【网络爬虫】Scrapy简要介绍及步骤示例
文章内容包括Scrapy的简要介绍、Scrapy在Window上的两种安装方法和一个阐述Scrapy使用步骤的简单示例。(仅用来记录网课笔记)
·
2.3 Scrapy简要介绍及步骤示例
2.3.1 Scrapy介绍
scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建 request请求,还有强大的selector 能够方便地解析response响应。
1. scrapy工作过程
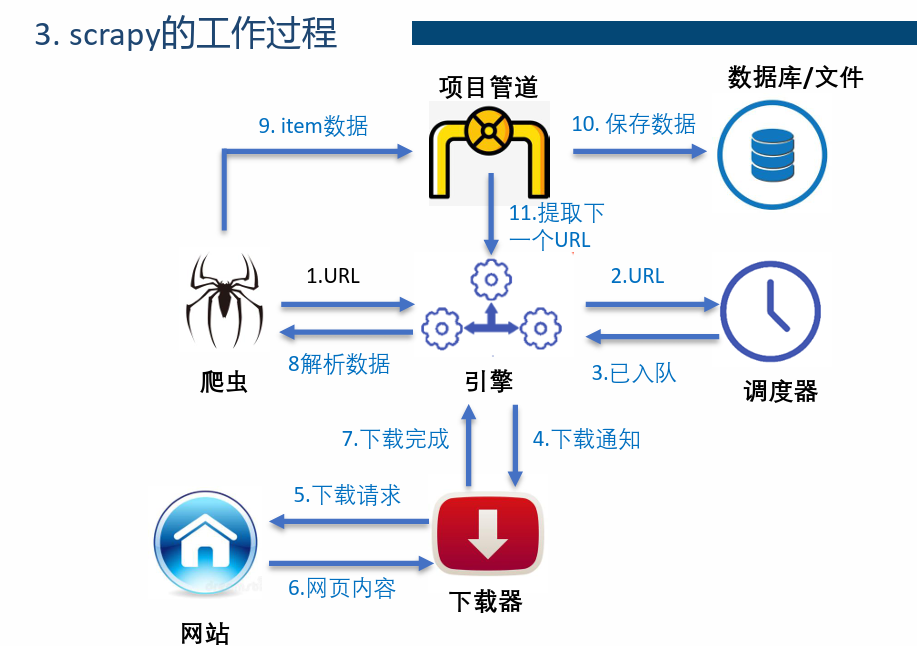
2. scrapy主要模块
| 模块 | 说明 |
|---|---|
| Scrapy Engine引擎 | 整个框架的核心,负责控制数据流在系统中的各个组件之间的传 送,并在相应动作发生时触发事件 |
| Scheduler调度器 | 接受引擎发过来的请求,并将其加入url队列当中,并默认完成去掉重复的url的工作 |
| Downloader 下载器 | 负责下载Engine 发送的所有Requests 请求,并将其获取到的 responses 回传给Scrapy Engine |
| Spider爬虫 | 负责解析response,从中提取数据赋给Item的各个字段。并将需要 继续进一步处理的url提交给引擎,再次进入Scheduler(调度器) |
| Item Pipeline 项目管道 | 处理Spider中获取到的Item,并进行后期的处理。例如清理 HTML 数据、验证爬取的数据(检查item 包含某些字段)、查重 (并丢弃)、爬取数据的持久化(写入文件或者存入数据库等) |
| Downloader Middlewares 下载中间件 | 是Engine 和Downloader 的枢纽。负责处理Downloader 传递给 Engine 的responses;它还支持自定义扩展。 |
| Spider Middlewares爬虫中间件 | 可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进 入Spider的Responses;和从Spider出去的Requests)负责下载Engine 发送的所有Requests 请求,并将其获取到的responses 回传给 ScrapyEngine |
2.3.2 scrapy的安装
scrapy依赖的模块较多,例如wheel、lxml、Twisted、 pywin32等,可以使用pip工具依次安装,但这样比较麻烦,推荐使用 pycharm来安装更加简单方便。
1. 使用 pycharm来安装
- 安装pycharm
- 新建一个工程(例如项目名称为myscrapy)–学堂云网课项目存放路径D:\Study\Python\xuetangyun-python\project
- 打开菜单File->Setting->Project: spider>Project Interpreter,找到右上角的加号符号,选择添加scrapy
