YOLOX网络详解
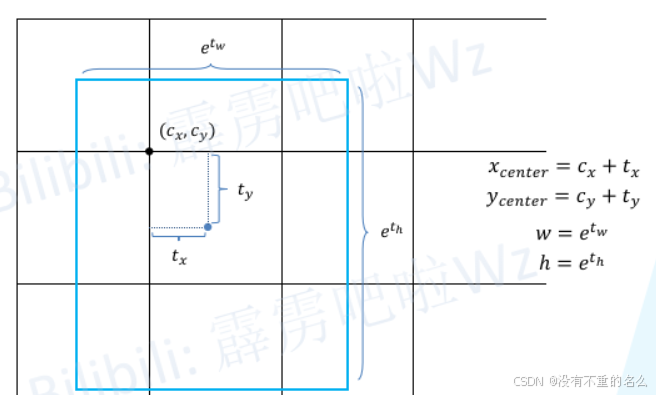
对于网络在每一个grid cell处都会预测4个参数(tx、ty、tw、th),tx与ty预测的是目标中心点相对于当前grid cell相对于当前grid cell左上角点的偏移量,预测边界框的高度和宽度用e的指数计算,计算得出的Xcenter、Ycenter、w、h都是在特征图尺度上的,需要*stride得到在原图的尺度。构建Anchor Point与每个GT之间的IoU矩阵,IoU矩阵并不需要
【YOLOX网络详解-哔哩哔哩】 https://b23.tv/jHx3D66
与之前网络区别:
①Anchor-free(借鉴于FCOS)
②Decoupled detection head 解耦的检测头
③Advanced label assigning strategy(SimOTA)更加先进的正负样本匹配策略
YOLOv5 vs YOLOX:
当数据集分辨率不是很高(640*640),两者都可以尝试
当数据集分辨率很高,达到了1280*1280,使用YOLOv5,YOLOv5的仓库官方提供了更大尺度的预训练权重
网络架构(YOLOX-L):
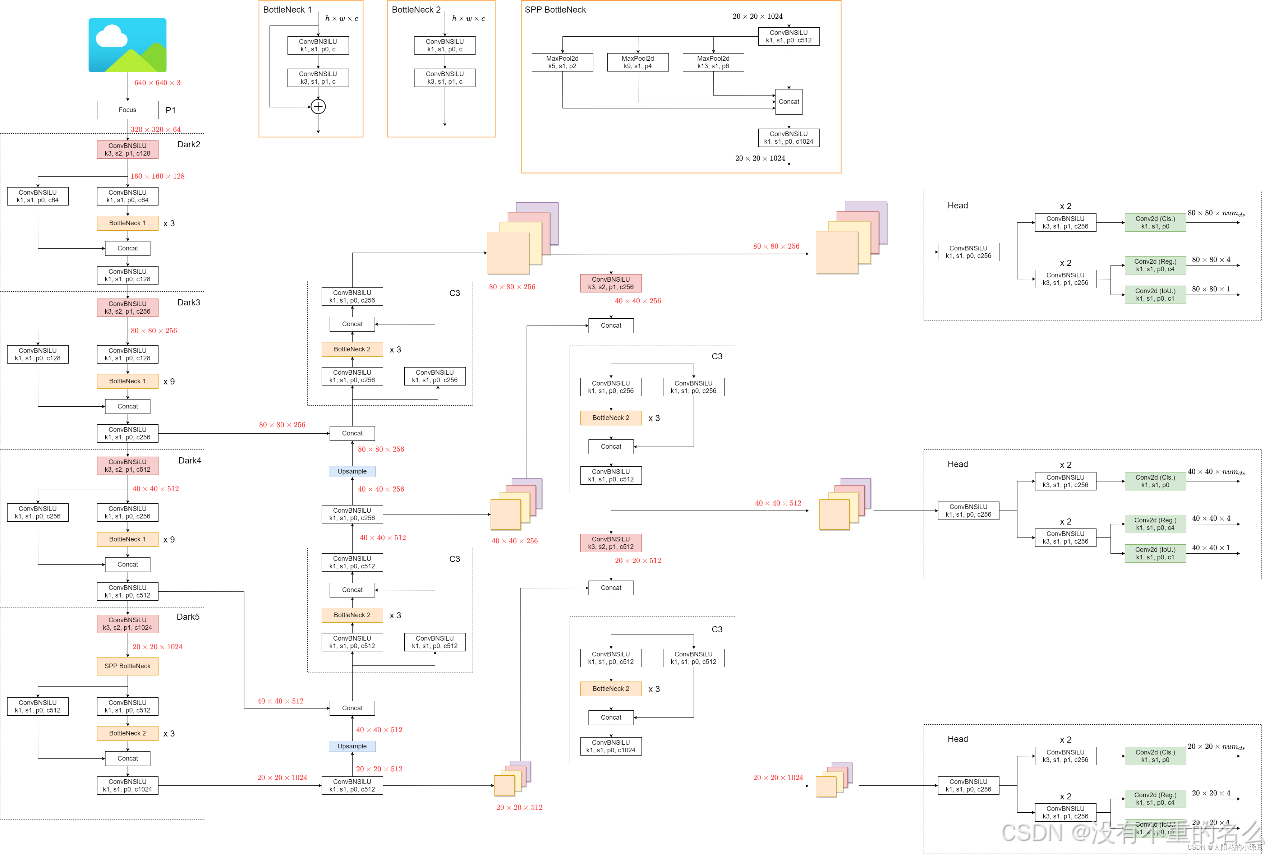
Base:YOLO v5(tag:v5.0)
Head:与YOLOv5相同
Focus模块:在YOLOv5 v6.1中,作者将focus模块替换成卷积核大小为6*6的卷积层
BottleNeck:堆叠次数与YOLOv5 v6.1版本不同
SPP BottleNeck:在YOLOv5 v6.1中,采用的是SPPF结构
检测头:
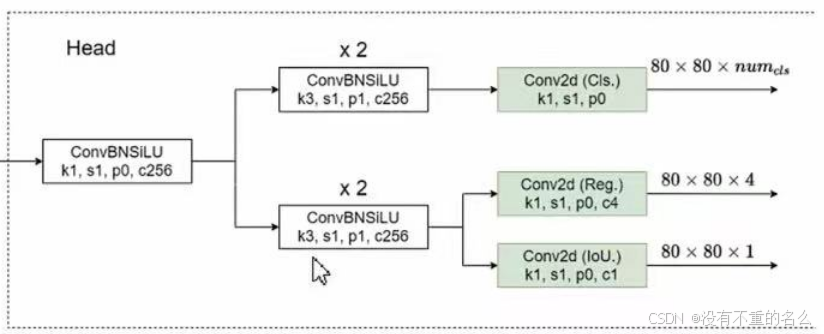
YOLOv5检测头:
在YOLOv5中,检测头就是一个kernel_size=1, stride=2,padding=0大小的卷积层,通过这一个卷积层同时预测目标的参数、objectness、每个类别的score,c=(5+Ncls)*3是因为在每个特征图上都采用三种不同大小的anchor模板;为耦合检测头
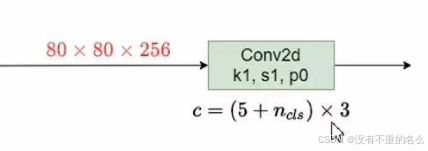
