Java web应用性能分析之【系统监控工具prometheus】
Prometheus是由SoundCloud开发的开源监控系统的开源版本。2016年,由Google发起的Linux基金会(Cloud Native Computing Foundation,CNCF)将Prometheus纳入其第二大开源项目。Prometheus在开源社区也十分活跃Prometheus由Go语言编写而成,采用Pull方式获取监控信息,并提供了多维度的数据模型和灵活的查询接口。
Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客
Java web应用性能分析之【java进程问题分析概叙】-CSDN博客
Java web应用性能分析之【java进程问题分析工具】-CSDN博客
Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客
Java web应用性能分析之【java进程问题分析定位】-CSDN博客
前面几篇介绍了java进程问题分析定位工具和方法,为了更加贴合实战,这里再来说一下Prometheus+grafana来监控我们的springboot进程。突然发现这样太长了,下一篇再来写Prometheus实战配置。
Prometheus 简介
Prometheus是由SoundCloud开发的开源监控系统的开源版本。2016年,由Google发起的Linux基金会(Cloud Native Computing Foundation,CNCF)将Prometheus纳入其第二大开源项目。Prometheus在开源社区也十分活跃
Prometheus 原理介绍
Prometheus由Go语言编写而成,采用Pull方式获取监控信息,并提供了多维度的数据模型和灵活的查询接口。Prometheus不仅可以通过静态文件配置监控对象,还支持自动发现机制,能通过Kubernetes、Consl、DNS等多种方式动态获取监控对象。在数据采集方面,借助Go语音的高并发特性,单机Prometheus可以采取数百个节点的监控数据;在数据存储方面,随着本地时序数据库的不断优化,单机Prometheus每秒可以采集一千万个指标,如果需要存储大量的历史监控数据,则还支持远程存储。
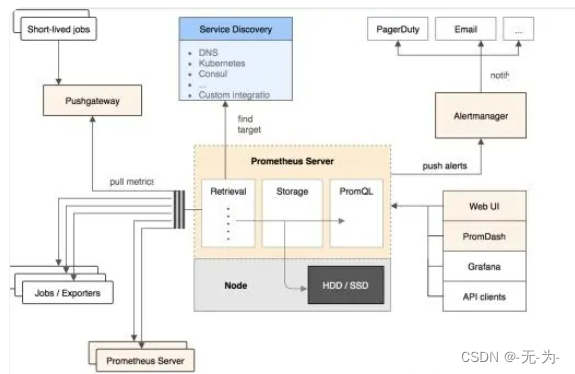
Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并符合Prometheus定义的数据格式,就可以介入Prometheus监控。
Prometheus Server负载定时在目标上抓取metrics(指标)数据,每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为Pull(拉)。Pull方式体现了Prometheus独特的设计哲学与大多数采用Push(推)方式的监控不同
Pull方式的优势是能够自动进行上游监控和水平监控,配置更少,更容易扩展,更灵活,更容易实现高可用。简单来说就是Pull方式可以降低耦合。由于在推送系统中很容易出现因为向监控系统推送数据失败而导致被监控系统瘫痪的问题。所以通过Pull方式,被采集端无需感知监控系统的存在,完全独立于监控系统之外,这样数据的采集完全由监控系统控制
Prometheus支持两种Pull方式采集数据
通过配置文件、文本等进行静态配置支持Zookeeper、Consul、Kubernetes等方式进行动态发现,例如对Kuernetes的动态发现,Prometheus使用Kubernetes的API查询和监控容器信息的变化,动态更新监控对象,这样容器的创建和删除都可以被Prometheus感知Storage通过一定的规则清理和整理数据,并把得到的结果从年初到新的时间序列中,这里存储的方式有两种
1.本地存储。通过Prometheus自带的时序数据库将数据库数据保存在本地磁盘。但是本地存储的容量毕竟有限,建议不要保存超过一个月的数据
2.另一种是远程存储,适用于存储大量监控数据。通过中间层的适配器的转发,目前Prometheus支持OpenTsdb、InfluxDB、Elasticsearch等后端存储,通过适配器实现Prometheus存储的remote write和remote read接口,便可以接入Prometheus作为远程存储使用。
