
【模型部署】PaddleOCR模型openvino部署(二)
上一篇博客【模型部署】PaddleOCR模型openvino部署(一)介绍了PaddleOCR检测模型DBNet的部署方法,本篇将介绍文本方向分类、文本识别的 部署方法,同时将检测、方向分类、文本识别模型串联起来,给出完整的部署流程。
上一篇博客【模型部署】PaddleOCR模型openvino部署(一)介绍了PaddleOCR检测模型DBNet的部署方法,本篇将介绍文本方向分类、文本识别的 部署方法,同时将检测、方向分类、文本识别模型串联起来,给出完整的部署流程。
PaddleOCR:https://github.com/PaddlePaddle/PaddleOCR
部署深度学习模型的时候,我们主要完成预处理和后处理部分的代码即可,对于检测、分类、识别3个模型也是同样的,我们只需要完成预处理和后处理即可。
模型部署效果如下(左为原图,右为检测结果):


识别结果如下:

目录
一、检测模型部署
检测模型部署参考:【模型部署】PaddleOCR模型openvino部署(一),本文不再过多介绍。
二、方向分类模型部署
1、下载分类模型
!wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar2、解压压缩包
解压得到的是飞桨的静态图模型,如下图:
3、查看模型
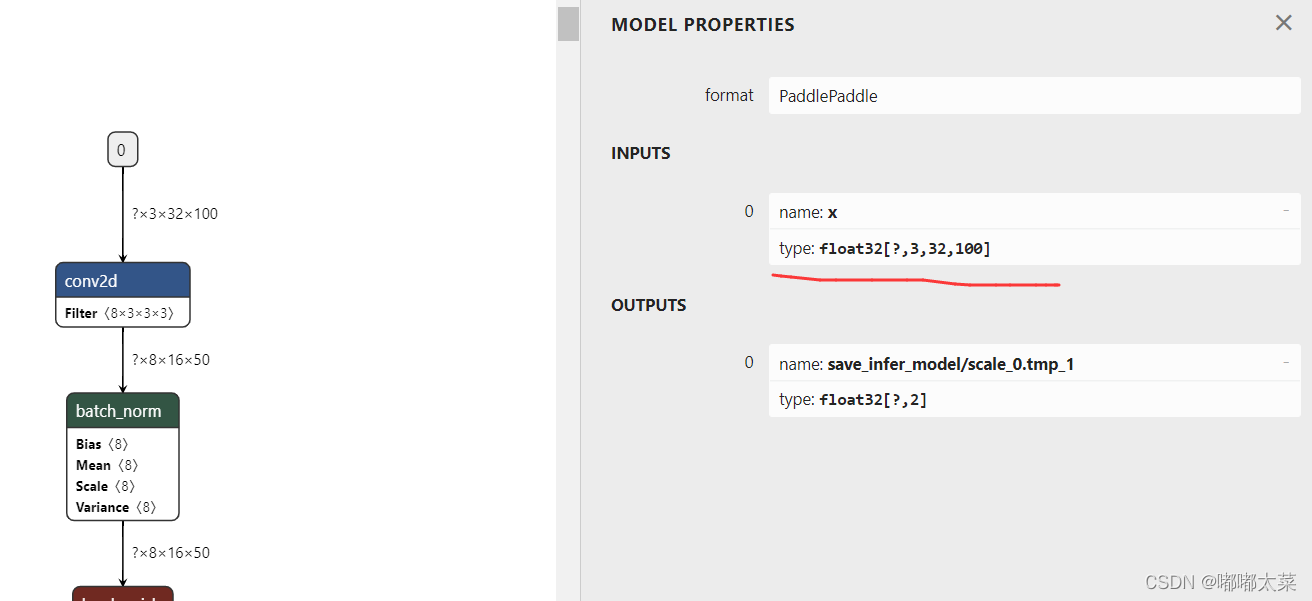
使用netron查看inference.pdmodel结构,如下图,主要关注2点:
(a)模型的输出(关系到后续的后处理);
(b)输入的维度(设计到后续的预处理);
4、部署
openvino部署代码如下:
import cv2
import openvino
import argparse
import numpy as np
import pyclipper
from openvino.runtime import Core
from shapely.geometry import Polygon
def normalize(im, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
return im
def resize(im, target_size=608, interp=cv2.INTER_LINEAR):
if isinstance(target_size, list) or isinstance(target_size, tuple):
w = target_size[0]
h = target_size[1]
else:
w = target_size
h = target_size
im = cv2.resize(im, (w, h), interpolation=interp)
return im
class ClsPostProcess(object):
""" Convert between text-label and text-index """
def __init__(self, label_list=['0', '180'], threshold=0.9):
super(ClsPostProcess, self).__init__()
self.label_list = label_list
self.threshold = threshold
def __call__(self, preds, image=None):
pred_idxs = preds.argmax(axis=1)
assert pred_idxs.shape[0] == 1, "batch size must be 1, but got {}.".format(pred_idxs.shape[0])
direction = self.label_list[pred_idxs[0]]
if direction == '180' and preds[0, 1] > self.threshold:
image = cv2.rotate(image, 1)
return image
class ClsPredictor:
def __init__(self, model_path, target_size=(100, 32), mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], threshold=0.9):
self.target_size = target_size
self.mean = mean
self.std = std
self.model_path = model_path
self.post_process = ClsPostProcess(threshold=threshold)
def preprocess(self, image):
image = resize(image, target_size=self.target_size)
image = normalize(image, mean=self.mean, std=self.std)
return image
def predict(self, image):
if isinstance(image, str):
image = cv2.imread(image)
image_h, image_w, _ = image.shape
inputs = self.preprocess(image)
input_image = np.expand_dims(
inputs.transpose(2, 0, 1), 0
)
ie = Core()
model = ie.read_model(model=self.model_path)
compiled_model = ie.compile_model(model=model, device_name="CPU")
