PaddleOCR训练和测试自己的数据集
PaddleOCR训练和测试自己的数据集
文章目录
一、环境配置
1、使用GPU训练之前需要安装paddlepaddle-gpu步骤如下:
飞浆官网(https://www.paddlepaddle.org.cn/)查找安装命令: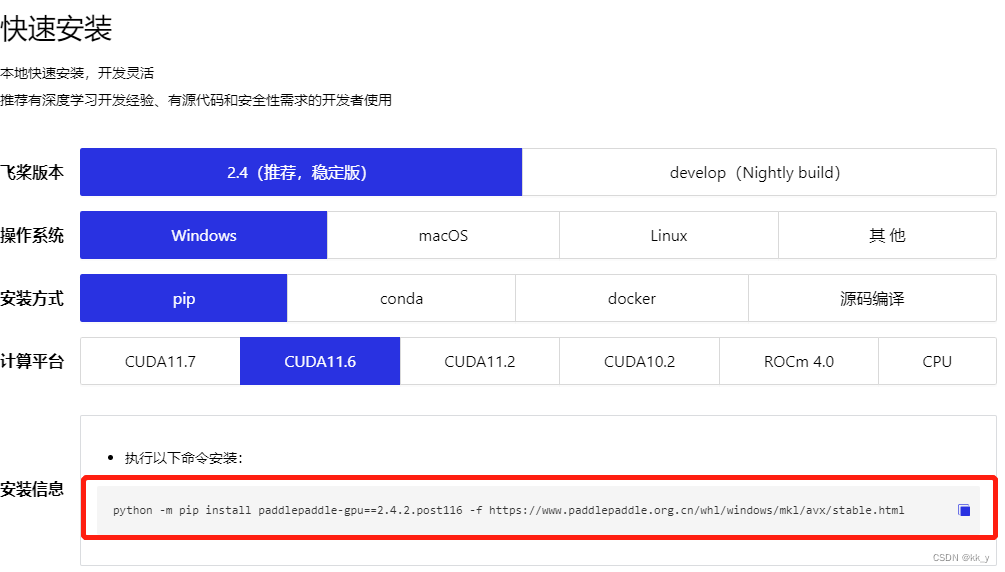
二、图像标注
1、法一(针对不下载项目的,只做标注的)
# 安装标注软件
pip install PPOCRLabel
# 安装paddlepaddle-gpu,去https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html中查找对应的命令
# 如:windows系统,cuda=11.6对应命令如下:
python -m pip install paddlepaddle-gpu==2.4.2.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
# 运行标注软件,进行标注
PPOCRLabel --lang ch
2、法二
下载paddleOCR项目:
https://github.com/PaddlePaddle/PaddleOCR
cd PPOCRLabel
python PPOCRLabel.py --lang ch
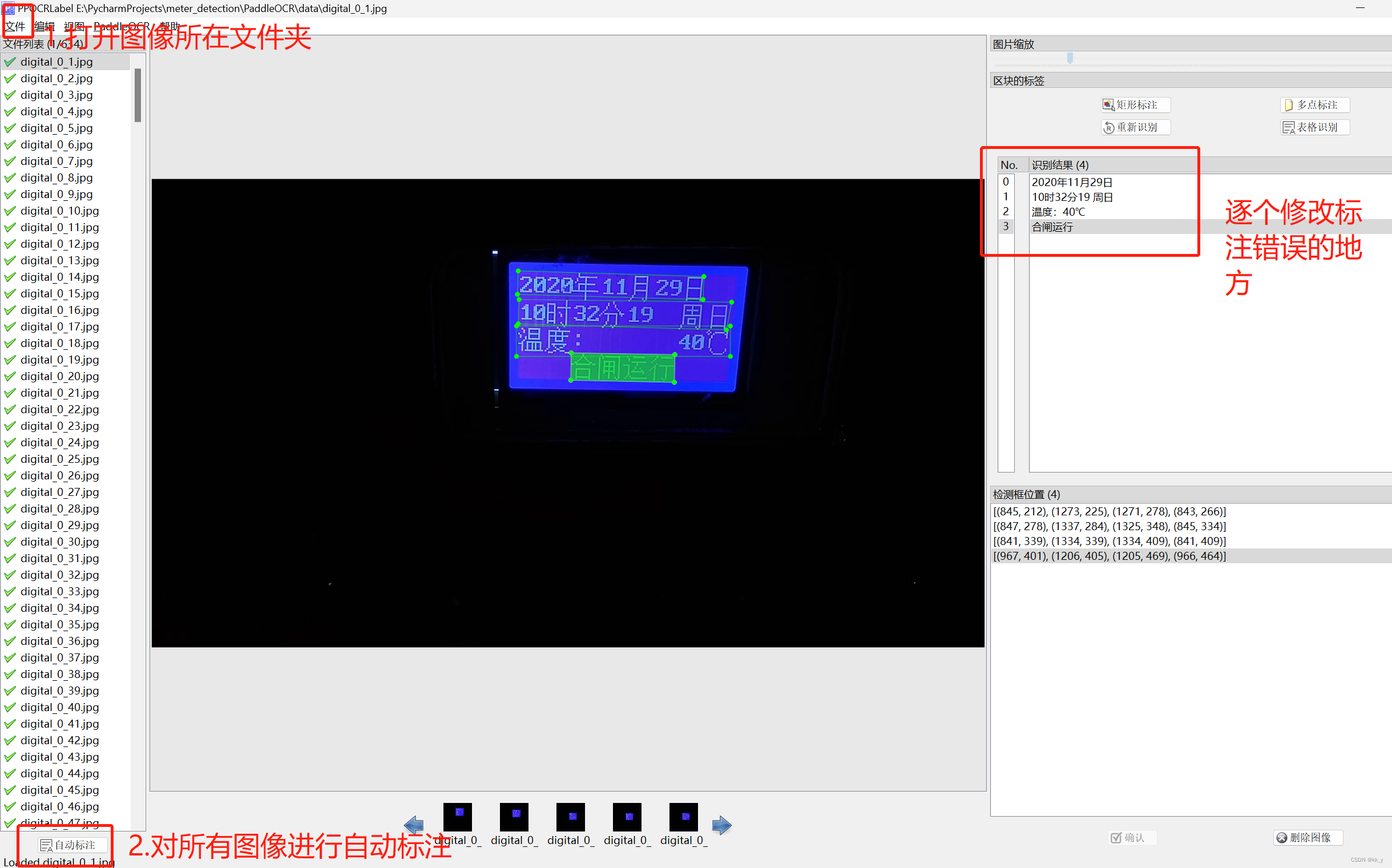
三、文本检测训练自己的数据集
1、数据集划分
import random
train_txt = open("train.txt", "w", encoding="utf-8")
val_txt = open("val.txt", "w", encoding="utf-8")
with open("Label.txt", "r", encoding="utf-8") as f:
data = f.readlines()
f.close()
li_all = []
for da in data:
data1 = da.strip('\n')
li_all.append(data1)
count = len(data)
tra = int(0.9 * count)
li = range(count)
print("训练集个数:", tra)
print("验证集个数:", count-tra)
train = random.sample(li, tra) # 随机从li列表中选取tra个数据
for i in li:
if i in train:
train_txt.write(li_all[i] + "\n")
else:
val_txt.write(li_all[i] + "\n")
2、修改配置文件
配置文件目录:./PaddleOCR/configs/det/det_mv3_db.yml
注: 这里的训练图像存放路径和标注label都在./data目录下。
Global:
use_gpu: True # 默认是True
use_xpu: false
use_mlu: false
epoch_num: 500 # ======================改====================================
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/db_mv3/ # ======================改====================================
save_epoch_step: 100 # ======================改====================================
# evaluation is run every 2000 iterations
eval_batch_step: [0, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained/ch_ppocr_mobile_v2.0_det_train/best_accuracy # ======================改====================================
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./output/det_db/predicts_db.txt
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
learning_rate: 0.001
regularizer:
name: 'L2'
factor: 0
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./ # ======================改====================================
label_file_list:
- ./data/train.txt # ======================改====================================
ratio_list: [1.0]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [-10, 10] } }
- { 'type': Resize, 'args': { 'size': [0.5, 3] } }
- EastRandomCropData:
size: [640, 640]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
loader:
shuffle: True
drop_last: False
batch_size_per_card: 1 # 16 =====================改====================================
num_workers: 1 # ======================改====================================
use_shared_memory: True
Eval:
dataset:
name: SimpleDataSet
data_dir: ./ # ======================改====================================
label_file_list:
- ./data/val.txt # ======================改====================================
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
image_shape: [736, 1280]
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1 ======================改====================================
num_workers: 8 # ======================改====================================
use_shared_memory: True
3、训练自己的数据集
python tools/train.py -c configs/det/det_mv3_db.yml
4、断点续训
python tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/db_mv3_0606/latest_accuracy
四、文本识别训练自己的数据集
1、制作数据集
对标注好的图像进行处理,如下:
import os
from PIL import Image
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
img_path = "E:/PycharmProjects/meter_detection/PaddleOCR/train_data/data/" # 图像目录
img_txt_path = "train_data/rec_ch/" # 标注好的图像的txt文件目录
img_save_path = "E:/PycharmProjects/meter_detection/PaddleOCR/train_data/rec_ch/" # 处理后的图像和txt存储目录,即训练集目录
mkdir(img_save_path)
li = ["train", "test"] # 待处理的txt标注文件
for txt in li:
ocr_li = []
img_save = img_save_path + txt + "/" # 图像保存路径
mkdir(img_save)
with open(f"E:/PycharmProjects/meter_detection/PaddleOCR/train_data/{txt}.txt", "r", encoding="utf-8") as f:
data = f.readlines()
f.close()
new_txt = open(f"{img_save_path}rec_gt_{txt}.txt", "w", encoding="utf-8") # 新的txt标注文件存放处
for da in data:
da_new = da.strip("\n")
img_name, img_info = da_new.split(" ")
img_name = img_name.split("/")[-1]
img = Image.open(img_path + img_name)
img_info = eval(img_info) # 将字符串转换为列表
i = 1
for di in img_info:
new_name = img_name[:-4] + "_" + str(i) + ".jpg"