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持多种方式的图标可视化,例如Grafana、自带的PromDash及自身提供的模板引擎等。Prometheus还提供HTTP API查询方法,自定义所需要的输出
Prometheus通过Pull方式拉取数据,但某些现有系统是通过Push方式实现的,为了接入这些系统,Prometheus提供了对PushGateway的支持,这些系统主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据
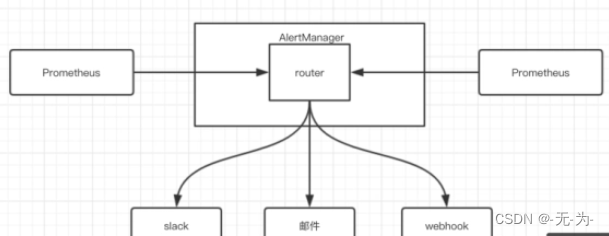
AlertManager是独立于Prometheus的一个组件,在出发了预先设置在Prometheus中的高级规则后,Prometheus便会推送告警信息到AlertManager。AlertManager提供了十分灵活的告警方式,可以通过邮件、slack或者钉钉等途径推送。并且AlertManager支持高可用部署,为了解决多个AlertManager重复告警的问题,引用了Gossip,在多个AlertManager直接通过Gossip同步告警信息
Prometheus 组件
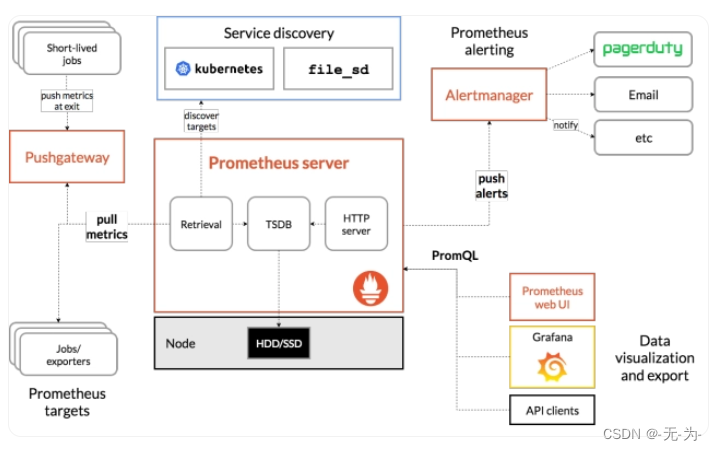
如上图所示Prometheus由多个组件组成,但是其中许多组件是可选的;
- Prometheus Server 用于抓取指标、存储时间序列数据
- exporter 暴露指标让任务抓取
- Pushgateway push的方式将指标数据推送到网关
- alertmanager 处理报警的报警组件
- adhoc 用于数据查询
大多数Prometheus组件都是使用go编写的,因此很容易构建和部署静态的二进制文件
Prometheus特征
Prometheus 相比于其他传统监控工具主要由以下几个特点
- 具有由metric名称和键值对标示的时间序列数据的多位数据模型
- 有一个灵活的查询语言promQL
- 不依赖分布式存储,只和本地磁盘有关
- 通过HTTP的服务拉取时间序列数据
- 也支持推送的方式来添加时间序列数据
- 支持通过服务发现和静态配置发现目标
- 多种图形和仪表盘支持
Prometheus优缺点
1.提供多维度数据模型和灵活的查询方式,通过将监控指标关联多个tag,来将监控数据进行任意维度的组合,并且提供简单的PromQL查询方式,还提供HTTP查询接口,可以很方便地结合Grafana等GUI组件展示数据
2.在不依赖外部存储的情况下,支持服务器节点的本地存储,通过Prometheus自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus可以对接第三方时序数据库和OpenTSDB等。
3.定义了开放指标数据标准,以基于HTTP的Pull方式采集时序数据,只有实现了Prometheus监控数据才可以被Prometheus采集、汇总、并支持Push方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景
4.支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。Prometheus目前已经支持Kubernetes、etcd、Consul等多种服务发现机制
5.易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。
6.支持数据的分区采样和联邦部署,支持大规模集群监控
Prometheus 能做什么
- http平均耗时
- 当前 tomcat 连接数
- tomcat 最大连接数
- jvm相关指标
- http 请求数
- 系统运行时间
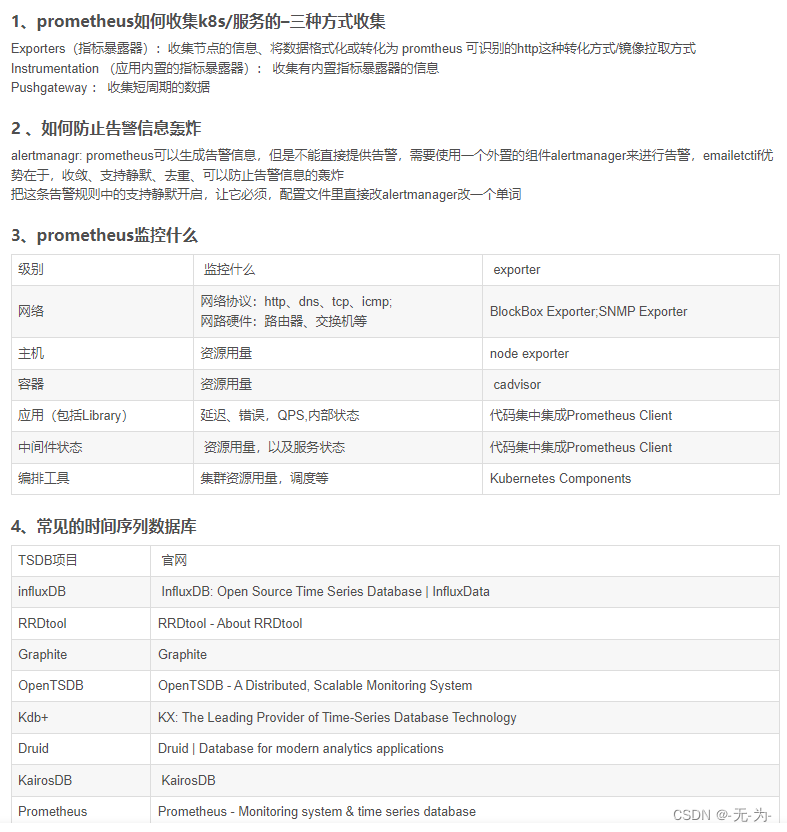
运维监控平台设计思路
① 数据收集模块
② 数据提取模块(prometheus-TSDB,查询语言是promQL)