input_layer_ir = next(iter(compiled_model.inputs))
output_layer_ir = next(iter(compiled_model.outputs))
preds = compiled_model([input_image])[output_layer_ir]
image = self.post_process(preds, image)
return image
def parse_args():
parser = argparse.ArgumentParser(description='Model export.')
# params of training
parser.add_argument(
'--model_path',
dest='model_path',
help='The path of pdmodel for export',
type=str,
default="ch_ppocr_mobile_v2.0_cls_infer/inference.pdmodel")
parser.add_argument(
'--image_path',
dest='image_path',
help='The path of image to predict.',
type=str,
default=None)
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
model_path = args.model_path
image_path = args.image_path
cls_predictor = ClsPredictor(model_path, target_size=(100, 32), mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], threshold=0.7)
image = cls_predictor.predict(image_path)
cv2.imwrite('cls_result.png', image)
cv2.imshow('1', image)
cv2.waitKey(0)
三、识别模型部署
1、下载模型
!wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar2、解压压缩包
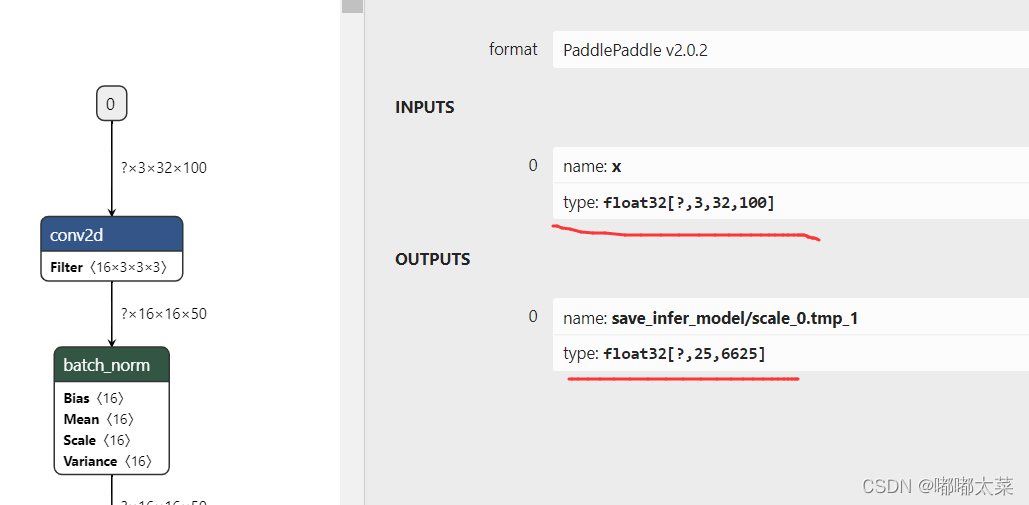
3、查看模型结构
可以看到识别模型的输入和方向分类的是一样的(因为方向分类后直接识别),输出的维度为[?, 25, 6625],这里的?表示batch size,25表示识别的字符长度,6625是字符类别个数(识别模型有个对应的字典,字典内字符数量应该和字符类别一致)。
4、部署
需要先准备好模型对应的字典,代码如下:
import cv2
import openvino
import argparse
import numpy as np
import pyclipper
from openvino.runtime import Core
from shapely.geometry import Polygon
def normalize(im, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
return im
def resize(im, target_size=608, interp=cv2.INTER_LINEAR):
if isinstance(target_size, list) or isinstance(target_size, tuple):
w = target_size[0]
h = target_size[1]
else:
w = target_size
h = target_size
im = cv2.resize(im, (w, h), interpolation=interp)
return im
class BaseRecLabelDecode(object):
""" Convert between text-label and text-index """
def __init__(self, character_dict_path=None, use_space_char=False):
self.beg_str = "sos"
self.end_str = "eos"
self.character_str = []
if character_dict_path is None:
self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"
dict_character = list(self.character_str)
else:
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
self.character_str.append(line)
if use_space_char:
self.character_str.append(" ")
dict_character = list(self.character_str)
dict_character = self.add_special_char(dict_character)
self.dict = {}
for i, char in enumerate(dict_character):
self.dict[char] = i
self.character = dict_character
def add_special_char(self, dict_character):
return dict_character
def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