YOLOX检测头:
采用了解耦的检测头
论文中提到,耦合检测头对网络有害;若将耦合检测头替换为解耦检测头(decoupled detection head)能加速收敛,提升AP
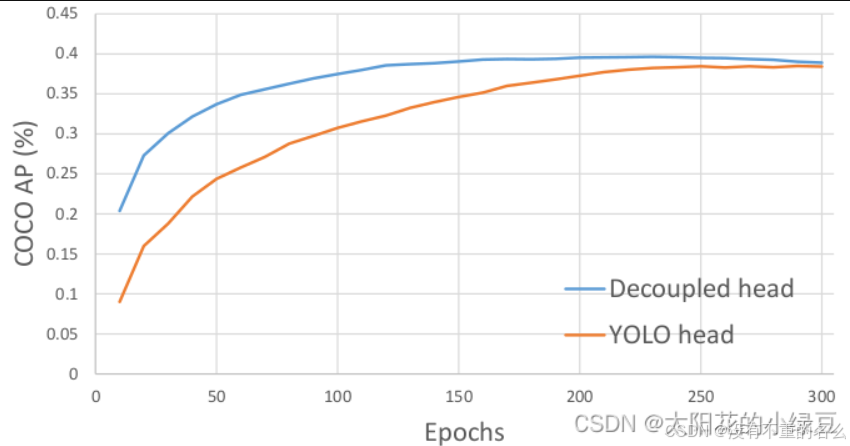
图上对比的YOLO head为YOLOv3
解耦检测头:
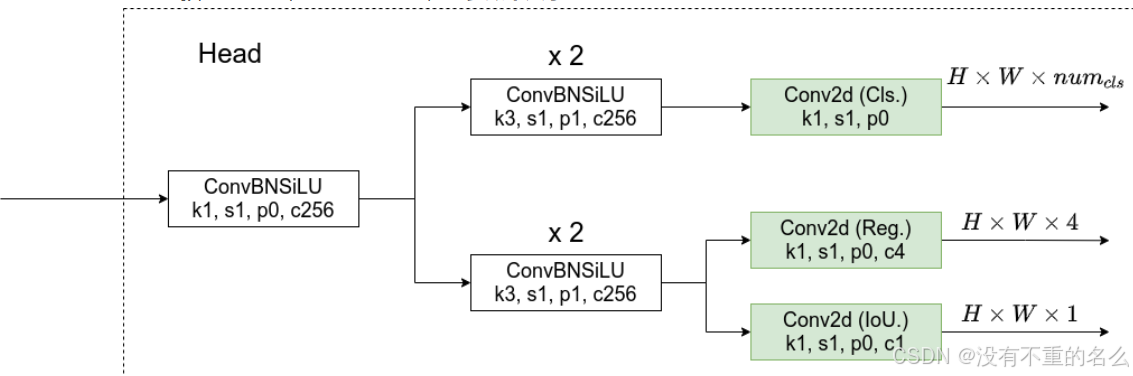
①通过kernel_size =1*1、stride=1、padding=0、卷积核个数=256的CBS模块(Conv+BN+SiLU激活函数),将通道个数统一调整为256
②并行两个分支,都采用kernel_size =3*3、stride=1、padding=0、卷积核个数为256的卷积模块
③上分支接一个1*1卷积,得到针对目标类别信息预测的分支cls分支
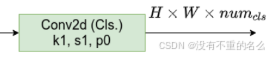
④下分支并行两个1*1卷积层,一个用来预测目标回归参数(anchor-free网络针对预测特征图只会预测4个回归参数),一个用来预测objectness
注意点:
在YOLOX检测头中,参数是不共享的,针对产生不同的预测特征图采用的Head参数是不一样的;而FCOS的Head参数是共享的
YOLOX如何将网络预测信息还原到原图尺度:
对于网络在每一个grid cell处都会预测4个参数,
与
预测的是目标中心点相对于当前grid cell相对于当前grid cell左上角点的偏移量,预测边界框的高度和宽度用
的指数计算,计算得出的
、
、
、
都是在特征图尺度上的,需要*stride得到在原图的尺度
与前YOLO系列的区别:
之前计算所得的宽度高度都需要乘anchor的宽度高度,而YOLOX的高度宽度直接为的指数,没有乘任何其他参数
YOLOX损失:
由于在网络的检测头中有Cls.分支、Reg分支以及Obj(IoU)分支
损失函数由、
、
三部分构成:
Obj分支:若当前样本被划分为正样本,gt=1;若当前样本为负样本,gt=0
和
j:采用二值交叉熵损失(BCELoss),只计算正样本损失
:采用的是IoU Loss,既计算正样本还计算负样本