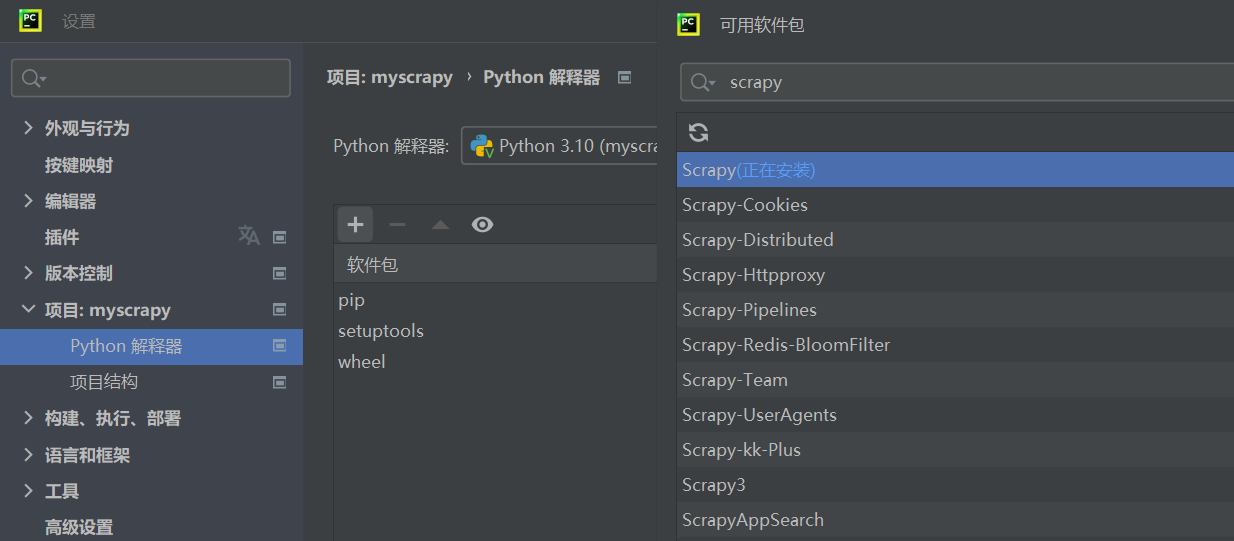
- 安装过程中可能会出现提示,提示缺少 Microsoft Visual C++ 14.0。这时可以使用以下网址安装: http://go.microsoft.com/fwlink/?LinkId=691126
2. 使用pip工具安装
- 在需要安装的路径打开终端

- 在终端输入
pip install scrapy,回车
这里显示的是在anaconda3中已经安装成功了。
- 在终端输入
scrapy startproject 项目名,回车,创建项目
出现如下提示显示已经创建项目成功。
2.3.3 使用Scrapy步骤
1. 创建一个爬虫项目
- 创建一个Scrapy项目(课堂上的方法,在安装scrapy的目录下创建Scrapy项目)
- 找到安装scrapy的目录,打开cmd命令行
- cd命令转到该目录下的venv\scripts\
- 键入命令:scrapy startproject test1

- 使用pycharm打开工程test1
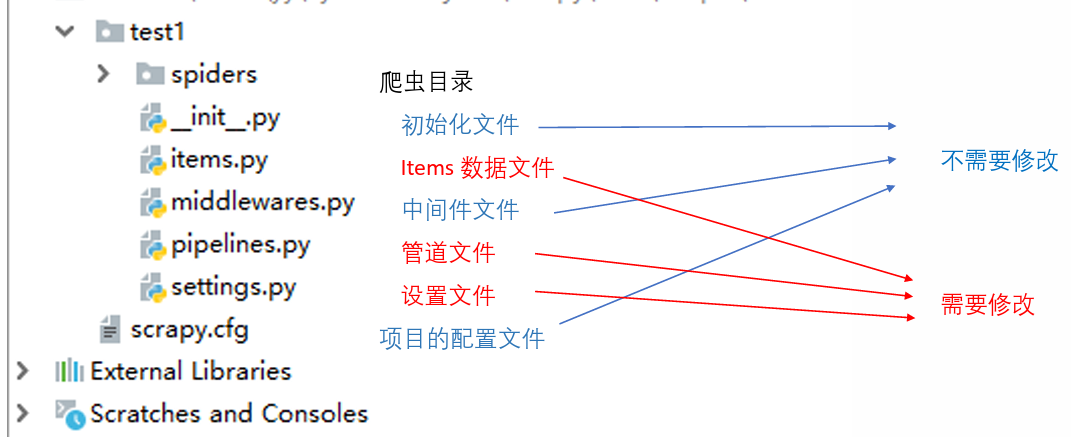
- 新建一个begin.py文件,和scrapy.cfg 在同一级目录下
from scrapy import cmdline
cmdline.execute("scrapy crawl bupt".split())
#bupt为爬虫的名字,在spider.py中定义
2. 确定需要抓取的目标(编写items.py)
- 修改items.py文件
import scrapy
class MyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
school = scrapy.Field()
link = scrapy.Field()
3. 制作爬虫(spiders/xxspiders.py)
在spiders目录下新建一个spider.py文件
import scrapy
from test1.items import MyItem# 从items.py中引入MyItem对象
class mySpider(scrapy.spiders.Spider):
name = "bupt" # 爬虫的名字是bupt
allowed_domains= ["bupt.edu.cn/"] # 允许爬取的网站域名
start_urls= ["https://www.bupt.edu.cn/yxjg1.htm"] # 初始URL,即爬虫爬取的第一个URL
静态网页数据抓取
- xpath路径确定
- spiders.py中添加以下代码
import scrapy
from test1.items import MyItem # 从items.py中引入MyItem对象
class mySpider(scrapy.spiders.Spider):
name = "bupt" # 爬虫的名字是bupt
allowed_domains= ["bupt.edu.cn/"] # 允许爬取的网站域名
