【机器学习】 Logistic 回归算法
一 、线性模型与回归
- 线性:两个变量之间的关系是一次函数关系的——图象是直线
注意:线性是指广义的线性,指数据与数据之间的关系。 - 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线
那到底什么时候可以使用线性回归呢?统计学家安斯库姆给出了四个数据集,被称为安斯库姆四重奏。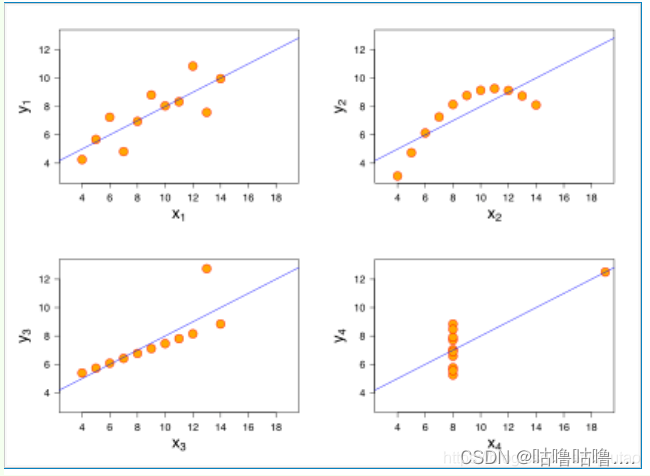
从这四个数据集的分布可以看出,并不是所有的数据集都可以用一元线性回归来建模。现实世界中的问题往往更复杂,变量几乎不可能非常理想化地符合线性模型的要求。因此使用线性回归,需要遵守下面几个假设:
- 线性回归是一个回归问题
- 要预测的变量y与自变量x的关系是线性的(图二是非线性的)
- 各项误差服从正态分布,均值为0,与x同方差(图四误差不是正态分布)
- 变量x的分布要有变异性
- 多元线性回归中不同特征之间应该相互独立,避免线性相关
线性回归一般形式:
f ( x ) = w 1 x 1 + w 2 x 2 + … + w d x d + b f(x) = w_1x_1+w_2x_2+…+w_dx_d+b f(x)=w1x1+w2x2+…+wdxd+b其中 x = ( x 1 , x 2 , … x d ) x = (x_1,x_2,…x_d) x=(x1,x2,…xd)是由d维属性描述的样本, x i x_i xi是x在第i 个属性上的取值。
向量形式可记为:
f ( x ) = w T x + b f(x)=w^Tx+b f(x)=wTx+b其中 w = ( w 1 , w 2 , … , w d ) w=(w_1,w_2,…,w_d) w=(w1,w2,…,wd)为待求解系数
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) {(x_1,y_1),(x_2,y_2),…,(x_m,y_m)} (x1,y1),(x2,y2),…,(xm,ym)},其中 x i = ( x i 1 , x i 2 , … , x i d ) , y i ∈ R x_i=(x_{i1},x_{i2},…,x_{id}),y_i \in R xi=(xi1,xi2,…,xid),yi∈R
线性回归的目的:学习一个线性模型以尽可能准确地预测实值输出标记:
f ( x ) = w x i + b f(x)=wx_i+b f(x)=wxi+b 使得 f ( x i ) ≃ y i f(x_i)\simeq y_i f(xi)≃yi
简单的线性回归算法实现
import numpy as np
import matplotlib.pyplot as plt
x=np.array([1,2,3,4,5],dtype=np.float)
y=np.array([1,3.0,2,3,5])
plt.scatter(x,y)
x_mean=np.mean(x)
y_mean=np.mean(y)
num=0.0
d=0.0
for x_i,y_i in zip(x,y):
num+=(x_i-x_mean)*(y_i-y_mean)
d+=(x_i-x_mean)**2
a=num/d
b=y_mean-a*x_mean
y_hat=a*x+b
plt.figure(2)
plt.scatter(x,y)
plt.plot(x,y_hat,c='r')
x_predict=4.8
y_predict=a*x_predict+b
print(y_predict)
plt.scatter(x_predict,y_predict,c='b',marker='+')
结果为:

二 、最小二乘与参数求解
最小二乘法是一种数学优化方法,它的主要思想是通过确定未知参数(通常是一个参数矩阵),来使得真实值和预测值的误差(也称残差)平方和最小。这个方法常用于拟合函数和估计参数。
来看生活中的一个例子:有五把尺子
用它们来分别测量一线段的长度,得到的数值分别为(颜色指不同的尺子):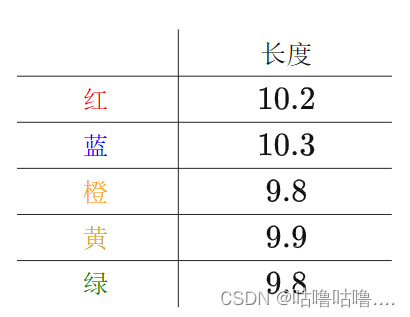
之所以出现不同的值可能为:
- 不同厂家的尺子生产精度不同
- 尺子材质不同,热胀冷缩不一样
- 测量时心情起伏不定
- ……
总之,就是存在误差,这种情况下,一般取平均值来作为线段的长度:
x ‾ = 10.2 + 10.3 + 9.8 + 9.9 + 9.8 5 = 10 \overline{x}=\frac{10.2+10.3+9.8+9.9+9.8}{5}=10 x=510.2+10.3+9.8+9.9+9.8=10
但是可能会引发思考:
- 这样做有道理吗?
