HDFS高可用架构
NameNode负责响应客户端的请求,负责管理整个文件系统的元数据HDFS的读、写操作都必须向NameNode申请,元数据非常关键负责维持文件副本的数据是为了帮助NameNode合并编辑日志,减少NameNode启动时间。另外NamNode的元数据丢失可以通过恢复。DataNode负责存放被切割后的文件块,文件在DataNode中存储单位是块(Block)如果集群是完全分布式的,那么一个文件的每一
1 HDFS高可用架构原理
1.1 HDFS的基本架构
- NameNode
负责响应客户端的请求,负责管理整个文件系统的元数据HDFS的读、写操作都必须向NameNode申请,元数据非常关键负责维持文件副本的数据
- SecondNameNode
是为了帮助NameNode合并编辑日志,减少NameNode启动时间。另外NamNode的元数据丢失可以通过SecondNameNode恢复。
- DataNode
负责存放被切割后的文件块,文件在DataNode中存储单位是块(Block)如果集群是完全分布式的,那么一个文件的每一块都必须有多个副本,存放在不同的DataNode上DataNode通过心跳信息定期向NameNode汇报自身保存的文件块信息。
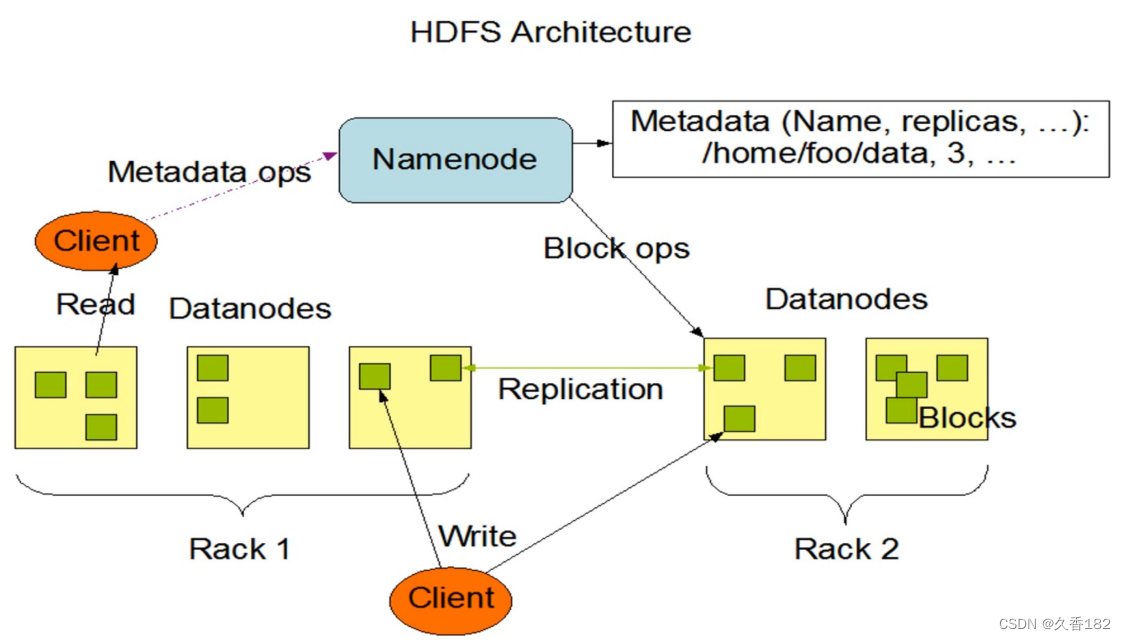
完全分布式模式和伪分布式模式下 HDFS 集群包括两种类型的节点,即 NameNode和DataNode,其中 DataNode 有多个,并且相互之间会做数据的冗余和备份,所以某个DataNode宕机不会对整个集群的使用造成影响。而 NameNode 在集群中是单一节点,一旦 NameNode 出现问题,比如宕机,将使得整个集群不可访问,这样就会导致整个 HDFS集群不能做到高可用
1.2 HDFS高可用架构
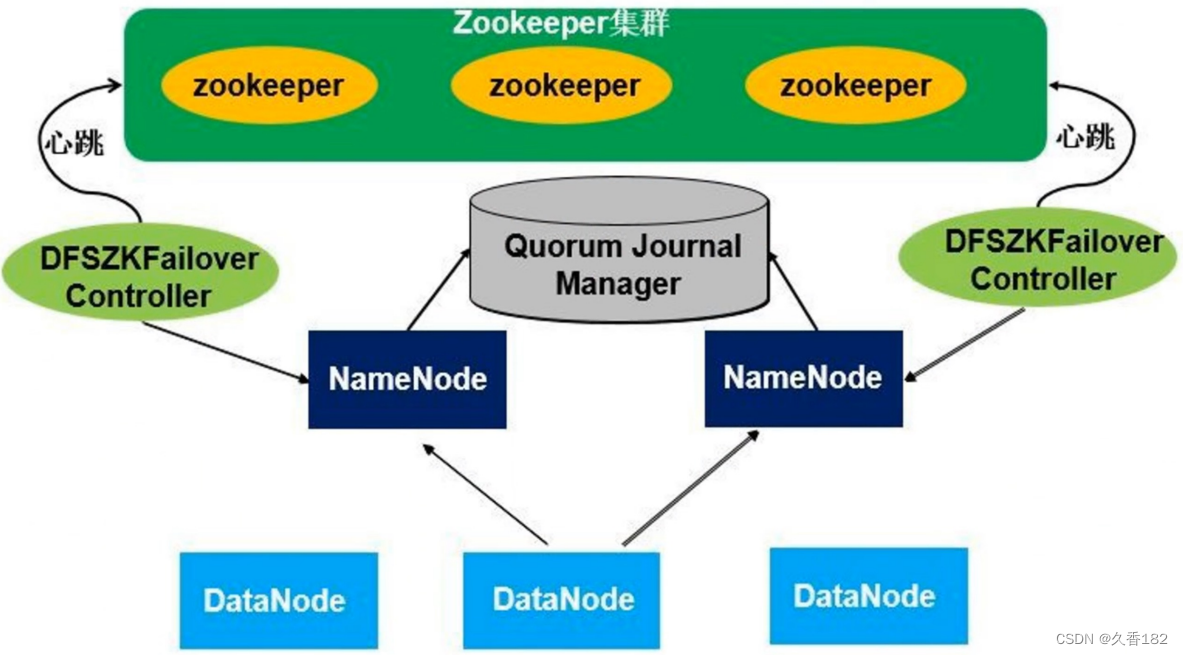
为了解决高可用的问题,在Hadoop2.0版本上引入了高可用架构的搭建。高可用架构集群相对比较复杂,除 NameNode 和 DataNode 外,还有 ZooKeeper集群、Quorum Journal Manager 和 DFSZKFailover Controller。