""" convert text-index into text-label. """
result_list = []
ignored_tokens = self.get_ignored_tokens()
batch_size = len(text_index)
for batch_idx in range(batch_size):
char_list = []
conf_list = []
for idx in range(len(text_index[batch_idx])):
if text_index[batch_idx][idx] in ignored_tokens:
continue
if is_remove_duplicate:
# only for predict
if idx > 0 and text_index[batch_idx][idx - 1] == text_index[
batch_idx][idx]:
continue
char_list.append(self.character[int(text_index[batch_idx][
idx])])
if text_prob is not None:
conf_list.append(text_prob[batch_idx][idx])
else:
conf_list.append(1)
text = ''.join(char_list)
result_list.append((text, np.mean(conf_list)))
return result_list
def get_ignored_tokens(self):
return [0] # for ctc blank
class CTCLabelDecode(BaseRecLabelDecode):
""" Convert between text-label and text-index """
def __init__(self, character_dict_path=None, use_space_char=False,
**kwargs):
super(CTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
def __call__(self, preds, label=None, *args, **kwargs):
if isinstance(preds, (tuple, list)):
preds = preds[-1]
preds_idx = preds.argmax(axis=2)
preds_prob = preds.max(axis=2)
text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
if label is None:
return text
label = self.decode(label)
return text, label
def add_special_char(self, dict_character):
dict_character = ['blank'] + dict_character
return dict_character
class RecPredictor:
def __init__(self, model_path, character_dict_path, target_size=(100, 32), mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], use_space_char=False):
self.target_size = target_size
self.mean = mean
self.std = std
self.model_path = model_path
self.post_process = CTCLabelDecode(character_dict_path=character_dict_path, use_space_char=use_space_char)
def preprocess(self, image):
image = resize(image, target_size=self.target_size)
#cv2.imshow('rec', image)
#cv2.waitKey(0)
image = normalize(image, mean=self.mean, std=self.std)
return image
def predict(self, image):
if isinstance(image, str):
image = cv2.imread(image)
image_h, image_w, _ = image.shape
inputs = self.preprocess(image)
input_image = np.expand_dims(
inputs.transpose(2, 0, 1), 0
)
ie = Core()
model = ie.read_model(model=self.model_path)
compiled_model = ie.compile_model(model=model, device_name="CPU")
input_layer_ir = next(iter(compiled_model.inputs))
output_layer_ir = next(iter(compiled_model.outputs))
preds = compiled_model([input_image])[output_layer_ir]
text = self.post_process(preds)
return text
def parse_args():
parser = argparse.ArgumentParser(description='Model export.')