- 用调和平均数行不行?
- 用中位数行不行?
- 用几何平均数行不行?
换一种思路来思考刚才的问题。
首先,把测试得到的值画在笛卡尔坐标系中,分别记作 y i y_i yi:
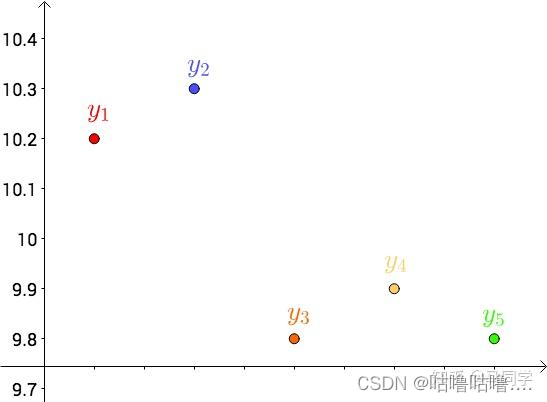
其次,把要猜测的线段长度的真实值用平行于横轴的直线来表示(因为是猜测的,所以用虚线来画),记作:
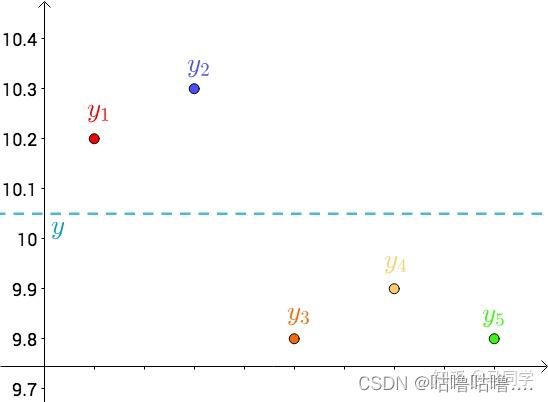
每个点都向y做垂线,垂线的长度就是 ∣ y − y i ∣ |y-y_i| ∣y−yi∣,也可以理解为测量值与真实值之间的误差:
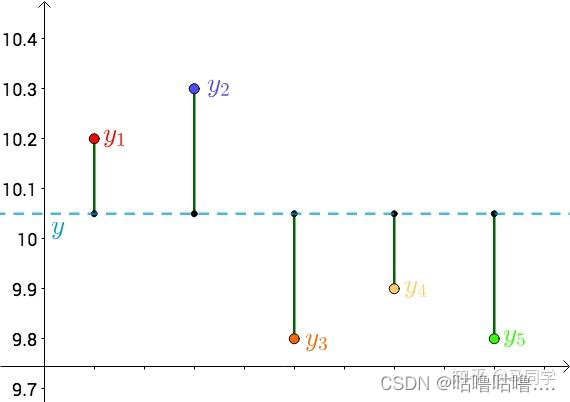
因为误差是长度,还要取绝对值,计算起来麻烦,所以干脆用平方差来代表误差:
∣ y − y i ∣ ⟹ ( y − y i ) 2 |y-y_i| \implies(y-y_i)^2 ∣y−yi∣⟹(y−yi)2误差的平方和就是( ϵ \epsilon ϵ代表误差): S ϵ 2 = ∑ ( y − y i ) 2 S_{\epsilon^2}=\sum(y-y_i)^2 Sϵ2=∑(y−yi)2因为y是猜测的,所以可以不断变换:

自然,误差的平方和 S ϵ 2 S_{\epsilon^2} Sϵ2也在不断变化的。
法国数学家 阿德里安-马里·勒让德 提出:让总的误差的平方最小的 y 就是真值,这是基于:如果误差随机,应该围绕真值上下波动。
勒让德 的想法变成代数式: S ϵ 2 = ∑ ( y − y i ) 2 最小 ⟹ 真值 y S_{\epsilon^2}=\sum(y-y_i)^2最小\implies真值y Sϵ2=∑(y−yi)2最小⟹真值y
这是一个二次函数,对其求导,导数为0时取得最小值,由结果可知正好是算术平均数。所以算术平均数可以让误差最小。
以下这种方法:
S ϵ 2 = ∑ ( y − y i ) 2 最小 ⟹ 真值 y S_{\epsilon^2}=\sum(y-y_i)^2最小\implies 真值y Sϵ2=∑(y−yi)2最小⟹真值y就是最小二乘法,所谓 “二乘” 就是平方的意思。(最小二乘法的原理理解)
算术平均数只是最小二乘法的特例,适用范围比较狭窄,而最小二乘法用途就广泛。
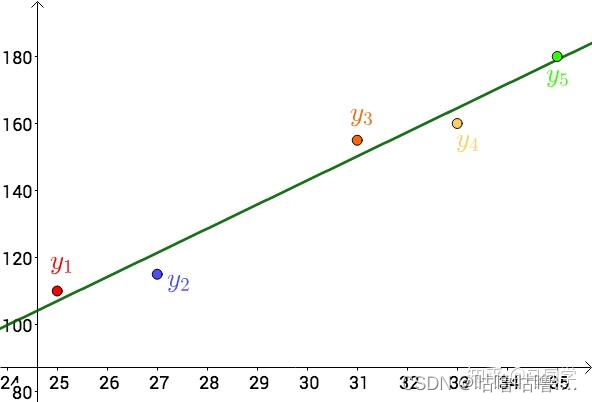
案例: 温度和冰淇淋的销量: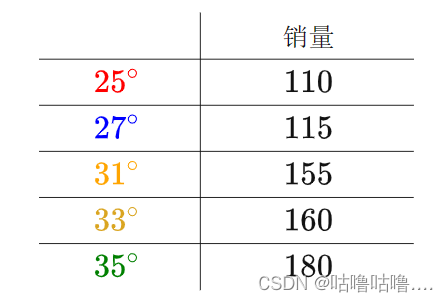
看上去像是某种线性关系:
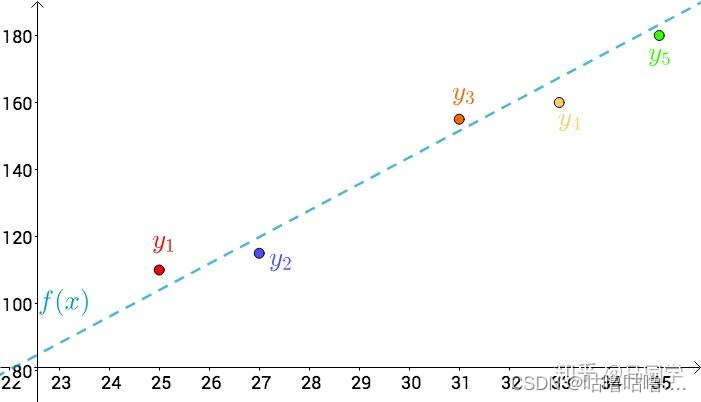