- 原本SecondaryNameNode功能是做检查点,把NameNode上的fsimage和edit log文件定期进行合并,并且能有元数据信息合并的作用,但是没办法解决自动故障转移,在高可用架构里面就不需要配置SecondaryNameNode。
-
在高可用架构里面有两个NameNode,这两个NameNode地位平等,其中一个是主NameNode,是Active状态,另外一个NameNode是从,Standby状态。两个NameNode同时启动,只有一个 NameNode会进入工作状态。在任何时间点,其中之一NameNode是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode尽可能用来保存好足够多的状态,以提供快速的故障恢复能力。
-
所有的DataNode节点会把自己的数据块信息同时向两个NameNode汇报。
-
DFSZKFailover Controller(ZKFC):实时NameNode的监控节点,ZKFC有两个,一个ZKFC会监控一个特定的NameNode节点,把节点运行情况向ZooKeeper集群汇报。一旦Active NameNode发生故障,ZKFC可以监控到故障,并把情况报告给ZooKeeper集群,然后通过ZooKeeper的一些处理机制进行重新选举,把Standby NameNode切换进入工作状态。
-
Standby NameNode切换进入工作状态后,通过共享存储能立刻获取到当前集群的元数据信息,并且它自身原本一直保存和DataNode数据块信息,就可以立马接管整个集群的NameNode工作。
-
Quorum Journal Manager:共享存储,用于保存元数据信息,是多台机器组成的共享存储集群,集群中的每台机器称为Journal Node(JN)。原本元数据信息是存储在NameNode硬盘,现在元数据信息存储在集群中的共享存储里面,这样可以保证元数据信息得到可靠的存储。