start_urls= ["https://www.bupt.edu.cn/yxjg1.htm"] # 初始URL,即爬虫爬取的第一个URL
def parse(self,response): # 解析爬取的内容
item = MyItem() # 生成一个在items.py中定义好的Myitem对象,用于接收爬取的数据
# 重点是搞懂这个XPath路径
for each in response.xpath("/html/body/div/div[2]/div[2]/div/ul/li[4]/div/ul/*"):
# 用xpath来解析html,div标签中的数据,就是我们需要的数据。
item['school'] = each.xpath("a/text()").extract() # 学院名称在text中
item['link'] = each.xpath("a/@href").extract() # 学院链接在href中
if (item['school'] and item['link']): # 去掉值为空的数据,只有当两个数值均不为空的时候才返回
yield (item) # 返回item数据给到pipelines模块
4. 存储内容(pipelines.py):设计管道存储爬取内容
修改pipelines.py
import json
class MyPipeline(object):
def open_spider(self, spider):
try: # 打开json文件
self.file = open('MyData.json', "w", encoding="utf-8")
except Exception as err:
print(err)
def process_item(self, item, spider):
dict_item = dict(item) # 生成字典对象
json_str = json.dumps(dict_item, ensure_ascii=False) + "\n" # 生成json串
self.file.write(json_str) # 将json串写入到文件中
return item
def close_spider(self, spider):
self.file.close() # 关闭文件
修改setting.py
- 参数是分配给每个类的整型值,确定了它们运行的顺序,item按数字从低到高的顺序。
- 通过pipeline。通常将这些数字定义在0-1000范围内。
ITEM_PIPELINES = {'test1.pipelines.MyPipeline': 300,}
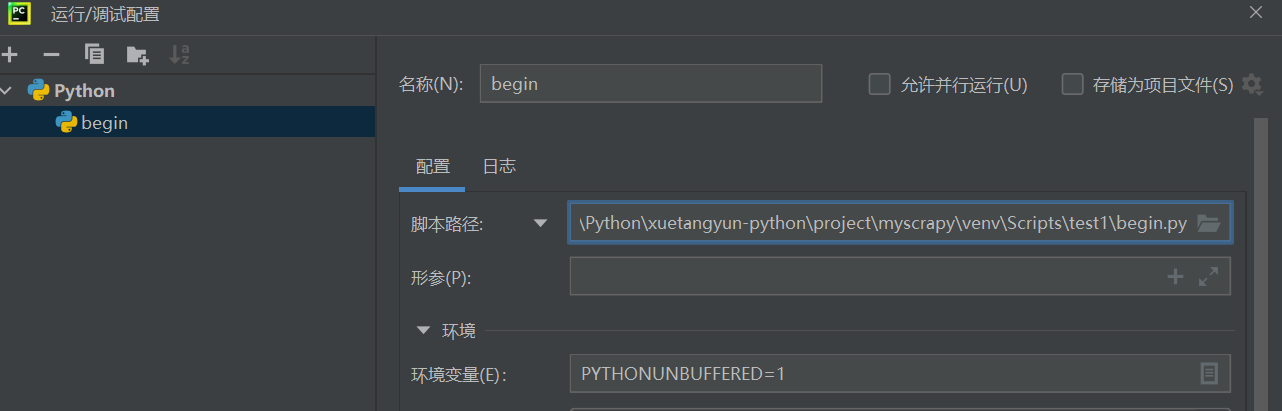
运行spider.py,并将其运行时的Script path配置项修改为begin.py
5. 爬取结果(MyData.json)


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)