可以假设这种线性关系为:
f ( x ) = a x + b f(x) = ax+b f(x)=ax+b通过最小二乘法的思想:
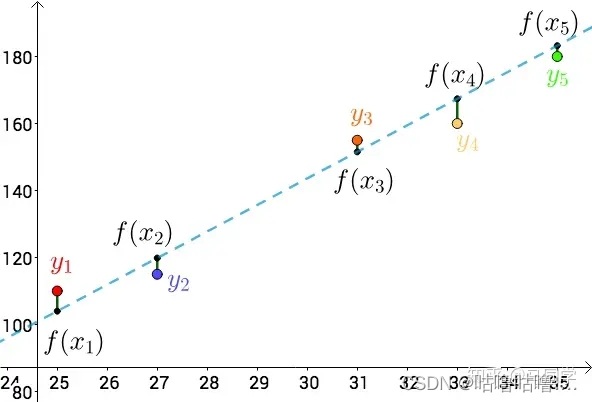
上图中的 i,x,y分别为: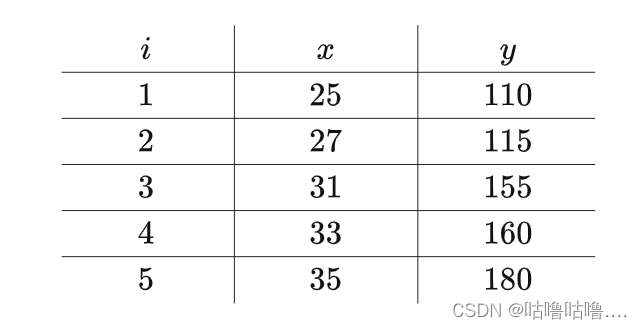
总误差的平方为:
S ϵ 2 = ∑ ( f ( x i ) − y i ) 2 = ∑ ( a x i + b − y i ) 2 S_{\epsilon^2}=\sum(f(x_i)-y_i)^2=\sum(ax_i+b-y_i)^2 Sϵ2=∑(f(xi)−yi)2=∑(axi+b−yi)2
不同的a,b会导致不同的 S ϵ 2 S_{\epsilon^2} Sϵ2,根据多元微积分的知识求导,当导数为0时 S ϵ 2 S_{\epsilon^2} Sϵ2取最小值。
对于a,b而言,上述方程组为线性方程组,用之前的数据解出来:
{ a ≈ 7.2 b ≈ − 73 \begin{cases} a\approx7.2 & \\ b\approx-73\end{cases} {a≈7.2b≈−73也就是这根直线:
三 、对数线性回归
线性回归模型: f ( x ) = w x + b f(x) = wx+ b f(x)=wx+b, 取合适的 w,b 值,使得预测值逼近真实标记 y
例如 : g ( x ) = e x g(x) =e^x g(x)=ex,取 y 的对数,即 lny ,就可以得到对数线性回归模型: y = e w x + b ⟺ l n y = w x + b y=e^{wx+b} \iff lny = wx+b y=ewx+b⟺lny=wx+b l n y = w T x + b ⟺ y = e w T x + b lny = w^Tx+b \iff y = e^{w^Tx+b} lny=wTx+b⟺y=ewTx+b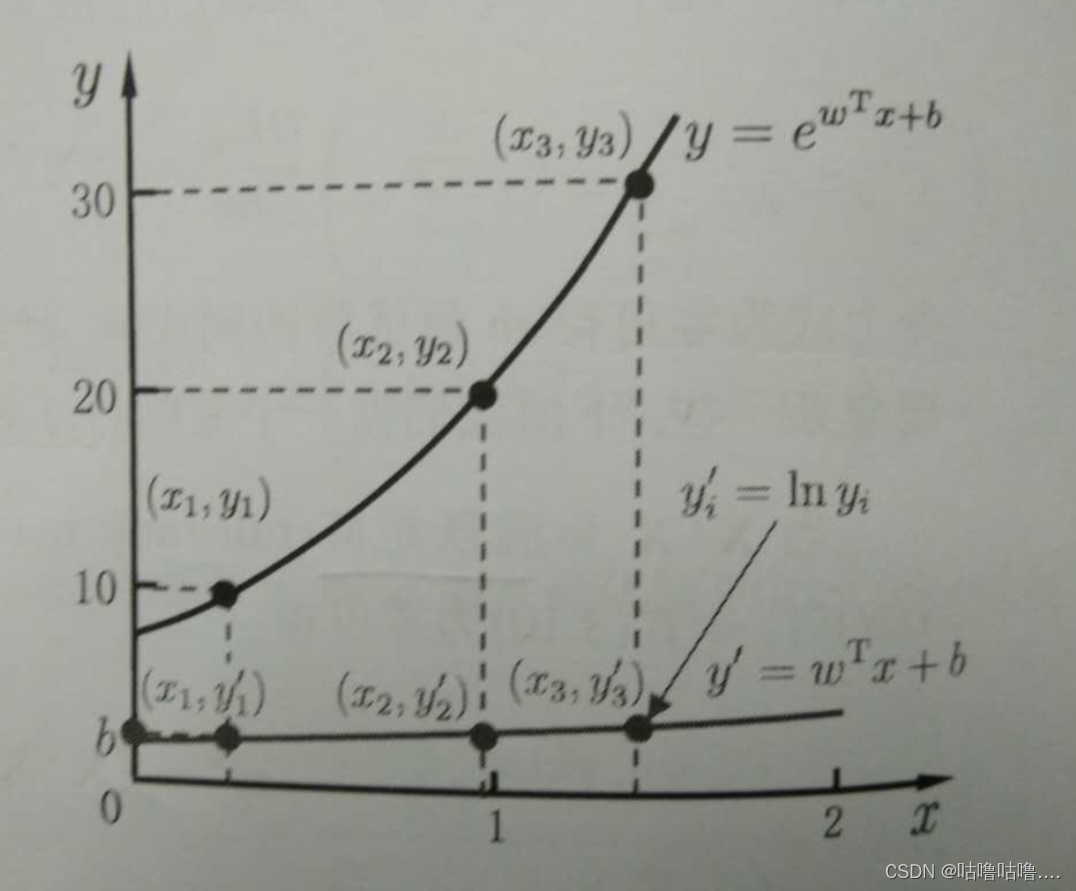
四 、Logistic 回归
逻辑回归与线性回归都是一种广义线性模型(generalized linear model,GLM)。具体的说,都是从指数分布族导出的线性模型,线性回归假设Y|X服从高斯分布,逻辑回归假设Y|X服从伯努利分布。
伯努利分布:伯努利分布又名0-1分布或者两点分布,是一个离散型概率分布。随机变量X只取0和1两个值,比如正面或反面,成功或失败。为方便起见,记这两个可能的结果为0和1,成功概率为p(0<=p<=1),失败概率为q=1-p。
高斯分布:高斯分布一般指正态分布。
