R-CNN 算法详解
一、 背景介绍
在目标检测领域的发展历程中,R-CNN(Regions with CNN features)算法犹如一座重要的里程碑,其诞生彻底革新了传统目标检测的格局。在 2014 年由 Ross Girshick 等人提出之前,目标检测主要依赖传统机器学习方法,如基于 HOG(Histogram of Oriented Gradients)特征与 SVM(Support Vector Machine)分类器的组合。但这类方法在面对复杂背景及多尺度目标时,往往显得力不从心,检测效果差强人意,且计算效率极为低下。
随着深度学习浪潮的兴起,尤其是卷积神经网络(CNN)在图像分类任务中展现出卓越的性能,极大地激发了研究者将其引入目标检测领域的探索热情。R-CNN 正是在这一背景下应运而生,它巧妙地融合了 CNN 强大的特征提取能力与传统目标检测方法中的候选区域生成策略,实现了目标检测准确率的显著提升,为后续一系列目标检测算法的发展奠定了坚实基础。
二、R-CNN 算法原理
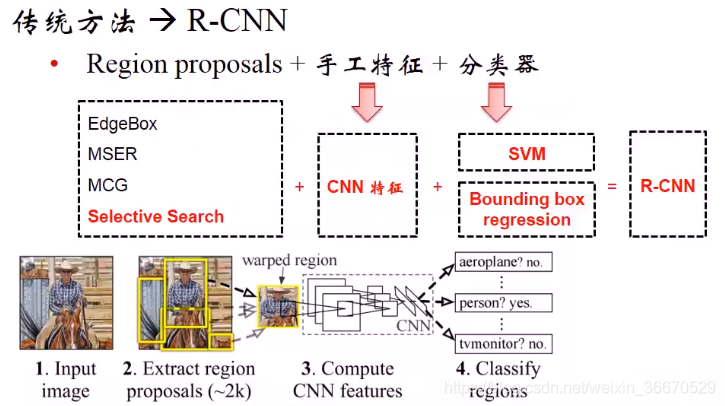
传统的方法,先要进行区域建议的生成,然后对每个区域进行手工特征的设计和提取,然后送入分类器。R-CNN 的整体框架遵循传统目标检测的基本思路,但在关键环节进行了创新改进。它主要包含四个核心步骤:提取候选框、对每个框提取特征、图像分类以及非极大值抑制。与传统方法不同之处在于,R-CNN 预先提取一系列较可能包含物体的候选区域,而非采用穷举法或滑动窗口遍历整幅图像,这一策略大幅减少了后续处理的计算量;同时,在特征提取阶段,摒弃了传统的手工设计特征(如 SIFT、HOG 特征等),转而利用深度卷积网络提取特征,充分发挥了深度学习自动学习特征的优势 。
三、R-CNN工作流程
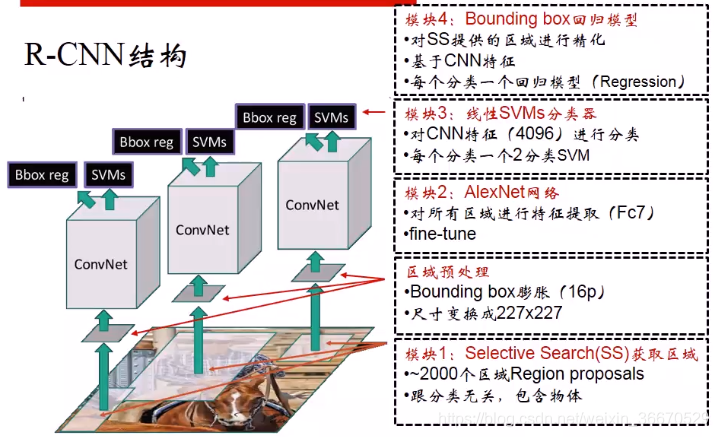
- 模块1:用SS算法获取区域建议,大约有2000多个,SS算法不负责分类,只是判断有没有包含物体。
- 区域预处理:接下来做区域预处理,每个区域先做16个像素的膨胀。接下来送到Alexnet网络,对所有区域进行特征提取。
- 模块二:从第7层,也就是第二个全连接层的输出作为特征,Alexnet网络需要fine-tune(微调),得到特征以后送到SVM里面进行分类。
- 模块三:对CNN特征进行分类,fc7输出的特征是4096维的1x4096,分类的时候是二分类问题,比如PASCAL VOC有20个类,最后就会有20个SVM,每个SVM负责一个分类,判断这个类有无用0或者1表示,而且是线性的分类器。
- 模块四:Bounding Box回归模型是额外加的,要精化SS算法生成的区域位置,输入需要CNN特征,使用的是第5卷积层的特征,和SVM分类器类似,一个分类对应一个模型,如果有20个分类就有20个分类模型。
四、R-CNN训练流程

- 第一步、获取预训练的模型,R-CNN使用的是在Imagenet上预训练好的Alexnet。
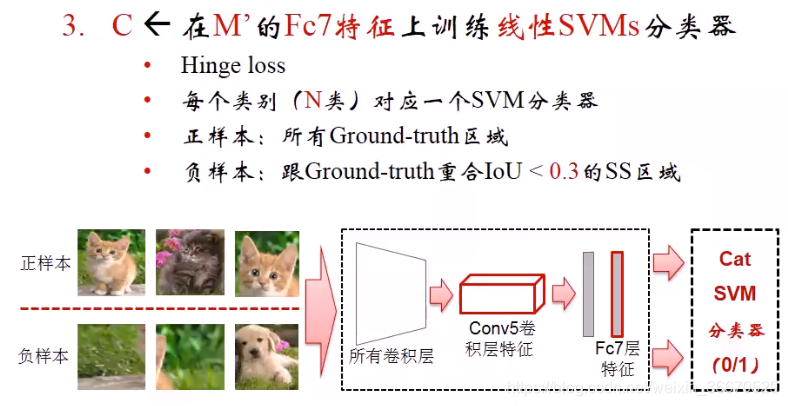
- 第二步、做fine-tune(微调),在fine-tune之前先对Alexnet进行稍微的修改,原始Alexnet最后一个全连接层的输出由1000维改为201维或21维,因为原始的Alexnet是在Imagenet上训练的,需要根据不同的数据集把全连接成改成相应的维度。样本的组织方式为:有N类,比如PASCAL VOC有20类,每个minibatch(小批次)提供23个正样本,负样本也就是背景类一共96个。正负样本的判断根据和groundtruth(真值)的重合度来判断。所有层都要fine-tune包括卷积层。