正负样本匹配SimOTA:
SimOTA由OTA简化得到,OTA也是旷视科技同年文章
目的:将匹配正负样本的过程看作一个最优传输的问题
采用SimOTA后,AP提升了
SimOTA将匹配正负样本的过程看作最优传输问题
举例说明:
设有1~6个城市,在图中用五角星表示,有2个牛奶生产基地A和B,现要求2个生产基地为6个城市输送牛奶,处理安排最小化运输成本的问题。设运输成本cost仅由距离决定,那么由图易得A负责1、2、3城市;B负责4、5、6城市,这样运输成本最低

在SimOTA正负样本匹配过程中,城市对应每个样本(Anchor Point=grid cell),牛奶生产基地对应的标注好的GT Bbox,目标是怎样以最低成本(cost)将GT分配给对应的样本,根据论文公式,cost的计算公式如下:
网络预测的类别和目标边界框越准确cost值越小,最小化cost可理解为让网络以最小的学习成本学习到有用知识。
FCOS:只要落入sub-box范围内的所有anchor point就将其视为正样本,除此之外设为负样本
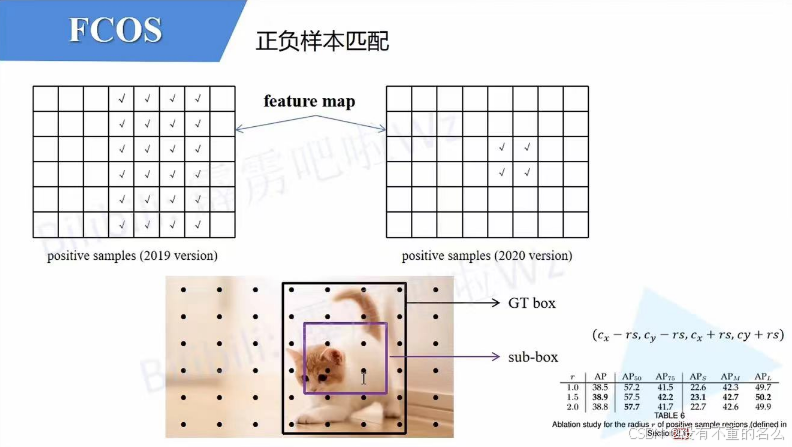
YOLOX:先进行一个预筛选的过程,根据源码,首先寻找fixed center area或GT box中的所有anchor point, fixed center area类似于FCOS中的sub-box,源码中将center_ratius设为2.5,其产生的固定区域在特征图上为5*5的大小区域,找出后得到下图打勾区域
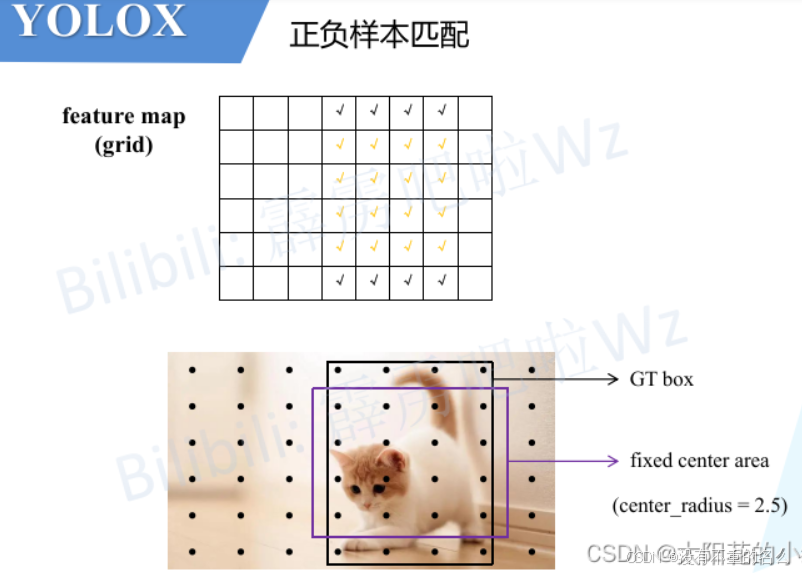
将打勾区域进行划分,一部分是落入gtbox和固定中心区域交集的点为黄色,交集之外的为黑色;在代码中计算cost由三部分组成:
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)

