Spark Streaming读写 kafka
大数据开发-Spark-开发Streaming处理数据 && 写入Kafka
Spark Streaming+Kafka spark 写入 kafka
Direct模式
和基于 Receiver 接收数据不一样,这种方式定期地从 Kafka 的 topic+partition 中查询最新的偏移量,再根据定义的偏移量范围在每个批处理时间间隔里面处理数据。当作业需要处理的数据来临时,Spark 通过调用 Kafka 的低级消费者 API 读取一定范围的数据。这个特性目前还处于试验阶段,而且仅仅在 Scala 和 Java 语言中提供相应的 API。
Direct模式优点
和基于 Receiver 方式相比,这种方式主要有一些几个优点:
(1)简化并行。
我们不需要创建多个 Kafka 输入流,然后 union 他们。而使用 DirectStream,SS 将会创建和 Kafka 分区一样的 RDD 分区个数,而且会从 Kafka 并行地读取数据,也就是说 Spark 分区将会和 Kafka 分区有一一对应的关系,这对我们来说很容易理解和使用;
(2)高效。
第一种实现零数据丢失是通过将数据预先保存在 WAL 中,这将会复制一遍数据,这种方式实际上很不高效,因为这导致了数据被拷贝两次:一次是被 Kafka 复制;另一次是写到 WAL 中。但是本方法因为没有 Receiver,从而消除了这个问题,所以不需要 WAL 日志;
(3)恰好一次语义(Exactly-once semantics)。
Receiver 实现中通过使用 Kafka 高层次的 API 把偏移量写入 Zookeeper 中,这是读取 Kafka 中数据的传统方法。虽然这种方法可以保证零数据丢失,但是还是存在一些情况导致数据会丢失,因为在失败情况下通过 SS 读取偏移量和 Zookeeper 中存储的偏移量可能不一致。而本文提到的方法是通过 Kafka 低层次的 API,并没有使用到 Zookeeper,偏移量仅仅被 SS 保存在 Checkpoint 中。这就消除了 SS 和 Zookeeper 中偏移量的不一致,而且可以保证每个记录仅仅被 SS 读取一次,即使是出现故障。
但是本方法唯一的坏处就是没有更新 Zookeeper 中的偏移量,所以基于 Zookeeper 的 Kafka 监控工具将会无法显示消费的状况。但是你可以通过自己手动地将偏移量写入到 Zookeeper 中。
架构图如下:
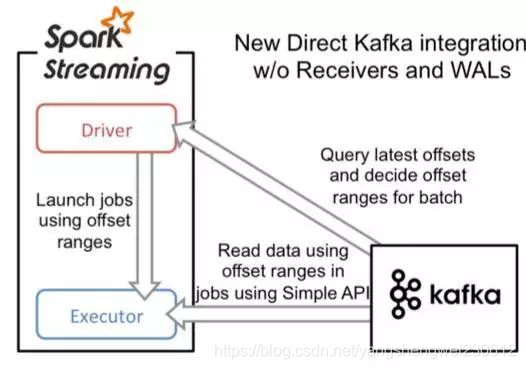
使用方式:
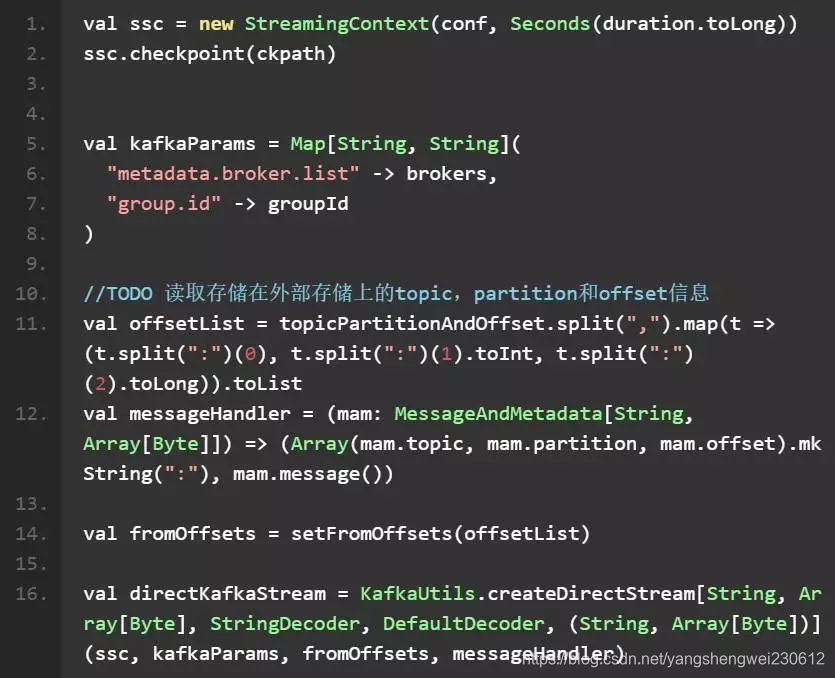
其中 fromOffsets 是指定的 topic 和 partition 开始读取的 offset 起始值,方法如下: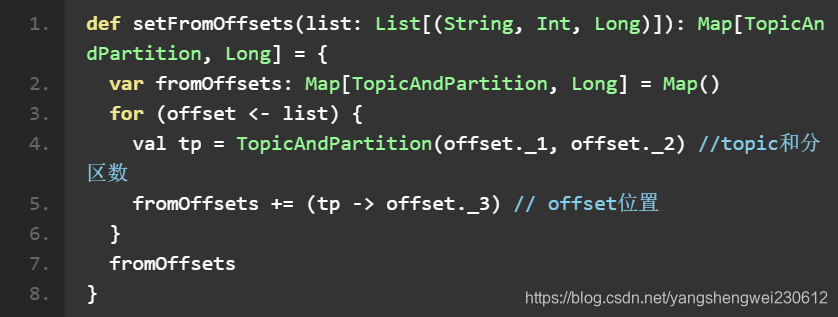
个人认为,DirectApproach 更符合 Spark 的思维。我们知道,RDD 的概念是一个不变的,分区的数据集合。我们将 Kafka 数据源包裹成了一个 KafkaRDD,RDD 里的 partition 对应的数据源为 Kafka 的 partition。唯一的区别是数据在 Kafka 里而不是事先被放到 Spark 内存里。其实包括 FileInputStream 里也是把每个文件映射成一个 RDD, 比较好奇,为什么一开始会有 Receiver-based Approach,额外添加了 Receiver 这么一个概念。
DirectKafkaInputDStream
SS 通过 Direct Approach 接收数据的入口自然是 KafkaUtils.createDirectStream 了。在调用该方法时,会先创建protected val kc = new KafkaCluster(KafkaParams)
KafkaCluster 这个类是真实负责和 Kafka 交互的类,该类会获取 Kafka 的 partition 信息, 接着会创建 DirectKafkaInputDStream。 此时会获取每个 Topic 的每个 partition 的 offset。 如果配置成 smallest 则拿到最早的 offset, 否则拿最近的 offset。