③ 监控告警模块(布尔值表达式判断是否需要告警,不成立是健康状态)
可以细化为6层
第六层:用户展示管理层 同一用户管理、集中监控、集中维护
第五层:告警事件生成层 实时记录告警事件、形成分析图表(趋势分析、可视化)
第四层:告警规则配置层 告警规则设置、告警伐值设置(定义布尔值表达式,筛选异常状态)
第三层:数据提取层 定时采集数据到监控模块
第二层:数据展示层 数据生成曲线图展示(对时序数据的动态展示)
第一层:数据收集层 多渠道监控数据(网络,硬件,应用,数据,物理环境)
Prometheus监控体系
参考:Promethues (普罗米修斯)详细介绍_prometheus-CSDN博客
1、系统层监控(需要监控的数据)
1.CPU、Load、Memory、swap、disk、I/O、process等
2.网络监控:网络设备、工作负载、网络延迟、丢包率等
2、中间件及基础设施类监控
1.消息中间件:kafka、RocketMQ、等消息代理(redis 中间件)
2.WEB服务容器:tomcat、weblogic、apache、php、spring系列
3.数据库/缓存数据库:Mysql、Postgresql、MongoDB、es、redis
2.1 redis监控内容
① redis的服务状态
② redis所在服务器的系统层监控
③ RDB和AOF日志监控
日志—>如果是哨兵模式—>哨兵共享集群信息,产生的日志—>直接包含的其他节点哨兵信息及mysql信息
3、应用层监控
用于衡量应用程序代码状态和性能
监控的分类:
白盒监控:自省指标,等待被下载(cadvisor)
黑盒监控:基于探针(snmp)的监控方式,不会主动干预、影响数据
4、业务层监控
用于衡量应用程序的价值,如电商业务的销售量,ops、dau日活、转化率等,
业务接口:登入数量,注册数、订单量、搜索量和支付量
prometheus时间序列数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴,服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据
1、数据来源
prometheus基于HTTP call (http/https请求),从配置文件中指定的网络端点(endpoint/IP:端口)上周期性获取指标数据。
很多环境、被监控对象,本身是没有直接响应/处理http请求的功能,prometheus-exporter则可以在被监控端收集所需的数据,收集过来之后,还会做标准化,把这些数据转化为prometheus可识别,可使用的数据(兼容格式)
2、收集数据
监控概念:白盒监控、黑盒监控
白盒监控:自省方式,被监控端内部,可以自己生成指标,只要等待监控系统来采集时提供出去即可
黑盒监控:对于被监控系统没有侵入性,对其没有直接"影响",这种类似于基于探针机制进行监控(snmp协议)
Prometheus支持通过三种类型的途径从目标上"抓取(Scrape)"指标数据(基于白盒监控);
Exporters ——>工作在被监控端,周期性的抓取数据并转换为pro兼容格式等待prometheus来收集,自己并不推送
Instrumentation ——>指被监控对象内部自身有数据收集、监控的功能,只需要prometheus直接去获取
Pushgateway ——>短周期5s—10s的数据收集
3、prometheus(获取方式)
Prometheus同其它TSDB相比有一个非常典型的特性:它主动从各Target上拉取(pull)数据,而非等待被监控端的推送(push)
两个获取方式各有优劣,其中,Pull模型的优势在于:
集中控制:有利于将配置集在Prometheus server上完成,包括指标及采取速率等;
Prometheus的根本目标在于收集在rarget上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统
通过targets(标识的是具体的被监控端)
比如配置文件中的 targets:[‘localhost:9090’]
prometheus生态组件
1、Prometheus Server
收集和储存时间序列数据