- 健康监控:一个NameNode一个监控进程。周期性的向NameNode发信息鉴定NameNode是否在正常工作。如果机器宕机,心跳失败,那么zkfc就会标记它处于不健康的状态。
- 会话管理:如果namenode是健康的,zkfc机会保持在zookeeper中保持一个打开的会话,如果namenode是active状态的,那么zkfc还会在zookeeper中创建有一个类型为临时类型的 znode,当这个namenode挂掉时,这个znode将会被删除,然后备用的namenode得到这把锁,升级为主的namenode,同时标记状态为active,当宕机的namenode,重新启动,他会再次注zookeeper,发现已经有znode了,就自动变为standby状态。
- master选举:通过在zookeeper中维持一个临时类型的znode,使用独占锁机制,从而判断哪个namenode为active状态
2 HDFS高可用架构配置思路
- 完全分布式集群搭建
- ZooKeeper集群搭建
- 高可用相关节点配置
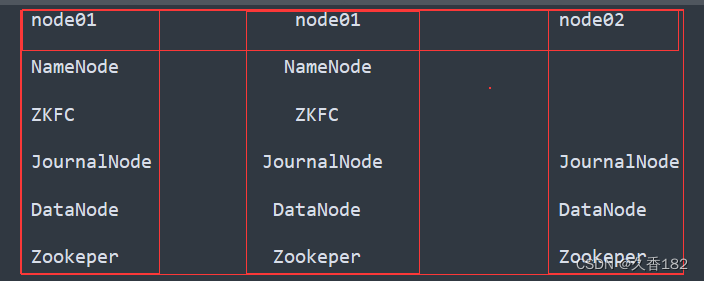
- NameNode配置两个,节点在node00和node01上配置
- ZKFC监控NameNode,一个NameNode对应一个ZKFC,配置在相同机器上
- 共享存储三台机器都要配置
- ZK和DN仍然配置在三台机器上
3 高可用配置工作
3.1 准备工作
3.1.1 环境准备工作
- 三台虚拟机
- HDFS完全分布式搭建
- ZK集群搭建
3.1.2 停止Hadoop集群
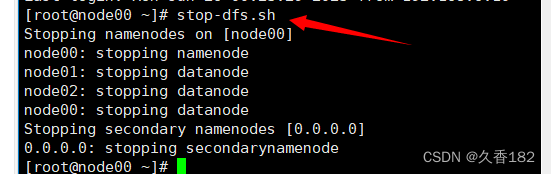
停掉Hadoop集群,在node01上执行stop-dfs命令把hadoop集群停止
- stop-yarn.sh
- stop-dfs.sh
3.1.3 停止ZK集群
cd /opt/apache-zookeeper-3.6.2-bin/bin/
./zkServer.sh stop
3.14 创建目录
- cd/opt/software/hadoop/hdfs/
- mkdir journalnode