- 第三步、fine-tune后这个网络就适应了检测数据集,fine-tune结束后就不使用softmax层了,而使用fc7输出的特征,4096维作为区域图片的特征,然后使用这个特征训练线性分类器。
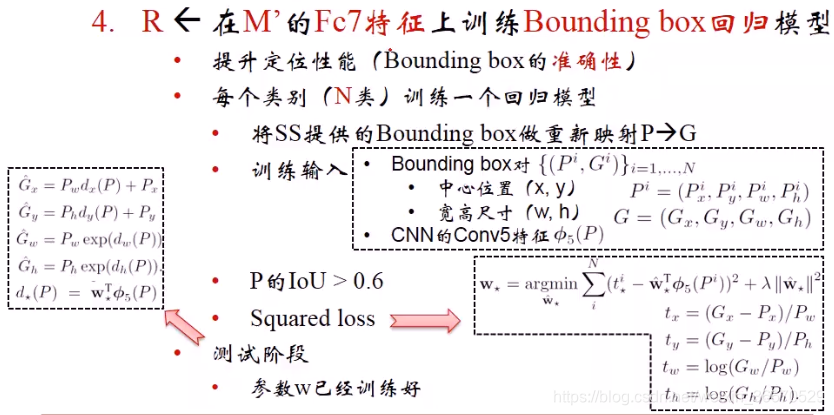
- 第四步、输入卷积层的conv5特征,是个tensor三维矩阵,特征回归模型将旧的x、y、h、w映射成更精确的x、y、h、w。P是SS算法提出的旧的Bounding box位置信息,G是ground truth输出的精确的位置选取。P的选取有新的方式,设置IOU的阈值为0.6,回归模型的优化时差平方和loss。在loss中w是需要学习的,w乘在Conv5的特征上进行特征的组织和变维,*的含义是x,y,w,h个需要学习一个参数w,x和y是直角坐标系下的比例关系,w和h是极坐标下的比例关系,最终计算出的是变化,或者说是校准量而不是原本的输出结果。最终回归模型学习到4个w。
五、测试阶段

测试和训练有一点差异,但是基本一致。首先用SS算法提取出2000个区域,然后对区域进行膨胀+缩放达到227x227,使用fine-tune过的Alexnet算出两套特征,分别是Fc7和Conv5。Fc7直接送到SVM里面进行分类,分类之后产生20个分支(假设使用的是PASCAL VOC数据集),哪个类别的分值最高,就认为这个区域属于哪个类别。比如对猫来讲,提取了2000个区域,里面有100个是猫属性输出的概率最大,对100个猫区域的候选区域进行筛选和过滤,通过非极大值抑制,把多于的重合的区域全部剔除掉,最终只剩下10个,10个就是重合度不高的区域,有可能就是多个猫,分散在不同位置上,缩小范围后进行Bounding box回归。
六、R-CNN 算法优缺点
优点
高准确率:通过引入深度学习模型进行特征提取,R-CNN 能够学习到更具判别性的图像特征,相较于传统目标检测方法,显著提高了目标检测的准确率,为目标检测领域带来了新的突破。
特征学习自动化:CNN 具备强大的自动学习图像特征的能力,极大地减少了人工设计特征的复杂性和工作量。模型能够从大量数据中自主学习到不同目标物体的特征模式,对复杂背景和多尺度目标具有更好的适应性 。
缺点
计算效率低:R-CNN 需要对每个候选区域分别进行 CNN 特征提取,这意味着在处理大规模图像数据集时,需要进行大量重复的计算,导致检测速度非常缓慢,难以满足实时性要求较高的应用场景 。
存储需求大:由于需要将提取的每个候选区域的特征向量存储在硬盘上,以减少重复计算,这无疑增加了大量的存储空间需求,对于大规模数据的处理和存储带来了挑战 。
训练复杂:R-CNN 的训练过程涉及多个阶段,包括 CNN 特征提取、SVM 分类器训练和回归模型训练,并且不同阶段需要不同的数据集和参数设置,整个训练流程较为复杂,对计算资源和技术要求较高 。
七、总结
R-CNN 算法作为深度学习应用于目标检测领域的开创性工作,通过创新地结合深度学习与传统目标检测方法,实现了目标检测性能的重大飞跃。它为后续目标检测算法的发展提供了重要的思路和基础,尽管其自身存在一些局限性,但这些不足也促使了后续如 Fast R-CNN、Faster R-CNN 等一系列算法的不断改进和优化。在未来,随着硬件性能的提升和算法的持续创新,目标检测技术有望在更多领域得到更广泛、更高效的应用 。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)