Facets:评估机器学习数据集质量利器 (来自Google、可交互、可可视化)
好的数据集质量,决定后续模型的上限 (Better data leads to better models),那么怎么快速评估数据集的质量了?本文分享的Facets,是一款由Google开...
·
好的数据集质量,决定后续模型的上限 (Better data leads to better models),那么怎么快速评估数据集的质量了?
本文分享的Facets,是一款由Google开源、快速评估数据集质量的神器;
Facets包含2个组件:
-
facets overview:outlier检测、数据集间各特征分布比较 -
facets dive:交互式探索某一特定数据细节。
安装
pip install facets-overviewfacets overview
以一个案例简单介绍使用方法,
# 1、生成数据源
import pandas as pd
features = [
"Age", "Workclass", "fnlwgt", "Education", "Education-Num",
"Marital Status", "Occupation", "Relationship", "Race", "Sex",
"Capital Gain", "Capital Loss", "Hours per week", "Country", "Target"
]
train_data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
names=features,
sep=r'\s*,\s*',
engine='python',
na_values="?")
test_data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test",
names=features,
sep=r'\s*,\s*',
skiprows=[0],
engine='python',
na_values="?")
# 2、GenericFeatureStatisticsGenerator()和ProtoFromDataFrames()函数存储数据集的所有统计信息
from facets_overview.generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
import base64
gfsg = GenericFeatureStatisticsGenerator()
proto = gfsg.ProtoFromDataFrames([{
'name': 'train',
'table': train_data
}, {
'name': 'test',
'table': test_data
}])
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
# 3、生成HTML并可视化结果
from IPython.core.display import display, HTML
HTML_TEMPLATE = """
<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/1.3.3/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/1.0.0/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))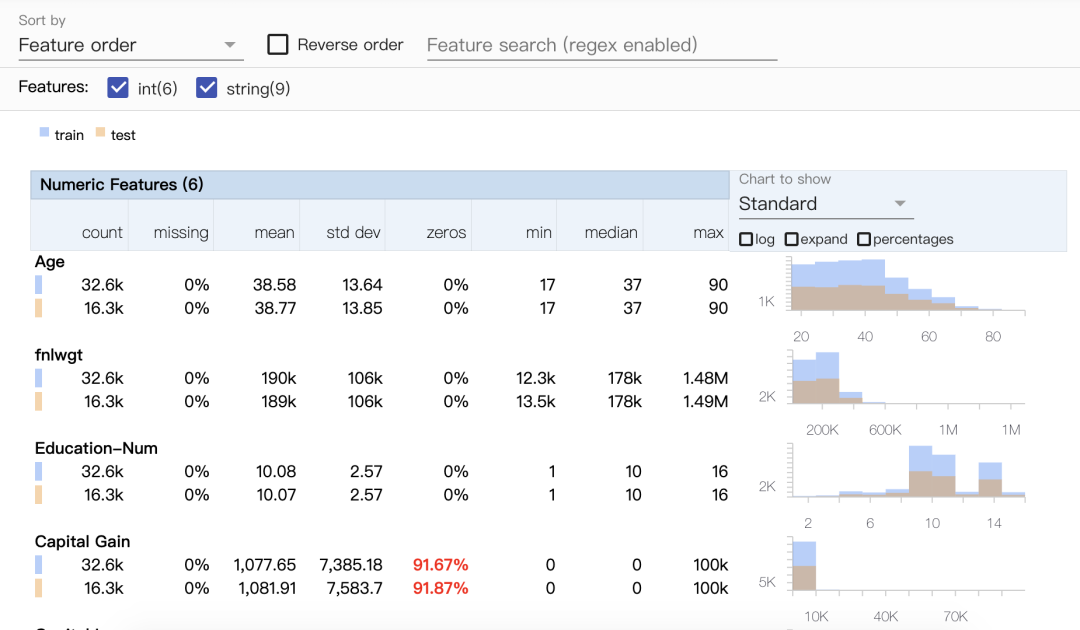