- cd journalnode/
- mkdir data

3.1.5 删除之前系统产生的数据文件
- 删除/opt/software/hadoop/hdfs/name目录下的数据
- cd /opt/software/hadoop/hdfs/name/
- rm -rf *
- 注意:rm -rf 在工作的时候别用别用别用

- 删除/opt/software/hadoop/hdfs/tmp目录下的数据

- 删除/opt/software/hadoop/hdfs/data目录下的数据

3.1.6 安装psmisc
- 三台机器安装psmisc,程序切换需用到shell命令。
yum install psmisc
psmisc是一个Linux系统工具包,包含了一些管理进程的命令,比如killall、fuser和pstree等。
其中,killall命令可以通过进程名杀死所有同名进程;fuser命令可以查找使用指定文件的进程;pstree命令可以以树状图的形式展示进程之间的关系。
除此之外,psmisc还提供了其他一些有用的命令,比如killall5、fusermount和peekfd等,可以帮助用户更方便地管理和调试进程。
3.2 整体配置工作
- core-site.xml 实现一些与 Hadoop 相关的核心配置
- hdfs-site.xml HDFS 相关的配置
3.3 core-site.xml
- fs.defaultFS配置需要修改为集群标识mycluster,集群标识在hdfs-site.xml内定义
- hadoop.tmp.dir配置不变化
- hadoop.http.staticuser.user配置新增
- ha.zookeeper.quorum配置新增,指向ZK集群地址
<!-- 默认的文件系统HDFS,NameNode主机通讯地址,配置集群标识定义在hdfs-site.xml里面 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- hadoop临时文件存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.9.2/tmp</value>
