Python基础爬虫爬取网站内容转化为pdf
首先需要下载一些必要的pip库
pip install requests
pip install beautifulsoup4
pip install pdfkit下载wkhtmltopdf,这个工具作用就是将HTML转化为pdf的核心软件
下载链接:链接
下载位置最好固定在一个没有中文的位置,这样可以省去许多麻烦。 我的位置如下
程序源代码如下(GUI)
#htmltopdf.py
import tkinter as tk
from tkinter import messagebox, filedialog
import requests
from bs4 import BeautifulSoup
import pdfkit
import os
current_dir = os.path.dirname(os.path.abspath(__file__))
path_wkhtmltopdf = os.path.join(current_dir, 'datas', 'bin', 'wkhtmltopdf.exe')
# 检查路径是否存在,这里主要是为相对路经,到时候好直接打包程序
if not os.path.exists(path_wkhtmltopdf):
raise FileNotFoundError(f"Cannot find wkhtmltopdf executable at: {path_wkhtmltopdf}")
# 创建 pdfkit 配置
config = pdfkit.configuration(wkhtmltopdf=path_wkhtmltopdf)
# 定义检查网站可访问性的函数
def check_url():
url = url_entry.get()
try:
response = requests.get(url)
if response.status_code == 200:
messagebox.showinfo("成功", "网站可访问!")
else:
messagebox.showerror("错误", "网站不可访问,状态码:" + str(response.status_code))
except Exception as e:
messagebox.showerror("错误", f"无法访问该网站,错误信息:{e}")
# 定义检查网站编码的函数
def get_encoding():
url = url_entry.get()
try:
response = requests.get(url)
encoding = response.apparent_encoding # 自动检测网页编码
encoding_entry.delete(0, tk.END)
encoding_entry.insert(0, encoding)
messagebox.showinfo("成功", f"检测到网站编码为:{encoding}")
except Exception as e:
messagebox.showerror("错误", f"无法获取编码,错误信息:{e}")