img_new_path = img_txt_path + txt + "/" + new_name # txt文件中的图像路径+名字
label = di["transcription"]
points = di["points"]
# 获取四个点的 x 和 y 坐标
x_coordinates = [point[0] for point in points]
y_coordinates = [point[1] for point in points]
# 计算剪切区域的坐标
left = min(x_coordinates)
upper = min(y_coordinates)
right = max(x_coordinates)
lower = max(y_coordinates)
if label not in ocr_li:
ocr_li.append(label)
new_txt.write(img_new_path + " " + label + "\n")
new_img = img.crop((left, upper, right, lower)) # 左上角和右下角的坐标
new_img.save(img_save + new_name)
i += 1
训练图像和txt存储路径: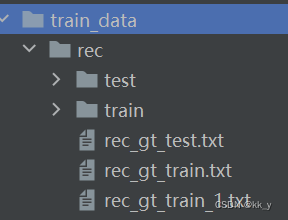
txt文件格式例子: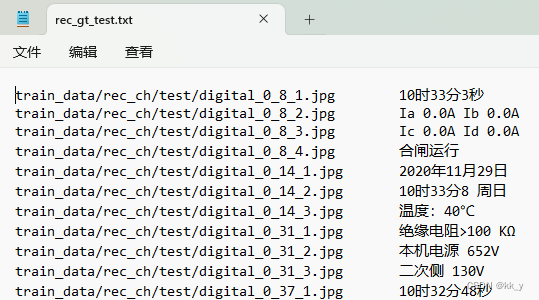
2、修改配置文件
配置文件路径:configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
Global:
debug: false
use_gpu: true
epoch_num: 500 # 800 ======================修改=====================
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/rec_ppocr_v3_distillation
save_epoch_step: 100 # 3 ======================修改=====================
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: pretrain_models/rec_train/ch_PP-OCRv2_rec_slim/ch_PP-OCRv3_rec_train/best_accuracy # ======================修改=====================
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_distillation.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Piecewise
decay_epochs : [700]
values : [0.0005, 0.00005]
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: &model_type "rec"
name: DistillationModel
algorithm: Distillation
Models:
Teacher:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Student:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: CombinedLoss
loss_config_list:
- DistillationDMLLoss:
weight: 1.0
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: ctc
name: dml_ctc
- DistillationDMLLoss:
weight: 0.5
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: sar
name: dml_sar
- DistillationDistanceLoss:
weight: 1.0
mode: "l2"
model_name_pairs:
- ["Student", "Teacher"]
key: backbone_out
- DistillationCTCLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
- DistillationSARLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
PostProcess:
name: DistillationCTCLabelDecode
model_name: ["Student", "Teacher"]