Prometheus server:服务核心组件,采用pull方式收集监控数据,通过http协议传输。并存储时间序列数据。Prometheus server 由三个部分组成:Retrival,Storage,PromQL
Retrieval:负责在活跃的target 主机上抓取监控指标数据。
Storage:存储,主要是把采集到的数据存储到磁盘中。默认为15天(可修改)。
PromQL:是Prometheus提供的查询语言模块。
2、Client Library
client Library:客户端库,目的在于为那些期望原生提供 Instrumentation 功能的应用程序提供便捷的开发途径,用于基于应用程序内建的测量系统。
3、Push Gateway
Pushgateway:类似一个中转站,Prometheus的server端只会使用pull方式拉取数据,但是某些节点因为某些原因只能使用push方式推送数据,那么它就是用来接收push而来的数据并暴露给Prometheus的server拉取的中转站。可以理解成目标主机可以上报短期任务的数据到Pushgateway,然后Prometheus server 统一从Pushgateway拉取数据。
4、Exporters
用于暴露现有应用程序或服务(不支持Instrumentation)的指标给Prometheus Server
而pro内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus 采集过后,会存储在自己内建的TSDB数据库中,提供了promQL 支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具(grafana)来展示数据
采集、抓取数据是其自身的功能,但一般被抓去的数据一般来自于:
export/instrumentation (指标数据暴露器) 来完成的,或者是应用程序自身内建的测量系统(汽车仪表盘之类的,测量、展示)来完成
5、Alertmanager
Alertmanager:是一个独立的告警模块,从Prometheus server端接收到“告警通知”后,会进行去重、分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件、钉钉、企业微信等。
1.Prometheus Server 仅负责生成告警指示,具体的告警行为由另一个独立的应用程序AlertManager负责;
2.告警指示由 Prometheus Server基于用户提供的告警规则周期性计算生成,Alertmanager 接收到Prometheus Server发来的告警指示后,基于用户定义的告警路由向告警接收人发送告警信息。
6、Service Discovery
Service Discovery:服务发现,用于动态发现待监控的Target,Prometheus支持多种服务发现机制:文件、DNS、Consul、Kubernetes等等。
服务发现可通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮询这些Target 获取监控数据。该组件目前由Prometheus Server内建支持
7、grafana
Grafana:是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
Prometheus 数据流向
① Prometheus server 定期从配置好的 jobs 或者 exporters 中拉取 metrics,或者接收来自 Pushgateway 发送过来的metrics,或者从其它的Prometheus server中拉取 metrics。
② Prometheus server在本地存储收集到的 metrics,并运行定义好的 alerts.rules,记录新 的时间序列或者向Alert manager推送警报。
③ Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
④ 在图形界面中,可视化采集数据。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)