因此逻辑回归与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
在做分类问题时,sigmoid、tanh、relu函数都可以很好的处理从0到1跳跃的瞬间过程。就拿最常见的sigmoid函数来说,它的方程是:
S ( x ) = 1 1 + e − x S(x) = \frac{1}{1+e^{-x}} S(x)=1+e−x1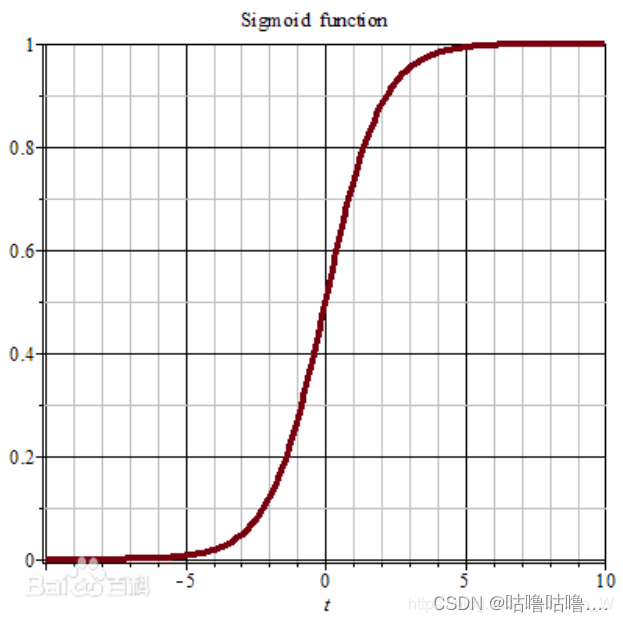
当x=0时,f(x)=0.5,函数在x=0两侧逐渐收敛向0和1两个极端,并且函数单增。有了sigmoid函数,我们无论输入什么值都可以得到(0,1)的数值,然后通过0.5为界分类。
梯度下降法
在高数中我们都学过偏导,而偏导的结果就是梯度。梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
f(x,y)有两个自变量,其梯度就有x和y两个方向。f分别对x和y求偏导就能得到该函数在该方向上的梯度。
f ( x , y ) = ( α f ( x , y ) α x ) f(x,y) = \left(\frac{\alpha f(x,y)}{\alpha x}\right) f(x,y)=(αxαf(x,y)) f ( x , y ) = ( α f ( x , y ) α y ) f(x,y) = \left(\frac{\alpha f(x,y)}{\alpha y}\right) f(x,y)=(αyαf(x,y))
下面用一个二维坐标系来讲解一下梯度下降法的思想,在二维坐标中有一条sin曲线,变量x在曲线上移动,试图寻找最大值,按照梯度下降(上升)法的思想,只要知道梯度的下降(上升)的方向就能知道x点在sin曲线上移动的方向。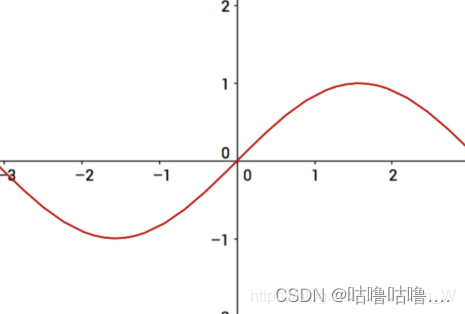
在上图中,x作为变量,y作为我们的目标值,这样方便理解,在实际运用中变量可能有n个,这时我们就需要在不同维度去求梯度从而使得粒子在不同维度都逼近我们想要的最大(最小)值。当我们寻找最高点时,使用梯度上升法。假设x=1,在该点对函数求导,得到的是正数,故x应当向正方向移动;当x=2时,得到的是负数,证明在该点继续移动f(x)会越来越小,这与我们预期相违背,所以应当向负方向移动。 梯度下降也是同样的道理。
Logistic 算法原理
我们先说一个概念,事件的几率(odds),是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是p,那么该事件的几率是p/(1-p)。取该事件发生几率的对数,定义为该事件的对数几率(log odds)或logit函数:
