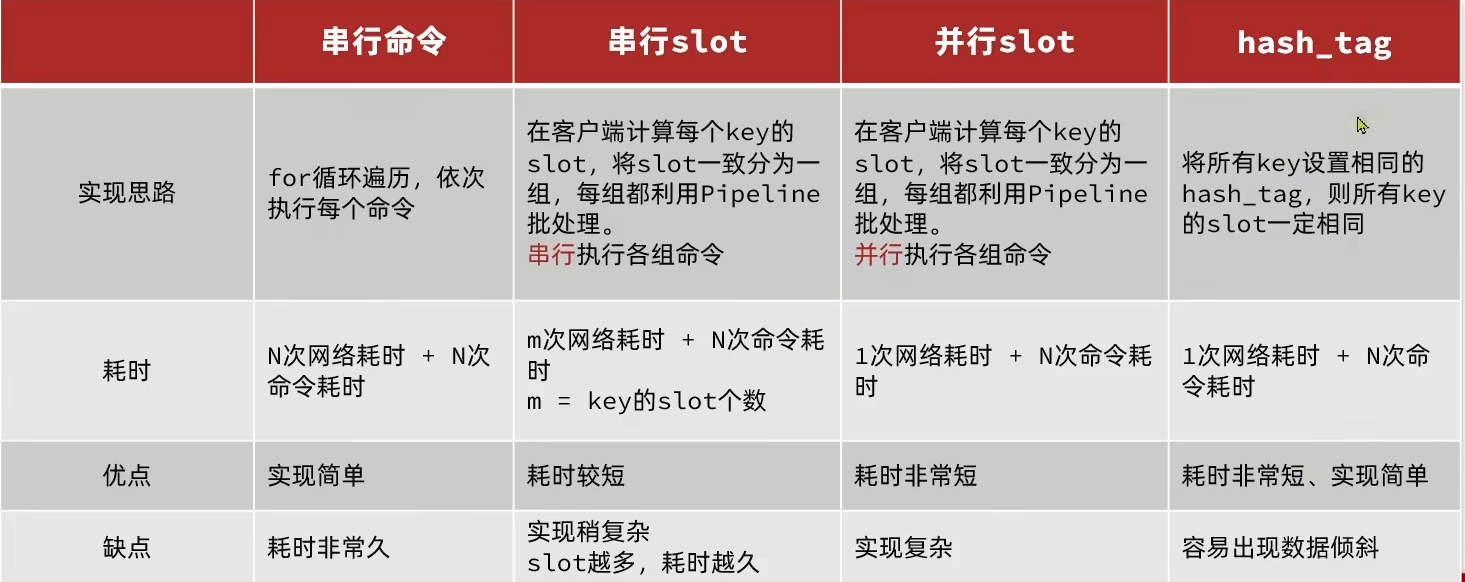
集群下的批处理
- 如果redis是一个集群,批处理命令的多个key必须落在一个插槽中,否则会执行失败
- 实行方案如下
慢查询
- 在redis执行耗时超过了某个阈值的命令,称为慢查询
- 慢查询会导致redis堵塞 ,慢查询的记录会保存在日志中,可在日志中查询慢查询的指令
Mysql基础篇回忆遗忘点
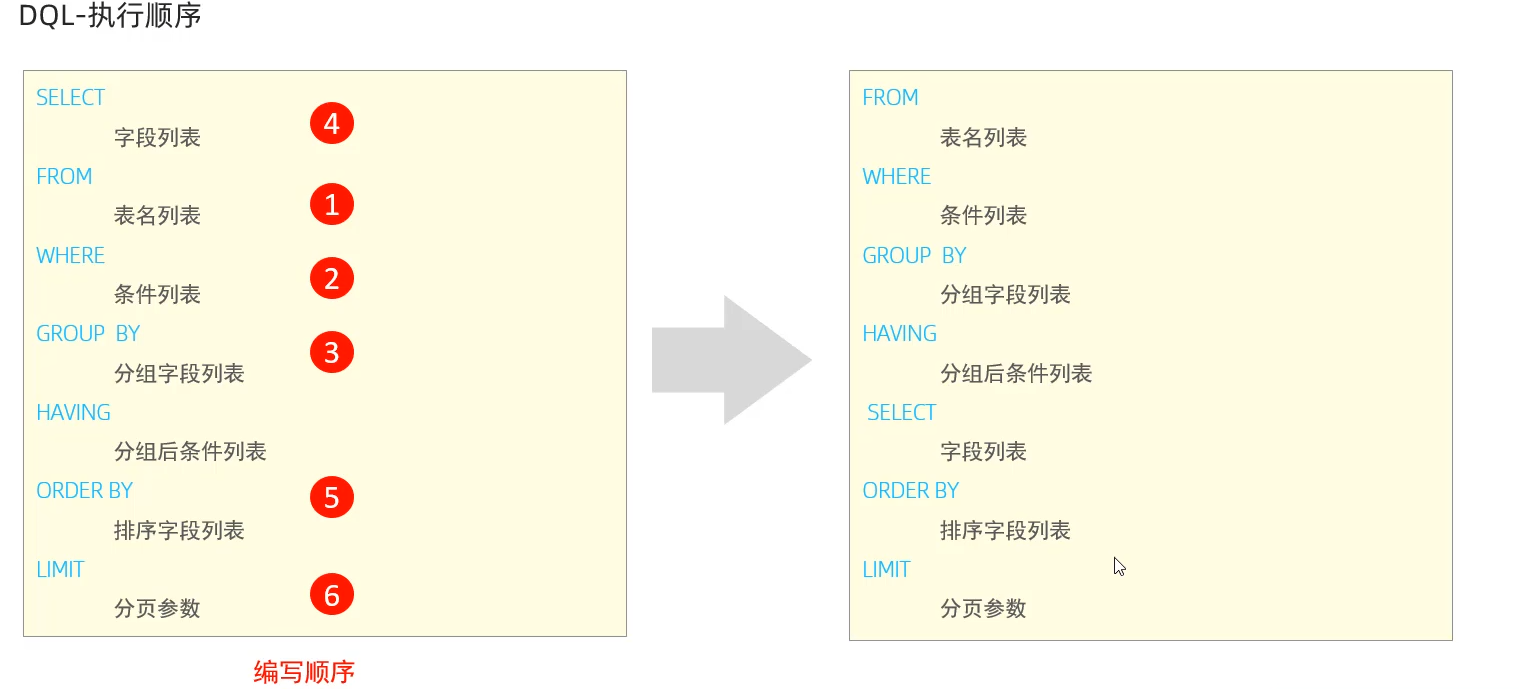
DQL的执行顺序

昨日八股答案
- 什么是java的垃圾回收,如何触发?
GC时管理内存的一种机制,负责释放不在被引用的对象所占用的空间,减少内存泄漏的可能性。
当JVM检测到堆内存不足时,会自动触发垃圾回收;开发者也可以用手动去操作GC,但不能保证立即执行;在启动java应用程序时,可以通过jvm参数来调整GC的行为。
- 判断垃圾的方法有哪些
1.引用计数法
原理:用计数的方法,记录对象被引用的次数。但引用失效时,计数器减少一,直到为0,可以被回收。
缺点:不能解决循环引用的问题。当两个对象相互引用,但不会被其他对象引用。导致这两个对象无法被回收。
2.可达性分析算法
JVM主要采用次算法来判断对象是否为垃圾
原理:类似于树形结构。从垃圾收集的根部出发,向下找他们引用的对象以及对象引用的对象。如果遍历过程中没有访问到对象(即垃圾收集根到该对象不可达),那么就会回收该对象。
- 垃圾回收算法有哪些
- 标记-清除算法:通过可达性分析算法,标记处需要回收的对象,然后统一进行回收。但该方法效率低,清除后会造成大量的碎片空间
- 复制算法:将内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上,然后清除已使用的那块。
- 标记-整理算法:该方法与标记-清除算法异曲同工,但标记之后不会直接清除。而是将所有的存货对象都移动到内存的一段,移动结束后直接清理掉剩余部分。
- 分代回收算法:将内存划分成了新生代和老年代。划分的依据是对象的生存周期(经历过GC的次数)
今日八股
-
GC只会对堆进行GC吗
-
什么情况下使用CMS,什么情况使用G1
-
minorGC、majorGC、fullGC的区别,什么场景触发full GC
总结


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)