# 定义转换为 PDF 的函数
def generate_pdf():
url = url_entry.get()
div_query = div_entry.get()
output_encoding = pdf_encoding_entry.get()
# wkhtmltopdf 配置路径
current_dir = os.path.dirname(os.path.abspath(__file__))
path_wkhtmltopdf = os.path.join(current_dir, 'datas', 'bin', 'wkhtmltopdf.exe')
# 检查路径是否存在,这里主要是为相对路经,到时候好直接打包程序
config = pdfkit.configuration(wkhtmltopdf=path_wkhtmltopdf)
# 爬取网页内容
try:
response = requests.get(url)
response.encoding = encoding_entry.get() # 使用用户输入的编码
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
div_content = soup.find(**eval(div_query)) # 使用 eval 将输入的字典转为 Python 表达式
if div_content is None:
messagebox.showerror("错误", "未找到目标 div 内容")
return
html_str = str(div_content)
# 选择保存位置和文件名
file_path = filedialog.asksaveasfilename(defaultextension=".pdf", filetypes=[("PDF files", "*.pdf")],initialfile="htmlto.pdf")
if not file_path:
return
# 生成 PDF
options = {
'encoding': output_encoding,
'enable-local-file-access': None
}
pdfkit.from_string(html_str, file_path, configuration=config, options=options)
messagebox.showinfo("成功", f"PDF 文件成功保存到:{file_path}")
except Exception as e:
messagebox.showerror("错误", f"生成 PDF 失败,错误信息:{e}")
# 创建主窗口
root = tk.Tk()
root.title("网页转PDF工具")
# 第一行:输入网址
tk.Label(root, text="输入网址:").grid(row=0, column=0, padx=10, pady=5)
url_entry = tk.Entry(root, width=50)