l o g i t ( p ) = l o g p 1 − p logit(p) = log\frac{p}{1-p} logit(p)=log1−pp事件发生的概率p的取值范围为[0,1],对于这样的输入,计算出来的几率只能是非负的,而通过取对数,便可以将输出转换到整个实数范围内。
极大似然估计:
极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
五 、实现
import numpy as np
from sklearn.preprocessing import OneHotEncoder
class Logistic:
def __init__(self, max_depth=5000):
self.sep = 0.01
self.onehot = OneHotEncoder()
self.max_depth = max_depth
def fit(self, train_x, train_y):
self.train_x = np.mat(train_x)
m, n = self.train_x.shape
# print(m,n)
self.simple = m # 样本数量
self.W = np.ones((n, 1)) # 初始权重
self.train_y = np.mat(train_y)
if self.train_y.shape[0] == 1:
self.train_y = np.mat(self.train_y.reshape((m, 1)))
self.W = self.Grade() # 最优权重
# 提取训练数据训练特征
def fit_transform(self, train_List, train_y=None):
x = np.array(train_List).T
y = np.array(train_y).T
train_x = self.onehot.fit_transform(x, y)
return train_x, y
def transform(self, test_x):
test_x = np.array(test_x)
return self.onehot.transform(test_x)
# sigmod 函数
def sigmod(self, X):
return 1/(1 + np.exp(-X))
# 梯度下降, 得到最优权重w
def Grade(self):
X = self.train_x
Y = self.train_y