key: head_out
multi_head: True
Metric:
name: DistillationMetric
base_metric_name: RecMetric
main_indicator: acc
key: "Student"
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: ./ # ======================修改=====================
ext_op_transform_idx: 1
label_file_list:
- ./train_data/rec_ch/rec_gt_train.txt # ======================修改=====================
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 8 # 128======================修改=====================
drop_last: true
num_workers: 4 # ======================修改=====================
Eval:
dataset:
name: SimpleDataSet
data_dir: ./ # ======================修改=====================
label_file_list:
- ./train_data/rec_ch/rec_gt_test.txt # ======================修改=====================
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 8 # 128======================修改=====================
num_workers: 4 # ======================修改=====================
3、训练自己的数据集
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
五、测试
1、将训练好的权重转换为infer文件
命令如下:
python tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/db_mv3_0606/best_accuracy Global.save_inference_dir=./output/db_mv3_infer_0606/
2、测试
import os
import time
from paddleocr import PaddleOCR
import pandas as pd
import numpy as np
import cv2
def ocr_predict(img, img_name):
'''
det_model_dir:文本检测
rec_model_dir:文本识别
'''
ocr = PaddleOCR(det_model_dir="./output/det_test/ch_PP-OCRv3_det/ch_PP-OCRv3_det_infer/",
rec_model_dir="./output/rec_test/ch_PP-OCRv3_rec_infer/", lang='ch', use_angle_cls=True,
use_gpu=False)
result = ocr.ocr(
img)
print(result)
if __name__ == '__main__':
img_path = "E:/PycharmProjects/meter_detection/data/digital_meter/test_data/"
files = os.listdir(img_path)
for file in files:
img = img_path + file
ocr_predict(img, file)
六、训练过程中遇到的问题
报错内容:
Could not locate zlibwapi.dll. Please make sure it is in your library path
解决方法:
缺少zlibwapi.dll文件,下载缺少的文件并存放到以下目录:
lib文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib
dll文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin
链接:https://pan.baidu.com/s/1Q9VNmU3UN_yaP-hWAJJNgA?pwd=0921
提取码:0921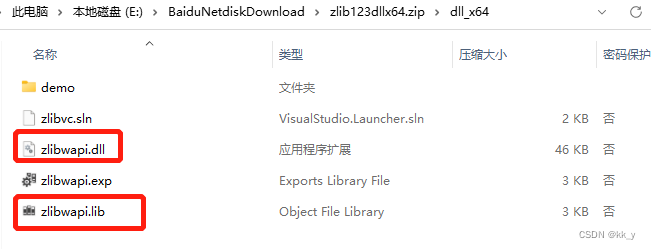

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)