url_entry.grid(row=0, column=1, padx=10, pady=5)
tk.Button(root, text="检查网址", command=check_url).grid(row=0, column=2, padx=10, pady=5)
# 第二行:编码检测
tk.Label(root, text="网页编码:").grid(row=1, column=0, padx=10, pady=5)
encoding_entry = tk.Entry(root, width=50)
encoding_entry.grid(row=1, column=1, padx=10, pady=5)
tk.Button(root, text="检测编码", command=get_encoding).grid(row=1, column=2, padx=10, pady=5)
# 第三行:输入要爬取的div
tk.Label(root, text="输入div选择器:").grid(row=2, column=0, padx=10, pady=5)
div_entry = tk.Entry(root, width=50)
div_entry.grid(row=2, column=1, padx=10, pady=5)
tk.Label(root, text="示例: {'class': 'main-warpper'}").grid(row=2, column=2, padx=10, pady=5)
# 第四行:输入PDF编码
tk.Label(root, text="PDF文件编码:").grid(row=3, column=0, padx=10, pady=5)
pdf_encoding_entry = tk.Entry(root, width=50)
pdf_encoding_entry.insert(0, 'UTF-8') # 默认设置为UTF-8
pdf_encoding_entry.grid(row=3, column=1, padx=10, pady=5)
# 最后一行:生成PDF按钮
tk.Button(root, text="生成PDF", command=generate_pdf).grid(row=4, column=1, padx=10, pady=20)
# 启动主循环
root.mainloop()
具体步骤
代码如上应该不需要更该,一下是具体步骤,步骤对了代码就不会报错 ,注意:htmltopdf.py就是我们的Python程序,位置最好和我差不多
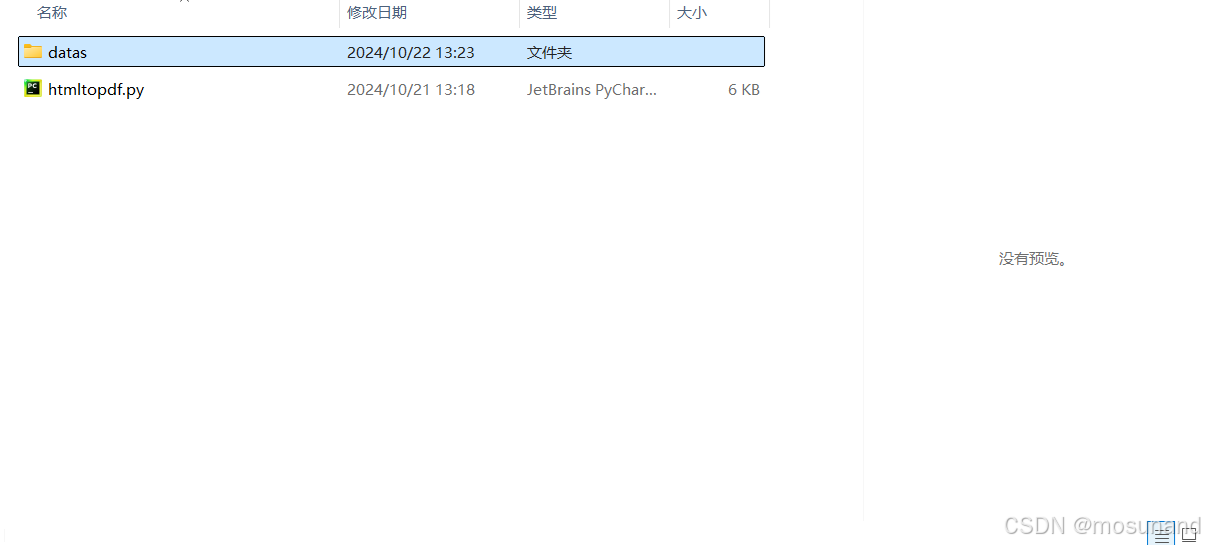
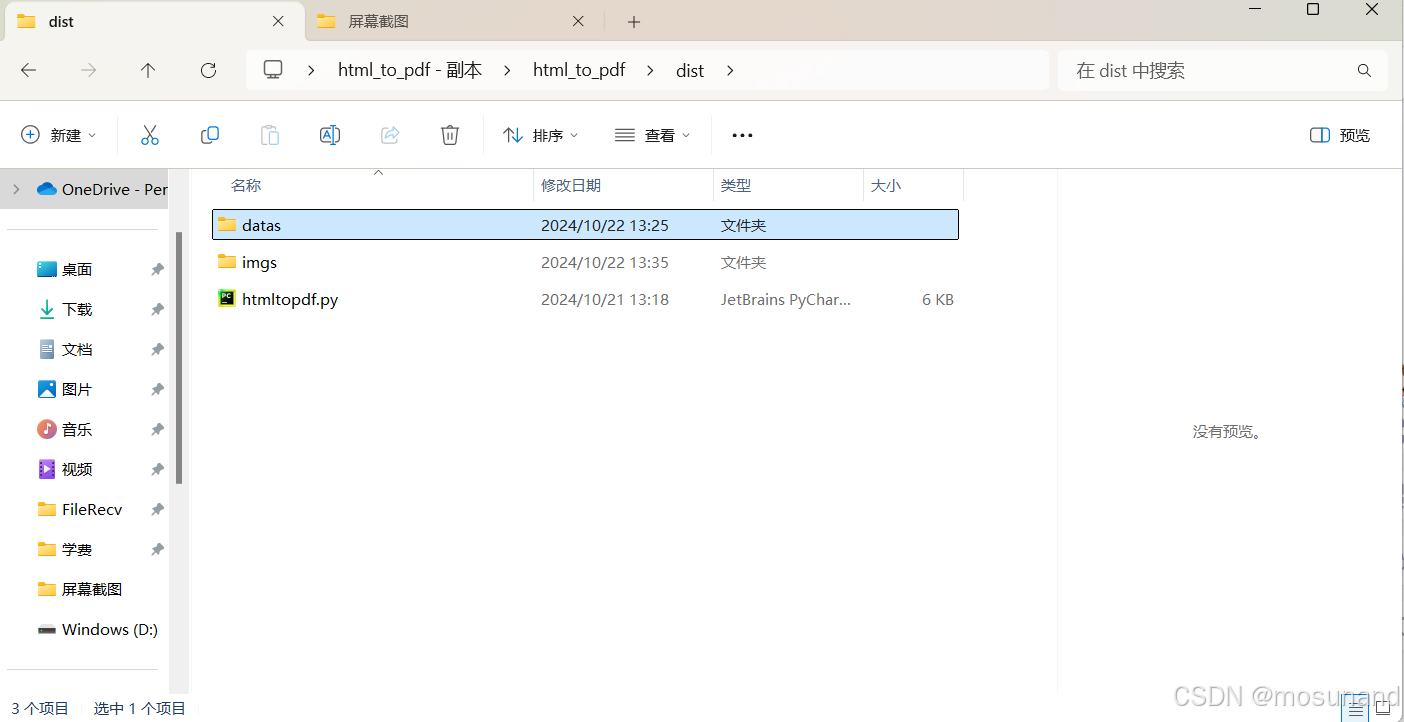
这个datas就是安装了 wkhtmltopdf这个软件的位置,如图,我只是把本来叫wkhtmltopdf的这个文件夹名字改为了datas
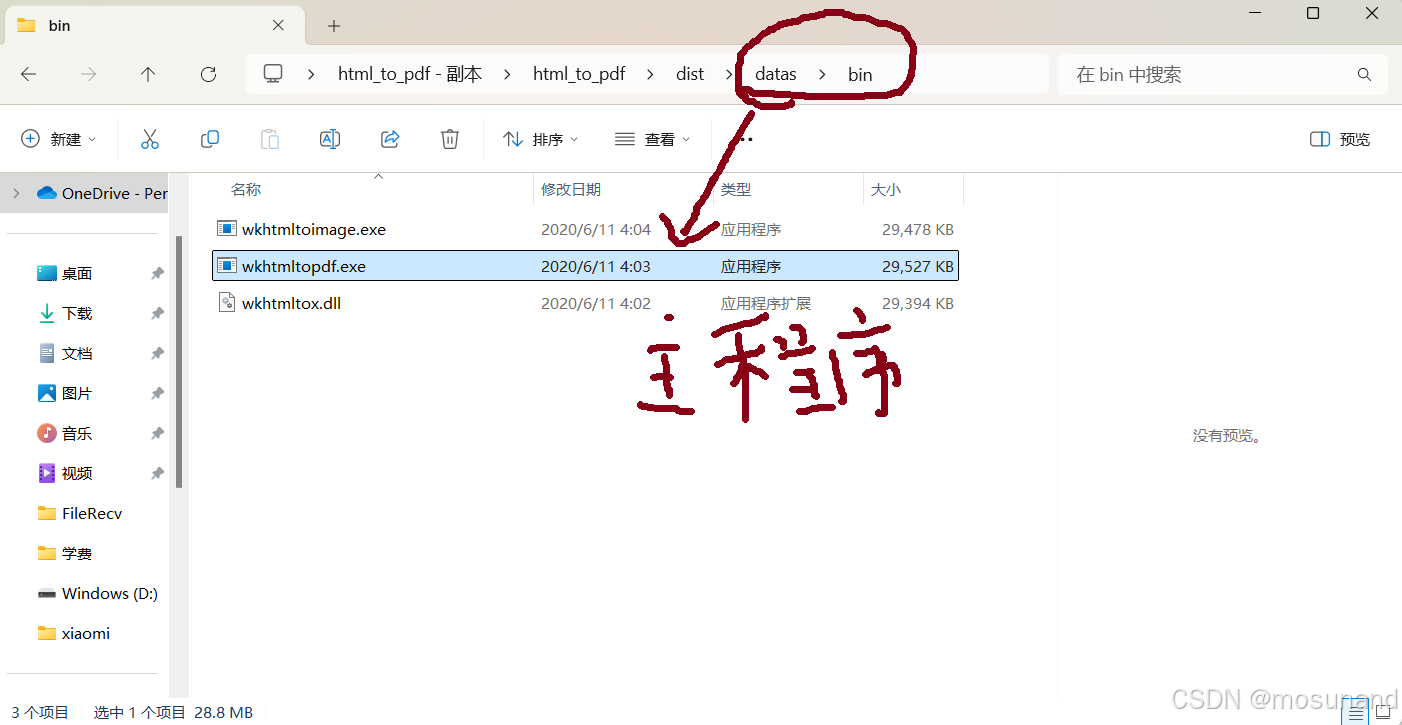
开始打包程序