for i in range(self.max_depth):
grad = X.T*(X * self.W - Y) # 梯度
self.W = self.W - self.sep * grad
# print(self.W)
return self.W
def predict(self, test_x):
data_y = self.sigmod(test_x * self.W)
# print(data_y)
predict_y = []
for y in data_y:
if y > 0.5:
predict_y.append(1)
else:
predict_y.append(-1)
return predict_y
if __name__ == '__main__':
train_List = [[1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3],
['S', 'M', 'M', 'S', 'S', 'S', 'M', 'M', 'L', 'L', 'L', 'M', 'M', 'L', 'L', 'L']
]
train_y = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
test_data = [[1, "S"], [2, "S"], [3, "S"]]
Logic = Logistic()
train_x, train_y = Logic.fit_transform(train_List, train_y)
train_x = train_x.toarray() # train_x为稀疏矩阵,转化为array格式
Logic.fit(train_x, train_y)
test_x = Logic.transform(test_data) # test_x为稀疏矩阵,转化为array格式
test_x = test_x.toarray()
print("测试数据为:{}, 预测类别为:{}".format(test_data, Logic.predict(np.mat(test_x))))
结果为:
六 、总结
Logistics回归算法是一种简单但强大的分类算法,它在实际应用中被广泛使用。除了二元分类和多元分类之外,逻辑回归也可以用于解决其他问题,例如异常检测、推荐系统、文本分类、图像分类等。然而,对于复杂的非线性问题,逻辑回归算法的表现可能并不理想,需要考虑其他更加高级和复杂的算法来解决。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)