# params of training
parser.add_argument(
'--model_path',
dest='model_path',
help='The path of pdmodel for export',
type=str,
default=None)
parser.add_argument(
'--image_path',
dest='image_path',
help='The path of image to predict.',
type=str,
default=None)
parser.add_argument(
'--use_space_char',
dest='use_space_char',
help='Whether use space char.',
type=bool,
default=False)
parser.add_argument(
'--character_dict_path',
dest='character_dict_path',
help='The path of character dict.',
type=str,
default="ppocr_keys_v1.txt")
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
model_path = args.model_path
image_path = args.image_path
use_space_char = args.use_space_char
character_dict_path = args.character_dict_path
rec_predictor = RecPredictor(model_path, character_dict_path=character_dict_path, target_size=(100, 32), mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], use_space_char=use_space_char)
text = rec_predictor.predict(image_path)
print(text)
四、检测+分类+识别串行部署
有了3个模型各自的部署代码,将其串起来,如下(全部代码见文末):
import cv2
import openvino
import argparse
import numpy as np
import pyclipper
from openvino.runtime import Core
from shapely.geometry import Polygon
from ppocr_cls import ClsPredictor
from ppocr_det import DetPredictor
from ppocr_rec import RecPredictor
from PIL import Image, ImageDraw, ImageFont
class PaddleOCR:
def __init__(self, det_model_path, rec_model_path, character_dict_path, cls_model_path=None, use_space_char=False, det_image_size=[960, 960], rec_image_size=[100, 32], mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
self.det_predictor = DetPredictor(det_model_path, target_size=det_image_size, mean=mean, std=std)
self.cls_predictor = ClsPredictor(cls_model_path, target_size=rec_image_size, mean=mean, std=std) if cls_model_path else None
self.rec_predictor = RecPredictor(rec_model_path, character_dict_path=character_dict_path, target_size=rec_image_size, mean=mean, std=std, use_space_char=use_space_char)
def predict(self, image_path):
image = cv2.imread(image_path)
raw_image = image.copy()
boxes_batch = self.det_predictor.predict(image_path)
draw_image = self.det_predictor.draw_det(image, boxes_batch[0]['points'])
texts = []
for box in boxes_batch[0]['points']:
box = box.astype(np.int32)
left, top = box[0, 0], box[0, 1]
right, bottom = box[2, 0], box[2, 1]
sub_image = raw_image[top:bottom, left:right, :]
if self.cls_predictor is not None:
sub_image = self.cls_predictor.predict(sub_image)
text = self.rec_predictor.predict(sub_image)
texts.append(text)
return draw_image, texts
def parse_args():
parser = argparse.ArgumentParser(description='Model export.')
# params of training
parser.add_argument(
'--det_model_path',
dest='det_model_path',
help='The path of detection pdmodel for export',
type=str,
default='ch_PP-OCRv2_det_infer/inference.pdmodel')
parser.add_argument(
'--rec_model_path',
dest='rec_model_path',
help='The path of recognition pdmodel for export',
type=str,
default="ch_PP-OCRv2_rec_infer/inference.pdmodel")
parser.add_argument(
'--cls_model_path',
dest='cls_model_path',
help='The path of direction class pdmodel for export',
type=str,
default="ch_ppocr_mobile_v2.0_cls_infer/inference.pdmodel")
parser.add_argument(
'--image_path',
dest='image_path',
help='The path of image to predict.',
type=str,
default=None)
parser.add_argument(
'--save_path',
dest='save_path',
help='The image save path.',
type=str,
default="result.png")
parser.add_argument(
'--use_space_char',
dest='use_space_char',
help='Whether use space char.',
type=bool,
default=True)
parser.add_argument(
'--character_dict_path',
dest='character_dict_path',
help='The path of character dict.',
type=str,
default="ppocr_keys_v1.txt")
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
predictor = PaddleOCR(det_model_path=args.det_model_path, rec_model_path=args.rec_model_path, character_dict_path=args.character_dict_path, cls_model_path=args.cls_model_path, use_space_char=args.use_space_char)
draw_image, texts = predictor.predict(args.image_path)
cv2.imwrite(args.save_path, draw_image)
print(texts)
五、参考
1、本文全部代码连接:pp-ocrv2pythonopenvino部署代码-深度学习文档类资源-CSDN下载

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)