每个 DirectKafkaInputDStream 也会持有一个 KafkaCluster 实例。到了计算周期后,对应的 DirectKafkaInputDStream .compute 方法会被调用, 此时做下面几个操作:
-
获取对应 Kafka Partition 的 untilOffset。这样就确定了需要获取数据的 offset 的范围,同时也就知道了需要计算多少数据了
-
构建一个 KafkaRDD 实例。这里我们可以看到,每个计算周期里,DirectKafkaInputDStream 和 KafkaRDD 是一一对应的
-
将相关的 offset 信息报给 InputInfoTracker
-
返回该 RDD
KafkaRDD 的组成结构
KafkaRDD 包含 N(N=Kafka 的 partition 数目) 个 KafkaRDDPartition, 每个 KafkaRDDPartition 其实只是包含一些信息,譬如 topic,offset 等,真正如果想要拉数据,是通过 KafkaRDDIterator 来完成,一个 KafkaRDDIterator 对应一个 KafkaRDDPartition。整个过程都是延时过程,也就是说数据其实都还在 Kafka 里,直到有实际的 action 被触发,才会主动去 Kafka 拉数据。
限速
Direct Approach (NoReceivers) 的接收方式也是可以限制接受数据的量的。你可以通过设置 spark.streaming.kafka.maxRatePerPartition 来完成对应的配置。需要注意的是,这里是对每个 Partition 进行限速。所以你需要事先知道 Kafka 有多少个分区,才好评估系统的实际吞吐量,从而设置该值。
相应的,spark.streaming.backpressure.enabled 参数在 Direct Approach 中也是继续有效的。
Receiver模式 VS Direct模式对比
经过上面对两种数据接收方案的介绍,我们发现, Receiver-based Approach 存在各种内存折腾,对应的 Direct Approach (No Receivers) 则显得比较纯粹简单些,这也给其带来了较多的优势,主要有如下几点:
-
因为按需要拉数据,所以不存在缓冲区,就不用担心缓冲区把内存撑爆了。这个在 Receiver-based Approach 就比较麻烦,你需要通过 spark.streaming.blockInterval 等参数来调整。
-
数据默认就被分布到了多个 Executor 上。Receiver-based Approach 你需要做特定的处理,才能让 Receiver 分不到多个 Executor 上。
-
Receiver-based Approach 的方式,一旦你的 Batch Processing 被 delay 了,或者被 delay 了很多个 batch, 那估计你的 Spark Streaming 程序离崩溃也就不远了。 Direct Approach (No Receivers) 则完全不会存在类似问题。就算你 delay 了很多个 batch time, 你内存中的数据只有这次处理的。
-
Direct Approach (No Receivers) 直接维护了 Kafka offset, 可以保证数据只有被执行成功了,才会被记录下来,通过 checkpoint 机制。如果采用 Receiver-based Approach,消费 Kafka 和数据处理是被分开的,这样就很不好做容错机制,比如系统宕掉了。所以你需要开启 WAL, 但是开启 WAL 带来一个问题是,数据量很大,对 HDFS 是个很大的负担,而且也会给实时程序带来比较大延迟。
我原先以为 Direct Approach 因为只有在计算的时候才拉取数据,可能会比 Receiver-based Approach 的方式慢,但是经过我自己的实际测试,总体性能 Direct Approach 会更快些,因为 Receiver-based Approach 可能会有较大的内存隐患,GC 也会影响整体处理速度。
如何保证数据接收的可靠性
SS 自身可以做到 at least once 语义, 具体方式是通过 CheckPoint 机制。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)