这个时候就可以打包python代码为一个exe可执行文件了,我们可以为这个exe文件增加一个图标(不是必须的,看自己),最好放在python程序同一个文件夹里,或者和它同级的文件夹下的文件夹内,比如我是在同级创建了一个imgs文件夹,如图
在里面弄一个图片文件,文件后缀改为.ico (图标作用的) ,我这个是logo.ico
这个时候可以开始打包了,打包之前安装pyinstaller库,方法
pip install pyinstaller打包方法:在python文件处输入图cmd
按下enter键,进入cmd
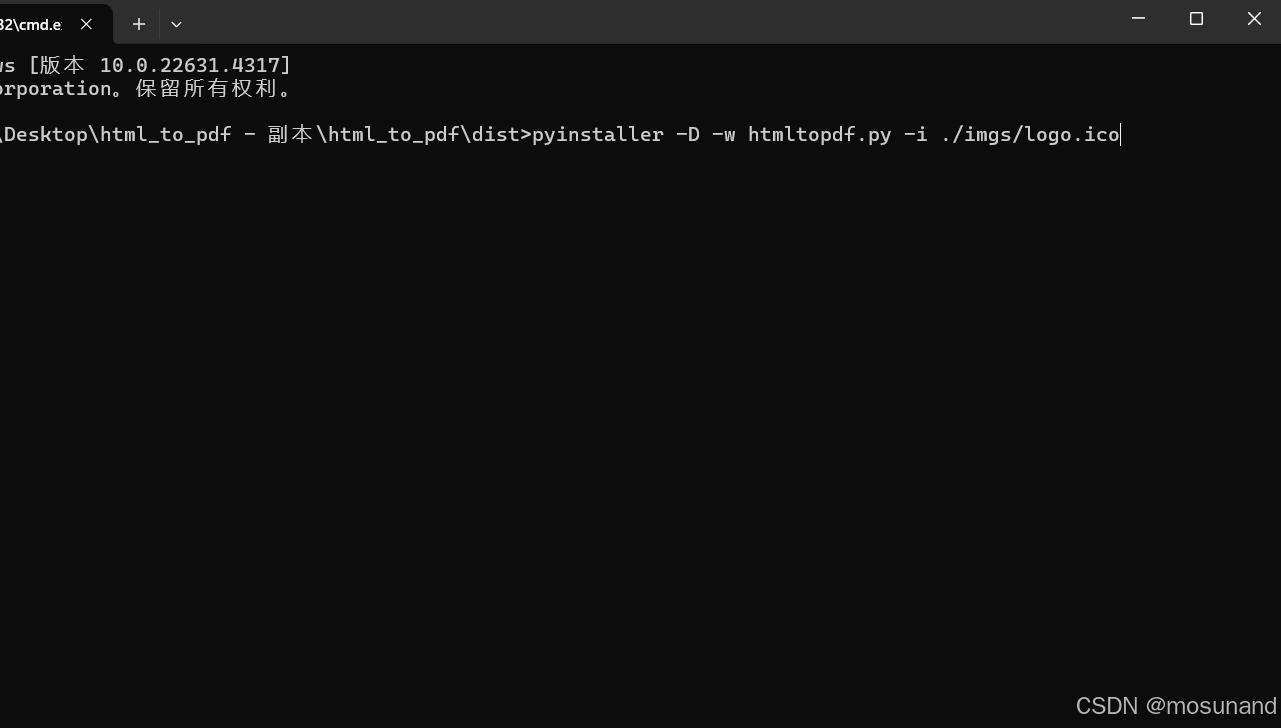
输入打包指令:
 注意:后面的-i ./imgs/logo.ico 不是必要的,如果你不想要图标,这个就不是必须的。
注意:后面的-i ./imgs/logo.ico 不是必要的,如果你不想要图标,这个就不是必须的。
我的指令如下
pyinstaller -D -w htmltopdf.py -i ./imgs/logo.ico后续操作
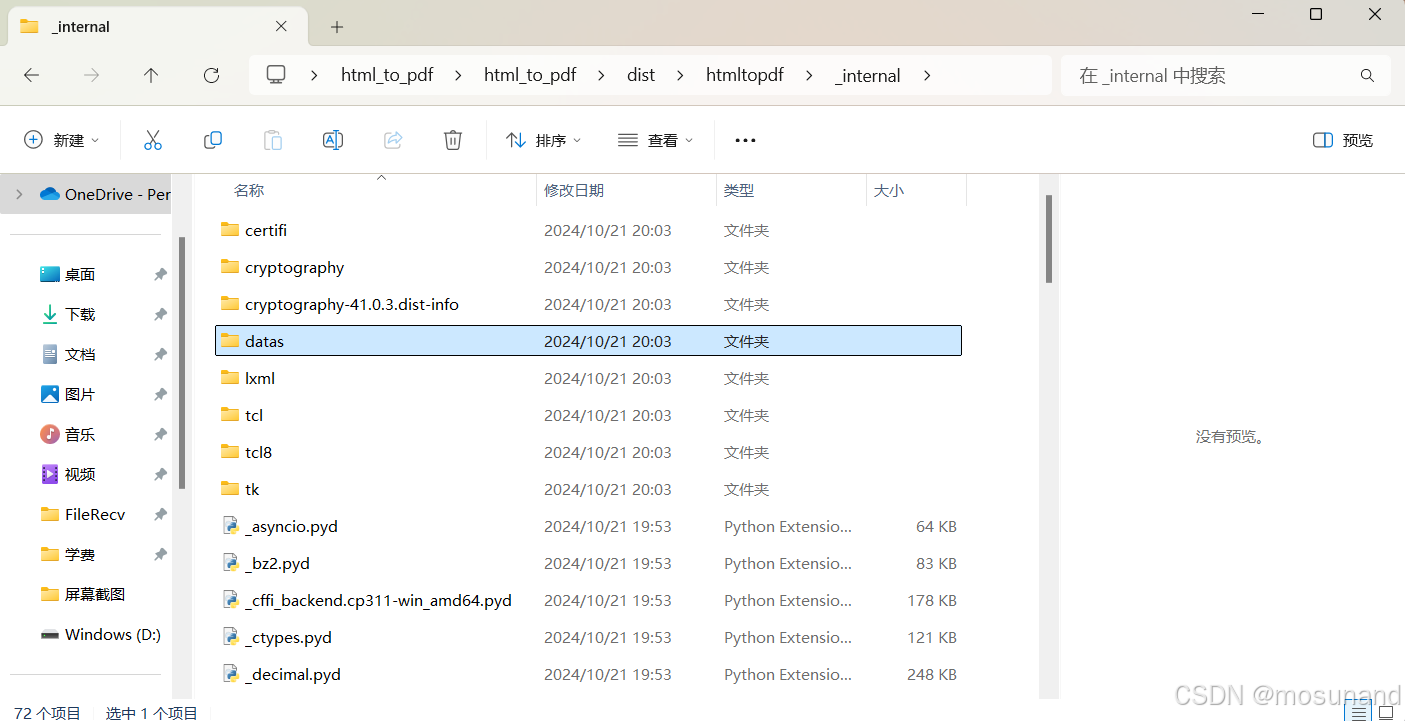
现在还不行,接着移动文件位置,把之前python文件位置的datas文件夹移动到打包后的html_to_pdf\html_to_pdf\dist\htmltopdf\_internal文件里面,如下2张图片
开始使用
打开html_to_pdf\html_to_pdf\dist\htmltopdf\htmltopdf.exe文件,这就是我们的可执行文件
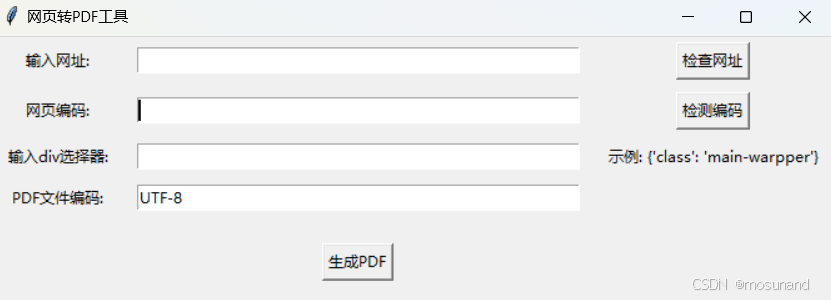