</property>
<!-- 网页方式进入管理页面,页面显示此用户相关数据 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 高可用集群指定的zk服务器信息 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node00:2181,node01:2181,node02:2181</value>
</property>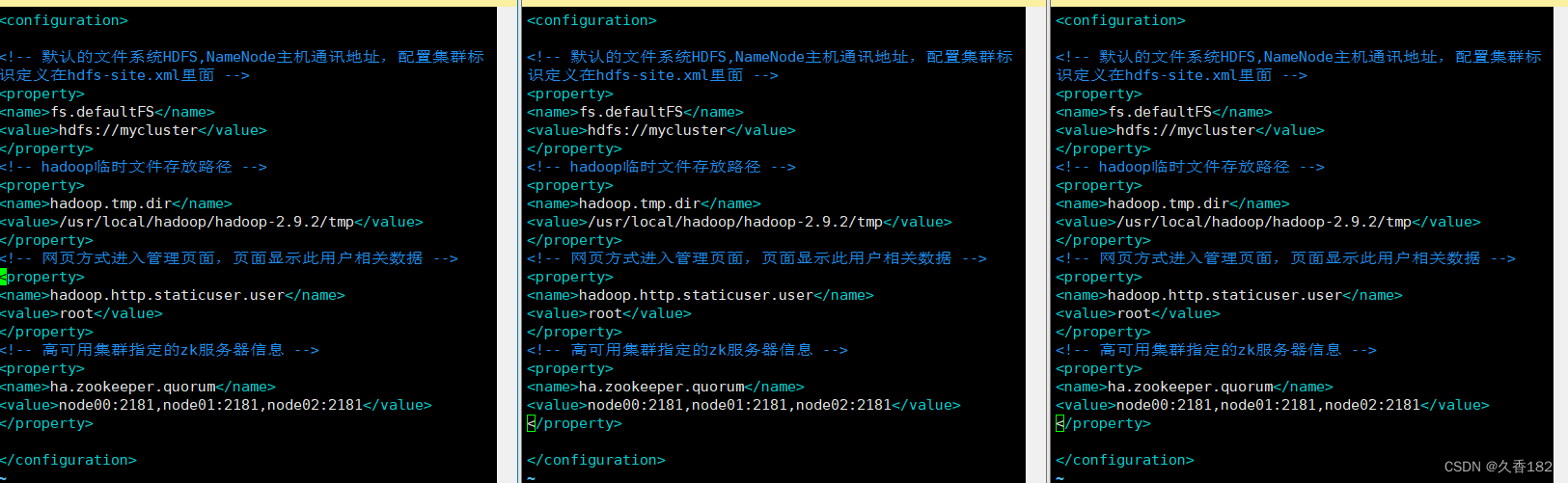
- fs.defaultFS原本是指向node00,高可用架构里面NameNode会发生变化,所以此配置需修改成一 个标识
<!-- 高可用架构下集群使用NameNode,配置集群标识, mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- NameNode节点标识 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode1的rpc通讯端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node00:8020</value>
</property>
<!-- NameNode2的rpc通讯端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node01:8020</value>
</property>
<!-- NameNode1的http通讯端口号 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node00:50070</value>
</property>
<!-- NameNode2的http通讯端口号 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node01:50070</value>