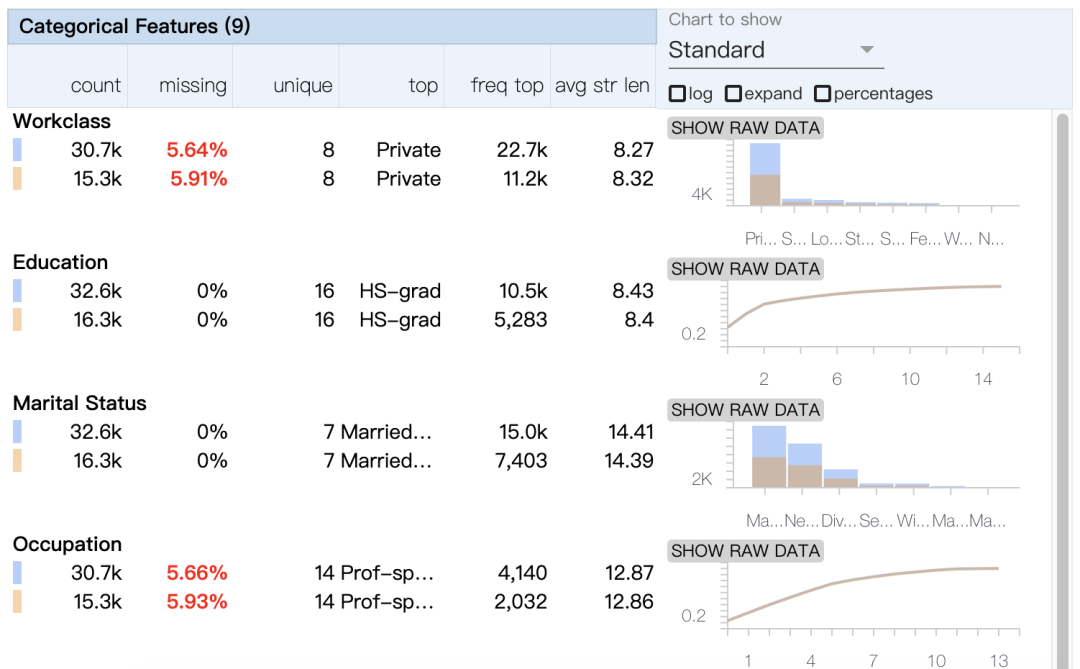 以上结果可非常方便的展示train//test数据集的偏斜情况、缺失值情况等等。
以上结果可非常方便的展示train//test数据集的偏斜情况、缺失值情况等等。
facets dive
同样以一个案例简单介绍使用方法,
import base64
import urllib.request
import os
import pandas as pd
# 数据准备
img_url = "https://storage.googleapis.com/what-if-tool-resources/misc-resources/fmnist_sprite_atlas.png"
img_name = os.path.basename(img_url)
urllib.request.urlretrieve(img_url, img_name)
df_fmnist = pd.read_csv(
"https://storage.googleapis.com/what-if-tool-resources/misc-resources/fmnist.csv"
)
with open("fmnist_sprite_atlas.png", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
# 生成HTML并可视化展示
from IPython.core.display import display, HTML
jsonstr = df_fmnist.to_json(orient='records')
HTML_TEMPLATE = """
<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/1.3.3/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/1.0.0/facets-dist/facets-jupyter.html">
<facets-dive id="elem" height="1000" sprite-image-width="28" sprite-image-height="28" atlas-url="data:image/png;base64,{encoded_string}"></facets-dive> #调用facets-dive
<script>
var data = {jsonstr};
document.querySelector("#elem").data = data;
</script>"""
html = HTML_TEMPLATE.format(jsonstr=jsonstr,
encoded_string=encoded_string.decode("utf-8"))
display(HTML(html))
 参考&进一步学习👉👉https://github.com/PAIR-code/facets
参考&进一步学习👉👉https://github.com/PAIR-code/facets

E N D

各位伙伴们好,詹帅本帅假期搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)