BM25算法与TF-IDF
BM25和tf-idf算法
BM25是信息索引领域,计算query与文档相似度得分的经典算法。
BM25算法通常用来做搜索相关性评分的,也是ES中的搜索算法,
通常用来计算query和文本集合D中每篇文本之间的相关性。
有下面三个公式组成:
- query中每个单词 t 与文档 d 间的相关性
- 单词 t 与 query 间的相似性
- 每个单词的权重
BM25 中计算Q,d 间的分数: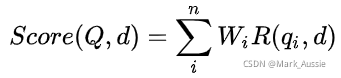
Q为序列,qi为Q中的单词,d为某文档;Wi为单词权重,计算公式如下:
不同于TF-IDF中的 IDF公式:![]()
N 为全部文档数目,dfi 为 含有词 qi 的文档数,dfi 越大 qi 重要性越低,词 qi与文档相似性。
BM25的设计依据:词频和相关性之间的关系是非线性的,当词出现的次数达到一个阈值后,词的影响就不再线性增加了,而阈值跟文档有关;在描述单词与文档相似性时,BM25使用如下公式:
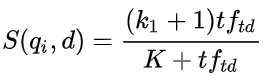
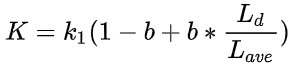
tf(td):单词 t 在文档 d 中的词频;Ld:文档 d 长度;Lave:全部文档平均长度;k1:正参数,标准化文章词频范围,k1=0时为二元模型,没有词频,更大的值对应使用更原始的词频信息。b 是一个可调参数(0<b<1),决定使用文档长度来表示信息量的范围:当b=1,是完全使用文档长度来权衡词的权重,当b=0表示不使用文档长度。
当query很长时,需要计算单词与query的之间的权重。对于短的query则不必。
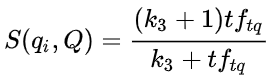 tf(tq):单词 t 在 query 中的词频;k3:正参数,矫正query词频范围
tf(tq):单词 t 在 query 中的词频;k3:正参数,矫正query词频范围
BM25最终的公式:
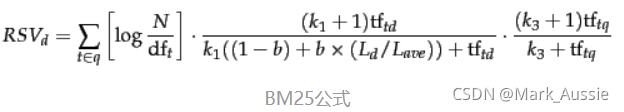
经试验一般三个可调参数 k1, k3可取1.2~2,b可取0.75
TF−IDF = TF∗IDF
TF 计算在一篇文档中词出现的频率,而IDF可降低通用词的作用。对一篇文档可用文档中每个词的TF−IDF组成的向量来表示该文档,再根据余弦相似度等方法来计算文档间相关性。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)