</property>
<!-- 配置共享存储 JN -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node00:8485;node01:8485;node02:8485/mycluster</value>
</property>
<!-- 配置失败转移执行类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!-- 当进行切换时,通过何种机制杀死原先 active 的 namenode -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- SSH 私钥,上面杀掉原先进程使用sshfence方式需使用私钥 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- JN 存放元数据的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/software/hadoop/hdfs/journalnode/data</value>
</property>
<!-- 当NameNode宕机,切换方式设置为自动 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>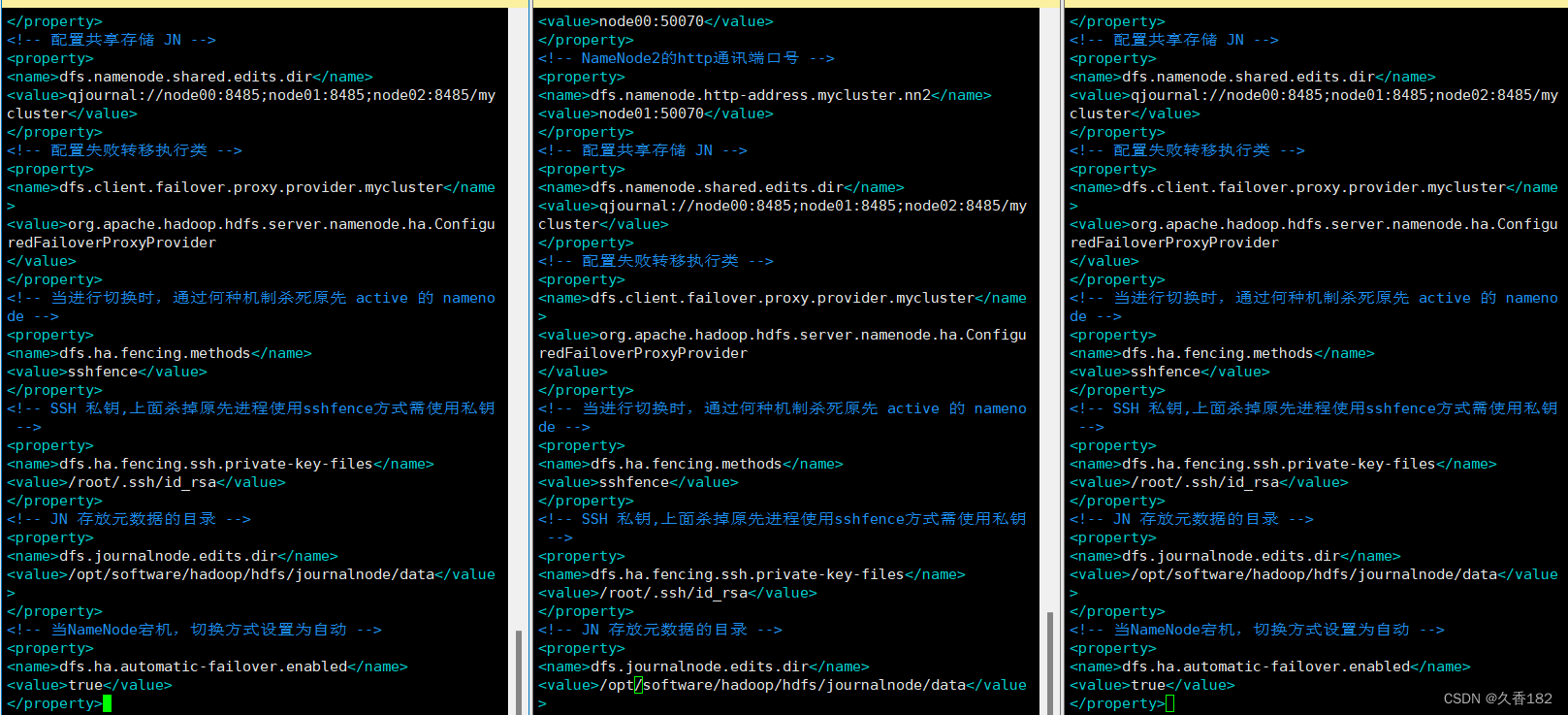
如果上面的步骤你只是在一台虚拟机上配置,可以看下面的第四章同步到node01,node02
4 同步配置
4.1 删除node01、node02的配置
- 在node01和node02上分别执行删除hadoop目录操作
- cd /opt/software/
- rm -rf hadoop
4.2 同步配置
scp -r hadoop node01:$PWD
scp -r hadoop node02:$PWD
5 高可用集群启动
5.1 启动ZK集群
- 三台机器执行以下命令启动ZK集群