对于交集之外的anchor points需要加一个很大的常数,在最小化cost过程中,优先选择交集之内的anchor points;若不够再取黑色
过程:
构建矩阵之前筛选出的Anchor Point与每个GT之间的cost矩阵

构建Anchor Point与每个GT之间的IoU矩阵,IoU矩阵并不需要单独计算,在计算cost矩阵时,已经事先计算了回归损失,而回归损失也计算了IoU

计算n_candidate_k并结合IoU对Anchor Point做进一步筛选(保留IoU大的Anchor Point),是在10和anchor point之间取最小

根据IoU,对于每一行选取前n_candidate_k个anchor point;实际中根据IoU进行排序筛选
![]()
对每个GT计算剩下所有的Anchor Point的IoU之和然后向下取整得到针对每个GT所采用的正样本数量,即代码中计算得到的dynamic_ks(这个计算过程对应论文中的Dynamic k Estimation Strategy)。在实际中计算就是每一行求和,然后向下取整,如下图所示。

根据刚刚计算得到的dynamic_ks(每个GT对应几个正样本)和cost矩阵找出所有的正样本(根据cost的数值大小)。比如对于示例中的GT1,刚刚计算采用3个正样本,然后看下GT1和所有Anchor Point的cost,按照最小化原则,优先选择cost较小的Anchor Point,即示例中的A1、A2和A5。同理对于GT2,cost排前3的是A3、A4和A5。

根据以上结果,我们可以再构建一个Anchor Point分配矩阵,记录每个GT对应哪些正样本,对应正样本的位置标1,其他位置标0。

GT1和GT2同时分配给了A5;作者为了解决这个带有歧义的问题,又加了一个判断。如果多个GT同时分配给一个Anchor Point,那么只选cost最小的GT。

在示例中,由于A5与GT2的cost小于与GT1的cost,故只将GT2分配给A5


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)