说明一下:这个有部分html是用不了的,比如csdn就难搞,一般还是可以
使用教程
以爬取百度百科里的湖南大学为例,我们爬取黑色线条以内的内容,黑色的叉叉不用
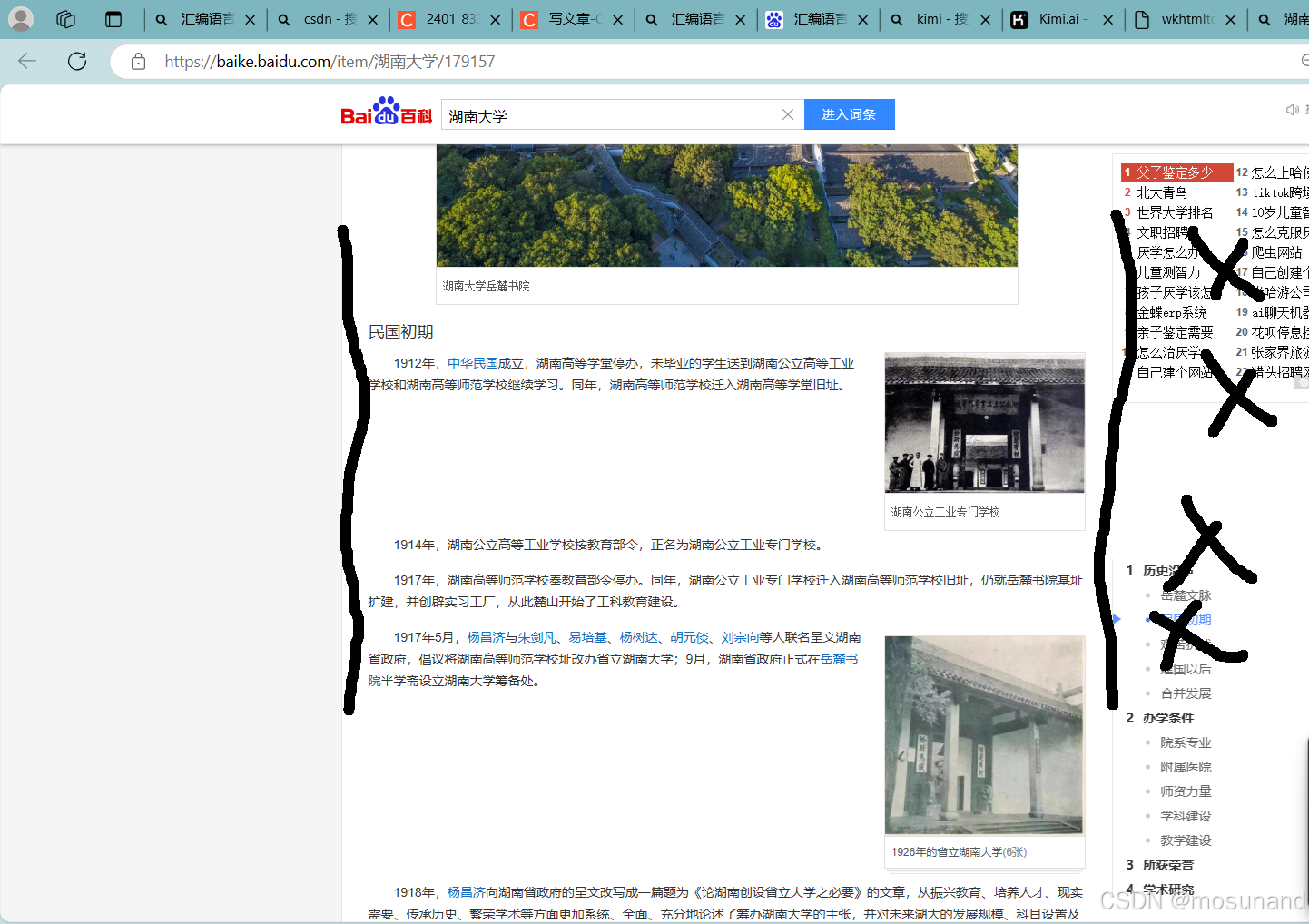
首先,在浏览器里按下F12
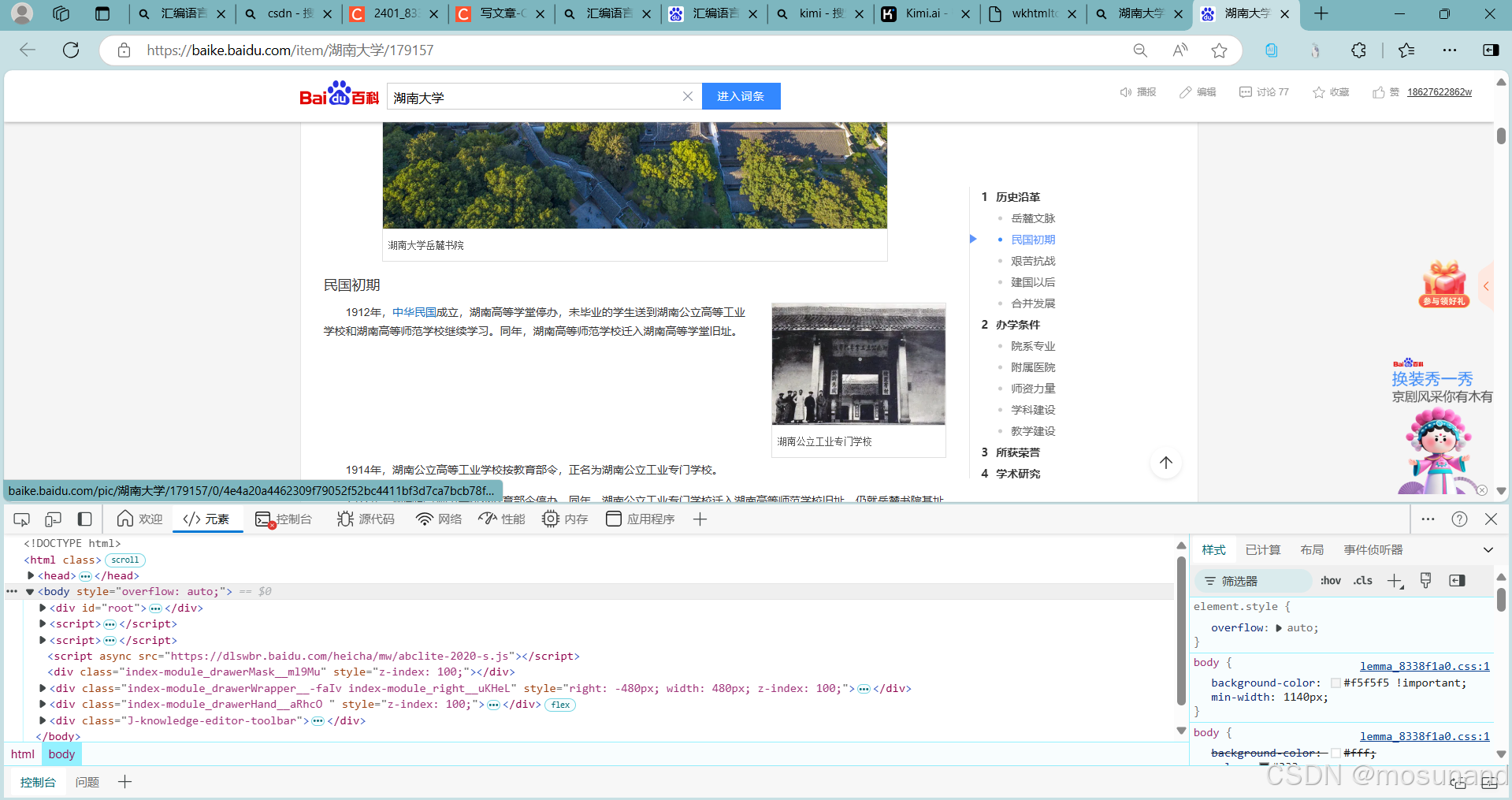
按下这个定位键,如图
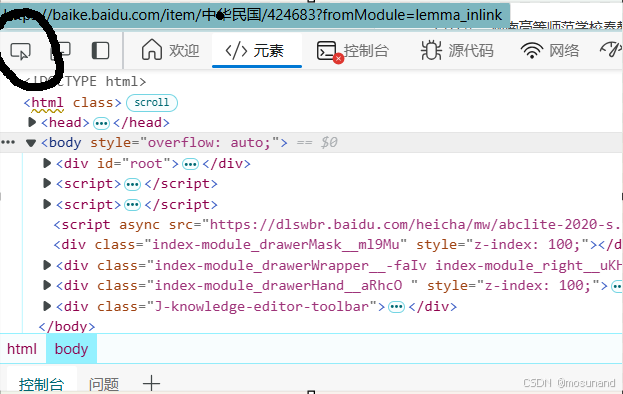
在网站出选中我们要用的界面,如图,再单击鼠标左键即可定位到html代码,如画黑线的地方
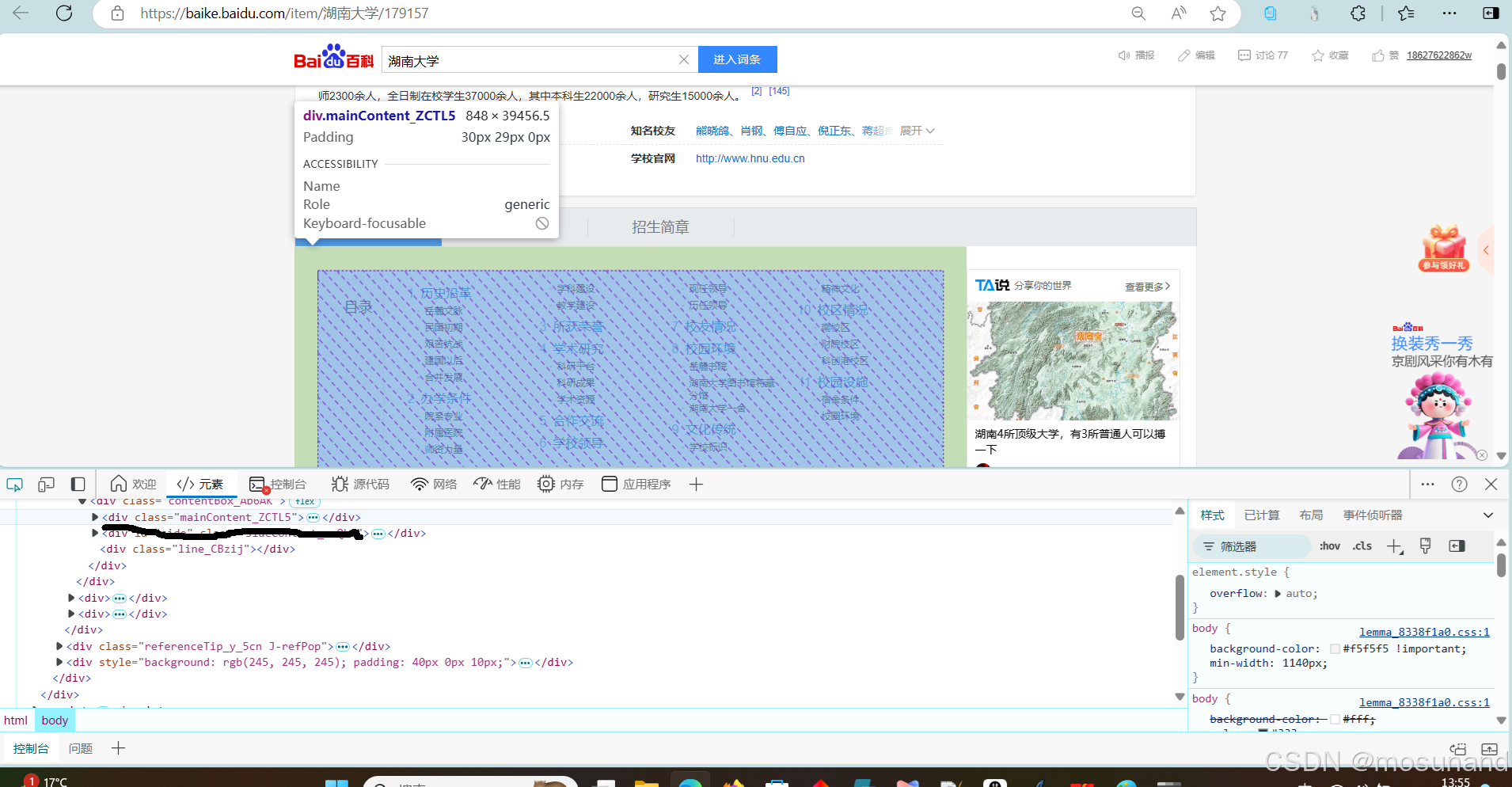
将网站复制下载,如
再将那个定位的div复制下来
<div class="mainContent_ZCTL5">把它改为{'class':'mainContent_ZCTL5'},放入软件,如下
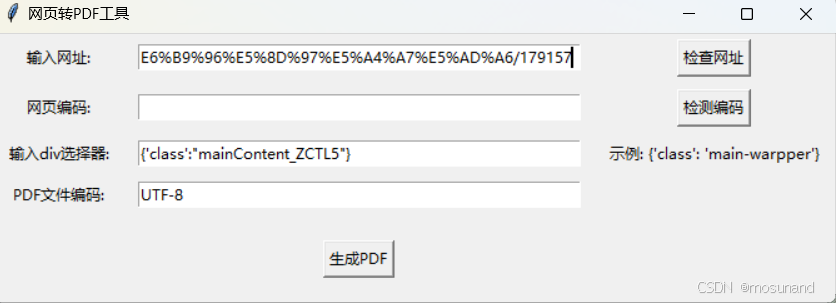
点击生成pdf,随便保存在一个位置,保存好后,成果如下(比较接近网站)
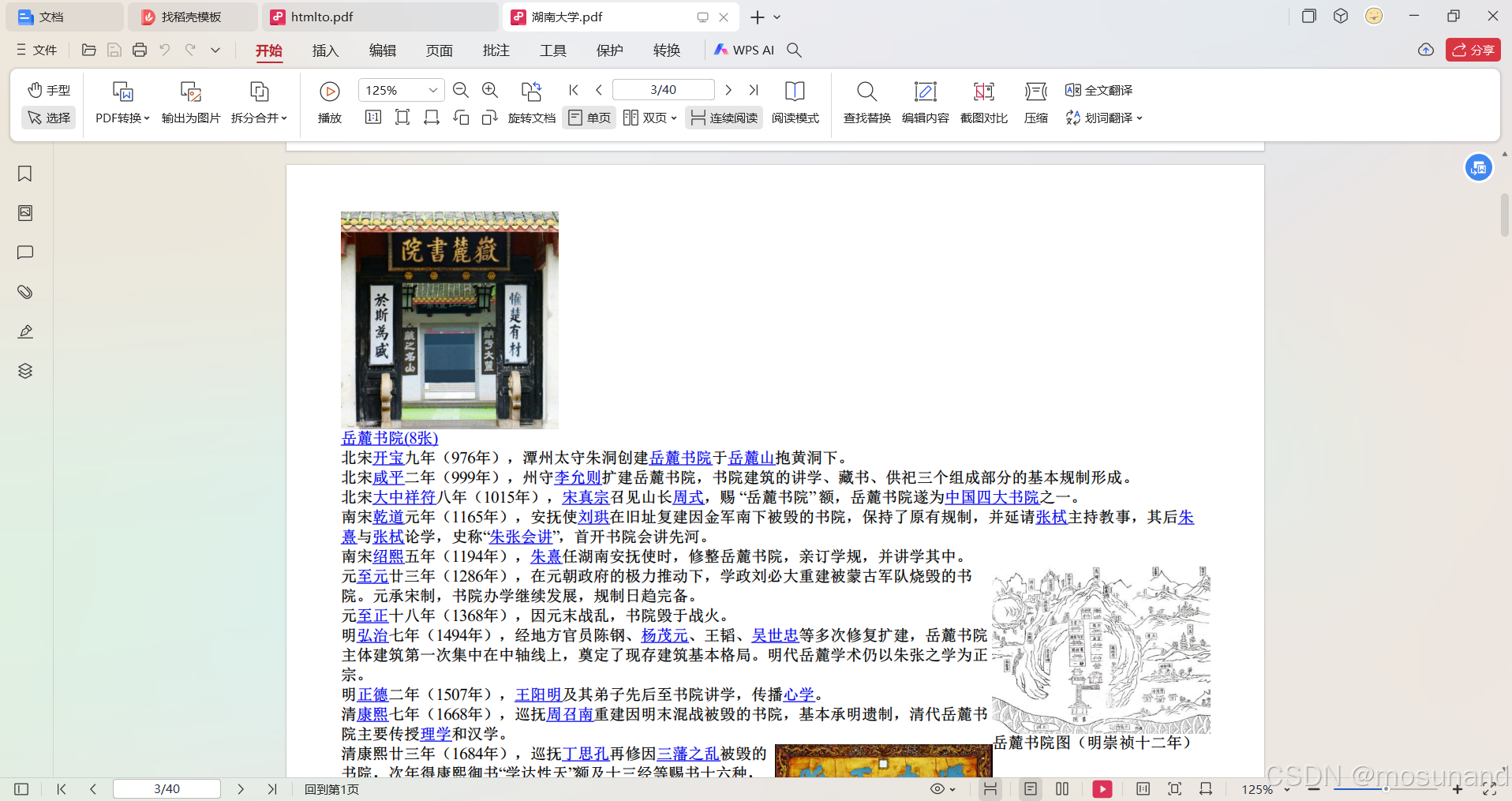
网站内容如下
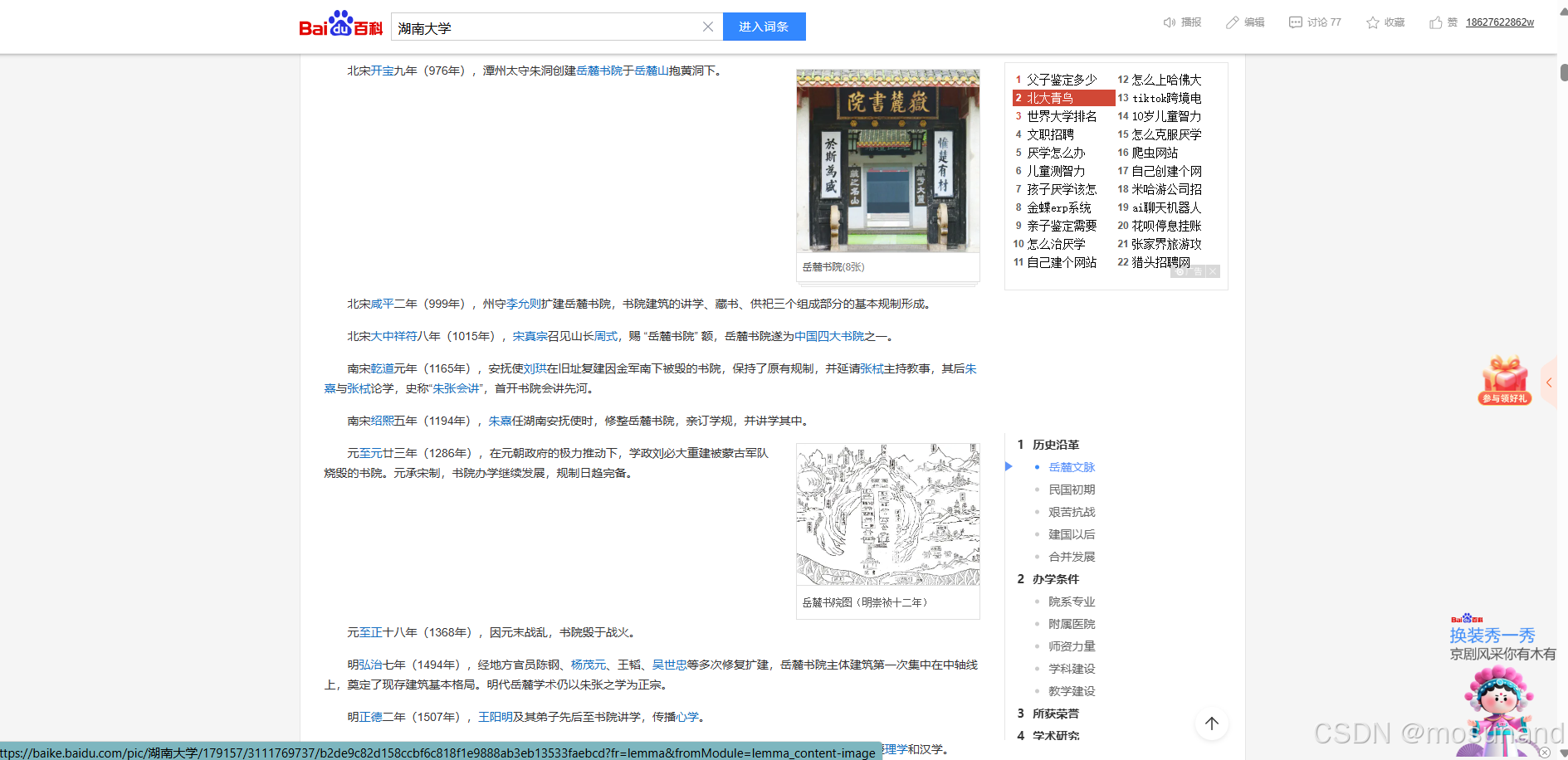
大差不差。哈哈
新人投稿,欢迎批评指正

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)