- 三台机器分别启动完成后再确认三台机器ZK集群的启动情况。zkServer.sh status 和jps
zKserver.sh start

hadoop-daemon.sh start journalnode

hdfs namenode -format
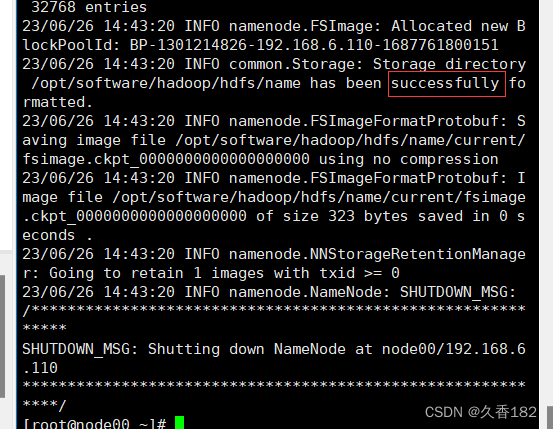
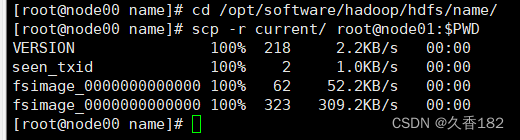
cd /opt/software/hadoop/hdfs/name/scp -r current/ root@node02:$PWD
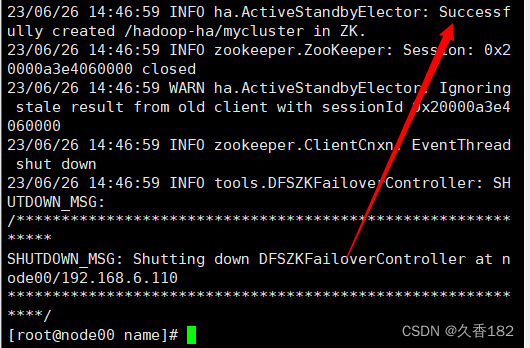
hdfs zkfc -formatZK
start-dfs.sh
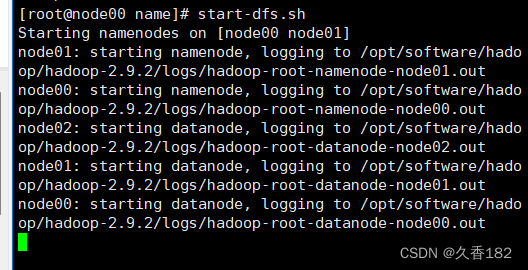
node00和node01上进程都是5个。没有SNN,多了JournalNode、DFSZKFailoverController、QuorumPeerMain。node02上比原来多了JournalNode、QuorumPeerMain

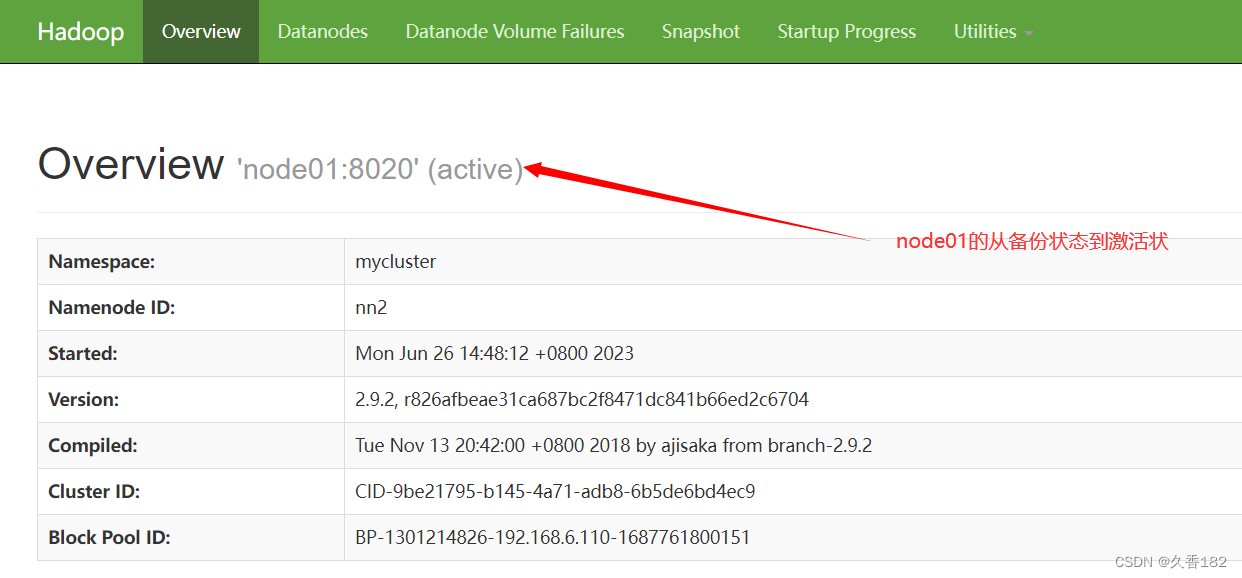
6.2 管理台查看


打开 Web 管理页面,可查看两个 NameNode 节点和 3 个 datanode 节点的状态,看看它们是否可以正常工作。其中有一个节点是active状态,一个节点是standby状态。
jps #查看namenode进程的pid,假设为xxxx
kill -9 xxxx #杀掉namenode进程
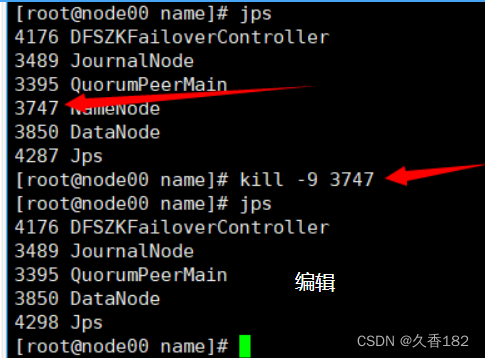
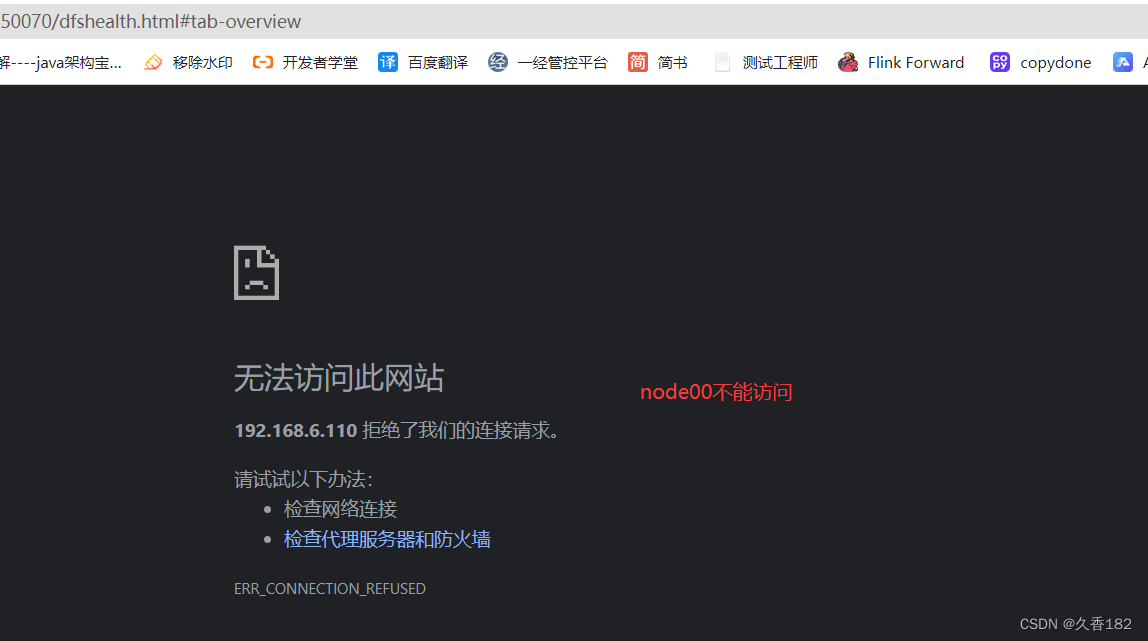
http://node00:50070/地址已经不能访问此时http://node02:50070/上namenode由原本的standby状态变为active状态

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)